O balanceamento de carga de banco de dados distribui solicitações simultâneas de clientes para vários servidores de banco de dados para reduzir a quantidade de carga em qualquer servidor único. Isso pode melhorar drasticamente o desempenho do seu banco de dados. Felizmente, o MongoDB pode lidar com solicitações de vários clientes para ler e gravar os mesmos dados simultaneamente por padrão. Ele usa alguns mecanismos de controle de simultaneidade e protocolos de bloqueio para garantir a consistência dos dados o tempo todo.
Dessa forma, o MongoDB também garante que todos os clientes tenham uma visão consistente dos dados a qualquer momento. Devido a esse recurso interno de lidar com solicitações de vários clientes, você não precisa se preocupar em adicionar um balanceador de carga externo em seus servidores MongoDB. No entanto, se você ainda deseja melhorar o desempenho do seu banco de dados usando o balanceamento de carga, aqui estão algumas maneiras de fazer isso.
Escalonamento vertical do MongoDB
Em termos simples, o dimensionamento vertical significa adicionar mais recursos ao seu servidor para lidar com o carregamento. Como todos os sistemas de banco de dados, o MongoDB prefere mais capacidade de RAM e E/S. Essa é a maneira mais simples de aumentar o desempenho do MongoDB sem distribuir a carga entre vários servidores. O dimensionamento vertical do banco de dados MongoDB geralmente inclui o aumento da capacidade da CPU ou do disco e o aumento da taxa de transferência (operações de E/S). Ao adicionar mais recursos, seu servidor mongo se torna mais capaz de lidar com várias solicitações de clientes. Assim, melhor balanceamento de carga para seu banco de dados.
A desvantagem de usar essa abordagem é a limitação técnica de adicionar recursos a qualquer sistema único. Além disso, todos os provedores de nuvem têm limitações para adicionar novas configurações de hardware. A outra desvantagem dessa abordagem é um único ponto de falha. Nesta abordagem, todos os seus dados estão sendo armazenados em um único sistema, o que pode levar à perda permanente de seus dados.
Escalonamento horizontal do MongoDB
A escala horizontal refere-se a dividir seu banco de dados em pedaços e armazená-los em vários servidores. A principal vantagem dessa abordagem é que você pode adicionar servidores adicionais rapidamente para aumentar o desempenho do banco de dados com tempo de inatividade zero. O MongoDB fornece dimensionamento horizontal por meio de fragmentação. O sharding do MongoDB oferece capacidade adicional para distribuir a carga de gravação entre vários servidores (shards). Aqui, cada fragmento pode ser visto como um banco de dados independente e a coleção de todos os fragmentos pode ser vista como um grande banco de dados lógico. O sharding permite que seu MongoDB distribua os dados entre vários servidores para lidar com solicitações de clientes simultâneos com eficiência. Portanto, aumenta a taxa de transferência de leitura e gravação do seu banco de dados.
Fragmentação do MongoDB
Um fragmento pode ser uma única instância do mongod ou um conjunto de réplicas que contém o subconjunto do banco de dados fragmentado do mongo. Você pode converter shard em conjunto de réplicas para garantir alta disponibilidade de dados e redundância.
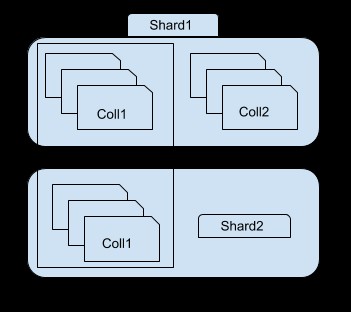
Como você pode ver na imagem acima, o fragmento 1 contém um subconjunto de coleção 1 e coleção2 inteira, enquanto o fragmento 2 contém apenas outro subconjunto da coleção1. Você pode acessar cada fragmento usando a instância mongos. Por exemplo, se você se conectar à instância shard1, poderá ver/acessar apenas um subconjunto de collection1.
Mongos
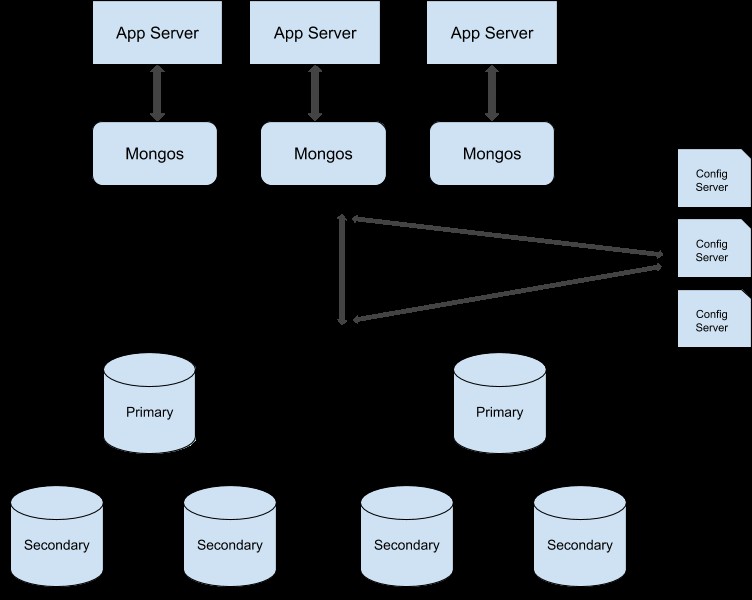
Mongos é o roteador de consulta que fornece acesso ao cluster fragmentado para aplicativos cliente. Você pode ter várias instâncias do mongos para melhor balanceamento de carga. Por exemplo, em seu cluster de produção, você pode ter uma instância do mongos para cada servidor de aplicativos. Agora aqui você pode usar um balanceador de carga externo, que redirecionará a solicitação do seu servidor de aplicativos para a instância mongos apropriada. Ao adicionar essas configurações ao seu servidor de produção, certifique-se de que a conexão de qualquer cliente sempre se conecte à mesma instância do mongos todas as vezes, pois alguns recursos do mongo, como cursores, são específicos da instância do mongos.
Servidores de configuração
Os servidores de configuração armazenam as definições de configuração e metadados sobre seu cluster. A partir do MongoDB versão 3.4, você precisa implantar servidores de configuração como um conjunto de réplicas. Se você estiver habilitando a fragmentação em um ambiente de produção, é obrigatório usar três servidores de configuração separados, cada um em máquinas diferentes.
Você pode seguir este guia para converter seu cluster de conjunto de réplicas em um cluster fragmentado. Aqui está a ilustração de exemplo do cluster de produção fragmentado:
Balanceamento de carga MongoDB usando replicação
Às vezes, a replicação do MongoDB pode ser usada para lidar com mais tráfego de clientes e reduzir a carga no servidor primário. Para fazer isso, você pode instruir os clientes a ler dos secundários em vez do servidor primário. Isso pode reduzir a quantidade de carga no servidor primário, pois todas as solicitações de leitura provenientes de clientes serão tratadas por servidores secundários, e o servidor primário cuidará apenas das solicitações de gravação.
A seguir está o comando para definir a preferência de leitura como secundária:
db.getMongo().setReadPref('secondary')Você também pode especificar algumas tags para direcionar secundários específicos ao lidar com as consultas de leitura.
db.getMongo().setReadPref(
"secondary", [
{ "datacenter": "APAC" },
{ "region": "East"},
{}
])Aqui, o MongoDB tentará encontrar o nó secundário com o valor da tag do datacenter como APAC. Se encontrado, o Mongo atenderá as solicitações de leitura de todos os secundários com a tag datacenter:“APAC”. Se não for encontrado, o Mongo tentará encontrar os secundários com a região da tag:“Leste”. Se ainda nenhum secundário for encontrado, {} funcionará como o caso padrão, e o Mongo atenderá às solicitações de qualquer secundário qualificado.
No entanto, essa abordagem para balanceamento de carga não é recomendada para aumentar a taxa de transferência de leitura. Porque qualquer modo de preferência de leitura diferente do primário pode retornar dados antigos em caso de atualizações de gravação recentes no servidor primário. Normalmente, o servidor primário levará algum tempo para lidar com as solicitações de gravação e propagar as alterações para os servidores secundários. Durante esse período, se alguém solicitar a operação de leitura nos mesmos dados, o servidor secundário retornará dados obsoletos, pois não estão sincronizados com o servidor primário. Você pode usar essa abordagem se seu aplicativo tiver operações de leitura pesadas em comparação com operações de gravação.
Conclusão
Como o MongoDB pode lidar sozinho com solicitações simultâneas, não há necessidade de adicionar um balanceador de carga em seu cluster MongoDB. Para balancear a carga das solicitações do cliente, você pode escolher o dimensionamento vertical ou o dimensionamento horizontal, pois não é aconselhável usar secundários para dimensionar suas operações de leitura e gravação. A escala vertical pode atingir os limites técnicos, conforme discutido acima. Portanto, é adequado para aplicações de pequena escala. Para grandes aplicativos, o dimensionamento horizontal por meio de fragmentação é a melhor abordagem para balancear a carga das operações de leitura e gravação.



