Em uma tabela sem um índice clusterizado (uma tabela heap), as páginas de dados não são vinculadas - portanto, percorrer as páginas requer um procure no mapa de alocação de índice .
Uma tabela clusterizada, no entanto, tem páginas de dados vinculadas em uma lista duplamente vinculada - tornando as varreduras sequenciais um pouco mais rápidas. Claro, em troca, você tem a sobrecarga de manter as páginas de dados em ordem em
INSERT , UPDATE e DELETE . Uma tabela de heap, no entanto, requer uma segunda gravação no IAM. Se sua consulta tiver um
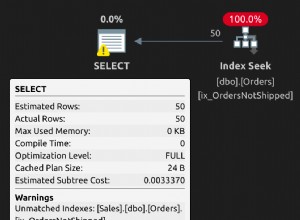
RANGE operador (por exemplo:SELECT * FROM TABLE WHERE Id BETWEEN 1 AND 100 ), então uma tabela clusterizada (sendo em uma ordem garantida) seria mais eficiente - pois poderia usar as páginas de índice para encontrar as páginas de dados relevantes. Um heap teria que varrer todas as linhas, pois não pode depender de ordenação. E, é claro, um índice clusterizado permite que você faça uma BUSCA DE ÍNDICE CLUSTERED, que é praticamente ideal para desempenho... um heap sem índices sempre resultaria em uma varredura de tabela.
Então:
-
Para sua consulta de exemplo em que você seleciona todas as linhas, a única diferença é a lista duplamente vinculada que um índice clusterizado mantém. Isso deve tornar sua tabela clusterizada um pouco mais rápida do que um heap com um grande número de linhas.
-
Para uma consulta com umWHEREcláusula que pode ser (pelo menos parcialmente) satisfeita pelo índice clusterizado, você sairá na frente por causa da ordenação - portanto, não precisará varrer a tabela inteira.
-
Para uma consulta que não é satisfeita pelo índice clusterizado, você está praticamente empatado... novamente, a única diferença é aquela lista duplamente vinculada para varredura sequencial. Em ambos os casos, você está abaixo do ideal.
-
ParaINSERT,UPDATEeDELETEum heap pode ou não vencer. O heap não precisa manter a ordem, mas exige uma segunda gravação no IAM. Acho que a diferença de desempenho relativa seria insignificante, mas também bastante dependente de dados.
A Microsoft tem um whitepaper que compara um índice clusterizado a um índice não clusterizado equivalente em um heap (não exatamente o mesmo que discuti acima, mas próximo). A conclusão deles é basicamente colocar um índice clusterizado em todas as tabelas. Farei o meu melhor para resumir seus resultados (novamente, observe que eles estão realmente comparando um índice não clusterizado com um índice clusterizado aqui - mas acho que é relativamente comparável):
INSERTdesempenho:o índice clusterizado ganha cerca de 3% devido à segunda gravação necessária para um heap.UPDATEdesempenho:o índice clusterizado ganha cerca de 8% devido à segunda pesquisa necessária para um heap.DELETEdesempenho:o índice clusterizado ganha cerca de 18% devido à segunda pesquisa necessária e à segunda exclusão necessária do IAM para um heap.- único
SELECTdesempenho:o índice clusterizado ganha cerca de 16% devido à segunda pesquisa necessária para um heap. - intervalo
SELECTdesempenho:o índice clusterizado ganha cerca de 29% devido à ordenação aleatória de um heap. INSERTsimultâneo :a tabela de heap ganha 30% sob carga devido a divisões de página para o índice clusterizado.