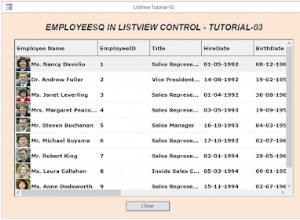
Padrão
RANGE / ROWS para FIRST_VALUE (como para qualquer outra função analítica) é BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW . Se você adicionar
IGNORE NULLS , então NULL os valores não são levados em consideração ao construir o intervalo. O
RANGE torna-se BETWEEEN UNBOUNDED PRECEDING AND CURRENT ROW EXCEPT FOR THE NULL ROWS (não é um OVER válido cláusula). Como seu
txt 's que são NULL tem id alto 's, eles são selecionados primeiro e seus intervalos estão vazios, já que não existem não NULL linhas entre eles e UNBOUNDED PRECEDING Você deve alterar
ORDER BY ou RANGE cláusula da sua consulta. Alterando
ORDER BY coloca as linhas com NULL id's ao final da janela para que um não-NULL valor (se houver) será sempre selecionado primeiro, e o RANGE certamente começará a partir desse valor:with t
as (
select 450 id, null txt , 3488 id_usr from dual union all
select 449 , null , 3488 from dual union all
select 79 , 'A' , 3488 from dual union all
select 78 , 'X' , 3488 from dual
)
select id
, txt
, id_usr
, first_value(txt) over (partition by id_usr order by NVL2(TXT, NULL, id) DESC) first_one
from t
Alterando
RANGE redefine o intervalo para incluir todos os não-NULL linhas na partição:with t
as (
select 450 id, null txt , 3488 id_usr from dual union all
select 449 , null , 3488 from dual union all
select 79 , 'A' , 3488 from dual union all
select 78 , 'X' , 3488 from dual
)
select id
, txt
, id_usr
, first_value(txt IGNORE NULLS) over (partition by id_usr order by id DESC RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) first_one
from t