O objetivo principal deste Tutorial do Hadoop é fornecer uma descrição detalhada de cada componente usado no funcionamento do Hadoop. Neste tutorial, abordaremos o Partitioner no Hadoop.
O que é o Hadoop Partitioner, qual é a necessidade do Partitioner no Hadoop, Qual é o Partitioner padrão no MapReduce, Quantos MapReduce Partitioner são usados no Hadoop?
Responderemos a todas essas perguntas neste tutorial do MapReduce.
O que é o Particionador Hadoop?
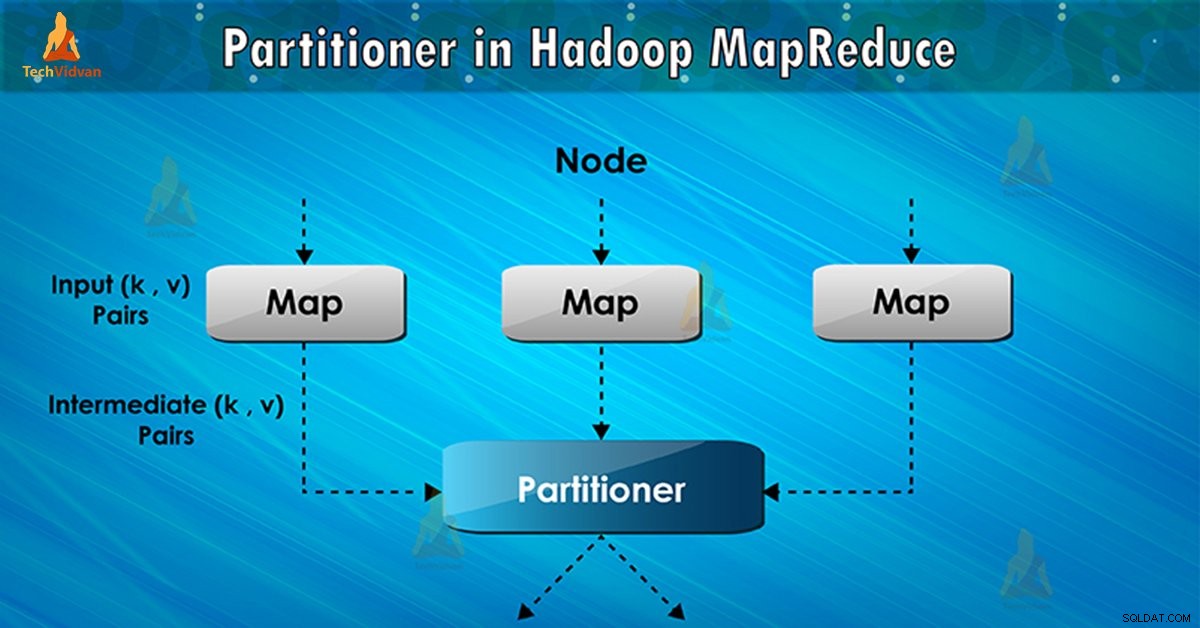
O particionador na execução do trabalho MapReduce controla o particionamento das chaves das saídas de mapa intermediárias. Com a ajuda da função hash, a chave (ou um subconjunto da chave) deriva a partição. O número total de partições é igual ao número de tarefas de redução.
Com base no valor-chave , partições de estrutura, cada mapeador saída. Registros como tendo o mesmo valor de chave vão para a mesma partição (dentro de cada mapeador). Em seguida, cada partição é enviada para um redutor .
A classe de partição decide para qual partição um determinado par (chave, valor) irá. A fase de partição no fluxo de dados MapReduce ocorre após a fase de mapeamento e antes da fase de redução.
Necessidade de particionador MapReduce no Hadoop
Na execução do job MapReduce, ele pega um conjunto de dados de entrada e produz a lista de pares de chave-valor. Esse par chave-valor é o resultado da fase do mapa. Em que os dados de entrada são divididos e cada tarefa processa a divisão e cada mapa, produza a lista de pares de valores-chave.
Em seguida, a estrutura envia a saída do mapa para reduzir a tarefa. Reduzir processa a função de redução definida pelo usuário nas saídas do mapa. Antes da fase de redução, o particionamento da saída do mapa ocorre com base na chave.
O particionamento do Hadoop especifica que todos os valores de cada chave são agrupados. Ele também garante que todos os valores de uma única chave vão para o mesmo redutor. Isso permite uma distribuição uniforme da saída do mapa sobre o redutor.
O particionador em um trabalho MapReduce redireciona a saída do mapeador para o redutor determinando qual redutor manipula a chave específica.
Particionador padrão do Hadoop
Particionador de hash é o Particionador padrão. Ele calcula um valor de hash para a chave. Ele também atribui a partição com base nesse resultado.
Quantos particionadores no Hadoop?
O número total de particionador depende do número de redutores. O Hadoop Partitioner divide os dados de acordo com o número de redutores. É definido por JobConf.setNumReduceTasks() método.
Assim, o redutor único processa os dados do particionador único. O importante a notar é que o framework cria particionador somente quando há muitos redutores.
Particionamento ruim no Hadoop MapReduce
Se na entrada de dados no trabalho MapReduce uma chave aparece mais do que qualquer outra chave. Nesse caso, para enviar dados para a partição, usamos dois mecanismos que são os seguintes:
- A chave que aparece mais vezes será enviada para uma partição.
- Todas as outras chaves serão enviadas para partições com base em seus hashCode() .
Se hashCode() O método não distribui outros dados de chave no intervalo de partição. Então os dados não serão enviados para os redutores.
O particionamento deficiente de dados significa que alguns redutores terão mais entrada de dados em comparação com outros. Eles terão mais trabalho a fazer do que outros redutores. Assim, todo o trabalho tem que esperar que um redutor termine sua parte extra grande da carga.
Como superar o particionamento deficiente no MapReduce?
Para superar o particionador ruim no Hadoop MapReduce, podemos criar o particionador personalizado. Isso permite compartilhar a carga de trabalho entre diferentes redutores.
Conclusão
Em conclusão, o Partitioner permite uma distribuição uniforme da saída do mapa sobre o redutor. No MapReducer Partitioner, o particionamento da saída do mapa ocorre com base na chave e no valor.
Portanto, cobrimos a visão geral completa do Partitioner neste blog. Espero que tenha gostado. Se você tiver alguma dúvida sobre o Hadoop Partitioner, não se esqueça de compartilhar conosco.



