Vários JOINS em uma única consulta
Múltiplos JOINS são normalmente associados a várias coleções, mas você deve ter um entendimento básico de como o INNER JOIN funciona (veja meus posts anteriores sobre este tópico). Além das nossas duas coleções que tínhamos antes; unidades e alunos, vamos adicionar uma terceira coleção e rotulá-la de esportes. Preencha a coleção de esportes com os dados abaixo:
{
"_id" : 1,"tournamentsPlayed" : 6,
"gamesParticipated" : [{"hockey" : "midfielder","football" : "stricker","handball" : "goalkeeper"}],
"sportPlaces" : ["Stafford Bridge","South Africa", "Rio Brazil"]
}
{
"_id" : 2,"tournamentsPlayed" : 3,
"gamesParticipated" : [{"hockey" : "goalkeeper","football" : "stricker", "handball" : "midfielder"}],
"sportPlaces" : ["Ukraine","India", "Argentina"]
}
{
"_id" : 3,"tournamentsPlayed" : 10,
"gamesParticipated" : [{"hockey" : "stricker","football" : "goalkeeper","tabletennis" : "doublePlayer"}],
"sportPlaces" : ["China","Korea","France"]
}Gostaríamos, por exemplo, de retornar todos os dados de um aluno com o valor do campo _id igual a 1. Normalmente, escreveríamos uma consulta para buscar o valor do campo _id da coleção de alunos e, em seguida, usaríamos o valor retornado para consultar dados nas outras duas coleções. Consequentemente, esta não será a melhor opção, especialmente se estiver envolvido um grande conjunto de documentos. Uma abordagem melhor seria usar o recurso SQL do programa Studio3T. Podemos consultar nosso MongoDB com o conceito SQL normal e, em seguida, tentar ajustar grosseiramente o código shell Mongo resultante para se adequar à nossa especificação. Por exemplo, vamos buscar todos os dados com _id igual a 1 de todas as coleções:
SELECT *
FROM students
INNER JOIN units
ON students._id = units._id
INNER JOIN sports
ON students._id = sports._id
WHERE students._id = 1;O documento resultante será:
{
"students" : {"_id" : NumberInt(1),"name" : "James Washington","age" : 15.0,"grade" : "A","score" : 10.5},
"units" : {"_id" : NumberInt(1),"grades" : {Maths" : "A","English" : "A","Science" : "A","History" : "B"}
},
"sports" : {
"_id" : NumberInt(1),"tournamentsPlayed" : NumberInt(6),
"gamesParticipated" : [{"hockey" : "midfielder", "football" : "striker","handball" : "goalkeeper"}],
"sportPlaces" : ["Stafford Bridge","South Africa","Rio Brazil"]
}
}Na guia Query code, o código MongoDB correspondente será:
db.getCollection("students").aggregate(
[{ "$project" : {"_id" : NumberInt(0),"students" : "$$ROOT"}},
{ "$lookup" : {"localField" : "students._id","from" : "units","foreignField" : "_id", "as" : "units"}},
{ "$unwind" : {"path" : "$units","preserveNullAndEmptyArrays" : false}},
{ "$lookup" : {"localField" : "students._id","from" : "sports", "foreignField" : "_id","as" : "sports"}},
{ "$unwind" : {"path" : "$sports", "preserveNullAndEmptyArrays" : false}},
{ "$match" : {"students._id" : NumberLong(1)}}
]
);Olhando para o documento retornado, pessoalmente, não estou muito feliz com a estrutura de dados, especialmente com documentos incorporados. Como você pode ver, há campos _id retornados e para as unidades podemos não precisar que o campo notas seja incorporado dentro das unidades.
Gostaríamos de ter um campo de unidades com unidades incorporadas e não quaisquer outros campos. Isso nos leva à parte da afinação grosseira. Como nas postagens anteriores, copie o código usando o ícone de cópia fornecido e vá para o painel de agregação, cole o conteúdo usando o ícone de colar.
Primeiramente, o operador $match deve ser o primeiro estágio, então mova-o para a primeira posição e tenha algo assim:
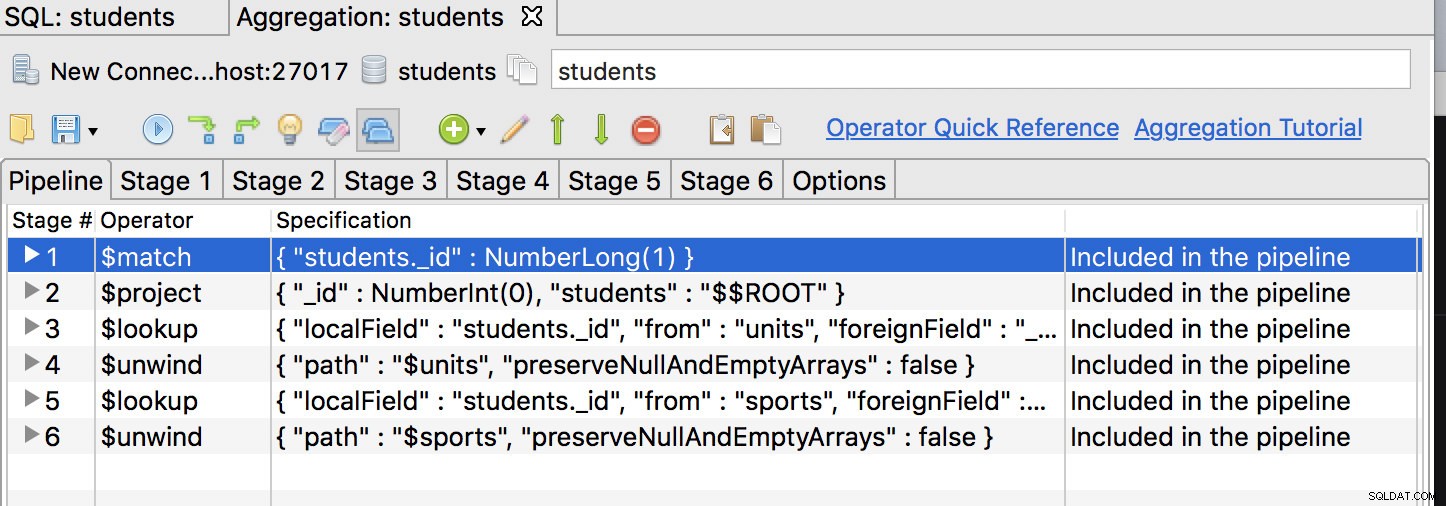
Clique na guia do primeiro estágio e modifique a consulta para:
{
"_id" : NumberLong(1)
}Em seguida, precisamos modificar ainda mais a consulta para remover muitos estágios de incorporação de nossos dados. Para isso, adicionamos novos campos para capturar dados para os campos que queremos eliminar, ou seja:
db.getCollection("students").aggregate(
[
{ "$project" : { "_id" : NumberInt(0), "students" : "$$ROOT"}},
{ "$match" : {"students._id" : NumberLong(1)}},
{ "$lookup" : { "localField" : "students._id", "from" : "units","foreignField" : "_id", "as" : "units"}},
{ "$addFields" : { "_id": "$students._id","units" : "$units.grades"}},
{ "$unwind" : { "path" : "$units", "preserveNullAndEmptyArrays" : false}},
{ "$lookup" : {"localField" : "students._id", "from" : "sports", "foreignField" : "_id", "as" : "sports"}},
{ "$unwind" : { "path" : "$sports","preserveNullAndEmptyArrays" : false}},
{ "$project" : {"sports._id" : 0.0}}
]
);Como você pode ver, no processo de ajuste fino, introduzimos novas unidades de campo que substituirão o conteúdo do pipeline de agregação anterior com notas como um campo incorporado. Além disso, criamos um campo _id para indicar que os dados eram em relação a algum documento das coleções com o mesmo valor. A última etapa do projeto $ é remover o campo _id no documento de esportes para que possamos ter os dados apresentados de forma organizada como abaixo.
{ "_id" : NumberInt(1),
"students" : {"name" : "James Washington", "age" : 15.0, "grade" : "A", "score" : 10.5},
"units" : {"Maths" : "A","English" : "A", "Science" : "A","History" : "B"},
"sports" : {
"tournamentsPlayed" : NumberInt(6),
"gamesParticipated" : [{"hockey" : "midfielder","football" : "striker","handball" : "goalkeeper"}],
"sportPlaces" : ["Stafford Bridge", "South Africa", "Rio Brazil"]
}
}Também podemos restringir quais campos devem ser retornados do ponto de vista SQL. Por exemplo podemos retornar o nome do aluno, as unidades que este aluno está fazendo e o número de torneios jogados usando vários JOINS com o código abaixo:
SELECT students.name, units.grades, sports.tournamentsPlayed
FROM students
INNER JOIN units
ON students._id = units._id
INNER JOIN sports
ON students._id = sports._id
WHERE students._id = 1;Isso não nos dá o resultado mais adequado. Então, como de costume, copie e cole no painel de agregação. Ajustamos com o código abaixo para obter o resultado apropriado.
db.getCollection("students").aggregate(
[
{ "$project" : { "_id" : NumberInt(0), "students" : "$$ROOT"}},
{ "$match" : {"students._id" : NumberLong(1)}},
{ "$lookup" : { "localField" : "students._id", "from" : "units","foreignField" : "_id", "as" : "units"}},
{ "$addFields" : {"units" : "$units.grades"}},
{ "$unwind" : { "path" : "$units", "preserveNullAndEmptyArrays" : false}},
{ "$lookup" : {"localField" : "students._id", "from" : "sports", "foreignField" : "_id", "as" : "sports"}},
{ "$unwind" : { "path" : "$sports","preserveNullAndEmptyArrays" : false}},
{ "$project" : {"name" : "$students.name", "grades" : "$units.grades", "tournamentsPlayed" : "$sports.tournamentsPlayed"}
}}
]
);Este resultado de agregação do conceito SQL JOIN nos dá uma estrutura de dados organizada e apresentável mostrada abaixo.
{
"name" : "James Washington",
"grades" : {"Maths" : "A", "English" : "A", "Science" : "A", "History" : "B"},
"tournamentsPlayed" : NumberInt(6)
}Bem simples, certo? Os dados são bastante apresentáveis como se estivessem armazenados em uma única coleção como um único documento.
LEFT OUTER JOIN
O LEFT OUTER JOIN normalmente é usado para mostrar documentos que não estão de acordo com o relacionamento mais retratado. O conjunto resultante de uma junção LEFT OUTER contém todas as linhas de ambas as coleções que atendem aos critérios da cláusula WHERE, da mesma forma que um conjunto de resultados INNER JOIN. Além disso, quaisquer documentos da coleção da esquerda que não tenham documentos correspondentes na coleção da direita também serão incluídos no conjunto de resultados. Os campos selecionados da tabela do lado direito retornarão valores NULL. No entanto, quaisquer documentos na coleção direita, que não tenham critérios correspondentes da coleção esquerda, não serão retornados.
Dê uma olhada nessas duas coleções:
alunos
{"_id" : 1,"name" : "James Washington","age" : 15.0,"grade" : "A","score" : 10.5}
{"_id" : 2,"name" : "Clinton Ariango","age" : 14.0,"grade" : "B","score" : 7.5}
{"_id" : 4,"name" : "Mary Muthoni","age" : 16.0,"grade" : "A","score" : 11.5}Unidades
{"_id" : 1,"Maths" : "A","English" : "A","Science" : "A","History" : "B"}
{"_id" : 2,"Maths" : "B","English" : "B","Science" : "A","History" : "B"}
{"_id" : 3,"Maths" : "A","English" : "A","Science" : "A","History" : "A"}Na coleção de alunos não temos o valor do campo _id definido como 3, mas na coleção de unidades temos. Da mesma forma, não há valor de campo _id 4 na coleção de unidades. Se usarmos a coleção de alunos como nossa opção esquerda na abordagem JOIN com a consulta abaixo:
SELECT *
FROM students
LEFT OUTER JOIN units
ON students._id = units._idCom este código teremos o seguinte resultado:
{
"students" : {"_id" : 1,"name" : "James Washington","age" : 15,"grade" : "A","score" : 10.5},
"units" : {"_id" : 1,"grades" : {"Maths" : "A","English" : "A", "Science" : "A","History" : "B"}}
}
{
"students" : {"_id" : 2,"name" : "Clinton Ariango", "age" : 14,"grade" : "B", "score" : 7.5 }
}
{
"students" : {"_id" : 3,"name" : "Mary Muthoni","age" : 16,"grade" : "A","score" : 11.5},
"units" : {"_id" : 3,"grades" : {"Maths" : "A","English" : "A","Science" : "A","History" : "A"}}
}O segundo documento não possui o campo de unidades porque não havia documento correspondente na coleção de unidades. Para esta consulta SQL, o código Mongo correspondente será
db.getCollection("students").aggregate(
[
{
"$project" : {"_id" : NumberInt(0), "students" : "$$ROOT"}},
{
"$lookup" : {"localField" : "students._id", "from" : "units", "foreignField" : "_id", "as" : "units"}
},
{
"$unwind" : { "path" : "$units", "preserveNullAndEmptyArrays" : true}
}
]
);É claro que aprendemos sobre o ajuste fino, para que você possa prosseguir e reestruturar o pipeline de agregação para se adequar ao resultado final desejado. SQL é uma ferramenta muito poderosa no que diz respeito ao gerenciamento de banco de dados. É um assunto amplo por si só, você também pode tentar usar as cláusulas IN e GROUP BY para obter o código correspondente para o MongoDB e ver como ele funciona.
Conclusão
Acostumar-se a uma nova tecnologia (de banco de dados) além daquela com a qual você está acostumado a trabalhar pode levar muito tempo. Bancos de dados relacionais ainda são mais comuns do que os não relacionais. No entanto, com a introdução do MongoDB, as coisas mudaram e as pessoas gostariam de aprender o mais rápido possível devido ao seu poderoso desempenho associado.
Aprender MongoDB do zero pode ser um pouco tedioso, mas podemos usar o conhecimento de SQL para manipular dados no MongoDB, obter o código relativo do MongoDB e ajustá-lo para obter os resultados mais apropriados. Uma das ferramentas disponíveis para melhorar isso é o Studio 3T. Ele oferece dois recursos importantes que facilitam a operação de dados complexos, a saber:recurso de consulta SQL e o editor de agregação. As consultas de ajuste fino não apenas garantirão o melhor resultado, mas também melhorarão o desempenho em termos de economia de tempo.



