Neste blog, forneceremos a você a introdução completa do Hadoop Mapper . EU
Neste blog, vamos responder o que é o Mapeador no Hadoop MapReduce, como funciona o mapeador do hadoop, quais são os processos do mapeador no Mapreduce, como o Hadoop gera o par chave-valor no MapReduce.
Introdução ao Hadoop Mapper
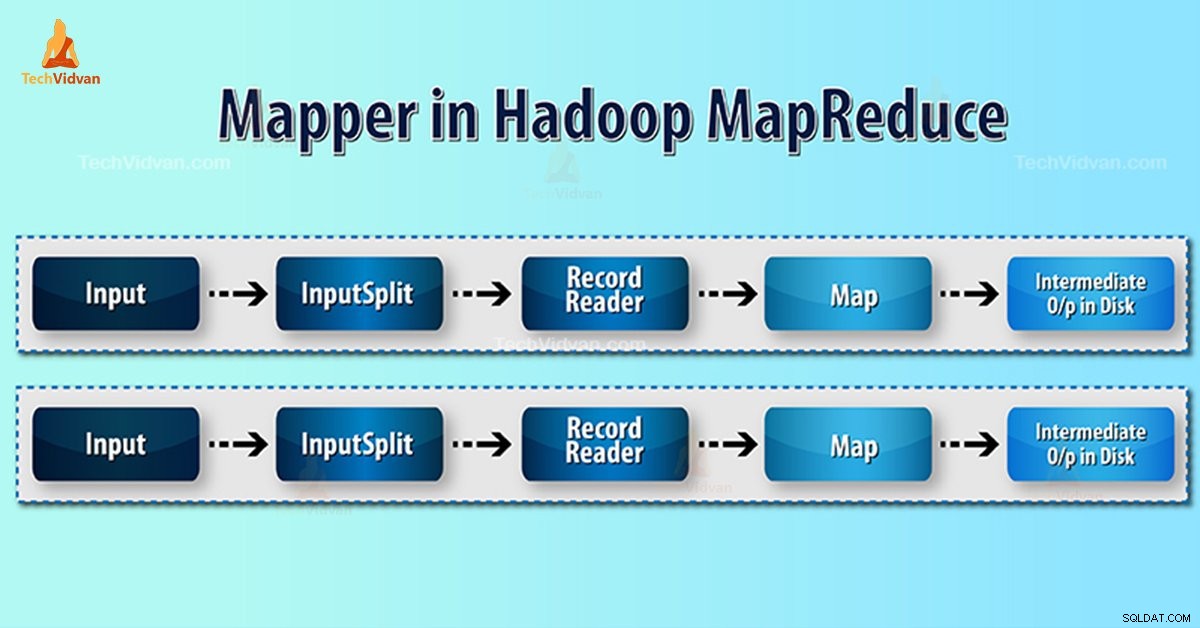
Mapeador Hadoop processa o registro de entrada produzido pelo RecordReader e gera pares de valores-chave intermediários. A saída intermediária é completamente diferente do par de entrada.
A saída do mapeador é a coleção completa de pares chave-valor. Antes de escrever a saída para cada tarefa do mapeador, o particionamento da saída ocorre com base na chave. Assim, o particionamento especifica que todos os valores de cada chave são agrupados.
O Hadoop MapReduce gera uma tarefa de mapa para cada InputSplit.
O Hadoop MapReduce só entende pares de dados de chave-valor. Portanto, antes de enviar dados para o mapeador, a estrutura do Hadoop deve converter os dados no par chave-valor.
Como o par de valores-chave é gerado no Hadoop?
Como entendemos o que é mapeador no hadoop, agora vamos discutir como o Hadoop gera o par chave-valor?
- Divisão de entrada – É a representação lógica dos dados gerados pelo InputFormat. No programa MapReduce, descreve uma unidade de trabalho que contém uma única tarefa de mapa.
- Leitor de registros- Ele se comunica com o inputSplit. E, em seguida, converte os dados em pares de valores-chave adequados para leitura pelo Mapeador. RecordReader por padrão usa TextInputFormat para converter dados no par chave-valor.
Processo do Mapeador no Hadoop MapReduce
Divisão de entrada converte a representação física dos blocos em lógica para o Mapeador. Por exemplo, para ler o arquivo de 100 MB, serão necessários 2 InputSplit. Para cada bloco, a estrutura cria um InputSplit. Cada InputSplit cria um mapeador.
MapReduce InputSplit nem sempre depende do número de blocos de dados . Podemos alterar o número de uma divisão definindo a propriedade mapred.max.split.size durante a execução do trabalho.
MapReduce RecordReader é responsável por ler/converter dados em pares chave-valor até o final do arquivo. RecordReader atribui deslocamento de Byte para cada linha presente no arquivo.
Em seguida, o Mapper recebe esse par de chaves. Mapper produz a saída intermediária (pares chave-valor que são compreensíveis para reduzir).
Quantas tarefas de mapa no Hadoop?
O número de tarefas de mapa depende do número total de blocos dos arquivos de entrada. No mapa MapReduce, o nível certo de paralelismo parece estar em torno de 10-100 mapas/nó. Mas há 300 mapas para tarefas de mapa de luz da CPU.
Por exemplo, temos um tamanho de bloco de 128 MB. E esperamos 10 TB de dados de entrada. Assim, produz 82.000 mapas. Portanto, o número de mapas depende de InputFormat.
Mapeador =(tamanho total dos dados)/ (tamanho da divisão de entrada)
Exemplo – o tamanho dos dados é de 1 TB. O tamanho da divisão de entrada é de 100 MB.
Mapeador =(1000*1000)/100 =10.000
Conclusão
Portanto, o Mapper no Hadoop pega um conjunto de dados e o converte em outro conjunto de dados. Assim, ele quebra elementos individuais em tuplas (pares chave/valor).
Espero que você goste deste bloco, se você tiver alguma dúvida sobre o mapeador do Hadoop, então deixe um comentário em uma seção abaixo. Ficaremos felizes em resolvê-los.



