A leitura confirmada é a segunda mais fraca dos quatro níveis de isolamento definidos pelo padrão SQL. No entanto, é o nível de isolamento padrão para muitos mecanismos de banco de dados, incluindo o SQL Server. Este post de uma série sobre níveis de isolamento e as propriedades ACID das transações analisa as garantias lógicas e físicas realmente fornecidas pelo isolamento de leitura confirmada.
Garantias Lógicas
O padrão SQL exige que uma transação executada sob isolamento de leitura confirmada leia somente confirmada dados. Ele expressa esse requisito proibindo o fenômeno de simultaneidade conhecido como leitura suja. Uma leitura suja ocorre quando uma transação lê dados que foram gravados por outra transação, antes que a segunda transação seja concluída. Outra maneira de expressar isso é dizer que uma leitura suja ocorre quando uma transação lê dados não confirmados.
O padrão também menciona que uma transação executada em isolamento de confirmação de leitura pode encontrar o fenômeno de simultaneidade conhecido como leituras não repetíveis e fantasmas . Embora muitos livros expliquem esses fenômenos em termos de uma transação poder ver itens de dados alterados ou novos se os dados forem relidos posteriormente, essa explicação pode reforçar o equívoco que os fenômenos de simultaneidade só podem ocorrer dentro de uma transação explícita que contém várias instruções. Isto não é assim. Uma declaração única sem uma transação explícita é tão vulnerável aos fenômenos de leitura e fantasma não repetíveis, como veremos em breve.
Isso é praticamente tudo o que o padrão tem a dizer sobre o isolamento de read commited. À primeira vista, ler apenas dados comprometidos parece uma boa garantia de comportamento sensato, mas, como sempre, o diabo está nos detalhes. Assim que você começar a procurar por possíveis brechas nesta definição, torna-se muito fácil encontrar instâncias em que nossas transações com confirmação de leitura podem não produzir os resultados esperados. Mais uma vez, discutiremos isso com mais detalhes em um momento ou dois.
Diferentes implementações físicas
Há pelo menos duas coisas que significam que o comportamento observado do nível de isolamento de leitura confirmada pode ser bem diferente em diferentes mecanismos de banco de dados. Primeiro, o requisito padrão do SQL para ler apenas dados confirmados não significa necessariamente que os dados confirmados lidos por uma transação serão os mais recentes dados comprometidos.
Um mecanismo de banco de dados tem permissão para ler uma versão confirmada de uma linha de qualquer ponto no passado , e ainda estar em conformidade com a definição padrão SQL. Vários produtos de banco de dados populares implementam o isolamento de leitura confirmada dessa maneira. Os resultados da consulta obtidos nesta implementação de isolamento de leitura confirmada podem estar arbitrariamente desatualizados , quando comparado com o estado confirmado atual do banco de dados. Abordaremos esse tópico como ele se aplica ao SQL Server na próxima postagem da série.
A segunda coisa para a qual quero chamar sua atenção é que a definição padrão SQL não impedir que uma implementação específica forneça proteções adicionais de efeito de simultaneidade além de impedir leituras sujas . O padrão apenas especifica que leituras sujas não são permitidas, não requer que outros fenômenos de simultaneidade sejam permitidos em qualquer nível de isolamento.
Para esclarecer este segundo ponto, um mecanismo de banco de dados compatível com os padrões poderia implementar todos os níveis de isolamento usando serializável comportamento se assim o desejar. Alguns dos principais mecanismos de banco de dados comerciais também fornecem uma implementação de confirmação de leitura que vai muito além de simplesmente impedir leituras sujas (embora nenhum vá tão longe quanto fornecer isolamento completo no ACID sentido da palavra).
Além disso, para vários produtos populares, leia comprometido o isolamento é o mais baixo nível de isolamento disponível; suas implementações de leitura não confirmadas isolamento são exatamente os mesmos que lidos confirmados. Isso é permitido pelo padrão, mas esses tipos de diferenças adicionam complexidade à tarefa já difícil de migrar o código de uma plataforma para outra. Ao falar sobre os comportamentos de um nível de isolamento, geralmente é importante especificar também a plataforma específica.
Até onde sei, o SQL Server é único entre os principais mecanismos de banco de dados comerciais ao fornecer dois implementações do nível de isolamento de leitura comprometida, cada uma com comportamentos físicos muito diferentes. Esta postagem aborda o primeiro deles, bloqueio leia comprometido.
Leitura de bloqueio do SQL Server confirmada
Se a opção de banco de dados
READ_COMMITTED_SNAPSHOT está OFF , o SQL Server usa um bloqueio implementação do nível de isolamento de leitura confirmada, onde os bloqueios compartilhados são usados para evitar que uma transação simultânea modifique os dados simultaneamente, porque a modificação exigiria um bloqueio exclusivo, que não é compatível com o bloqueio compartilhado. A principal diferença entre o bloqueio de leitura confirmado do SQL Server e o bloqueio de leitura repetitiva (que também recebe bloqueios compartilhados ao ler dados) é que a leitura confirmada libera o bloqueio compartilhado o mais rápido possível , enquanto a leitura repetitiva mantém esses bloqueios até o final da transação delimitadora.
Quando o bloqueio de leitura confirmada adquire bloqueios na granularidade da linha, o bloqueio compartilhado obtido em uma linha é liberado quando um bloqueio compartilhado é obtido na próxima linha . Na granularidade da página, o bloqueio de página compartilhada é liberado quando a primeira linha da próxima página é lida e assim por diante. A menos que uma dica de granularidade de bloqueio seja fornecida com a consulta, o mecanismo de banco de dados decide com que nível de granularidade começar. Observe que as dicas de granularidade são tratadas apenas como sugestões pelo mecanismo, um bloqueio menos granular do que o solicitado ainda pode ser usado inicialmente. Os bloqueios também podem ser escalados durante a execução do nível de linha ou página para o nível de partição ou tabela, dependendo da configuração do sistema.
O ponto importante aqui é que os bloqueios compartilhados normalmente são mantidos apenas por tempo muito curto enquanto a instrução está sendo executada. Para resolver um equívoco comum explicitamente, bloquear a leitura confirmada não mantenha bloqueios compartilhados até o final da instrução.
Bloqueando Comportamentos Comprometidos de Leitura
Os bloqueios compartilhados de curto prazo usados pela implementação de confirmação de leitura de bloqueio do SQL Server fornecem muito poucas das garantias normalmente esperadas de uma transação de banco de dados por programadores de T-SQL. Em particular, uma instrução em execução sob bloqueio de leitura confirmada isolamento:
- Pode encontrar a mesma linha várias vezes;
- Pode perder completamente algumas linhas; e
- não fornecer uma visualização pontual dos dados
Essa lista pode parecer mais uma descrição dos comportamentos estranhos que você pode associar mais ao uso de
NOLOCK dicas, mas todas essas coisas realmente podem, e acontecem ao usar o isolamento de leitura de bloqueio de confirmação. Exemplo
Considere a simples tarefa de contar as linhas em uma tabela, usando a óbvia consulta de instrução única. Sob bloqueio de leitura confirmada isolamento com granularidade de bloqueio de linha, nossa consulta pegará um bloqueio compartilhado na primeira linha, lerá, liberará o bloqueio compartilhado, passará para a próxima linha e assim por diante até atingir o final da estrutura. está lendo. Para este exemplo, suponha que nossa consulta esteja lendo um índice b-tree em ordem crescente de chave (embora também possa usar uma ordem decrescente ou qualquer outra estratégia).
Como apenas uma única linha está bloqueado por compartilhamento em um determinado momento, é claramente possível que transações simultâneas modifiquem as linhas desbloqueadas no índice que nossa consulta está percorrendo. Se essas modificações simultâneas alterarem os valores da chave do índice, elas farão com que as linhas se movam dentro da estrutura do índice. Com essa possibilidade em mente, o diagrama abaixo ilustra dois cenários problemáticos que podem ocorrer:
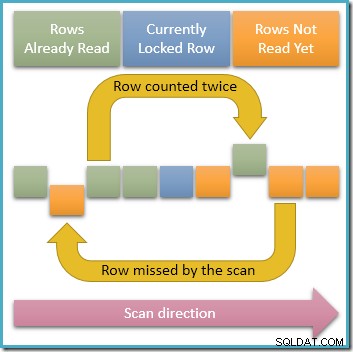
A seta superior mostra uma linha que já contamos tendo sua chave de índice modificada simultaneamente para que a linha se mova à frente da posição de varredura atual no índice, o que significa que a linha será contada duas vezes . A segunda seta mostra uma linha que nossa varredura ainda não encontrou movendo-se para trás da posição de varredura, o que significa que a linha não será contada de forma alguma.
Não é uma visualização pontual
A seção anterior mostrou como o bloqueio de leitura confirmada pode perder dados completamente ou contar o mesmo item várias vezes (mais de duas vezes, se não tivermos sorte). O terceiro ponto na lista de comportamentos inesperados afirmou que o bloqueio de leitura confirmada também não fornece uma exibição pontual dos dados.
O raciocínio por trás dessa afirmação deve agora ser fácil de ver. Nossa consulta de contagem, por exemplo, pode ler facilmente dados que foram inseridos por transações simultâneas depois que nossa consulta começou a ser executada. Da mesma forma, os dados que nossa consulta vê podem ser modificados pela atividade simultânea após o início da consulta e antes de ser concluída. Por fim, os dados que lemos e contamos podem ser excluídos por uma transação simultânea antes que nossa consulta seja concluída.
Claramente, os dados vistos por uma instrução ou transação em execução no isolamento de bloqueio de leitura e confirmação não correspondem a nenhum estado único do banco de dados em qualquer momento específico . Os dados que encontramos podem ser de vários pontos diferentes no tempo, com o único fator comum sendo que cada item representava o valor confirmado mais recente desses dados no momento em que foram lidos (embora possa ter mudado ou desaparecido desde então).
Qual a gravidade desses problemas?
Isso tudo pode parecer um estado de coisas bastante confuso se você estiver acostumado a pensar em suas consultas de instrução única e transações explícitas como sendo logicamente executadas instantaneamente ou como sendo executadas em um único estado point-in-time confirmado do banco de dados ao usar o nível de isolamento padrão do SQL Server. Certamente não se encaixa bem com o conceito de isolamento no sentido de ACID.
Dada a aparente fraqueza das garantias fornecidas pelo bloqueio de isolamento de confirmação de leitura, você pode começar a se perguntar como qualquer do seu código T-SQL de produção já funcionou corretamente! Claro, podemos aceitar que usar um nível de isolamento abaixo do serializável significa abrir mão do isolamento total da transação ACID em troca de outros benefícios potenciais, mas quão sérios podemos esperar que esses problemas sejam na prática?
Linhas ausentes e contadas duas vezes
Esses dois primeiros problemas dependem essencialmente da mudança de chaves de atividades simultâneas em uma estrutura de índice que estamos verificando no momento. Observe que digitalização aqui inclui a parte de varredura de intervalo parcial de um índice procurar , bem como o índice irrestrito familiar ou varredura de tabela.
Se estivermos (intervalo) varrendo uma estrutura de índice cujas chaves normalmente não são modificadas por nenhuma atividade simultânea, esses dois primeiros problemas não devem ser um problema prático. No entanto, é difícil ter certeza disso, porque os planos de consulta podem mudar para usar um método de acesso diferente, e o novo índice pesquisado pode incorporar chaves voláteis.
Também devemos ter em mente que muitas consultas de produção só precisam de um aproximado ou resposta de melhor esforço para alguns tipos de pergunta de qualquer maneira. O fato de algumas linhas estarem faltando ou contadas duas vezes pode não importar muito no esquema mais amplo das coisas. Em um sistema com muitas alterações simultâneas, pode até ser difícil ter certeza de que o resultado foi impreciso, dado que os dados mudam com tanta frequência. Nesse tipo de situação, uma resposta aproximadamente correta pode ser boa o suficiente para os propósitos do consumidor de dados.
Sem visualização pontual
A terceira questão (a questão da chamada visão pontual "consistente" dos dados) também se resume ao mesmo tipo de considerações. Para fins de relatório, onde as inconsistências tendem a resultar em perguntas incômodas dos consumidores de dados, uma visualização de instantâneo é frequentemente preferível. Em outros casos, o tipo de inconsistências decorrentes da falta de uma visão pontual dos dados pode ser tolerável.
Cenários problemáticos
Há também muitos casos em que as preocupações listadas serão ser importante. Por exemplo, se você escrever um código que aplique regras de negócios no T-SQL, você precisa ter cuidado para selecionar um nível de isolamento (ou tomar outra ação adequada) para garantir a correção. Muitas regras de negócios podem ser impostas usando chaves estrangeiras ou restrições, onde as complexidades da seleção do nível de isolamento são tratadas automaticamente para você pelo mecanismo de banco de dados. Como regra geral, usar o conjunto integrado de integridade declarativa features é preferível a construir suas próprias regras em T-SQL.
Existe outra classe ampla de consulta que não impõe uma regra de negócios per se , mas que, no entanto, pode ter consequências infelizes quando executado no nível de isolamento de leitura de bloqueio padrão. Esses cenários nem sempre são tão óbvios quanto os exemplos frequentemente citados de transferência de dinheiro entre contas bancárias ou garantia de que o saldo de várias contas vinculadas nunca caia abaixo de zero. Por exemplo, considere a seguinte consulta que identifica faturas vencidas como uma entrada para algum processo que envia cartas de lembrete com palavras severas:
INSERT dbo.OverdueInvoices
SELECT I.InvoiceNumber
FROM dbo.Invoices AS INV
WHERE INV.TotalDue >
(
SELECT SUM(P.Amount)
FROM dbo.Payments AS P
WHERE P.InvoiceNumber = I.InvoiceNumber
); Claramente, não gostaríamos de enviar uma carta para alguém que pagou integralmente sua fatura em parcelas, simplesmente porque a atividade simultânea do banco de dados no momento em que nossa consulta foi executada significava que calculamos uma soma incorreta dos pagamentos recebidos. Consultas reais em sistemas de produção reais são frequentemente muito mais complexas do que o exemplo simples acima, é claro.
Para terminar por hoje, dê uma olhada na consulta a seguir e veja se você pode identificar quantas oportunidades existem para que algo não intencional ocorra, se várias dessas consultas forem executadas simultaneamente no nível de isolamento confirmado de leitura de bloqueio (talvez enquanto outras transações não relacionadas também estão modificando a tabela Casos):
-- Allocate the oldest unallocated case ID to
-- the current case worker, while ensuring
-- the worker never has more than three
-- active cases at once.
UPDATE dbo.Cases
SET WorkerID = @WorkerID
WHERE
CaseID =
(
-- Find the oldest unallocated case ID
SELECT TOP (1)
C2.CaseID
FROM dbo.Cases AS C2
WHERE
C2.WorkerID IS NULL
ORDER BY
C2.DateCreated DESC
)
AND
(
SELECT COUNT_BIG(*)
FROM dbo.Cases AS C3
WHERE C3.WorkerID = @WorkerID
) < 3; Depois que você começar a procurar todas as pequenas maneiras pelas quais uma consulta pode dar errado nesse nível de isolamento, pode ser difícil parar. Tenha em mente as advertências observadas anteriormente sobre a necessidade real de resultados precisos completamente isolados e pontuais. Não há problema em ter consultas que retornem resultados bons o suficiente, desde que você esteja ciente das trocas que está fazendo ao usar a leitura confirmada.
Próxima vez
A próxima parte desta série examina a segunda implementação física do isolamento de leitura confirmada disponível no SQL Server, isolamento de instantâneo de leitura confirmado.
[ Veja o índice para toda a série ]