Melhorar o desempenho do sistema, especialmente para estruturas de computador, requer um processo de obtenção de uma boa visão geral do desempenho. Esse processo é geralmente chamado de monitoramento. O monitoramento é uma parte essencial do gerenciamento de banco de dados e as informações detalhadas de desempenho do seu MongoDB não apenas ajudarão você a avaliar seu estado funcional; mas também dar uma pista sobre anomalias, o que é útil ao fazer a manutenção. É essencial identificar comportamentos incomuns e corrigi-los antes que se transformem em falhas mais graves.
Alguns dos tipos de falhas que podem surgir são...
- Atraso ou lentidão
- Inadequação de recursos
- Solução do sistema
O monitoramento geralmente é centrado na análise de métricas. Algumas das principais métricas que você deseja monitorar incluem...
- Desempenho do banco de dados
- Utilização de recursos (uso da CPU, memória disponível e uso da rede)
- Contrastes emergentes
- Saturação e limitação dos recursos
- Operações de rendimento
Neste blog vamos discutir, em detalhes, essas métricas e ver as ferramentas disponíveis do MongoDB (como utilitários e comandos). Também veremos outras ferramentas de software como Pandora, FMS Open Source e Robo 3T. Para simplificar, vamos usar o software Robo 3T neste artigo para demonstrar as métricas.
Desempenho do banco de dados
A primeira e mais importante coisa a verificar em um banco de dados é seu desempenho geral, por exemplo, se o servidor está ativo ou não. Se você executar este comando db.serverStatus() em um banco de dados no Robo 3T, você verá esta informação mostrando o estado do seu servidor.
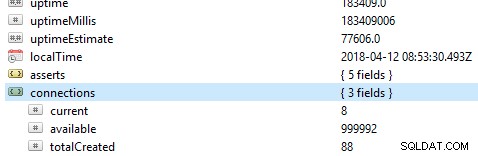

Conjuntos de réplicas
O conjunto de réplicas é um grupo de processos mongod que mantêm o mesmo conjunto de dados. Se você estiver usando conjuntos de réplicas especialmente no modo de produção, os logs de operação fornecerão uma base para o processo de replicação. Todas as operações de gravação são rastreadas usando nós, que é um nó primário e um nó secundário, que armazenam uma coleção de tamanho limitado. No nó primário, as operações de gravação são aplicadas e processadas. No entanto, se o nó primário falhar antes de serem copiados para os logs de operação, a gravação secundária será feita, mas, nesse caso, os dados poderão não ser replicados.
Principais métricas para ficar de olho...
Atraso de replicação
Isso define até que ponto o nó secundário está atrás do nó primário. Um estado ideal requer que o intervalo seja o menor possível. Em um sistema operacional normal, esse atraso é estimado em 0. Se a lacuna for muito grande, a integridade dos dados será comprometida assim que o nó secundário for promovido a primário. Nesse caso, você pode definir um limite, por exemplo, 1 minuto, e se for excedido, um alerta é definido. Causas comuns de grande atraso de replicação incluem...
- Fragmentos que podem ter uma capacidade de gravação insuficiente, o que geralmente está associado à saturação de recursos.
- O nó secundário está fornecendo dados a uma taxa mais lenta do que o nó primário.
- Os nós também podem ser impedidos de alguma forma de se comunicar, possivelmente devido a uma rede ruim.
- As operações no nó primário também podem ser mais lentas, bloqueando a replicação. Se isso acontecer, você pode executar os seguintes comandos:
- db.getProfilingLevel():se você obtiver um valor de 0, então suas operações de banco de dados são ótimas.
Se o valor for 1, então ele corresponde a operações lentas que podem ser consequentemente devido a consultas lentas. - db.getProfilingStatus():neste caso verificamos o valor de slowms, por padrão é 100ms. Se o valor for maior que isso, você pode estar tendo operações de gravação pesadas no primário ou recursos inadequados no secundário. Para resolver isso, você pode dimensionar o secundário para que ele tenha tantos recursos quanto o primário.
- db.getProfilingLevel():se você obtiver um valor de 0, então suas operações de banco de dados são ótimas.
Cursores
Se você fizer uma solicitação de leitura, por exemplo, localizar, será fornecido um cursor que é um ponteiro para o conjunto de dados do resultado. Se você executar este comando db.serverStatus() e navegar até o objeto de métricas e então o cursor, você verá isso…

Nesse caso, a propriedade cursor.timeOut foi atualizada incrementalmente para 9 porque havia 9 conexões que morreram sem fechar o cursor. A consequência é que ele permanecerá aberto no servidor e, portanto, consumindo memória, a menos que seja colhido pela configuração padrão do MongoDB. Um alerta para você deve estar identificando cursores não ativos e colhendo-os para economizar na memória. Você também pode evitar cursores sem tempo limite porque eles geralmente retêm recursos, diminuindo assim o desempenho do sistema interno. Isso pode ser feito definindo o valor da propriedade cursor.open.noTimeout para um valor de 0.
Diário
Considerando o mecanismo de armazenamento WiredTiger, antes que os dados sejam gravados, eles são gravados nos arquivos do disco. Isso é conhecido como journaling. O registro no diário garante a disponibilidade e a durabilidade dos dados em um evento de falha a partir do qual uma recuperação pode ser realizada.
Para fins de recuperação, geralmente usamos pontos de verificação (especialmente para o sistema de armazenamento WiredTiger) para recuperar do último ponto de verificação. No entanto, se o MongoDB for encerrado inesperadamente, usaremos a técnica de journaling para recuperar quaisquer dados que foram processados ou fornecidos após o último checkpoint.
O registro no diário não deve ser desativado no primeiro caso, pois leva apenas 60 segundos para criar um novo ponto de verificação. Portanto, se ocorrer uma falha, o MongoDB pode reproduzir o diário para recuperar os dados perdidos nesses segundos.
O registro no diário geralmente restringe o intervalo de tempo desde quando os dados são aplicados à memória até que sejam duráveis no disco. O objeto storage.journal tem uma propriedade que descreve a frequência de confirmação, ou seja, commitIntervalMs que geralmente é definido como um valor de 100ms para WiredTiger. Ajustá-lo para um valor mais baixo melhorará a gravação frequente de gravações, reduzindo assim as instâncias de perda de dados.
Desempenho de bloqueio
Isso pode ser causado por várias solicitações de leitura e gravação de muitos clientes. Quando isso acontece, é necessário manter a consistência e evitar conflitos de gravação. Para conseguir isso, o MongoDB usa o bloqueio de multigranularidade, que permite que as operações de bloqueio ocorram em diferentes níveis, como global, banco de dados ou nível de coleção.
Se você tiver padrões de design de esquema ruins, ficará vulnerável a bloqueios mantidos por longos períodos. Isso geralmente ocorre ao fazer duas ou mais operações de gravação diferentes em um único documento na mesma coleção, com a consequência de bloquear uma à outra. Para o mecanismo de armazenamento WiredTiger, podemos usar o sistema de tickets onde as solicitações de leitura ou gravação vêm de algo como uma fila ou thread.
Por padrão, o número simultâneo de operações de leitura e gravação é definido pelos parâmetros wiredTigerConcurrentWriteTransactions e wiredTigerConcurrentReadTransactions, ambos definidos com um valor de 128.
Se você dimensionar esse valor muito alto, acabará sendo limitado pelos recursos da CPU. Para aumentar as operações de taxa de transferência, seria aconselhável dimensionar horizontalmente fornecendo mais shards.
Vários noves Torne-se um DBA do MongoDB - Trazendo o MongoDB para a produçãoSaiba mais sobre o que você precisa saber para implantar, monitorar, gerenciar e dimensionar o MongoDBBaixe gratuitamente
Utilização de Recursos
Isso geralmente descreve o uso de recursos disponíveis, como capacidade da CPU/taxa de processamento e RAM. O desempenho, especialmente para a CPU, pode mudar drasticamente de acordo com cargas de tráfego incomuns. Coisas para verificar incluem...
- Número de conexões
- Armazenamento
- Cache
Número de conexões
Se o número de conexões for maior do que o sistema de banco de dados pode manipular, haverá muitas filas. Consequentemente, isso sobrecarregará o desempenho do banco de dados e fará com que sua configuração seja executada lentamente. Esse número pode resultar em problemas de driver ou até mesmo complicações com seu aplicativo.
Se você monitorar um determinado número de conexões por algum período e perceber que esse valor atingiu o pico, é sempre uma boa prática definir um alerta se a conexão exceder esse número.
Se o número estiver ficando muito alto, você pode aumentar a escala para atender a esse aumento. Para fazer isso, você precisa saber o número de conexões disponíveis em um determinado período, caso contrário, se as conexões disponíveis não forem suficientes, as solicitações não serão tratadas em tempo hábil.
Por padrão, o MongoDB oferece suporte para até 1 milhão de conexões. Com seu monitoramento, sempre garanta que as conexões atuais nunca cheguem muito perto desse valor. Você pode verificar o valor no objeto de conexões.

Armazenamento
Cada linha e registro de dados no MongoDB é chamado de documento. Os dados do documento estão no formato BSON. Em um determinado banco de dados, se você executar o comando db.stats(), esses dados serão apresentados.
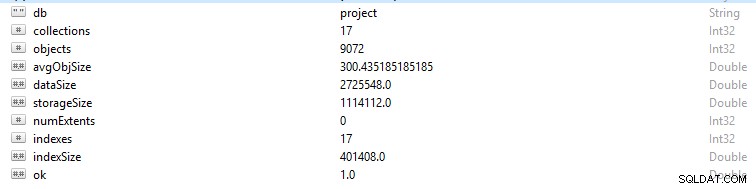
- StorageSize define o tamanho de todas as extensões de dados no banco de dados.
- IndexSize descreve o tamanho de todos os índices criados nesse banco de dados.
- dataSize é uma medida do espaço total ocupado pelos documentos no banco de dados.
Às vezes, você pode ver uma mudança na memória, especialmente se muitos dados foram excluídos. Nesse caso, você deve configurar um alerta para garantir que não foi devido a atividade maliciosa.
Às vezes, o tamanho geral do armazenamento pode aumentar enquanto o gráfico de tráfego do banco de dados é constante e, nesse caso, você deve verificar a estrutura do aplicativo ou do banco de dados para evitar duplicações, se não for necessário.
Assim como a memória geral de um computador, o MongoDB também possui caches nos quais os dados ativos são armazenados temporariamente. No entanto, uma operação pode solicitar dados que não estão nesta memória ativa, fazendo assim uma solicitação do armazenamento em disco principal. Essa solicitação ou situação é chamada de falha de página. As solicitações de falha de página têm a limitação de levar mais tempo para serem executadas e podem ser prejudiciais quando ocorrem com frequência. Para evitar esse cenário, certifique-se de que o tamanho de sua RAM seja sempre suficiente para atender aos conjuntos de dados com os quais você está trabalhando. Você também deve garantir que não haja redundância de esquema ou índices desnecessários.
Cache
Cache é um item de armazenamento de dados temporal para dados acessados com frequência. No WiredTiger, o cache do sistema de arquivos e o cache do mecanismo de armazenamento são frequentemente empregados. Certifique-se sempre de que seu conjunto de trabalho não ultrapasse o cache disponível, caso contrário, as falhas de página aumentarão em número, causando alguns problemas de desempenho.
Em algum momento, você pode decidir modificar suas operações frequentes, mas as alterações às vezes não são refletidas no cache. Esses dados não modificados são chamados de “Dados Sujos”. Ele existe porque ainda não foi liberado para o disco. Afunilamentos ocorrerão se a quantidade de “Dados Sujos” crescer para algum valor médio definido pela gravação lenta no disco. Adicionar mais fragmentos ajudará a reduzir esse número.
Utilização da CPU
Indexação imprópria, estrutura de esquema ruim e consultas projetadas hostis exigirão mais atenção da CPU, portanto, obviamente, aumentarão sua utilização.
Operações de rendimento
Em grande medida, obter informações suficientes sobre essas operações pode permitir evitar contratempos consequentes, como erros, saturação de recursos e complicações funcionais.
Você deve sempre observar o número de operações de leitura e gravação no banco de dados, ou seja, uma visão de alto nível das atividades do cluster. Saber o número de operações geradas para as solicitações permitirá calcular a carga que o banco de dados deve manipular. A carga pode, então, ser tratada aumentando ou expandindo seu banco de dados; dependendo do tipo de recursos que você tem. Isso permite que você avalie facilmente a proporção do quociente em que as solicitações estão se acumulando em relação à taxa na qual estão sendo processadas. Além disso, você pode otimizar suas consultas adequadamente para melhorar o desempenho.
Para verificar o número de operações de leitura e escrita, execute este comando db.serverStatus(), então navegue até o objeto locks.global, o valor da propriedade r representa o número de pedidos de leitura e w número de gravações.
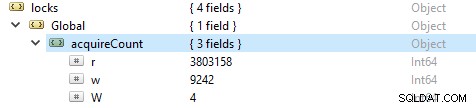
Mais frequentemente, as operações de leitura são mais do que as operações de gravação. As métricas do cliente ativo são relatadas em globalLock.
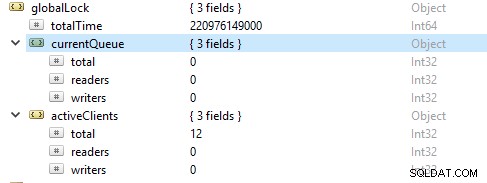
Saturação e limitação de recursos
Às vezes, o banco de dados pode não acompanhar a taxa de gravação e leitura, conforme retratado por um número crescente de solicitações enfileiradas. Nesse caso, você precisa escalar seu banco de dados fornecendo mais shards para permitir que o MongoDB resolva as solicitações com rapidez suficiente.
Contrastes emergentes
Os arquivos de log do MongoDB sempre fornecem uma visão geral sobre as exceções de declaração retornadas. Este resultado lhe dará uma pista sobre as possíveis causas dos erros. Se você executar o comando db.serverStatus(), alguns dos alertas de erro que você observará incluem:

- Declarações regulares:são resultado de uma falha de operação. Por exemplo, em um esquema, se um valor de string for fornecido a um campo inteiro, resultando em falha na leitura do documento BSON.
- Declarações de aviso:geralmente são alertas sobre algum problema, mas não estão tendo muito impacto em sua operação. Por exemplo, ao atualizar seu MongoDB, você pode ser alertado usando funções obsoletas.
- Afirmações de mensagem:elas são resultado de exceções internas do servidor, como rede lenta ou se o servidor não estiver ativo.
- Asserções do usuário:como asserções regulares, esses erros surgem ao executar um comando, mas geralmente são retornados ao cliente. Por exemplo, se houver chaves duplicadas, espaço em disco inadequado ou nenhum acesso para gravar no banco de dados. Você optará por verificar seu aplicativo para corrigir esses erros.



