O Galera Cluster, com sua replicação (virtualmente) síncrona, é comumente usado em diversos tipos de ambientes. Dimensioná-lo adicionando novos nós não é difícil (ou apenas alguns cliques quando você usa o ClusterControl).
O principal problema com a replicação síncrona é, bem, a parte síncrona que geralmente resulta em que todo o cluster seja tão rápido quanto seu nó mais lento. Qualquer gravação executada em um cluster deve ser replicada para todos os nós e certificada neles. Se, por qualquer motivo, esse processo ficar lento, isso poderá afetar seriamente a capacidade do cluster de acomodar gravações. O controle de fluxo será ativado, para garantir que o nó mais lento ainda possa acompanhar a carga. Isso torna bastante complicado para alguns dos cenários comuns que acontecem em um ambiente do mundo real.
Primeiro, vamos discutir a recuperação de desastres distribuída geograficamente. Claro, você pode executar clusters em uma rede de longa distância, mas o aumento da latência terá um impacto significativo no desempenho do cluster. Isso limita seriamente a capacidade de usar tal configuração, especialmente em distâncias maiores quando a latência é maior.
Outro caso de uso bastante comum - um ambiente de teste para atualização de versão principal. Não é uma boa ideia misturar diferentes versões de nós do MariaDB Galera Cluster no mesmo cluster, mesmo que seja possível. Por outro lado, a migração para a versão mais recente requer testes detalhados. Idealmente, tanto as leituras quanto as gravações teriam sido testadas. Uma maneira de conseguir isso é criar um cluster Galera separado e executar os testes, mas você gostaria de executar os testes em um ambiente o mais próximo possível da produção. Uma vez provisionado, um cluster pode ser usado para testes com consultas do mundo real, mas seria difícil gerar uma carga de trabalho próxima à de produção. Você não pode mover parte do tráfego de produção para esse sistema de teste, porque os dados não estão atualizados.
Por fim, a migração em si. Novamente, o que dissemos anteriormente, mesmo que seja possível misturar versões antigas e novas de nós Galera no mesmo cluster, não é a maneira mais segura de fazê-lo.
Felizmente, a solução mais simples para todos esses três problemas seria conectar clusters Galera separados com uma replicação assíncrona. O que a torna uma solução tão boa? Bem, é assíncrono, o que faz com que não afete a replicação do Galera. Não há controle de fluxo, portanto, o desempenho do cluster “mestre” não será afetado pelo desempenho do cluster “escravo”. Como em toda replicação assíncrona, um atraso pode aparecer, mas desde que permaneça dentro dos limites aceitáveis, pode funcionar perfeitamente. Você também deve ter em mente que hoje em dia a replicação assíncrona pode ser paralelizada (vários threads podem trabalhar juntos para aumentar a largura de banda) e reduzir ainda mais o atraso da replicação.
Nesta postagem do blog, discutiremos quais são as etapas para implantar a replicação assíncrona entre os clusters MariaDB Galera.
Como configurar a replicação assíncrona entre clusters MariaDB Galera?
Primeiro, temos que implantar um cluster. Para nossos propósitos, configuramos um cluster de três nós. Manteremos a configuração no mínimo, portanto, não discutiremos a complexidade do aplicativo e da camada de proxy. A camada proxy pode ser muito útil para lidar com tarefas para as quais você deseja implantar replicação assíncrona - redirecionando um subconjunto do tráfego somente leitura para o cluster de teste, ajudando na situação de recuperação de desastres quando o cluster “principal” não estiver disponível, redirecionando o tráfego para o cluster de DR. Existem inúmeros proxies que você pode experimentar, dependendo de sua preferência - HAProxy, MaxScale ou ProxySQL - todos podem ser usados nessas configurações e, dependendo do caso, alguns deles podem ajudá-lo a gerenciar seu tráfego.
Configurando o cluster de origem
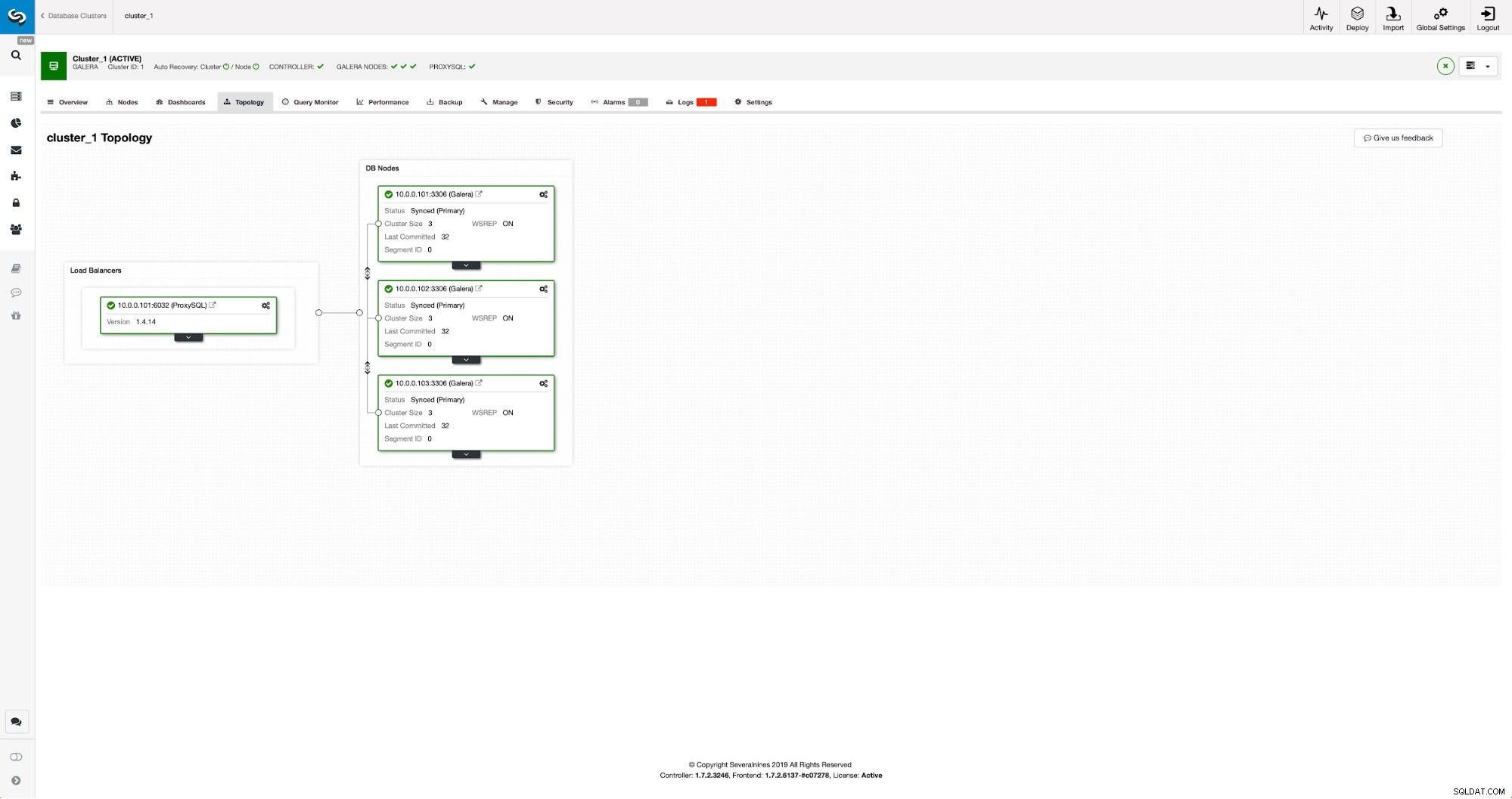
Nosso cluster consiste em três nós MariaDB 10.3, também implantamos o ProxySQL para fazer a divisão de leitura e gravação e distribuir o tráfego em todos os nós do cluster. Esta não é uma implantação de nível de produção, para isso teríamos que implantar mais nós ProxySQL e um Keepalived em cima deles. Ainda é suficiente para nossos propósitos. Para configurar a replicação assíncrona, teremos que ter um log binário habilitado em nosso cluster. Pelo menos um nó, mas é melhor mantê-lo ativado em todos eles, caso o único nó com log binário ativado fique inativo - então você deseja ter outro nó no cluster em funcionamento que possa ser escravizado.
Ao habilitar o log binário, certifique-se de configurar a rotação do log binário para que os logs antigos sejam removidos em algum momento. Você usará o formato de log binário ROW. Você também deve garantir que o GTID esteja configurado e em uso - ele será muito útil quando você precisar reescravizar seu cluster "escravo" ou se precisar habilitar a replicação multithread. Como este é um cluster Galera, você quer ter ‘wsrep_gtid_domain_id’ configurado e ‘wsrep_gtid_mode’ habilitado. Essas configurações garantirão que os GTIDs sejam gerados para o tráfego proveniente do cluster Galera. Mais informações podem ser encontradas na documentação. Feito isso, você pode prosseguir com a configuração do segundo cluster.
Configurando o cluster de destino
Dado que atualmente não há cluster de destino, temos que começar a implantá-lo. Não abordaremos essas etapas em detalhes, você pode encontrar instruções na documentação. De um modo geral, o processo consiste em várias etapas:
- Configurar repositórios MariaDB
- Instale os pacotes MariaDB 10.3
- Configurar nós para formar um cluster
No início, vamos começar com apenas um nó. Você pode configurar todos eles para formar um cluster, mas deve interrompê-los e usar apenas um para a próxima etapa. Esse nó se tornará escravo do cluster original. Usaremos mariabackup para provisioná-lo. Em seguida, configuraremos a replicação.
Primeiro, temos que criar um diretório onde armazenaremos o backup:
mkdir /mnt/mariabackupEm seguida, executamos o backup e o criamos no diretório preparado no passo acima. Certifique-se de usar o usuário e a senha corretos para se conectar ao banco de dados:
mariabackup --backup --user=root --password=pass --target-dir=/mnt/mariabackup/Em seguida, temos que copiar os arquivos de backup para o primeiro nó do segundo cluster. Usamos scp para isso, você pode usar o que quiser - rsync, netcat, qualquer coisa que funcione.
scp -r /mnt/mariabackup/* 10.0.0.104:/root/mariabackup/Após a cópia do backup, devemos prepará-lo aplicando os arquivos de log:
mariabackup --prepare --target-dir=/root/mariabackup/
mariabackup based on MariaDB server 10.3.16-MariaDB debian-linux-gnu (x86_64)
[00] 2019-06-24 08:35:39 cd to /root/mariabackup/
[00] 2019-06-24 08:35:39 This target seems to be not prepared yet.
[00] 2019-06-24 08:35:39 mariabackup: using the following InnoDB configuration for recovery:
[00] 2019-06-24 08:35:39 innodb_data_home_dir = .
[00] 2019-06-24 08:35:39 innodb_data_file_path = ibdata1:100M:autoextend
[00] 2019-06-24 08:35:39 innodb_log_group_home_dir = .
[00] 2019-06-24 08:35:39 InnoDB: Using Linux native AIO
[00] 2019-06-24 08:35:39 Starting InnoDB instance for recovery.
[00] 2019-06-24 08:35:39 mariabackup: Using 104857600 bytes for buffer pool (set by --use-memory parameter)
2019-06-24 8:35:39 0 [Note] InnoDB: Mutexes and rw_locks use GCC atomic builtins
2019-06-24 8:35:39 0 [Note] InnoDB: Uses event mutexes
2019-06-24 8:35:39 0 [Note] InnoDB: Compressed tables use zlib 1.2.8
2019-06-24 8:35:39 0 [Note] InnoDB: Number of pools: 1
2019-06-24 8:35:39 0 [Note] InnoDB: Using SSE2 crc32 instructions
2019-06-24 8:35:39 0 [Note] InnoDB: Initializing buffer pool, total size = 100M, instances = 1, chunk size = 100M
2019-06-24 8:35:39 0 [Note] InnoDB: Completed initialization of buffer pool
2019-06-24 8:35:39 0 [Note] InnoDB: page_cleaner coordinator priority: -20
2019-06-24 8:35:39 0 [Note] InnoDB: Starting crash recovery from checkpoint LSN=3448619491
2019-06-24 8:35:40 0 [Note] InnoDB: Starting final batch to recover 759 pages from redo log.
2019-06-24 8:35:40 0 [Note] InnoDB: Last binlog file '/var/lib/mysql-binlog/binlog.000003', position 865364970
[00] 2019-06-24 08:35:40 Last binlog file /var/lib/mysql-binlog/binlog.000003, position 865364970
[00] 2019-06-24 08:35:40 mariabackup: Recovered WSREP position: e79a3494-964f-11e9-8a5c-53809a3c5017:25740
[00] 2019-06-24 08:35:41 completed OK!Em caso de erro, pode ser necessário reexecutar o backup. Se tudo correu bem, podemos remover os dados antigos e substituí-los pelas informações de backup
rm -rf /var/lib/mysql/*
mariabackup --copy-back --target-dir=/root/mariabackup/
…
[01] 2019-06-24 08:37:06 Copying ./sbtest/sbtest10.frm to /var/lib/mysql/sbtest/sbtest10.frm
[01] 2019-06-24 08:37:06 ...done
[00] 2019-06-24 08:37:06 completed OK!Também queremos definir o proprietário correto dos arquivos:
chown -R mysql.mysql /var/lib/mysql/Contaremos com o GTID para manter a replicação consistente, portanto, precisamos ver qual foi o último GTID aplicado neste backup. Essas informações podem ser encontradas no arquivo xtrabackup_info que faz parte do backup:
example@sqldat.com:~/mariabackup# cat /var/lib/mysql/xtrabackup_info | grep binlog_pos
binlog_pos = filename 'binlog.000003', position '865364970', GTID of the last change '9999-1002-23012'Também teremos que garantir que o nó escravo tenha logs binários habilitados junto com 'log_slave_updates'. Idealmente, isso será ativado em todos os nós no segundo cluster - apenas no caso de o nó “escravo” falhar e você ter que configurar a replicação usando outro nó no cluster escravo.
A última parte que precisamos fazer antes de configurar a replicação é criar um usuário que usaremos para executar a replicação:
MariaDB [(none)]> CREATE USER 'repuser'@'10.0.0.104' IDENTIFIED BY 'reppass';
Query OK, 0 rows affected (0.077 sec)MariaDB [(none)]> GRANT REPLICATION SLAVE ON *.* TO 'repuser'@'10.0.0.104';
Query OK, 0 rows affected (0.012 sec)Isso é tudo que precisamos. Agora, podemos iniciar o primeiro nó no segundo cluster, nosso to-be-slave:
galera_new_clusterUma vez iniciado, podemos entrar no MySQL CLI e configurá-lo para se tornar um escravo, usando a posição GITD que encontramos algumas etapas anteriores:
mysql -ppassMariaDB [(none)]> SET GLOBAL gtid_slave_pos = '9999-1002-23012';
Query OK, 0 rows affected (0.026 sec)Feito isso, podemos finalmente configurar a replicação e iniciá-la:
MariaDB [(none)]> CHANGE MASTER TO MASTER_HOST='10.0.0.101', MASTER_PORT=3306, MASTER_USER='repuser', MASTER_PASSWORD='reppass', MASTER_USE_GTID=slave_pos;
Query OK, 0 rows affected (0.016 sec)MariaDB [(none)]> START SLAVE;
Query OK, 0 rows affected (0.010 sec)Neste ponto temos um Galera Cluster composto por um nó. Esse nó também é um escravo do cluster original (em particular, seu mestre é o nó 10.0.0.101). Para juntar outros nós, usaremos o SST, mas para fazê-lo funcionar primeiro, precisamos garantir que a configuração do SST esteja correta - lembre-se de que acabamos de substituir todos os usuários em nosso segundo cluster pelo conteúdo do cluster de origem. O que você precisa fazer agora é garantir que a configuração ‘wsrep_sst_auth’ do segundo cluster corresponda à do primeiro cluster. Feito isso, você pode iniciar os nós restantes um a um e eles devem se juntar ao nó existente (10.0.0.104), obter os dados por SST e formar o cluster Galera. Eventualmente, você deve terminar com dois clusters, três nós cada, com link de replicação assíncrona entre eles (de 10.0.0.101 a 10.0.0.104 em nosso exemplo). Você pode confirmar que a replicação está funcionando verificando o valor de:
MariaDB [(none)]> show global status like 'wsrep_last_committed';
+----------------------+-------+
| Variable_name | Value |
+----------------------+-------+
| wsrep_last_committed | 106 |
+----------------------+-------+
1 row in set (0.001 sec)MariaDB [(none)]> show global status like 'wsrep_last_committed';
+----------------------+-------+
| Variable_name | Value |
+----------------------+-------+
| wsrep_last_committed | 114 |
+----------------------+-------+
1 row in set (0.001 sec)Como configurar a replicação assíncrona entre clusters MariaDB Galera usando o ClusterControl?
No momento deste blog, o ClusterControl não tem a funcionalidade de configurar a replicação assíncrona em vários clusters, estamos trabalhando nisso enquanto digito isso. No entanto, o ClusterControl pode ser de grande ajuda neste processo - mostraremos como você pode acelerar as etapas manuais trabalhosas usando a automação fornecida pelo ClusterControl.
Pelo que mostramos anteriormente, podemos concluir que essas são as etapas gerais a serem seguidas ao configurar a replicação entre dois clusters Galera:
- Implantar um novo cluster Galera
- Provisionar novo cluster usando dados do antigo
- Configurar novo cluster (configuração SST, logs binários)
- Configure a replicação entre o cluster antigo e o novo
Os primeiros três pontos são algo que você pode fazer facilmente usando o ClusterControl mesmo agora. Nós vamos mostrar-lhe como fazer isso.
Implantar e provisionar um novo cluster MariaDB Galera usando o ClusterControl
A situação inicial é semelhante - temos um cluster em funcionamento. Temos que configurar o segundo. Um dos recursos mais recentes do ClusterControl é a opção de implantar um novo cluster e provisioná-lo usando os dados do backup. Isso é muito útil para criar ambientes de teste, também é uma opção que usaremos para provisionar nosso novo cluster para a configuração da replicação. Portanto, o primeiro passo que daremos é criar um backup usando mariabackup:
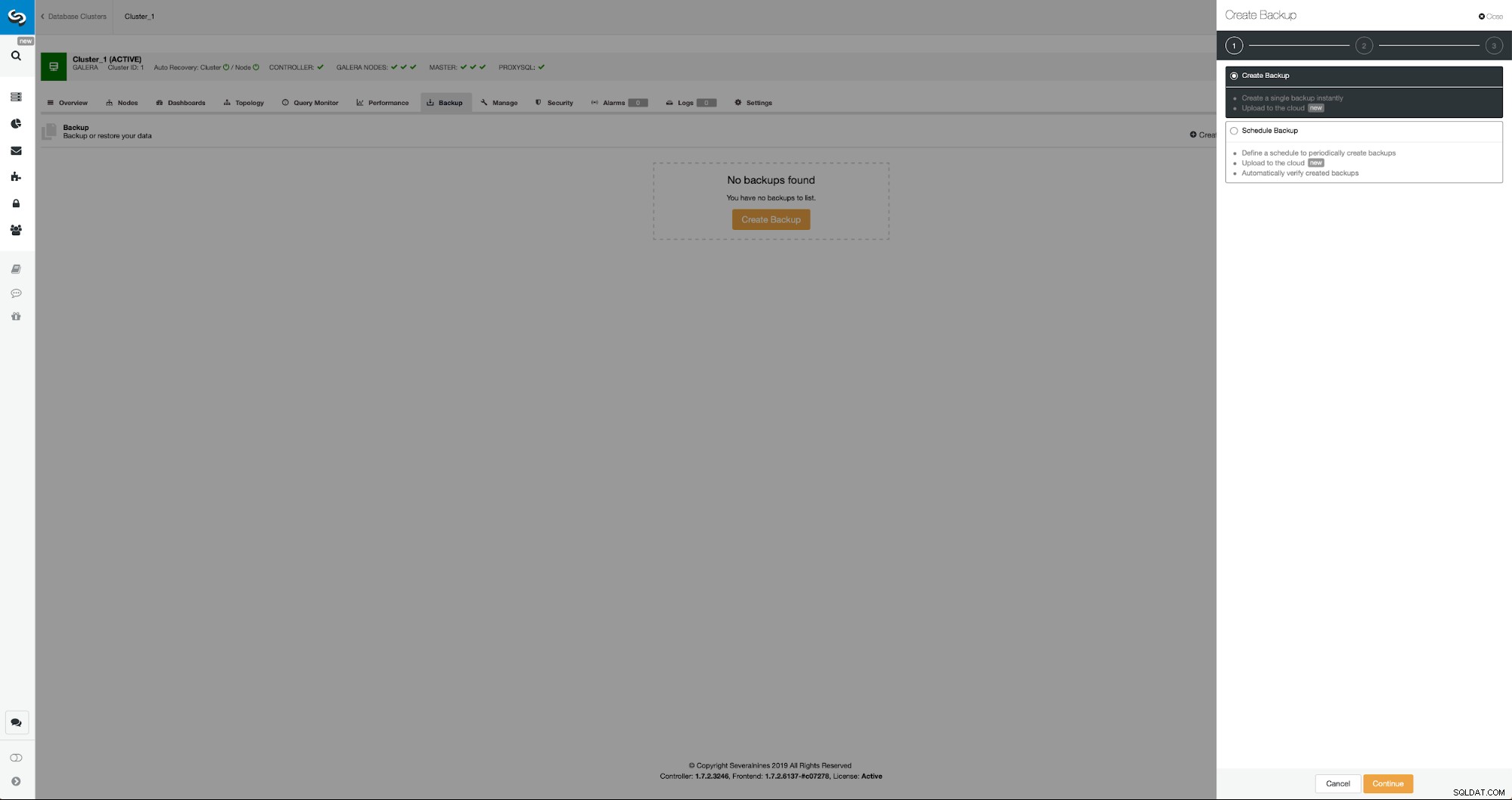
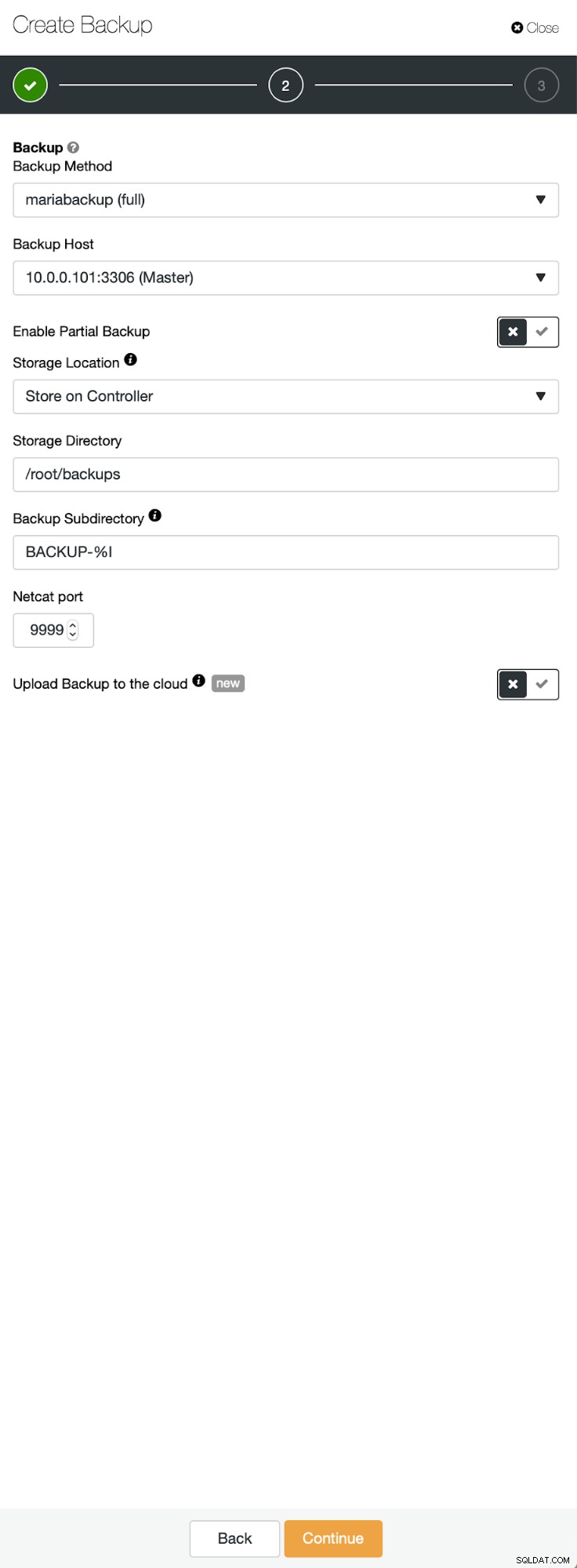
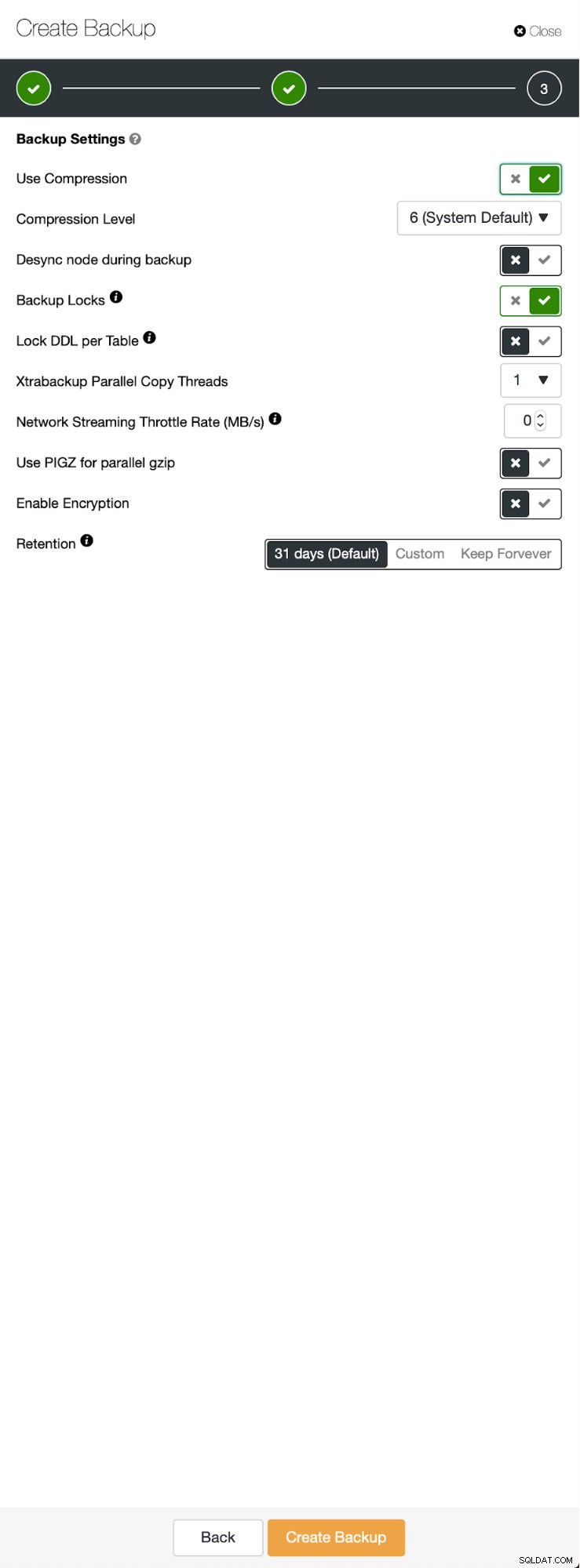
Três etapas nas quais escolhemos o nó para tirar o backup dele. Este nó (10.0.0.101) se tornará um mestre. Tem que ter logs binários habilitados. No nosso caso, todos os nós têm o binlog habilitado, mas se não tiverem é muito fácil habilitá-lo a partir do ClusterControl - mostraremos os passos mais tarde, quando o faremos para o segundo cluster.
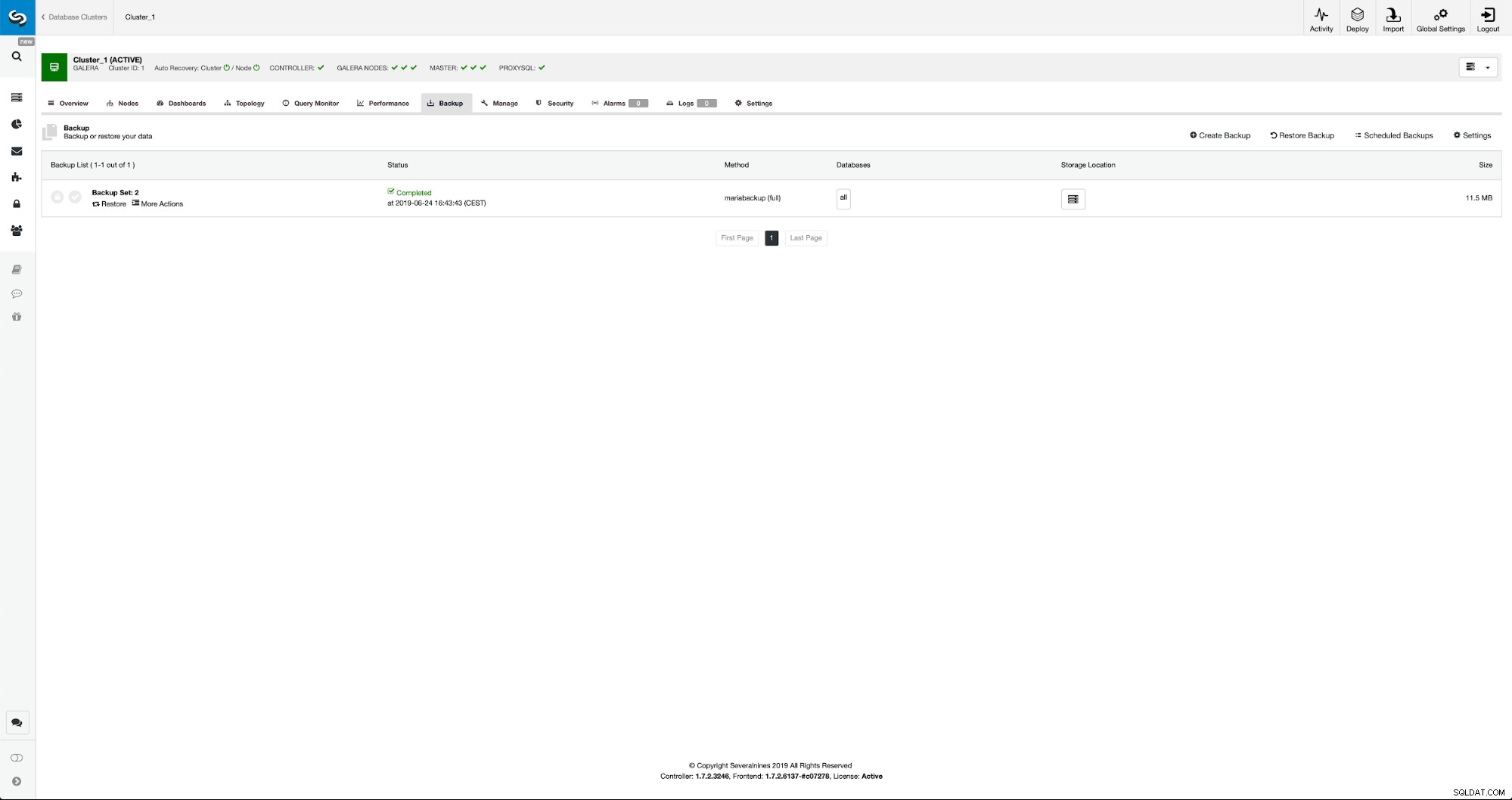
Quando o backup estiver concluído, ele ficará visível na lista. Podemos então prosseguir e restaurá-lo:

Se quisermos, poderíamos até fazer a Recuperação Point-In-Time, mas no nosso caso isso não importa muito:uma vez que a replicação esteja configurada, todas as transações necessárias dos logs binários serão aplicadas no novo cluster.

Em seguida, escolhemos a opção de criar um cluster a partir do backup. Isso abre outra caixa de diálogo:
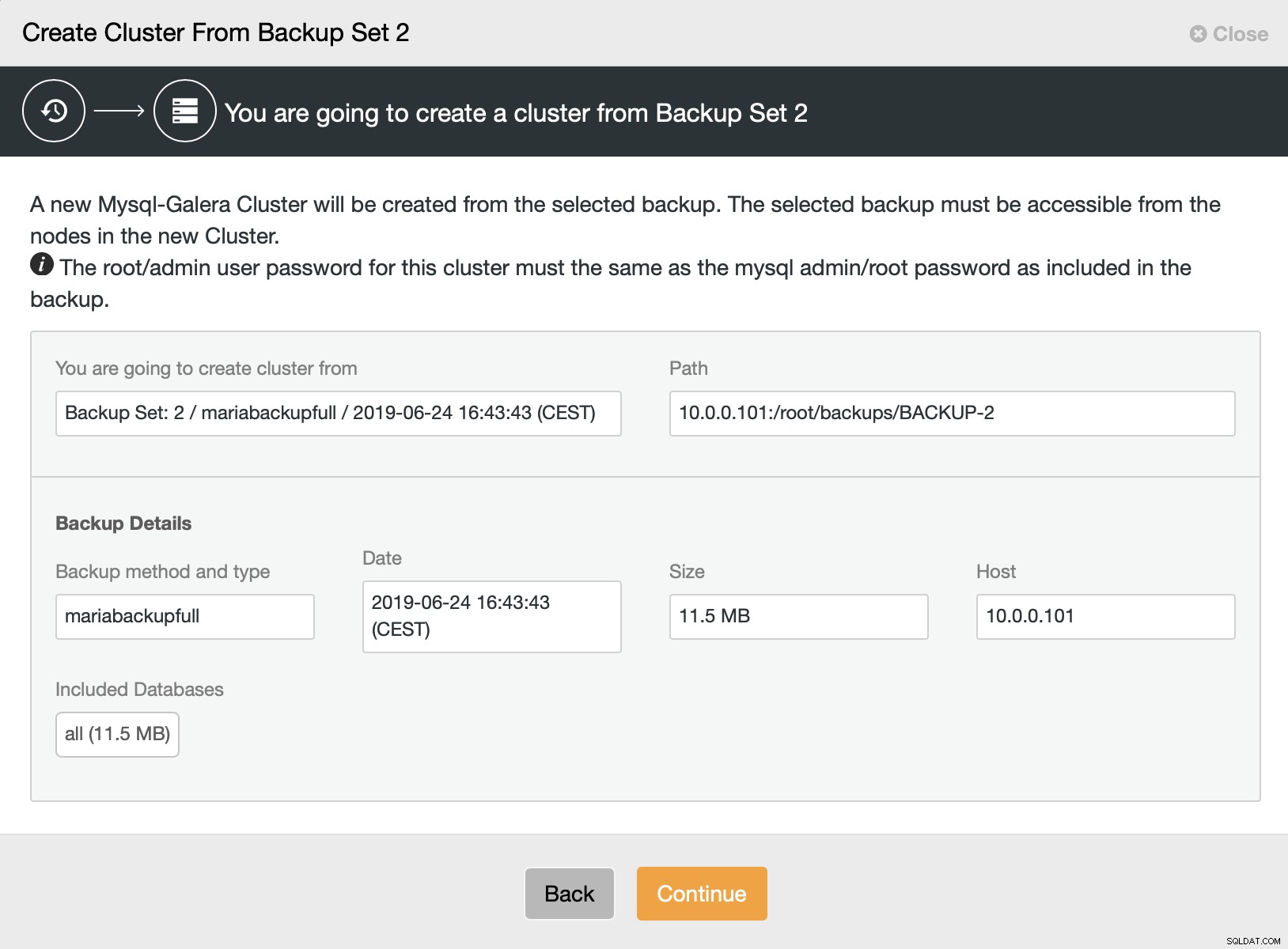
É uma confirmação de qual backup será usado, de qual host o backup foi feito, qual método foi usado para criá-lo e alguns metadados para ajudar a verificar se o backup parece bom.
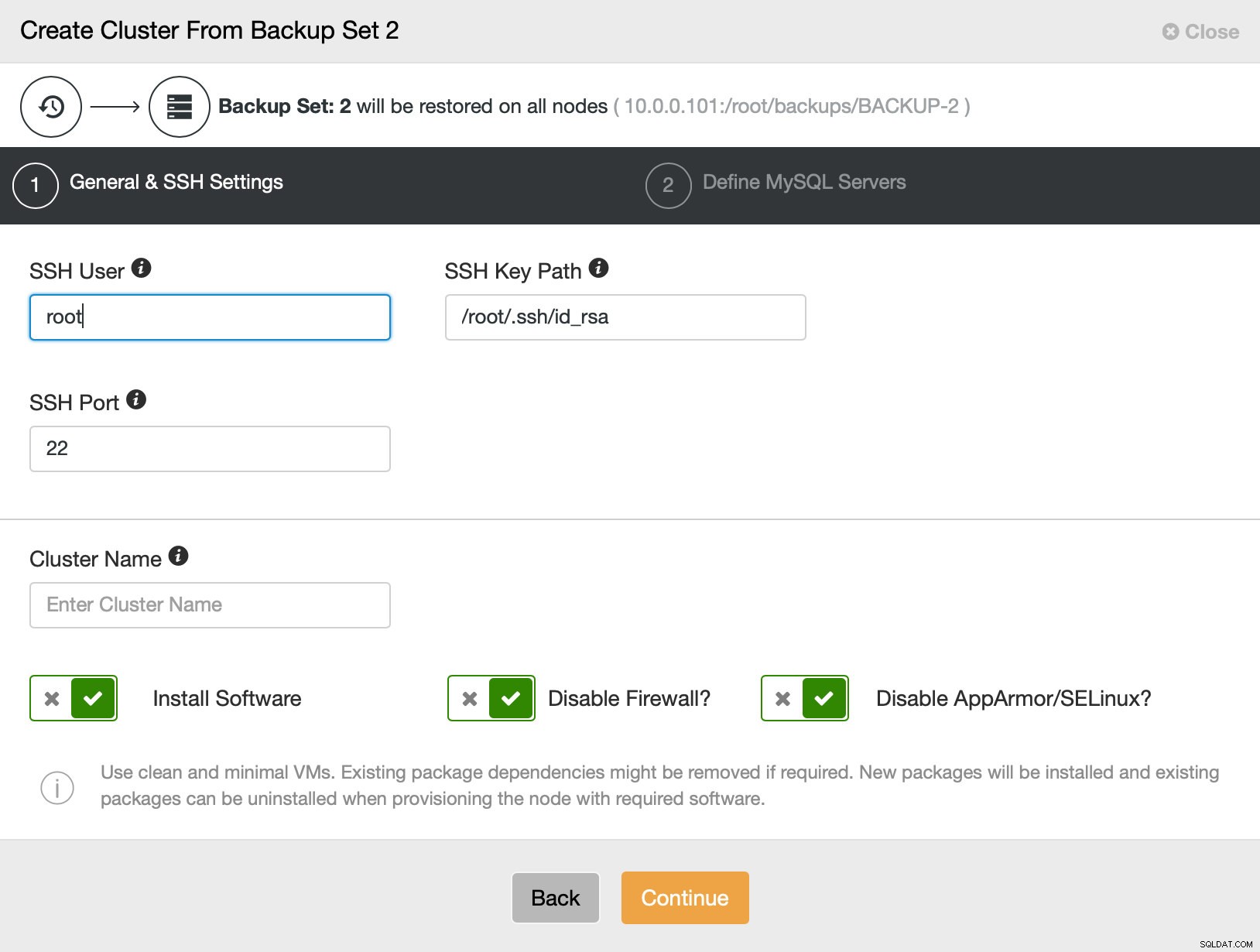
Então basicamente vamos para o assistente de implantação regular no qual temos que definir a conectividade SSH entre o host ClusterControl e os nós para implantar o cluster (o requisito para ClusterControl) e, na segunda etapa, fornecedor, versão, senha e nós para implantar em:
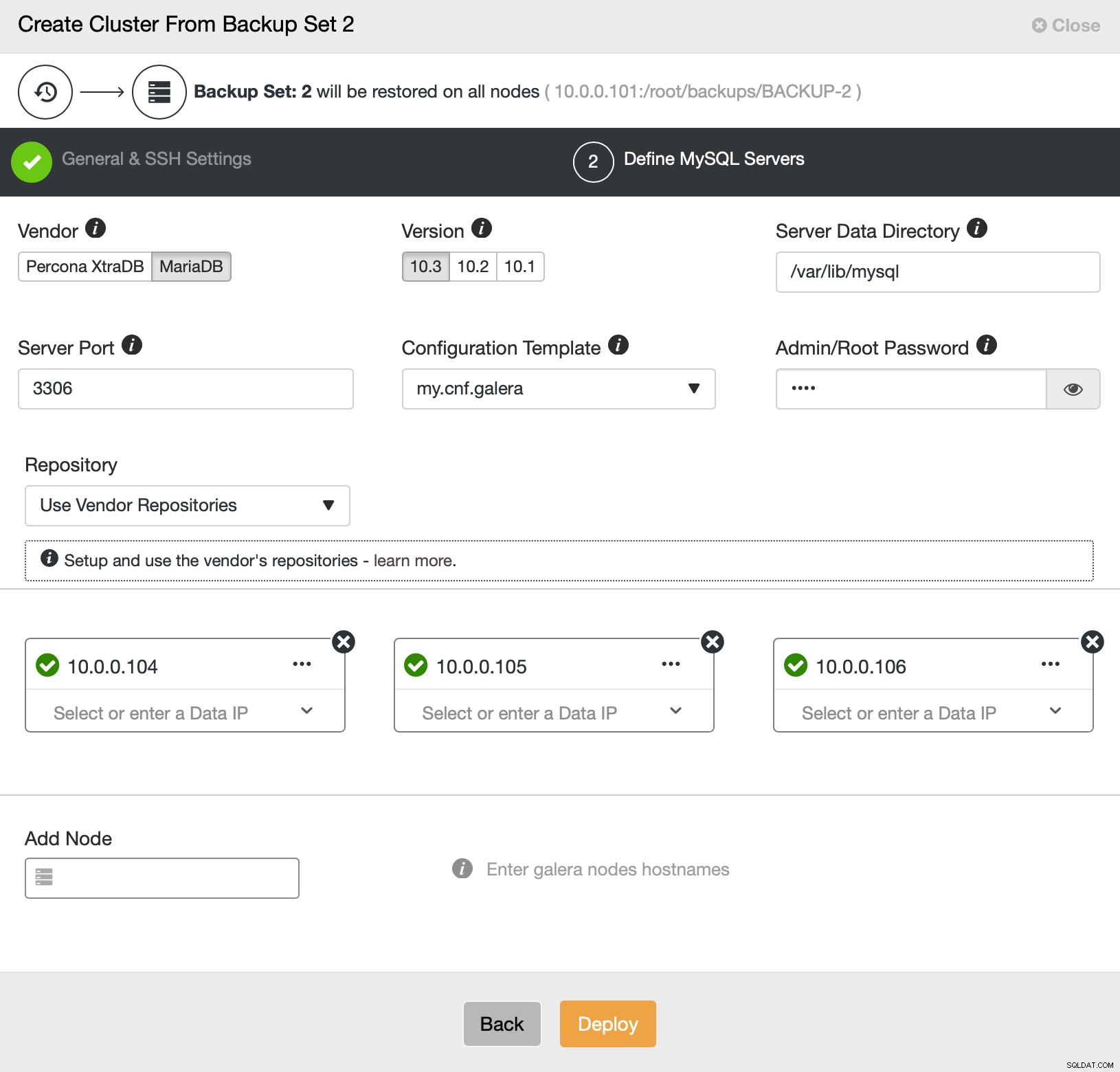
Isso é tudo sobre implantação e provisionamento. O ClusterControl configurará o novo cluster e o provisionará usando os dados do antigo.
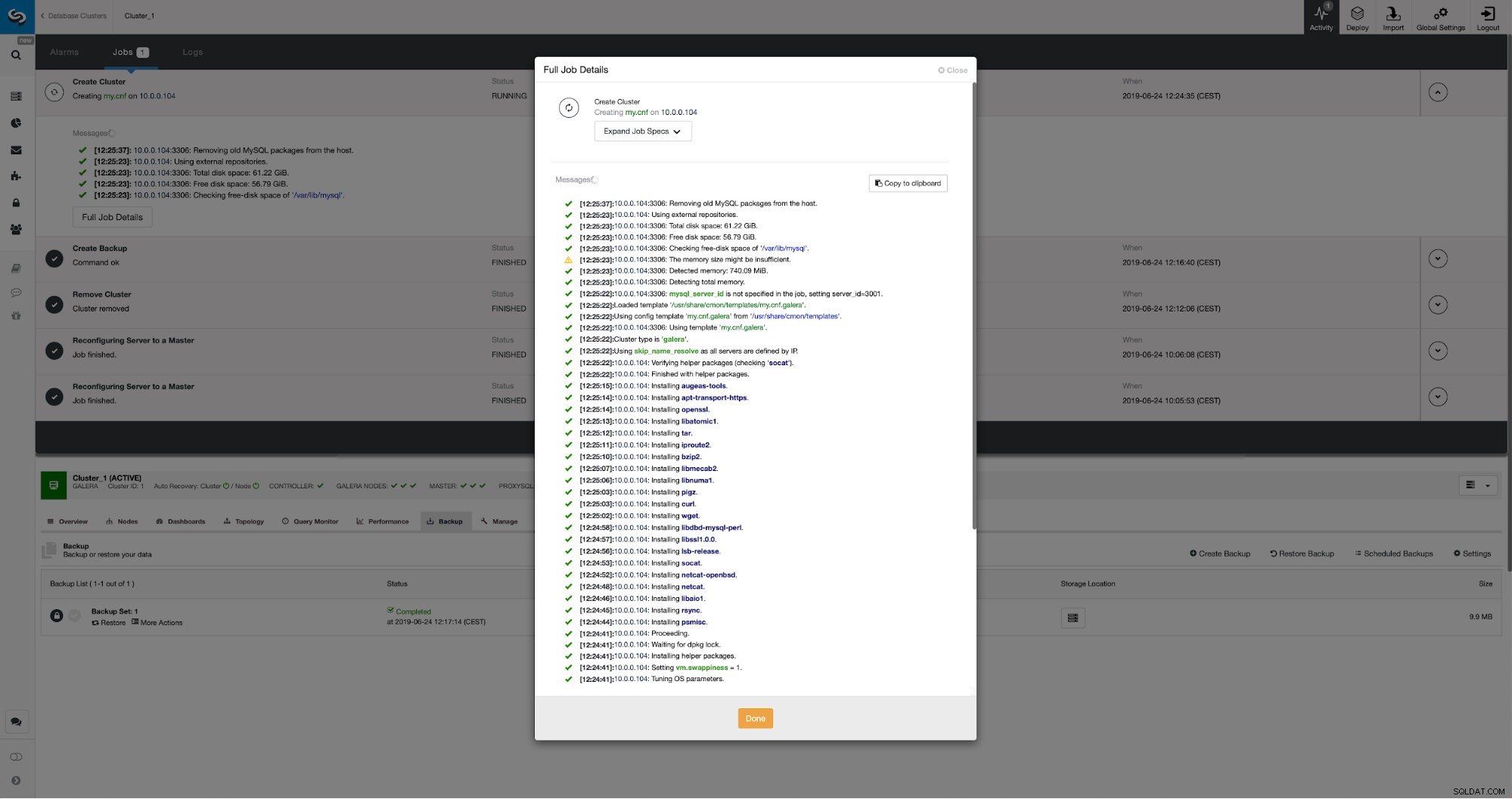
Podemos monitorar o progresso na guia de atividade. Depois de concluído, o segundo cluster aparecerá na lista de clusters no ClusterControl.
Reconfiguração do novo cluster usando ClusterControl
Agora, temos que reconfigurar o cluster - vamos habilitar os logs binários. No processo manual, tivemos que fazer alterações na configuração wsrep_sst_auth e também nas entradas de configuração nas seções [mysqldump] e [xtrabackup] do arquivo config. Essas configurações podem ser encontradas no arquivo secrets-backup.cnf. Desta vez não é necessário, pois o ClusterControl gerou novas senhas para o cluster e configurou os arquivos corretamente. O que é importante ter em mente, porém, se você alterar a senha do usuário 'backupuser'@'127.0.0.1' no cluster original, você terá que fazer alterações de configuração no segundo cluster também para refletir isso como alterações no o primeiro cluster será replicado para o segundo cluster.
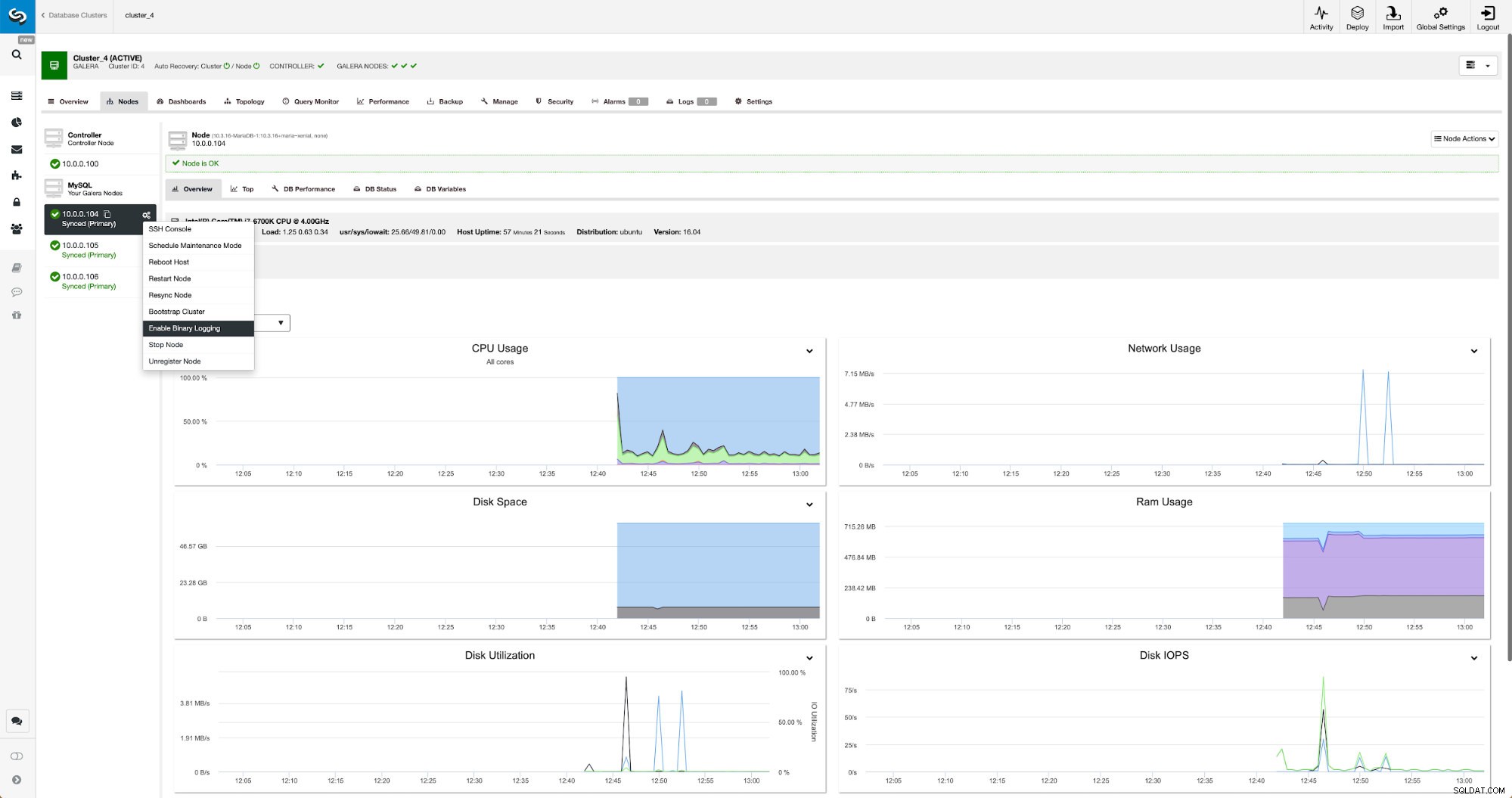
Os logs binários podem ser habilitados na seção Nós. Você precisa escolher nó por nó e executar o trabalho “Ativar log binário”. Você será apresentado a uma caixa de diálogo:
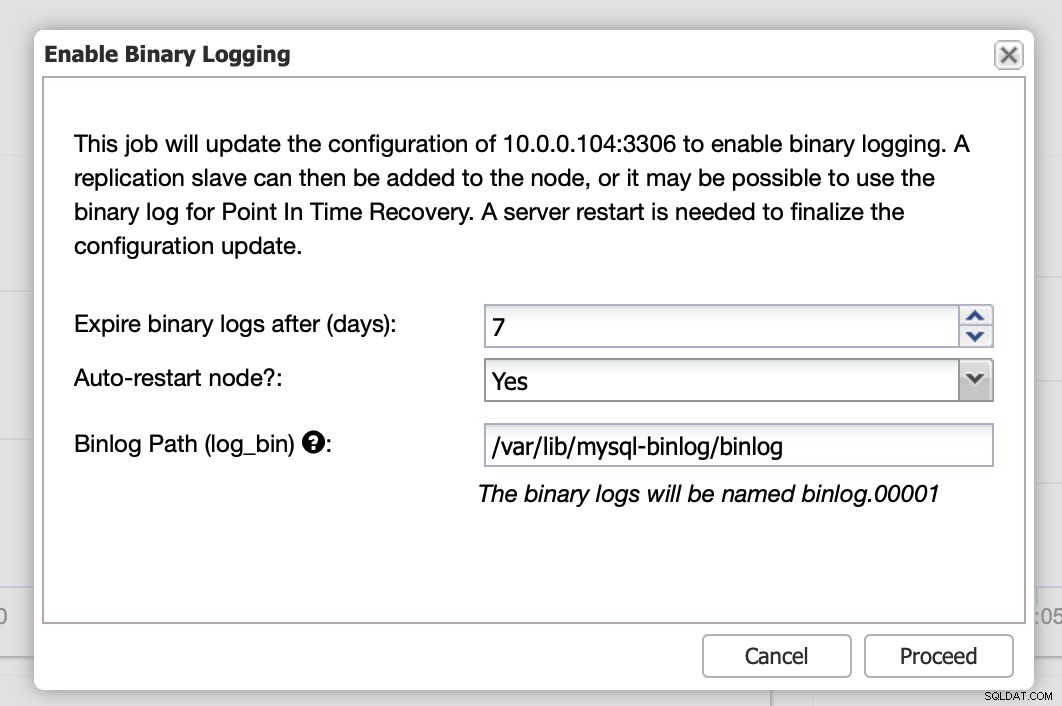
Aqui você pode definir por quanto tempo deseja manter os logs, onde eles devem ser armazenados e se o ClusterControl deve reiniciar o nó para você aplicar as alterações - a configuração do log binário não é dinâmica e o MariaDB deve ser reiniciado para aplicar essas alterações.
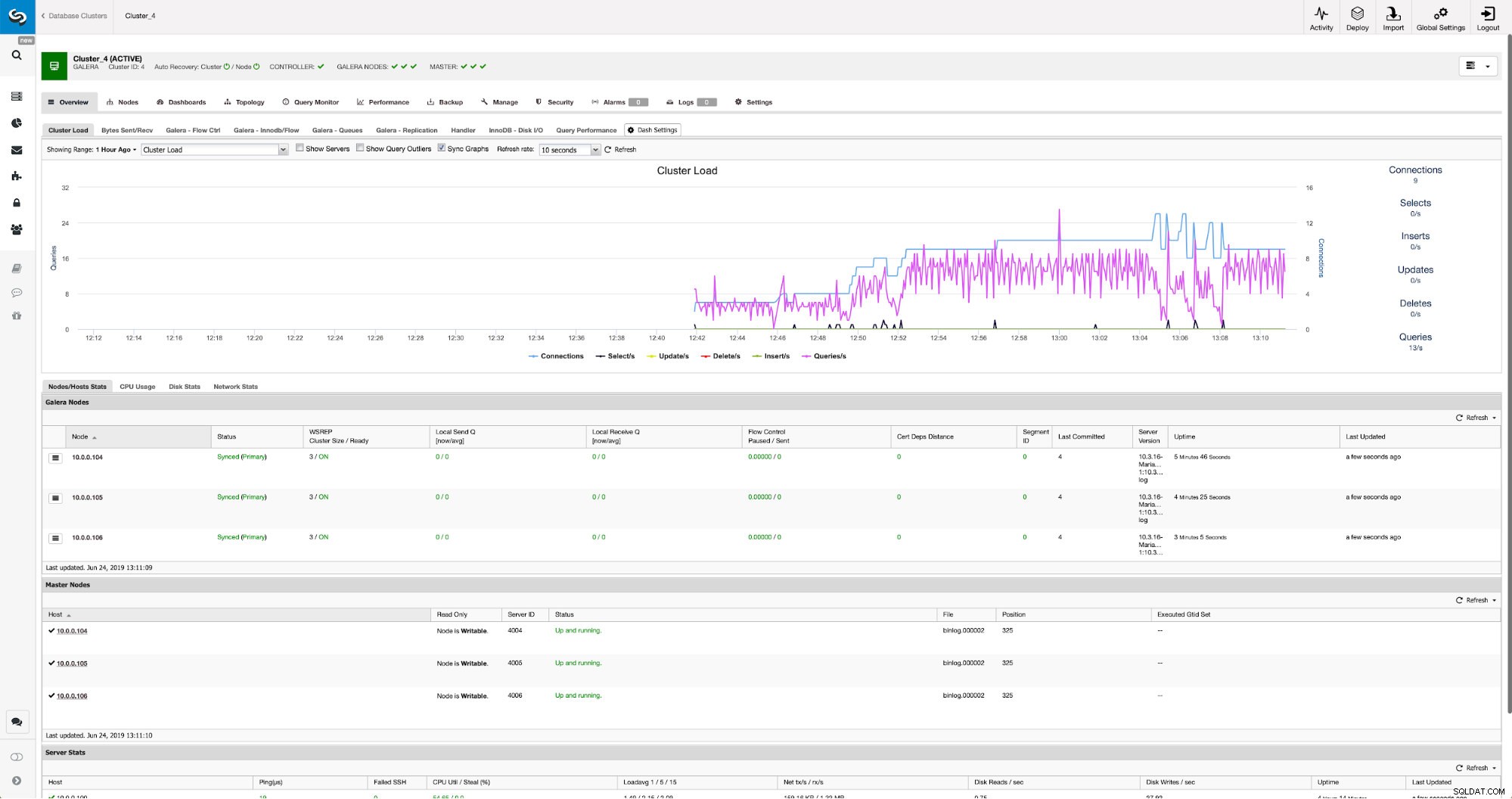
Quando as alterações forem concluídas, você verá todos os nós marcados como “mestre”, o que significa que esses nós têm o log binário ativado e podem atuar como mestres.
Se ainda não tivermos um usuário de replicação criado, teremos que fazer isso. No primeiro cluster temos que ir em Gerenciar -> Esquemas e Usuários:
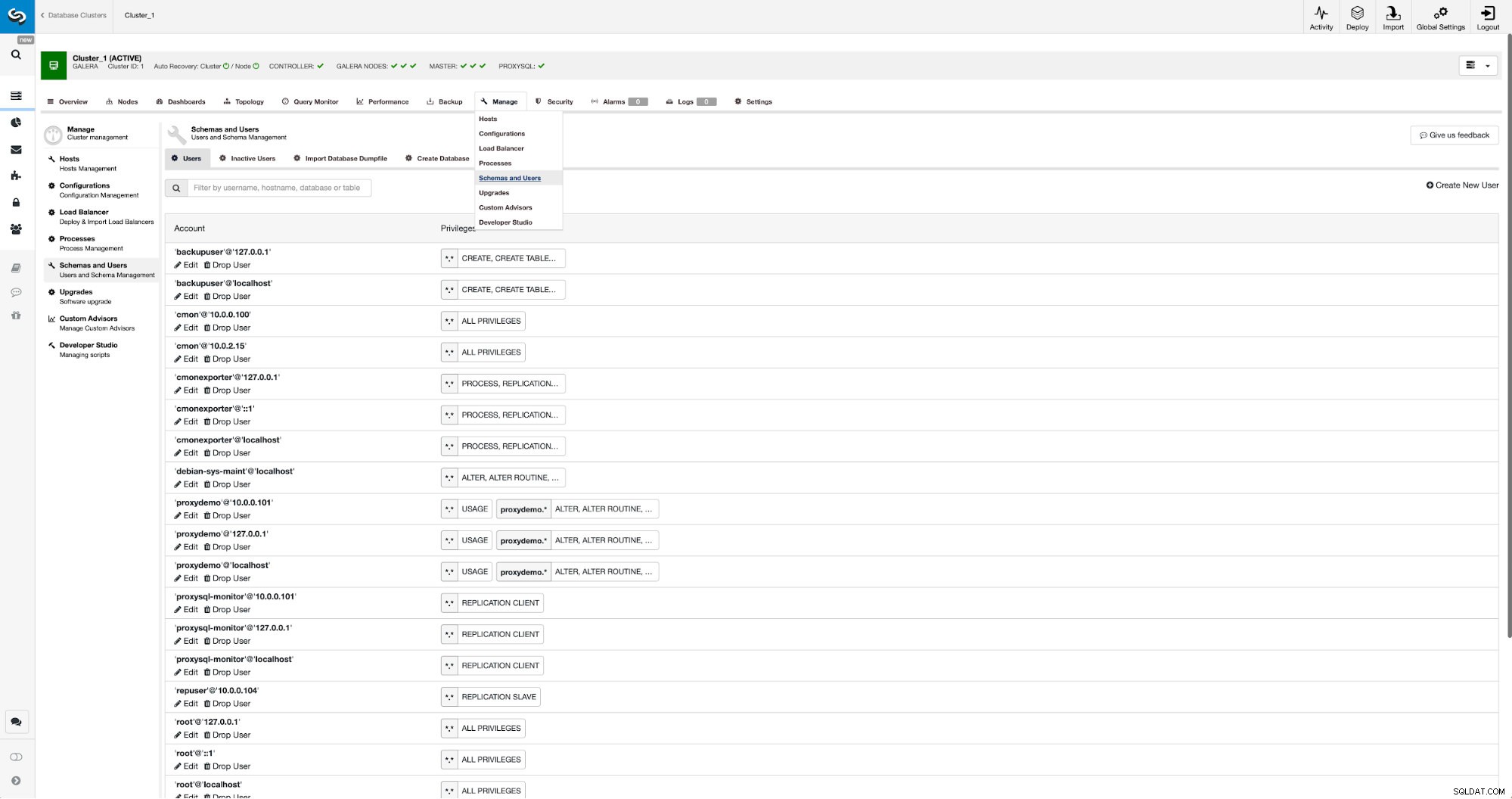
No lado direito temos a opção de criar um novo usuário:
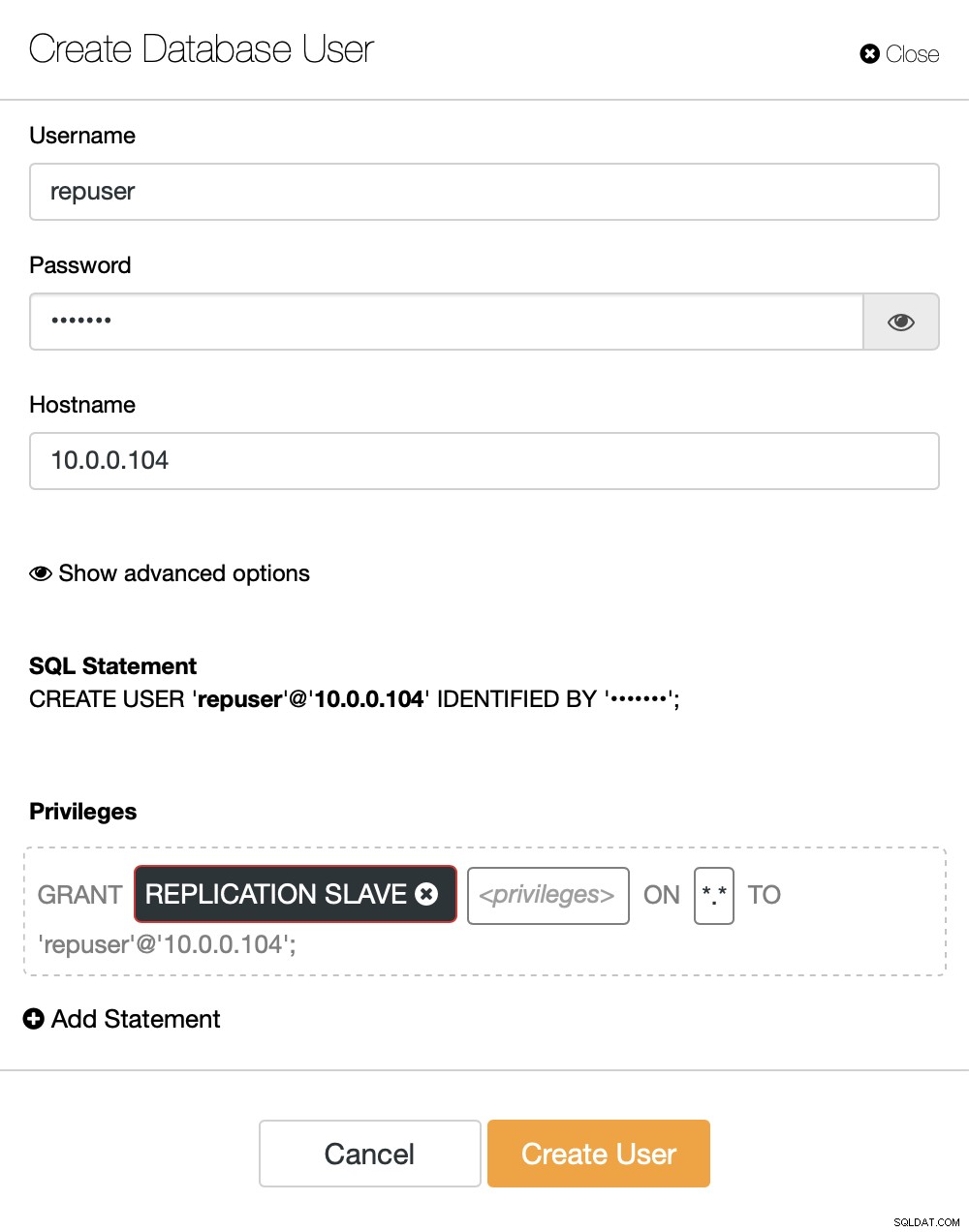
Isso conclui a configuração necessária para configurar a replicação.
Configurando a replicação entre clusters usando ClusterControl
Como dissemos, estamos trabalhando na automatização dessa parte. Atualmente tem que ser feito manualmente. Como você deve se lembrar, precisamos da posição GITD do nosso backup e, em seguida, executamos alguns comandos usando o MySQL CLI. Os dados GTID estão disponíveis no backup. ClusterControl cria backup usando xbstream/mbstream e o compacta depois. Nosso backup é armazenado no host ClusterControl onde não temos acesso ao binário mbstream. Você pode tentar instalá-lo ou copiar o arquivo de backup para o local onde esse binário está disponível:
scp /root/backups/BACKUP-2/ backup-full-2019-06-24_144329.xbstream.gz 10.0.0.104:/root/mariabackup/Feito isso, em 10.0.0.104 queremos verificar o conteúdo do arquivo xtrabackup_info:
cd /root/mariabackup
zcat backup-full-2019-06-24_144329.xbstream.gz | mbstream -x
example@sqldat.com:~/mariabackup# cat /root/mariabackup/xtrabackup_info | grep binlog_pos
binlog_pos = filename 'binlog.000007', position '379', GTID of the last change '9999-1002-846116'Por fim, configuramos a replicação e a iniciamos:
MariaDB [(none)]> SET GLOBAL gtid_slave_pos ='9999-1002-846116';
Query OK, 0 rows affected (0.024 sec)MariaDB [(none)]> CHANGE MASTER TO MASTER_HOST='10.0.0.101', MASTER_PORT=3306, MASTER_USER='repuser', MASTER_PASSWORD='reppass', MASTER_USE_GTID=slave_pos;
Query OK, 0 rows affected (0.024 sec)MariaDB [(none)]> START SLAVE;
Query OK, 0 rows affected (0.010 sec)É isso - acabamos de configurar a replicação assíncrona entre dois clusters MariaDB Galera usando o ClusterControl. Como você pode ver, o ClusterControl conseguiu automatizar a maioria das etapas que tivemos que seguir para configurar esse ambiente.