Toda empresa lucrativa requer alta disponibilidade. Sites e blogs não são diferentes, pois empresas e indivíduos ainda menores exigem que seus sites permaneçam ativos para manter sua reputação.
O WordPress é, de longe, o CMS mais popular do mundo, alimentando milhões de sites de pequeno a grande porte. Mas como você pode garantir que seu site permaneça ativo. Mais especificamente, como posso garantir que a indisponibilidade do meu banco de dados não afetará meu site?
Nesta postagem de blog, mostraremos como obter failover para seu site WordPress usando o ClusterControl.
A configuração que usaremos para este blog usará o Percona Server 5.7. Teremos outro host que contém o aplicativo Apache e Wordpress. Não tocaremos na parte de alta disponibilidade do aplicativo, mas também algo que você deseja ter. Usaremos o ClusterControl para gerenciar bancos de dados para garantir a disponibilidade e usaremos um terceiro host para instalar e configurar o próprio ClusterControl.
Supondo que o ClusterControl esteja funcionando, precisaremos importar nosso banco de dados existente para ele.
Importando um cluster de banco de dados com ClusterControl
Vá para a opção Importar Servidor/Banco de Dados Existente no assistente de implantação.
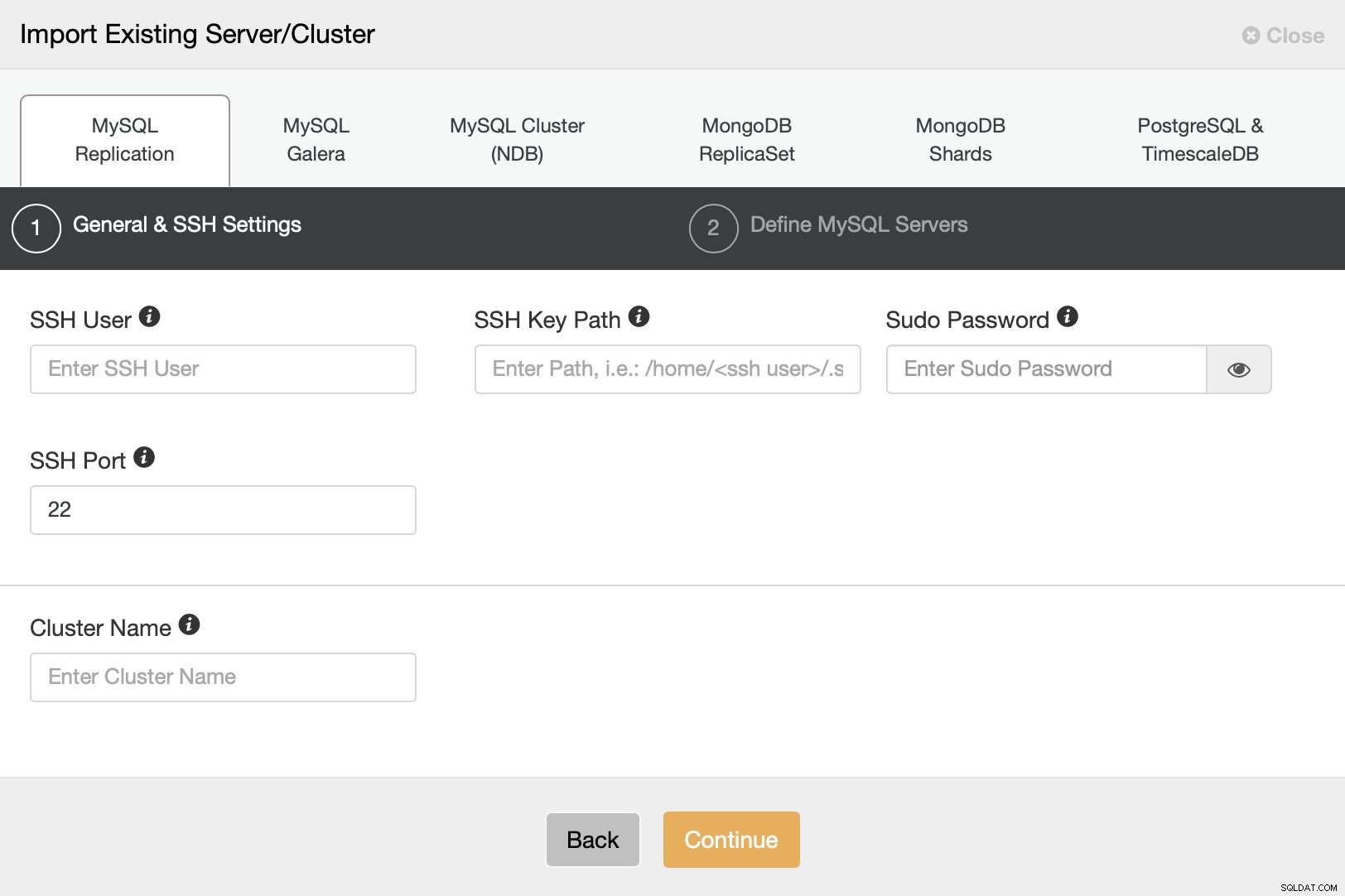
Temos que configurar a conectividade SSH, pois este é um requisito para o ClusterControl ser capaz de gerenciar os nós.
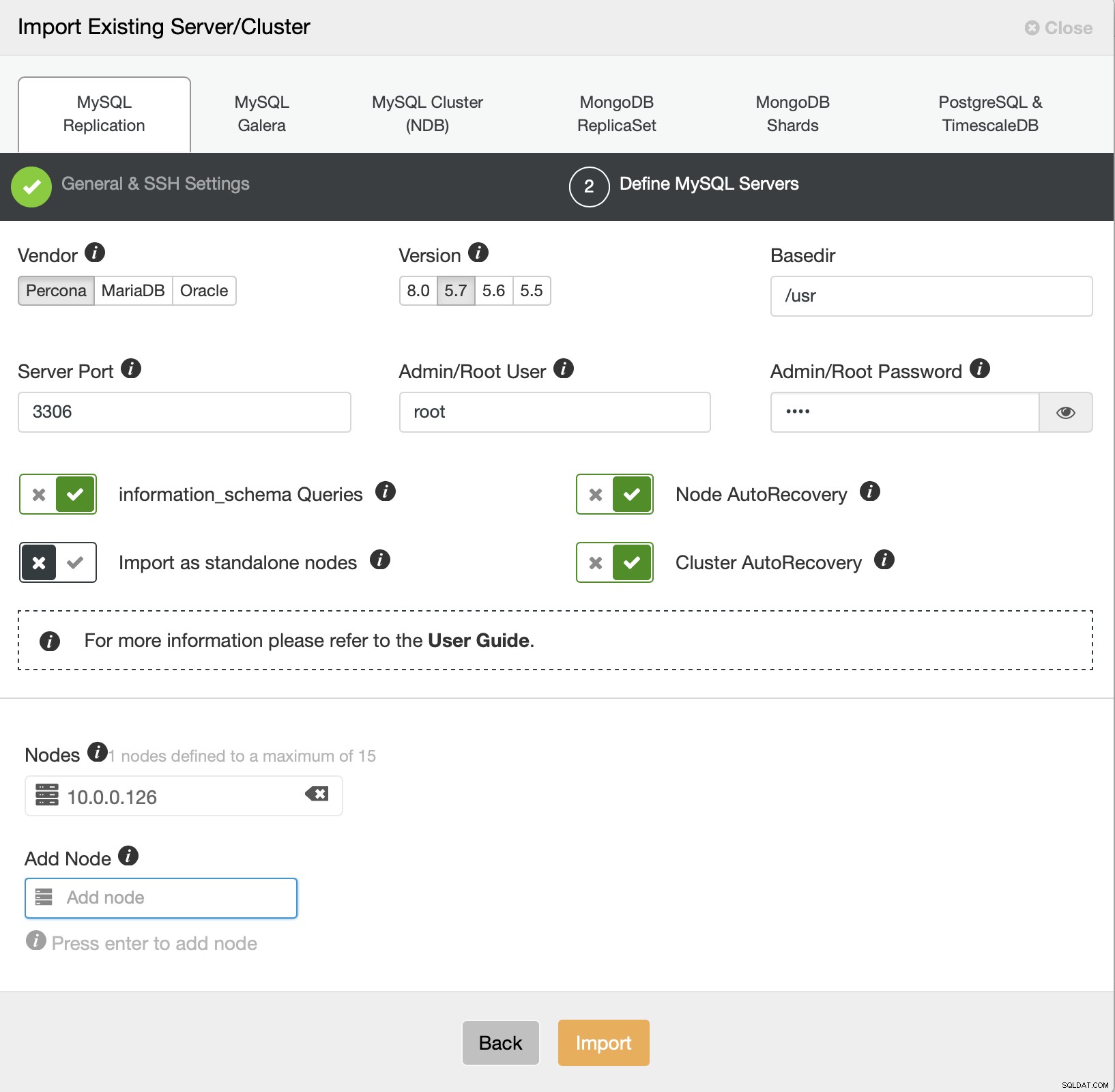
Agora temos que definir alguns detalhes sobre o fornecedor, versão, usuário root acesso, o próprio nó e se queremos que o ClusterControl gerencie a recuperação automática para nós ou não. Isso é tudo, assim que o trabalho for bem-sucedido, você verá um cluster na lista.
Para configurar o ambiente altamente disponível, precisamos executar alguns de ações. Nosso ambiente será composto por...
- Par Mestre - Escravo
- Duas instâncias do ProxySQL para divisão de leitura/gravação e detecção de topologia
- Duas instâncias Keepalived para gerenciamento de IP virtual
A ideia é simples - vamos implantar o escravo em nosso mestre para que tenhamos uma segunda instância para fazer o failover caso o mestre falhe. O ClusterControl será responsável pela detecção de falhas e promoverá o escravo caso o mestre fique indisponível. O ProxySQL manterá o controle da topologia de replicação e redirecionará o tráfego para o nó correto - as gravações serão enviadas para o mestre, não importa em qual nó esteja, as leituras podem ser enviadas somente para mestre ou distribuídas entre mestre e escravos . Por fim, Keepalived será colocado com ProxySQL e fornecerá VIP para o aplicativo se conectar. Esse VIP sempre será atribuído a uma das instâncias do ProxySQL e o Keepalived o moverá para a segunda, caso o nó ProxySQL “principal” falhe.
Tendo dito tudo isso, vamos configurar isso usando o ClusterControl. Tudo isso pode ser feito em apenas alguns cliques. Vamos começar adicionando o slave.
Adicionando um escravo de banco de dados com ClusterControl

Começamos escolhendo o trabalho “Add Replication Slave”. Em seguida, somos solicitados a preencher um formulário:
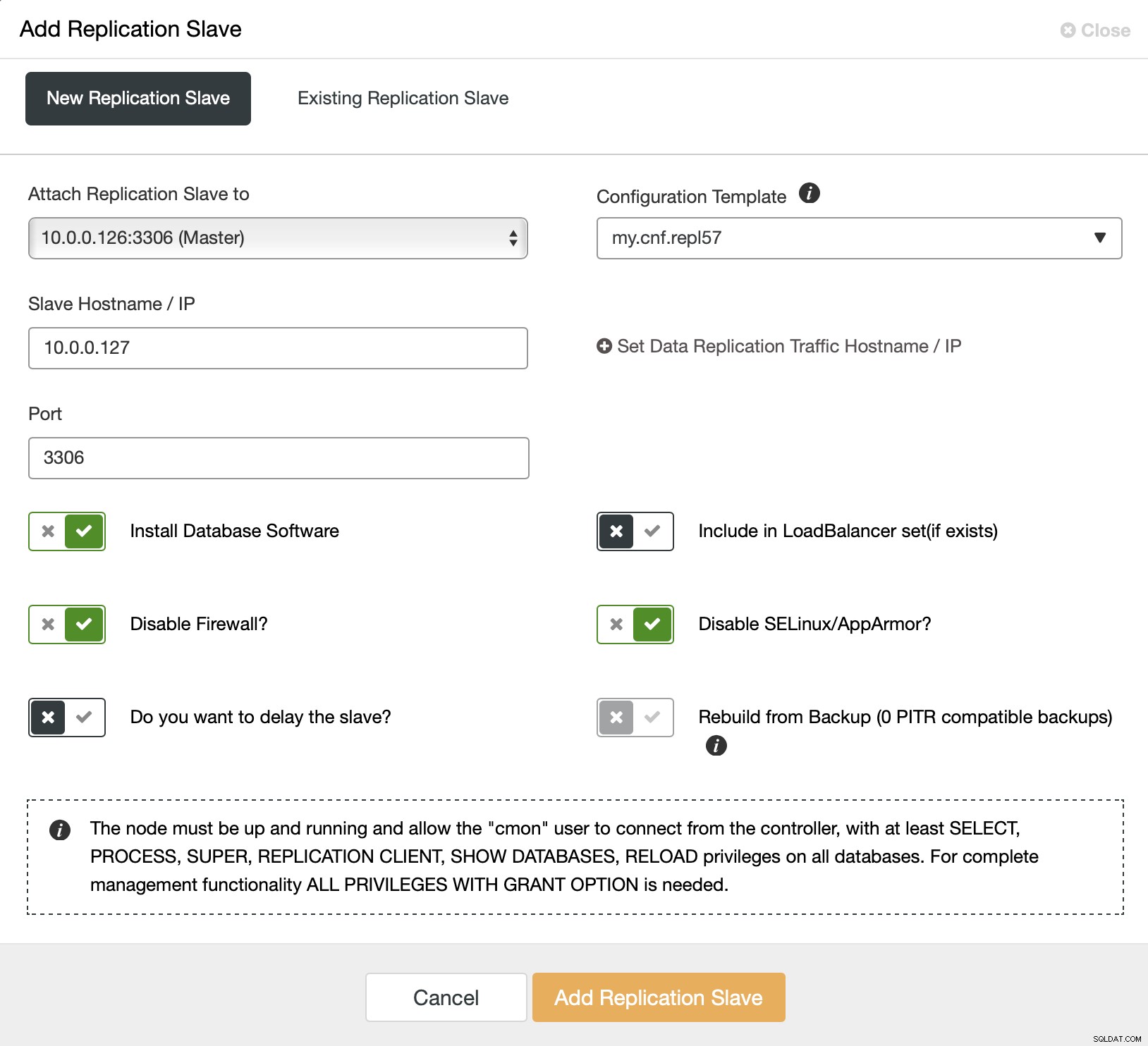
Temos que escolher o master (no nosso caso não tem muitas opções), temos que passar o IP ou hostname para o novo escravo. Se tivéssemos backups criados anteriormente, poderíamos usar um deles para provisionar o escravo. No nosso caso, isso não está disponível e o ClusterControl provisionará o escravo diretamente do mestre. Isso é tudo, o trabalho é iniciado e o ClusterControl executa as ações necessárias. Você pode monitorar o progresso na guia Atividade.

Finalmente, uma vez que o trabalho seja concluído com sucesso, o escravo deve estar visível no lista de clusters.

Agora continuaremos com a configuração das instâncias do ProxySQL. No nosso caso, o ambiente é mínimo, então, para simplificar, vamos localizar o ProxySQL em um dos nós do banco de dados. Esta não é, no entanto, a melhor opção em um ambiente de produção real. Idealmente, o ProxySQL estaria localizado em um nó separado ou colocado com os outros hosts de aplicativos.
O local para iniciar o trabalho é Manage -> Loadbalancers.
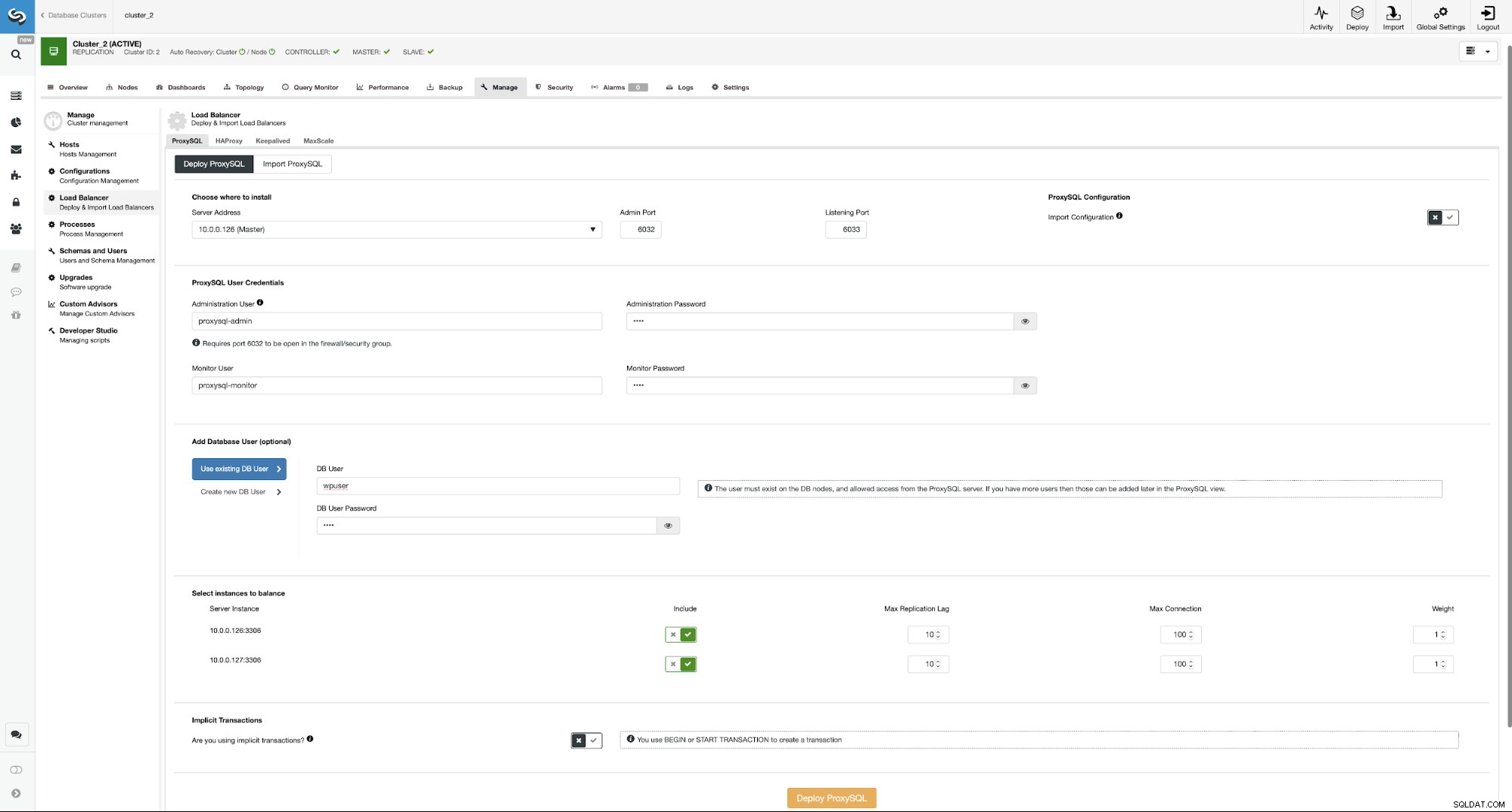
Aqui você deve escolher onde o ProxySQL deve ser instalado, passar credenciais administrativas e adicione um usuário de banco de dados. No nosso caso, usaremos nosso usuário existente, pois nosso aplicativo WordPress já o usa para se conectar ao banco de dados. Em seguida, temos que escolher quais nós usar no ProxySQL (queremos mestre e escravo aqui) e informar ao ClusterControl se usamos transações explícitas ou não. Isso não é realmente relevante em nosso caso, pois reconfiguraremos o ProxySQL assim que ele for implantado. Quando você tiver essa opção habilitada, a divisão de leitura/gravação não será habilitada. Caso contrário, o ClusterControl configurará o ProxySQL para divisão de leitura/gravação. Em nossa configuração mínima, devemos pensar seriamente se queremos que a divisão de leitura/gravação aconteça. Vamos analisar isso.
As vantagens e desvantagens de leitura/gravação Spit no ProxySQL
A principal vantagem de usar a divisão de leitura/gravação é que todo o tráfego SELECT será distribuído entre o mestre e o escravo. Isso significa que a carga nos nós será menor e o tempo de resposta também deverá ser menor. Isso soa bem, mas lembre-se de que, caso um nó falhe, o outro nó terá que ser capaz de acomodar todo o tráfego. Há pouco sentido em ter um failover automatizado em vigor se a perda de um nó significa que o segundo nó ficará sobrecarregado e, de fato, indisponível também.
Pode fazer sentido distribuir a carga se você tiver vários escravos - perder um nó em cinco é menos impactante do que perder um em dois. Não importa o que você decidir, você pode alterar facilmente o comportamento indo para o nó ProxySQL e clicando na guia Regras.
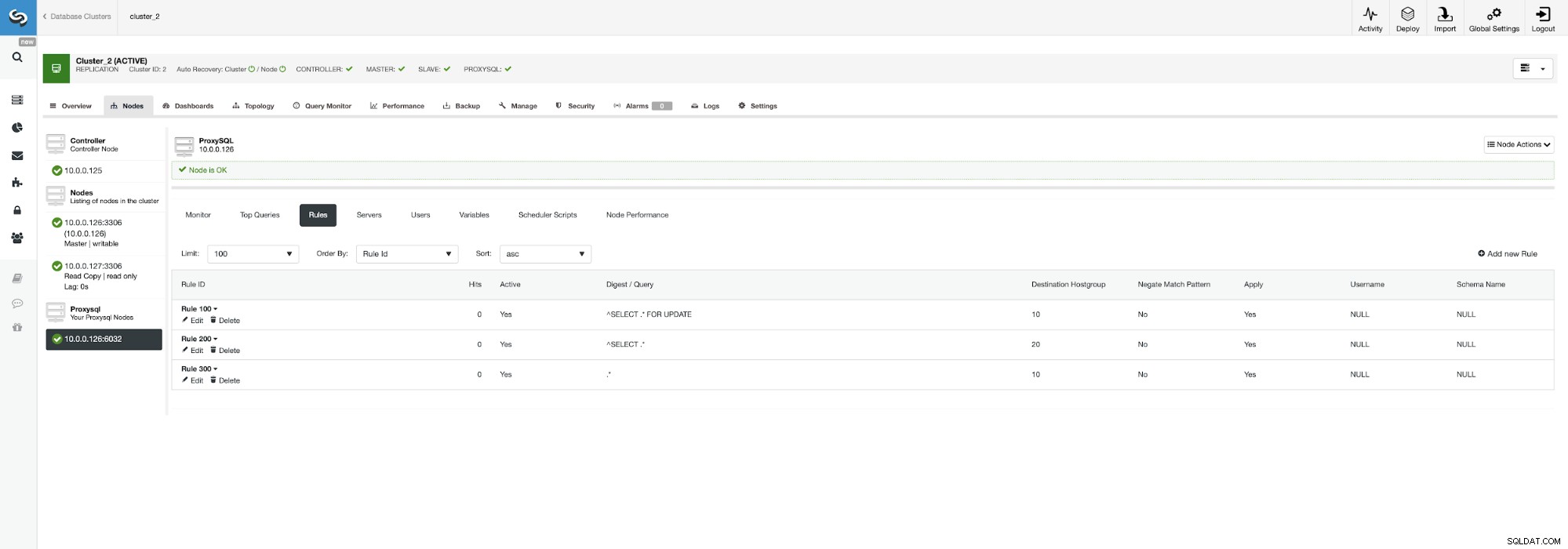
Certifique-se de observar a regra 200 (a que captura todas as instruções SELECT ). Na captura de tela abaixo, você pode ver que o hostgroup de destino é 20, o que significa que todos os nós no cluster - a divisão de leitura/gravação e a expansão estão habilitadas. Podemos desabilitar isso facilmente editando esta regra e alterando o Destination Hostgroup para 10 (aquele que contém master).
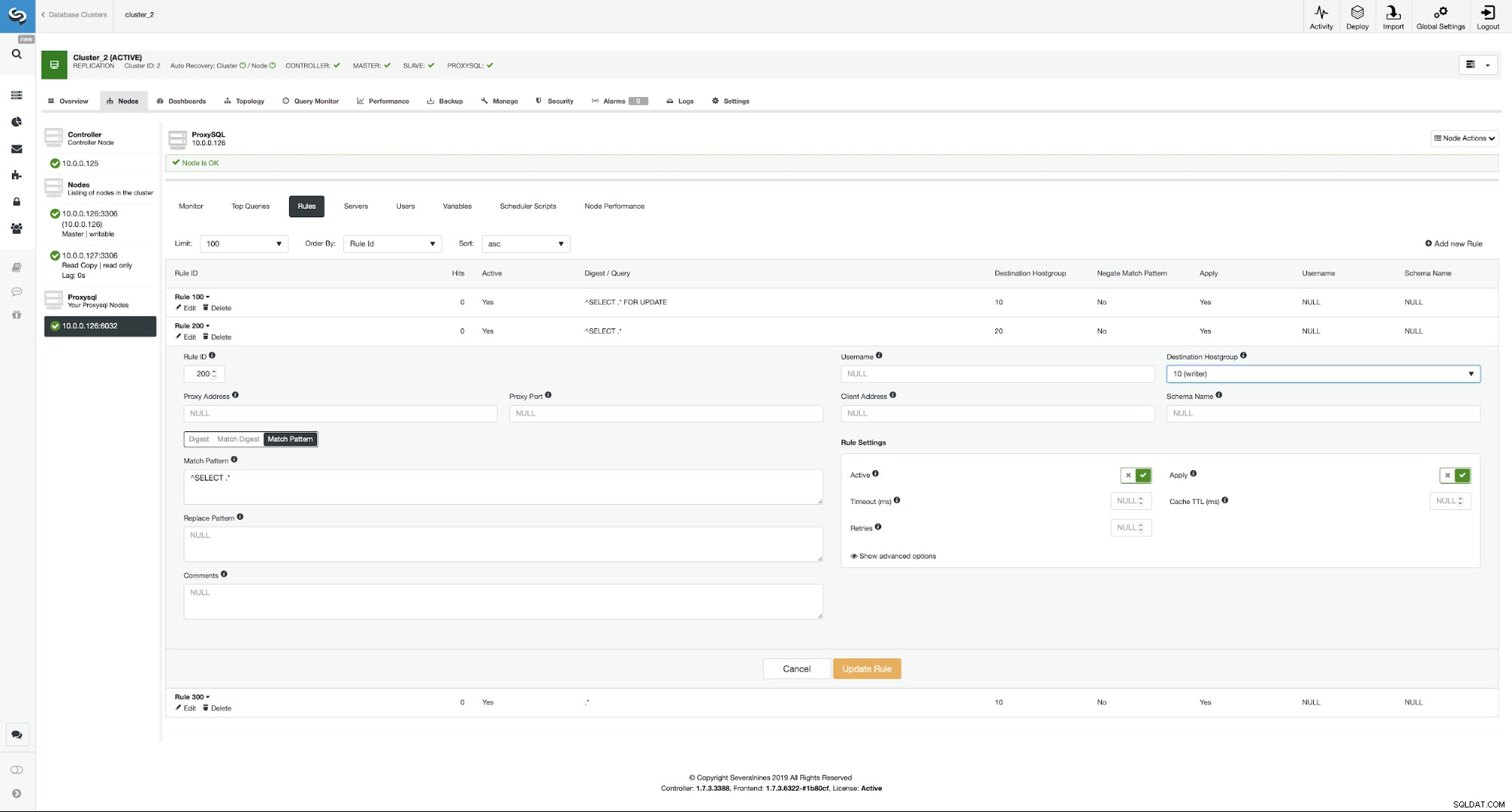
Se você quiser habilitar a divisão de leitura/gravação, você pode facilmente faça isso editando esta regra de consulta novamente e definindo o hostgroup de destino de volta para 20.
Agora, vamos implantar o segundo ProxySQL.
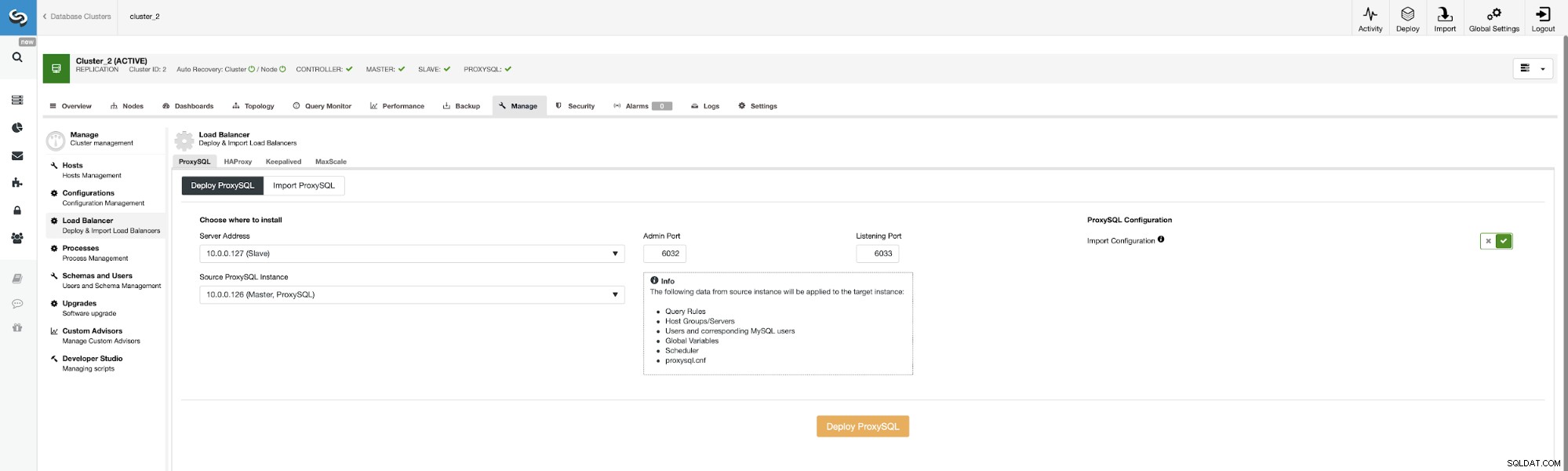
Para evitar passar todas as opções de configuração novamente, podemos usar a opção “Import Configuration ” e escolha nosso ProxySQL existente como a fonte.
Quando este trabalho for concluído, ainda teremos que executar a última etapa na configuração do nosso ambiente. Temos que implantar o Keepalived sobre as instâncias do ProxySQL.
Implantando Keepalived em instâncias ProxySQL
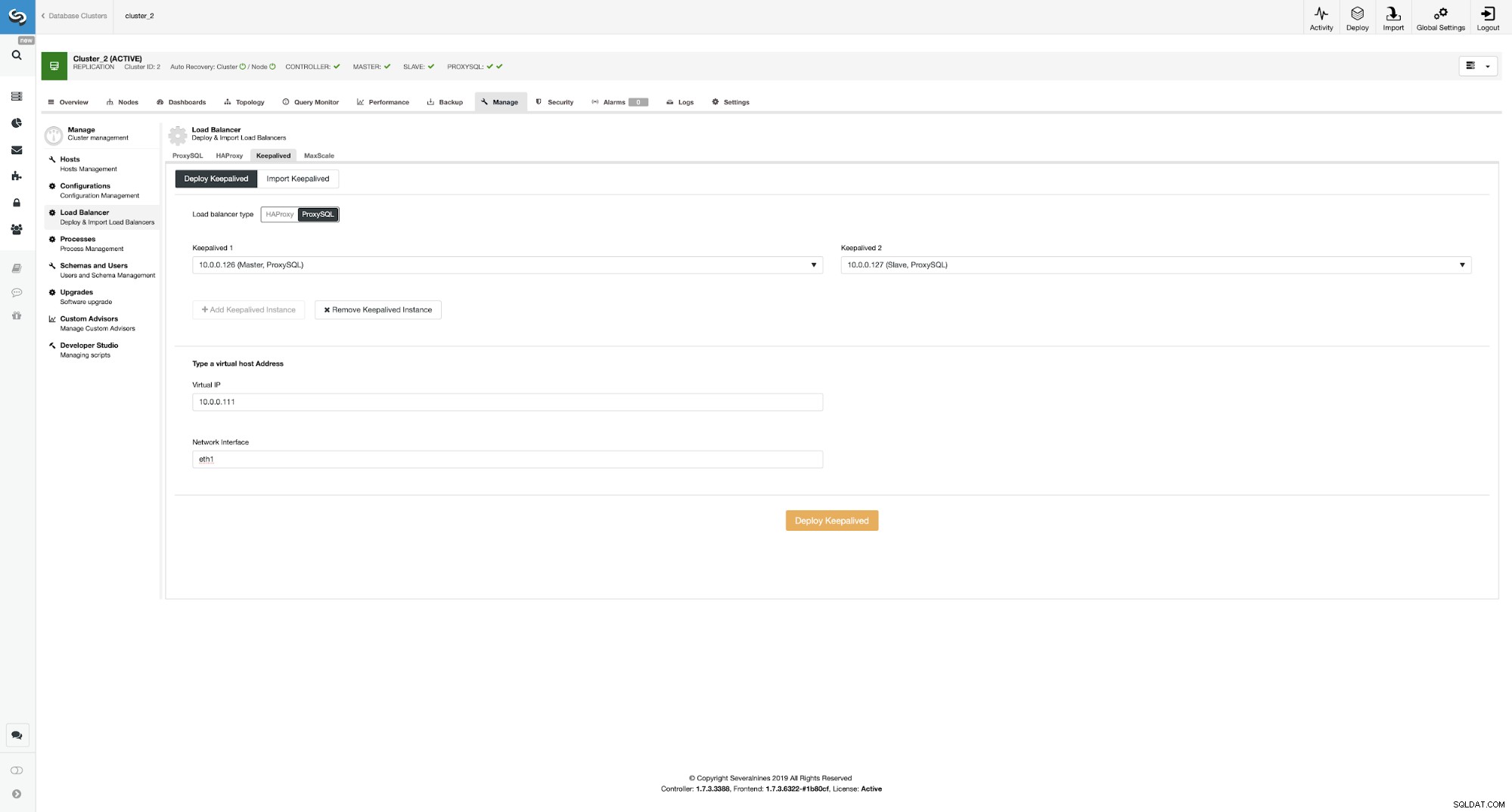
Aqui escolhemos ProxySQL como o tipo de balanceador de carga, passamos ambas as instâncias ProxySQL para Keepalived para ser instalado e digitamos nossa interface VIP e de rede.
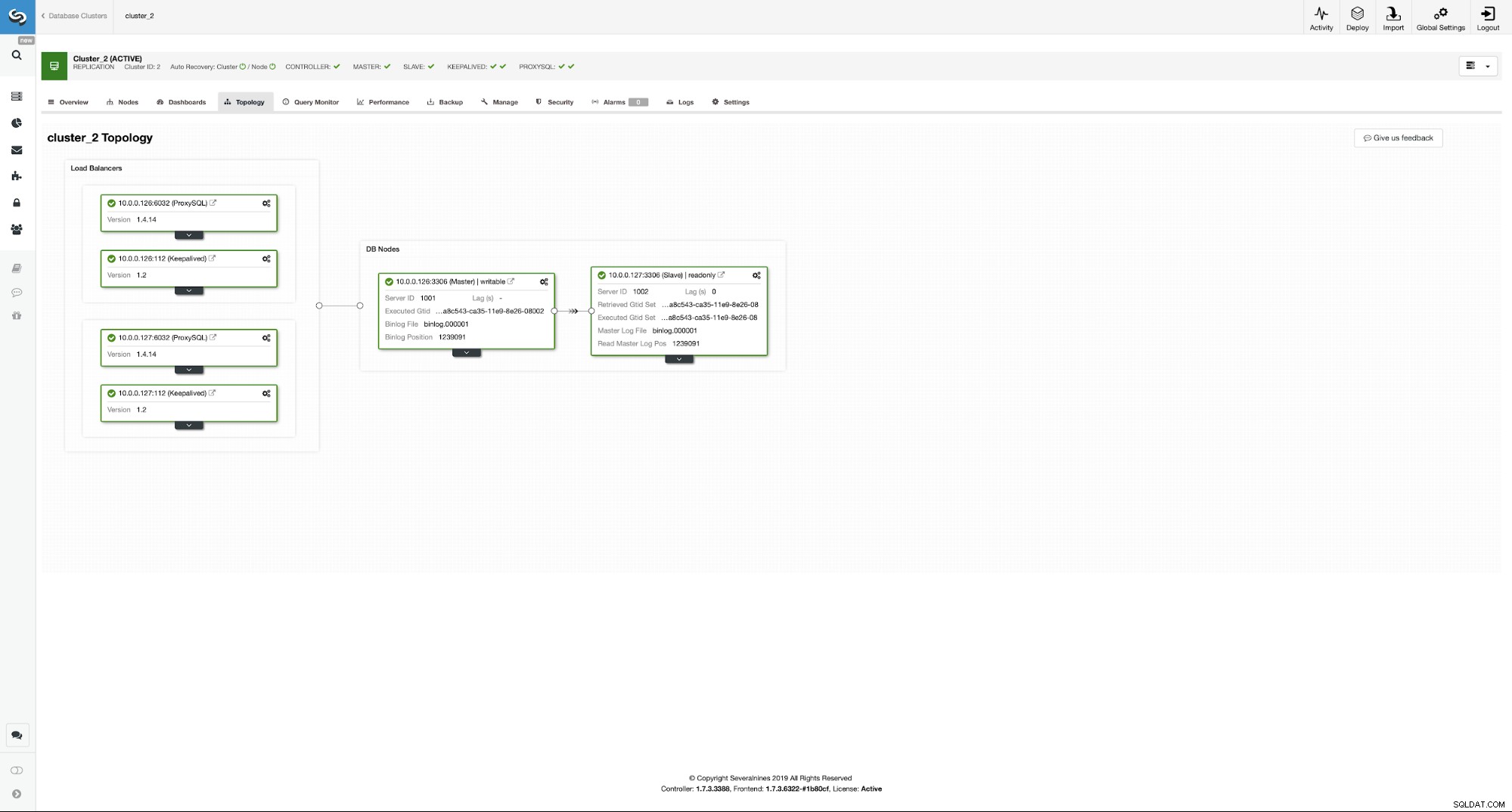
Como você pode ver, agora temos toda a configuração pronta. Temos um VIP de 10.0.0.111 que é atribuído a uma das instâncias do ProxySQL. As instâncias ProxySQL redirecionarão nosso tráfego para os nós MySQL de back-end corretos e o ClusterControl ficará de olho no ambiente realizando failover, se necessário. A última ação que temos que tomar é reconfigurar o Wordpress para usar o IP virtual para se conectar ao banco de dados.
Para fazer isso, temos que editar wp-config.php e alterar a variável DB_HOST para nosso IP virtual:
/** MySQL hostname */
define( 'DB_HOST', '10.0.0.111' );Conclusão
A partir de agora o Wordpress se conectará ao banco de dados usando VIP e ProxySQL. Caso o nó mestre falhe, o ClusterControl realizará o failover.
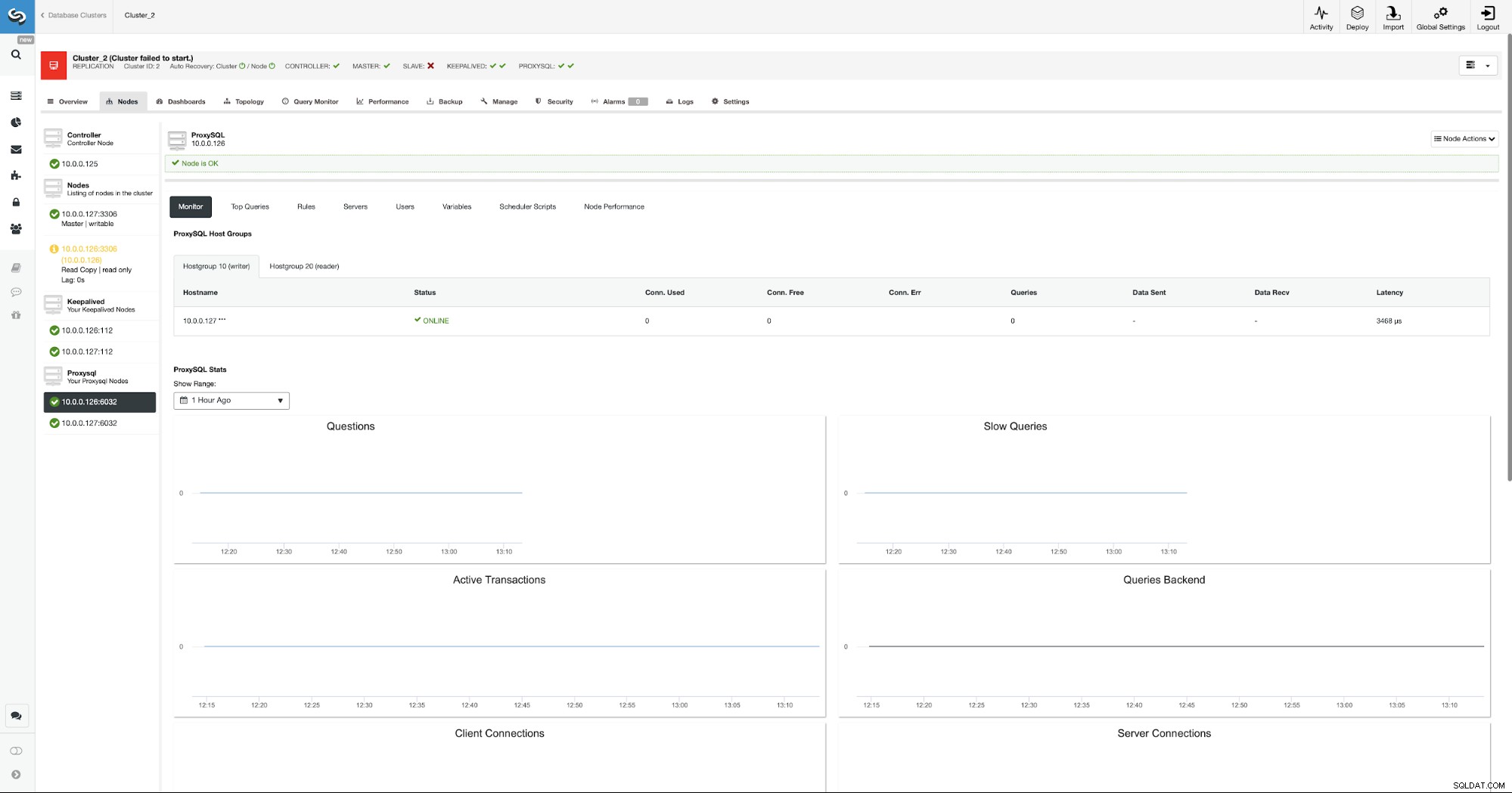
Como você pode ver, um novo mestre foi eleito e o ProxySQL também aponta para novo mestre no hostgroup 10.
Esperamos que esta postagem de blog dê a você uma ideia sobre como projetar um ambiente de banco de dados altamente disponível para um site Wordpress e como o ClusterControl pode ser usado para implantar todos os seus elementos.