O Meteor está configurado para conectar-se a um banco de dados mongo externo . Você empacota o mongo em um aplicativo de desenvolvimento local, mas isso é apenas para conforto e fácil integração.
Na produção, você sempre terá que conectar o Meteor à sua instância do Mongo em execução usando o
MONGO_URL variável de ambiente
. Bônus:você pode definir o
MONGO_URL mesmo no modo dev para se conectar a um banco de dados específico no modo dev. Esteja ciente de que você pode CRUD tudo neste banco de dados, use com cuidado. Sob o capô, o Meteor usa o driver node mongo. Você basicamente pode usar toda a API deste driver (veja esta postagem para detalhes sobre como chamar métodos nativos do Mongo)
Com o sistema de publicação/assinatura do Meteor você basicamente controla quais dados são publicados para o cliente. As publicações são executadas sempre que os dados são alterados (semelhante ao padrão do observador).
Se todos os seus clientes assinarem os dados de uma coleção, eles receberão as atualizações assim que a coleção for atualizada. E agora chegando ao seu recurso mais procurado:isso também funciona se esses dados forem atualizados por alguma fonte externa.
Também funciona com intervalos de atualização muito rápidos. Trabalhei em um projeto recente em que grandes quantidades de dados foram atualizadas via python em uma coleção do Mongo-DB. O aplicativo Meteor ouviu e exibiu os dados para os clientes em "tempo real" (ou o que os usuários percebem como tempo real).
No entanto, existem algumas armadilhas e é bom conhecê-las com antecedência.
-
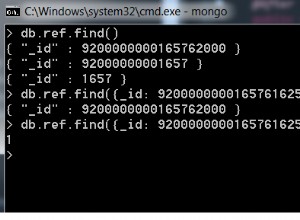
Meteor cria documentos com um_iddo tipo string e nãoMongo.ObjectID. No entanto, é capaz de lê-lo e escrevê-lo se você usá-lo corretamente .
-
O Meteor agrupa as coleções com uma própria API que integra melhor a coleção com suasfibersambiente baseado. Se você precisar usar outras funcionalidades, leia aqui e aqui .
-
Cursores retornados se comportam um pouco diferente, mas como acontece com as Coleções, também existem todas as funcionalidades nativas disponíveis se você receber o cursor de umarawCollection
-
Verifique os tipos de dados que você usa em suas coleções. Por exemplo, fique com os mesmos tipos de data (como ISODate) para que não haja erros não intencionais após uma atualização. Há também uma contrapartida do Meteor paramongoosechamadosimpl-schema(pacote npm ), que é uma boa maneira de manter a estrutura em suas coleções.
Resumindo, se você considerar o guia Meteor e os documentos da API, você deve estar no caminho certo, pois a integração de coleções atualizadas externamente geralmente funciona muito bem e trata-se principalmente de entender o sistema pub/sub para fazê-lo funcionar.
Editar:
Sim, mas você precisa estar ciente de uma consulta diferente. Se o documento (criado externamente) tiver o seguinte valor:
{ "_id" : ObjectId("4ecc05e55dd98a436ddcc47c") }
Então você tem que mudar sua consulta (Meteor) de
collection.findOne("4ecc05e55dd98a436ddcc47c") // returns undefined
para
collection.findOne({ "_id" : new Mongo.ObjectID("4ecc05e55dd98a436ddcc47c") }) // returns { _id: ObjectID { _str: '4ecc05e55dd98a436ddcc47c' } }
O mesmo padrão funciona para a criação de documentos. Ao invés de
collection.insert({ foo:'bar' })
você passa um ObjectID recém-criado:
collection.insert({ foo:'bar', _id: new Mongo.ObjectID() })
Se você criar documentos no Meteor com o método acima, você não precisa se preocupar com
_id sendo uma Corda. Além disso, os documentos são como deveriam ser (consulte a ponte de formato de dados ). No entanto, se houver uma exceção que você encontrou que não foi mencionada aqui, sinta-se à vontade para comentar, pois isso também pode ser importante para outros usuários.