O que é indexação?
A indexação é um conceito importante no mundo dos bancos de dados. A principal vantagem de criar índice em qualquer campo é o acesso mais rápido aos dados. Otimiza o processo de busca e acesso ao banco de dados. Considere este exemplo para entender isso.
Quando qualquer usuário solicita uma linha específica do banco de dados, o que o sistema de banco de dados fará? Ele começará da primeira linha e verificará se essa é a linha que o usuário deseja? Se sim, retorne essa linha, caso contrário, continue procurando a linha até o final.
Geralmente, quando você define um índice em um campo específico, o sistema de banco de dados cria uma lista ordenada do valor desse campo e a armazena em uma tabela diferente. Cada entrada desta tabela apontará para os valores correspondentes na tabela original. Portanto, quando o usuário tentar pesquisar qualquer linha, ele primeiro procurará o valor na tabela de índice usando o algoritmo de pesquisa binária e retornará o valor correspondente da tabela original. Esse processo levará menos tempo porque estamos usando a pesquisa binária em vez da pesquisa linear.
Neste artigo, vamos nos concentrar na Indexação do MongoDB e entender como criar e usar índices no MongoDB.
Como criar um índice na coleção do MongoDB?
Para criar um índice usando o shell do Mongo, você pode usar esta sintaxe:
db.collection.createIndex( <key and index type specification>, <options> )Exemplo:
Para criar um índice no campo de nome na coleção myColl:
db.myColl.createIndex( { name: -1 } )Tipos de índices do MongoDB
-
Índice _id padrão
Este é o índice padrão que será criado pelo MongoDB quando você criar uma nova coleção. Se você não especificar nenhum valor para este campo, _id será a chave primária por padrão para sua coleção para que um usuário não possa inserir dois documentos com os mesmos valores de campo _id. Você não pode remover este índice do campo _id.
-
Índice de campo único
Você pode usar esse tipo de índice quando quiser criar um novo índice em qualquer campo que não seja o campo _id.
Exemplo:
db.myColl.createIndex( { name: 1 } )
Isso criará um índice ascendente de chave única no campo de nome na coleção myColl
-
Índice Composto
Você também pode criar um índice em vários campos usando índices compostos. Para este índice, importa a ordem dos campos em que são definidos no índice. Considere este exemplo:
db.myColl.createIndex({ name: 1, score: -1 })
Esse índice primeiro classificará a coleção por nome em ordem crescente e, em seguida, para cada valor de nome, classificará por valores de pontuação em ordem decrescente.
-
Índice multichave
Esse índice pode ser usado para indexar dados de matriz. Se algum campo em uma coleção tiver um array como seu valor, você poderá usar esse índice que criará entradas de índice separadas para cada elemento no array. Se o campo indexado for um array, o MongoDB criará automaticamente o índice Multikey nele.
Considere este exemplo:
{ ‘userid’: 1, ‘name’: ‘mongo’, ‘addr’: [ {zip: 12345, ...}, {zip: 34567, ...} ] }
Você pode criar um índice Multikey no campo addr emitindo este comando no shell do Mongo.
db.myColl.createIndex({ addr.zip: 1 }) -
Índice geoespacial
Suponha que você armazenou algumas coordenadas na coleção do MongoDB. Para criar índices neste tipo de campos (que possuem dados geoespaciais), você pode usar um índice geoespacial. O MongoDB suporta dois tipos de índices geoespaciais.
-
Índice 2d:Você pode usar este índice para dados armazenados como pontos no plano 2D.
db.collection.createIndex( { <location field> : "2d" } ) -
Índice 2dsphere:Use este índice quando seus dados são armazenados como formato GeoJson ou pares de coordenadas (longitude, latitude)
db.collection.createIndex( { <location field> : "2dsphere" } ) -
-
Índice de texto
Para oferecer suporte a consultas que incluem a pesquisa de algum texto na coleção, você pode usar o índice de texto.
Exemplo:
db.myColl.createIndex( { address: "text" } ) -
Índice de hash
O MongoDB suporta fragmentação baseada em hash. O índice hash calcula o hash dos valores do campo indexado. O índice com hash é compatível com a fragmentação usando chaves fragmentadas com hash. A fragmentação com hash usa esse índice como chave de fragmentação para particionar os dados em seu cluster.
Exemplo:
db.myColl.createIndex( { _id: "hashed" } )
-
Índice exclusivo
Essa propriedade garante que não haja valores duplicados no campo indexado. Se alguma duplicata for encontrada durante a criação do índice, ele descartará essas entradas.
-
Índice Esparso
Essa propriedade garante que todas as consultas pesquisem documentos com campo indexado. Se algum documento não tiver um campo indexado, ele será descartado do conjunto de resultados.
-
Índice TTL
Esse índice é usado para excluir automaticamente os documentos de uma coleção após um intervalo de tempo específico (TTL). Isso é ideal para remover documentos de logs de eventos ou sessões de usuário.
Análise de desempenho
Considere uma coleção de notas de alunos. Tem exatamente 3.000.000 documentos nele. Não criamos nenhum índice nesta coleção. Veja esta imagem abaixo para entender o esquema.
 Documentos de amostra na coleção de pontuação
Documentos de amostra na coleção de pontuação Agora, considere esta consulta sem nenhum índice:
db.scores.find({ student: 585534 }).explain("executionStats")Esta consulta leva 1155ms para ser executada. Aqui está a saída. Procure o campo executionTimeMillis para obter o resultado.
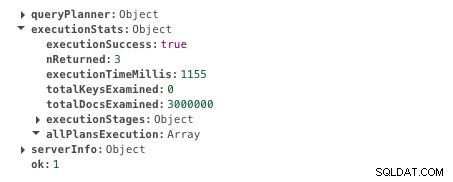 Tempo de execução sem indexação
Tempo de execução sem indexação Agora vamos criar um índice no campo do aluno. Para criar o índice, execute esta consulta.
db.scores.createIndex({ student: 1 })Agora, a mesma consulta leva 0ms.
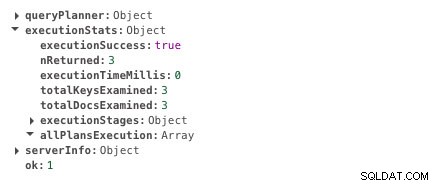 Tempo de execução com indexação
Tempo de execução com indexação Você pode ver claramente a diferença no tempo de execução. É quase instantâneo. Esse é o poder da indexação.
Conclusão
Uma dica óbvia é:Crie índices. Com base em suas consultas, você pode definir diferentes tipos de índices em suas coleções. Se você não criar índices, cada consulta verificará as coleções completas, o que leva muito tempo, tornando seu aplicativo muito lento e usa muitos recursos do seu servidor. Por outro lado, também não crie muitos índices porque criar índices desnecessários causará sobrecarga de tempo extra para todas as inserções, exclusões e atualizações. Quando você executa qualquer uma dessas operações em um campo indexado, também é necessário executar a mesma operação na árvore de índice, o que leva tempo. Os índices são armazenados na RAM, portanto, a criação de índices irrelevantes pode consumir seu espaço de RAM e diminuir a velocidade do servidor.



