O tipo de dados string é um dos tipos de dados mais significativos em qualquer linguagem de programação. Você dificilmente pode escrever um programa útil sem ele. No entanto, muitos desenvolvedores não conhecem certos aspectos desse tipo. Portanto, vamos considerar esses aspectos.
Representação de strings na memória
Em .Net, as strings são localizadas de acordo com a regra BSTR (Basic string ou binary string). Este método de representação de dados de string é usado em COM (a palavra ‘básico’ se origina da linguagem de programação Visual Basic na qual foi usada inicialmente). Como sabemos, PWSZ (Pointer to Wide-character String, Zero-terminated) é usado em C/C++ para representação de strings. Com tal localização na memória, um terminado em nulo está localizado no final de uma string. Este terminador permite determinar o final da string. O comprimento da string no PWSZ é limitado apenas por um volume de espaço livre.
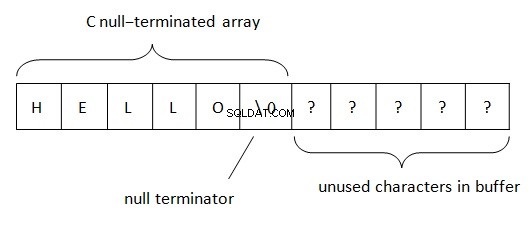
No BSTR, a situação é um pouco diferente.
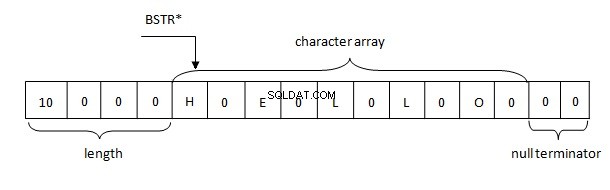
Aspectos básicos da representação de string BSTR na memória são os seguintes:
- O comprimento da string é limitado por um determinado número. No PWSZ, o comprimento da string é limitado pela disponibilidade de memória livre.
- A string BSTR sempre aponta para o primeiro caractere no buffer. O PWSZ pode apontar para qualquer caractere no buffer.
- No BSTR, semelhante ao PWSZ, o caractere nulo está sempre localizado no final. No BSTR, o caractere nulo é um caractere válido e pode ser encontrado em qualquer lugar da string.
- Como o terminador nulo está localizado no final, o BSTR é compatível com PWSZ, mas não vice-versa.
Portanto, strings em .NET são representadas na memória de acordo com a regra BSTR. O buffer contém um comprimento de string de 4 bytes seguido por caracteres de dois bytes de uma string no formato UTF-16, que, por sua vez, é seguido por dois bytes nulos (\u0000).
Usar essa implementação tem muitos benefícios:o comprimento da string não deve ser recalculado, pois é armazenado no cabeçalho, uma string pode conter caracteres nulos em qualquer lugar. E o mais importante é que o endereço de uma string (fixada) pode ser facilmente passado pelo código nativo onde WCHAR* é esperado.
Quanta memória um objeto string usa?
Encontrei artigos informando que o tamanho do objeto string é igual a tamanho=20 + (comprimento/2)*4, mas essa fórmula não está totalmente correta.
Para começar, uma string é um tipo de link, então os primeiros quatro bytes contêm SyncBlockIndex e os próximos quatro bytes contêm o ponteiro de tipo.
Tamanho da string =4 + 4 + …
Como afirmei acima, o comprimento da string é armazenado no buffer. É um campo do tipo int, portanto precisamos adicionar mais 4 bytes.
Tamanho da string =4 + 4 + 4 + …
Para passar uma string para o código nativo rapidamente (sem copiar), o terminador nulo está localizado no final de cada string que ocupa 2 bytes. Portanto,
Tamanho da string =4 + 4 + 4 + 2 + …
A única coisa que resta é lembrar que cada caractere em uma string está na codificação UTF-16 e também leva 2 bytes. Portanto:
Tamanho da string =4 + 4 + 4 + 2 + 2 * comprimento =14 + 2 * comprimento
Mais uma coisa e terminamos. A memória alocada pelo gerenciador de memória no CLR é múltiplo de 4 bytes (4, 8, 12, 16, 20, 24, …). Portanto, se o comprimento da string for de 34 bytes no total, 36 bytes serão alocados. Precisamos arredondar nosso valor para o número maior mais próximo que seja múltiplo de quatro. Para isso, precisamos:
Tamanho da string =4 * ((14 + 2 * comprimento + 3) / 4) (divisão inteira)
O problema das versões :até o .NET v4, havia um m_arrayLength adicional campo do tipo int na classe String que levou 4 bytes. Este campo é um comprimento real do buffer alocado para uma string, incluindo o terminador nulo, ou seja, é comprimento + 1. No .NET 4.0, este campo foi removido da classe. Como resultado, um objeto do tipo string ocupa 4 bytes a menos.
O tamanho de uma string vazia sem o m_arrayLength campo (ou seja, em .Net 4.0 e superior) é igual a =4 + 4 + 4 + 2 =14 bytes, e com este campo (ou seja, inferior a .Net 4.0), seu tamanho é igual a =4 + 4 + 4 + 4 + 2 =18 bytes. Se arredondarmos 4 bytes, o tamanho será de 16 e 20 bytes, respectivamente.
Aspectos da string
Assim, consideramos a representação das strings e o tamanho que elas assumem na memória. Agora, vamos falar sobre suas peculiaridades.
Aspectos básicos de strings em .NET são os seguintes:
- Strings são tipos de referência.
- Strings são imutáveis. Uma vez criada, uma string não pode ser modificada (por meios justos). Cada chamada do método desta classe retorna uma nova string, enquanto a string anterior se torna uma presa para o coletor de lixo.
- Strings redefinem o método Object.Equals. Como resultado, o método compara valores de caracteres em strings, não valores de link.
Vamos considerar cada ponto em detalhes.
Strings são tipos de referência
Strings são tipos de referência reais. Ou seja, eles estão sempre localizados no heap. Muitos de nós os confundem com tipos de valor, já que vocês se comportam da mesma maneira. Por exemplo, eles são imutáveis e sua comparação é feita por valor, não por referências, mas devemos ter em mente que é um tipo de referência.
Strings são imutáveis
- Strings são imutáveis para um propósito. A imutabilidade da string tem vários benefícios:
- O tipo de string é thread-safe, pois nem um único thread pode modificar o conteúdo de uma string.
- O uso de strings imutáveis leva à diminuição da carga de memória, pois não há necessidade de armazenar 2 instâncias da mesma string. Como resultado, menos memória é gasta e a comparação é executada mais rapidamente, pois apenas as referências são comparadas. Em .NET, esse mecanismo é chamado de internamento de strings (string pool). Falaremos sobre isso um pouco mais tarde.
- Ao passar um parâmetro imutável para um método, podemos parar de nos preocupar que ele será modificado (se não foi passado como ref ou out, é claro).
As estruturas de dados podem ser divididas em dois tipos:efêmeras e persistentes. Estruturas de dados efêmeras armazenam apenas suas últimas versões. Estruturas de dados persistentes salvam todas as suas versões anteriores durante a modificação. Estes últimos são, de fato, imutáveis, pois suas operações não modificam a estrutura no local. Em vez disso, eles retornam uma nova estrutura baseada na anterior.
Dado o fato de que as strings são imutáveis, elas podem ser persistentes, mas não são. Strings são efêmeras em .Net.
Para comparação, vamos pegar as strings Java. Eles são imutáveis, como no .NET, mas também são persistentes. A implementação da classe String em Java tem a seguinte aparência:
public final class String
{
private final char value[];
private final int offset;
private final int count;
private int hash;
.....
}
Além de 8 bytes no cabeçalho do objeto, incluindo uma referência ao tipo e uma referência a um objeto de sincronização, as strings contêm os seguintes campos:
- Uma referência a uma matriz de caracteres;
- Um índice do primeiro caractere da string na matriz de caracteres (deslocamento desde o início)
- O número de caracteres na string;
- O código de hash calculado após a primeira chamada de HashCode() método.
Strings em Java consomem mais memória do que em .NET, pois contêm campos adicionais permitindo que sejam persistentes. Devido à persistência, a execução do String.substring() método em Java leva O(1) , uma vez que não requer cópia de string como em .NET, onde a execução deste método leva O(n) .
Implementação do método String.substring() em Java:
public String substring(int beginIndex, int endIndex)
{
if (beginIndex < 0) throw new StringIndexOutOfBoundsException(beginIndex); if (endIndex > count)
throw new StringIndexOutOfBoundsException(endIndex);
if (beginIndex > endIndex)
throw new StringIndexOutOfBoundsException(endIndex - beginIndex);
return ((beginIndex == 0) && (endIndex == count)) ? this : new String(offset + beginIndex, endIndex - beginIndex, value);
}
public String(int offset, int count, char value[])
{
this.value = value;
this.offset = offset;
this.count = count;
} No entanto, se uma string de origem for grande o suficiente e a substring cortada tiver vários caracteres, toda a matriz de caracteres da string inicial ficará pendente na memória até que haja uma referência à substring. Ou, se você serializar a substring recebida por meios padrão e passá-la pela rede, toda a matriz original será serializada e o número de bytes transmitidos pela rede será grande. Portanto, em vez do código
s =ss.substring(3)
o seguinte código pode ser usado:
s =new String(ss.substring(3)),
Este código não armazenará a referência ao array de caracteres da string de origem. Em vez disso, ele copiará apenas a parte realmente usada da matriz. A propósito, se chamarmos esse construtor em uma string cujo comprimento seja igual ao comprimento do array de caracteres, a cópia não ocorrerá. Em vez disso, a referência ao array original será usada.
Como se viu, a implementação do tipo string foi alterada na última versão do Java. Agora, não há campos de deslocamento e comprimento na classe. O novo hash32 (com algoritmo de hash diferente) foi introduzido em seu lugar. Isso significa que as strings não são mais persistentes. Agora, a String.substring O método criará uma nova string a cada vez.
String redefine Onbject.Equals
A classe string redefine o método Object.Equals. Como resultado, a comparação ocorre, mas não por referência, mas por valor. Suponho que os desenvolvedores sejam gratos aos criadores da classe String por redefinir o operador ==, já que o código que usa ==para comparação de strings parece mais profundo do que a chamada de método.
if (s1 == s2)
Comparado com
if (s1.Equals(s2))
A propósito, em Java, o operador ==compara por referência. Se você precisar comparar strings por caractere, precisamos usar o método string.equals().
Internação de strings
Finalmente, vamos considerar o internamento de strings. Vamos dar uma olhada em um exemplo simples – um código que inverte uma string.
var s = "Strings are immutuble";
int length = s.Length;
for (int i = 0; i < length / 2; i++)
{
var c = s[i];
s[i] = s[length - i - 1];
s[length - i - 1] = c;
} Obviamente, este código não pode ser compilado. O compilador lançará erros para essas strings, pois tentamos modificar o conteúdo da string. Qualquer método da classe String retorna uma nova instância da string, em vez de sua modificação de conteúdo.
A string pode ser modificada, mas precisaremos usar o código não seguro. Vamos considerar o seguinte exemplo:
var s = "Strings are immutable";
int length = s.Length;
unsafe
{
fixed (char* c = s)
{
for (int i = 0; i < length / 2; i++)
{
var temp = c[i];
c[i] = c[length - i - 1];
c[length - i - 1] = temp;
}
}
} Após a execução deste código, elbatummi era sgnirtS será escrito na string, como esperado. A mutabilidade de strings leva a um caso extravagante relacionado ao internamento de strings.
Estagiar de string é um mecanismo onde literais semelhantes são representados na memória como um único objeto.
Resumindo, o objetivo do internamento de strings é o seguinte:há uma única tabela interna com hash dentro de um processo (não dentro de um domínio de aplicação), em que as strings são suas chaves e os valores são referências a elas. Durante a compilação JIT, strings literais são colocadas em uma tabela sequencialmente (cada string em uma tabela pode ser encontrada apenas uma vez). Durante a execução, referências a strings literais são atribuídas a partir desta tabela. Durante a execução, podemos colocar uma string na tabela interna com o String.Intern método. Além disso, podemos verificar a disponibilidade de uma string na tabela interna usando o String.IsInterned método.
var s1 = "habrahabr"; var s2 = "habrahabr"; var s3 = "habra" + "habr"; Console.WriteLine(object.ReferenceEquals(s1, s2));//true Console.WriteLine(object.ReferenceEquals(s1, s3));//true
Observe que apenas literais de string são internos por padrão. Como a tabela interna com hash é usada para implementação interna, a pesquisa nessa tabela é realizada durante a compilação JIT. Este processo leva algum tempo. Portanto, se todas as strings forem internadas, reduzirá a otimização a zero. Durante a compilação em código IL, o compilador concatena todas as strings literais, pois não há necessidade de armazená-las em partes. Portanto, a segunda igualdade retorna true .
Agora, voltemos ao nosso caso. Considere o seguinte código:
var s = "Strings are immutable";
int length = s.Length;
unsafe
{
fixed (char* c = s)
{
for (int i = 0; i < length / 2; i++)
{
var temp = c[i];
c[i] = c[length - i - 1];
c[length - i - 1] = temp;
}
}
}
Console.WriteLine("Strings are immutable"); Parece que tudo é bastante óbvio e o código deve retornar Strings são imutáveis . No entanto, não! O código retorna elbatummi era sgnirtS . Isso acontece exatamente por causa do estágio. Quando modificamos strings, modificamos seu conteúdo e, como é literal, é internado e representado por uma única instância da string.
Podemos abandonar o internamento de strings se aplicarmos o CompilationRelaxationsAttribute atribuir à assembléia. Este atributo controla a precisão do código que é criado pelo compilador JIT do ambiente CLR. O construtor deste atributo aceita o CompilationRelaxations enumeração, que atualmente inclui apenas CompilationRelaxations.NoStringInterning . Como resultado, a assembléia é marcada como aquela que não requer estágio.
A propósito, esse atributo não é processado no .NET Framework v1.0. Por isso, era impossível desabilitar o internamento. A partir da versão 2, o mscorlib assembly é marcado com este atributo. Então, acontece que strings em .NET podem ser modificadas com o código inseguro.
E se esquecermos do inseguro?
Por acaso, podemos modificar o conteúdo da string sem o código inseguro. Em vez disso, podemos usar o mecanismo de reflexão. Este truque foi bem sucedido em .NET até a versão 2.0. Depois, os desenvolvedores da classe String nos privaram dessa oportunidade. No .NET 2.0, a classe String tem dois métodos internos:SetChar para verificação de limites e InternalSetCharNoBoundsCheck que não faz a verificação de limites. Esses métodos definem o caractere especificado por um determinado índice. A implementação dos métodos tem a seguinte aparência:
internal unsafe void SetChar(int index, char value)
{
if ((uint)index >= (uint)this.Length)
throw new ArgumentOutOfRangeException("index", Environment.GetResourceString("ArgumentOutOfRange_Index"));
fixed (char* chPtr = &this.m_firstChar)
chPtr[index] = value;
}
internal unsafe void InternalSetCharNoBoundsCheck (int index, char value)
{
fixed (char* chPtr = &this.m_firstChar)
chPtr[index] = value;
} Portanto, podemos modificar o conteúdo da string sem código inseguro com a ajuda do seguinte código:
var s = "Strings are immutable";
int length = s.Length;
var method = typeof(string).GetMethod("InternalSetCharNoBoundsCheck", BindingFlags.Instance | BindingFlags.NonPublic);
for (int i = 0; i < length / 2; i++)
{
var temp = s[i];
method.Invoke(s, new object[] { i, s[length - i - 1] });
method.Invoke(s, new object[] { length - i - 1, temp });
}
Console.WriteLine("Strings are immutable");
Como esperado, o código retorna elbatummi era sgnirtS .
O problema das versões :em diferentes versões do .NET Framework, string.Empty pode ser integrado ou não. Vamos considerar o seguinte código:
string str1 = String.Empty;
StringBuilder sb = new StringBuilder().Append(String.Empty);
string str2 = String.Intern(sb.ToString());
if (object.ReferenceEquals(str1, str2))
Console.WriteLine("Equal");
else
Console.WriteLine("Not Equal"); No .NET Framework 1.0, .NET Framework 1.1 e .NET Framework 3.5 com o service pack 1 (SP1), str1 e str2 não são iguais. Atualmente, string.Empty não está internado.
Aspectos de desempenho
Há um efeito colateral negativo de internar. O fato é que a referência a um objeto interno String armazenado pelo CLR pode ser salvo mesmo após o término do trabalho do aplicativo e até mesmo após o término do trabalho do domínio do aplicativo. Portanto, é melhor omitir o uso de grandes strings literais. Se ainda for necessário, o estágio deve ser desativado aplicando o CompilationRelaxations atributo à montagem.