Tendo dificuldades com SQL UNION? Isso acontece se os resultados combinados colocarem seu SQL Server em uma paralisação. Ou um relatório que estava funcionando antes aparece uma caixa com um ícone de X vermelho. Ocorre um erro de “conflito de tipo de operando” apontando para uma linha com UNION. O “fogo” começa. Soa familiar?
Esteja você usando SQL UNION por um tempo ou apenas começando, uma folha de dicas ou um conjunto conciso de notas não fará mal. É isso que você vai receber hoje neste post. Esta lista oferece 10 dicas úteis para iniciantes e veteranos. Além disso, haverá exemplos e algumas discussões avançadas.

[id do formulário de envio=”11900″]
Mas antes de entrarmos no primeiro ponto, vamos esclarecer os termos.
UNION é um dos operadores de conjunto em SQL que combina 2 ou mais conjuntos de resultados. Pode ser útil quando você precisa combinar nomes, estatísticas mensais e muito mais de diferentes fontes. E se você usa SQL Server, MySQL ou Oracle, a finalidade, o comportamento e a sintaxe serão muito semelhantes. Mas como isso funciona?
1. Use SQL UNION para combinar Único Registros
Usar UNION para combinar conjuntos de resultados remove duplicatas.
Por que isso é importante?
Na maioria das vezes, você não quer resultados com duplicatas. Um relatório com linhas duplicadas desperdiça tinta e papel em cópias impressas. E isso vai irritar seus usuários.
Como usar
Você combina os resultados das instruções SELECT com UNION no meio.
Antes de começarmos com o exemplo, vamos preparar nossos dados de exemplo.
USE AdventureWorks
GO
IF OBJECT_ID ('dbo.Customer1', 'U') IS NOT NULL
DROP TABLE dbo.Customer1;
GO
IF OBJECT_ID ('dbo.Customer2', 'U') IS NOT NULL
DROP TABLE dbo.Customer2;
GO
IF OBJECT_ID ('dbo.Customer3', 'U') IS NOT NULL
DROP TABLE dbo.Customer3;
GO
-- Get 3 customer names with Andersen lastname
SELECT TOP 3
p.LastName
, p.FirstName
, c.AccountNumber
INTO dbo.Customer1
FROM Person.Person AS p
INNER JOIN Sales.Customer c
ON c.PersonID = p.BusinessEntityID
WHERE p.LastName = 'Andersen';
-- Make sure we have a duplicate in another table
SELECT
c.LastName
,c.FirstName
,c.AccountNumber
INTO dbo.Customer2
FROM Customer1 c
-- Seems it's not enough. Let's have a 3rd copy
SELECT
c.LastName
,c.FirstName
,c.AccountNumber
INTO dbo.Customer3
FROM Customer1 c
Usaremos os dados gerados pelo código acima até a terceira dica. Agora que estamos prontos, abaixo está o exemplo:
SELECT
c.LastName
,c.FirstName
,c.AccountNumber
FROM dbo.Customer1 c
UNION
SELECT
c2.LastName
,c2.FirstName
,c2.AccountNumber
FROM dbo.Customer2 c2
UNION
SELECT
c3.LastName
,c3.FirstName
,c3.AccountNumber
FROM dbo.Customer3 c3
Temos 3 cópias dos nomes dos mesmos clientes e esperamos que os registros exclusivos desapareçam. Veja os resultados:
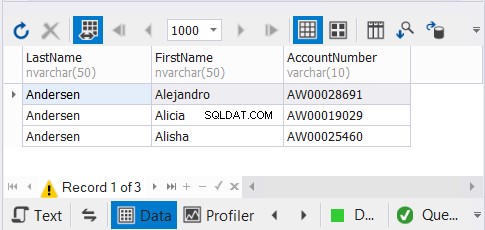
A solução dbForge Studio for SQL Server que usamos para nossos exemplos mostra apenas 3 registros. Poderia ter sido 9. Ao aplicar UNION, removemos as duplicatas.
Como funciona?
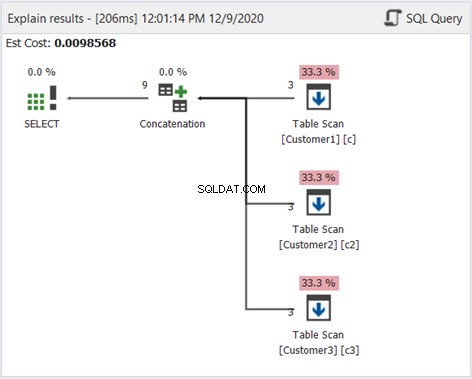
O Diagrama de Plano no dbForge Studio revela como o SQL Server produz o resultado mostrado na Figura 1. Dê uma olhada:
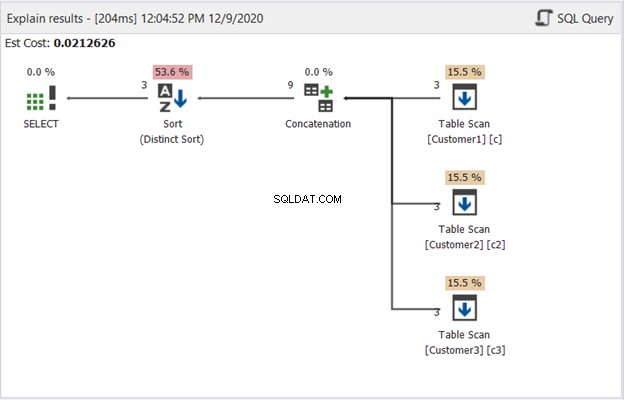
Para interpretar a Figura 2, comece da direita para a esquerda:
- Recuperamos 3 registros de cada operador Table Scan. Essas são as 3 instruções SELECT do exemplo acima. Cada linha que sai dela mostra '3', o que significa 3 registros cada.
- O operador Concatenação faz a combinação dos resultados. A linha que sai dela mostra '9' - uma saída de 9 registros da combinação de resultados.
- O operador Distinct Sort garante que registros exclusivos sejam a saída final. A linha que sai dela mostra '3', que é consistente com o número de registros na Figura 1.
O diagrama acima mostra como UNION é processado pelo SQL Server. O número e o tipo de operadores usados podem ser diferentes dependendo da consulta e da fonte de dados subjacente. Mas, em resumo, uma UNIÃO funciona da seguinte forma:
- Recupere os resultados de cada instrução SELECT.
- Combine os resultados com um operador de concatenação.
- Se os resultados combinados não forem exclusivos, o SQL Server filtrará as duplicatas.
Todos os exemplos de sucesso com UNION seguem estes passos básicos.
2. Use SQL UNION ALL para combinar registros com duplicatas
O uso de UNION ALL combina conjuntos de resultados com duplicatas incluídas.
Por que isso é importante?
Você pode combinar conjuntos de resultados e obter os registros com duplicatas para processamento posterior. Esta tarefa é útil para limpar seus dados.
Como usar
Você combina os resultados das instruções SELECT com UNION ALL no meio. Dê uma olhada no exemplo:
SELECT
c.LastName
,c.FirstName
,c.AccountNumber
FROM dbo.Customer1 c
UNION ALL
SELECT
c2.LastName
,c2.FirstName
,c2.AccountNumber
FROM dbo.Customer2 c2
UNION ALL
SELECT
c3.LastName
,c3.FirstName
,c3.AccountNumber
FROM dbo.Customer3 c3
O código acima gera 9 registros, conforme mostrado na Figura 3:
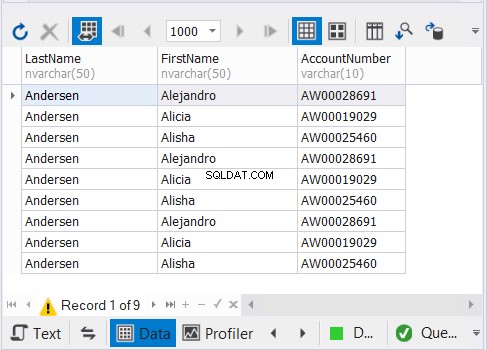
Como funciona?
Como antes, usamos o diagrama de Plano para saber como isso funciona:
Exceto pelo Sort Distinct na Figura 2, o diagrama acima é o mesmo. Isso é apropriado porque não queremos filtrar as duplicatas.
O diagrama acima mostra como UNION ALL funciona. Em resumo, estas são as etapas que o SQL Server seguirá:
- Recupere os resultados de cada instrução SELECT.
- Em seguida, combine os resultados com um operador de concatenação.
Exemplos de sucesso com UNION ALL seguem este padrão.
3. Você pode misturar SQL UNION e UNION ALL, mas agrupá-los com parênteses
Você pode misturar o uso de UNION e UNION ALL em pelo menos três instruções SELECT.
Como usar?
Você combina os resultados das instruções SELECT com UNION ou UNION ALL no meio. Os parênteses agrupam os resultados que vêm juntos. Vamos usar os mesmos dados para o próximo exemplo:
SELECT
c.LastName
,c.FirstName
,c.AccountNumber
FROM dbo.Customer1 c
UNION ALL
(
SELECT
c2.LastName
,c2.FirstName
,c2.AccountNumber
FROM dbo.Customer2 c2
UNION
SELECT
c3.LastName
,c3.FirstName
,c3.AccountNumber
FROM dbo.Customer3 c3
)
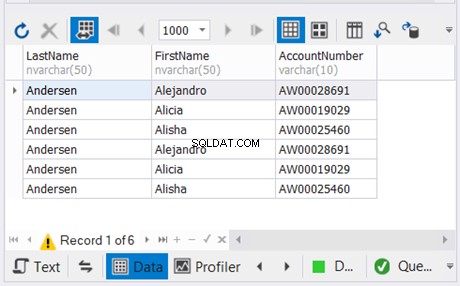
O exemplo acima combina os resultados das duas últimas instruções SELECT sem duplicatas. Em seguida, ele combina isso com o resultado da primeira instrução SELECT. O resultado está na Figura 5 abaixo:
4. As colunas de cada instrução SELECT devem ter tipos de dados compatíveis
As colunas em cada instrução SELECT que usa UNION podem ter diferentes tipos de dados. É aceitável desde que sejam compatíveis e permitam a conversão implícita sobre eles. O tipo de dados final dos resultados combinados usará o tipo de dados com a precedência mais alta. Além disso, a base do tamanho final dos dados são os dados com o maior tamanho. No caso de strings, usará os dados com o maior número de caracteres.
Por que isso é importante?
Se você precisar inserir o resultado de UNIONs em uma tabela, o tipo e o tamanho dos dados finais determinarão se ele se encaixa na coluna da tabela de destino ou não. Caso contrário, ocorrerá um erro. Por exemplo, uma das colunas no UNION tem um tipo final de NVARCHAR(50). Se a coluna da tabela de destino for VARCHAR(50), você não poderá inseri-la na tabela.
Como funciona?
Não há melhor maneira de explicar do que um exemplo:
SELECT N'김지수' AS FullName
UNION
SELECT N'김제니' AS KoreanName
UNION
SELECT N'박채영' AS KoreanName
UNION
SELECT N'ลลิษา มโนบาล' AS ThaiName
UNION
SELECT 'Kim Ji-soo' AS EnglishName
UNION
SELECT 'Jennie Kim' AS EnglishName
UNION
SELECT 'Roseanne Park' AS EnglishName
UNION
SELECT 'Lalisa Manoban' AS EnglishName
O exemplo acima contém dados com nomes de caracteres em inglês, coreano e tailandês. Tailandês e coreano são caracteres Unicode. Os caracteres ingleses não são. Então, qual você acha que será o tipo e o tamanho dos dados finais? O dbForge Studio mostra isso no conjunto de resultados:
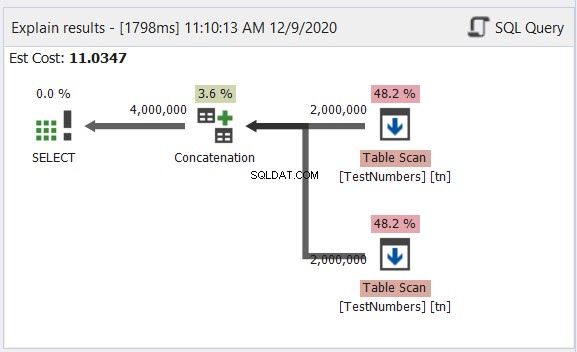
Você notou o tipo de dados final na Figura 6? Não pode ser VARCHAR por causa dos caracteres Unicode. Então, tem que ser NVARCHAR. Enquanto isso, o tamanho não pode ser menor que 14, pois os dados com maior número de caracteres possuem 14 caracteres. Veja as legendas em vermelho na Figura 6. É bom incluir o tipo de dados e tamanho no cabeçalho da coluna no dbForge Studio.
É o caso não apenas para tipos de dados de string. Também se aplica a números e datas. Enquanto isso, se você tentar combinar dados com tipos de dados incompatíveis, ocorrerá um erro. Veja o exemplo abaixo:
SELECT CAST('12/25/2020' AS DATE) AS col1
UNION
SELECT CAST('10' AS INT) AS col1
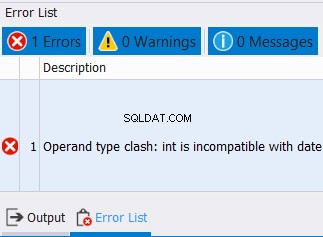
Não podemos combinar datas e números inteiros em uma coluna. Então, espere um erro como o abaixo:
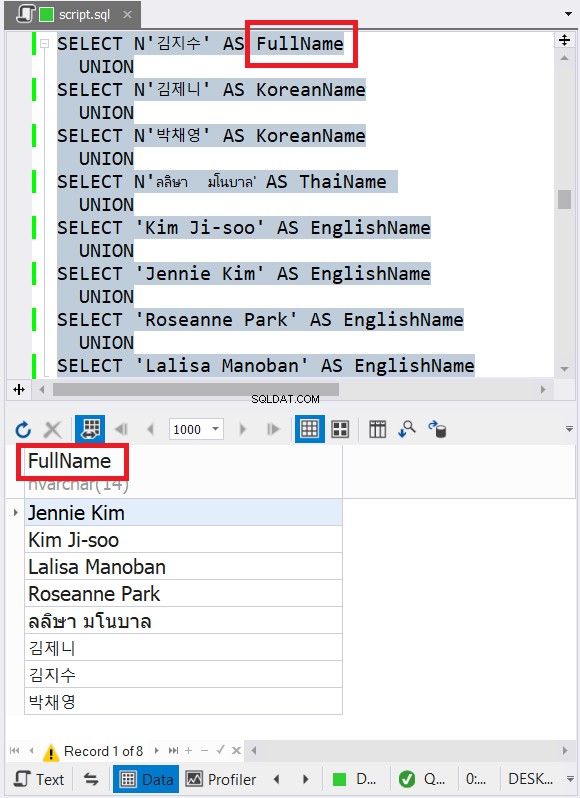
5. Os nomes das colunas dos resultados combinados usarão os nomes das colunas da primeira instrução SELECT
Esse problema está relacionado à dica anterior. Observe os nomes das colunas no código da Dica #4. Existem nomes de colunas diferentes em cada instrução SELECT. No entanto, vimos o nome da coluna final no resultado combinado na Figura 6 anterior. Assim, a base é o nome da coluna da primeira instrução SELECT.
Por que isso é importante?
Isso pode ser útil quando você precisa despejar o resultado do UNION em uma tabela temporária. Se você precisar fazer referência aos nomes das colunas nas instruções seguintes, precisará ter certeza dos nomes. A menos que você esteja usando um editor de código avançado com o IntelliSense, você terá outro erro em seu código T-SQL.
Como funciona?
Veja a Figura 8 para resultados mais claros do uso do dbForge Studio:
6. Adicione ORDER BY na última instrução SELECT com SQL UNION para classificar os resultados
Você precisa classificar os resultados combinados. Em uma série de instruções SELECT com UNION no meio, você pode fazer isso com a cláusula ORDER BY na última instrução SELECT.
Por que isso é importante?
Os usuários desejam classificar os dados da maneira que preferirem em aplicativos, páginas da Web, relatórios, planilhas e muito mais.
Como usar
Use ORDER BY na última instrução SELECT. Aqui está um exemplo:
SELECT
e.BusinessEntityID
,p.FirstName
,p.MiddleName
,p.LastName
,'Employee' AS PersonType
FROM HumanResources.Employee e
INNER JOIN Person.Person p ON e.BusinessEntityID = p.BusinessEntityID
UNION
SELECT
c.PersonID
,p.FirstName
,p.MiddleName
,p.LastName
,'Customer' AS PersonType
FROM Sales.Customer c
INNER JOIN Person.Person p ON c.PersonID = p.BusinessEntityID
ORDER BY p.LastName, p.FirstName
O exemplo acima faz parecer que a classificação só acontece na última instrução SELECT. Mas isso não. Ele funcionará para o resultado combinado. Você terá problemas se o colocar em cada instrução SELECT. Veja o resultado:
Sem ORDER BY, o conjunto de resultados terá todos os funcionários PersonType primeiro seguido por todos os clientes PersonType . No entanto, a Figura 9 demonstra que os nomes se tornam a ordem de classificação do resultado combinado.
Se você tentar colocar ORDER BY em cada instrução SELECT para classificar, eis o que acontecerá:
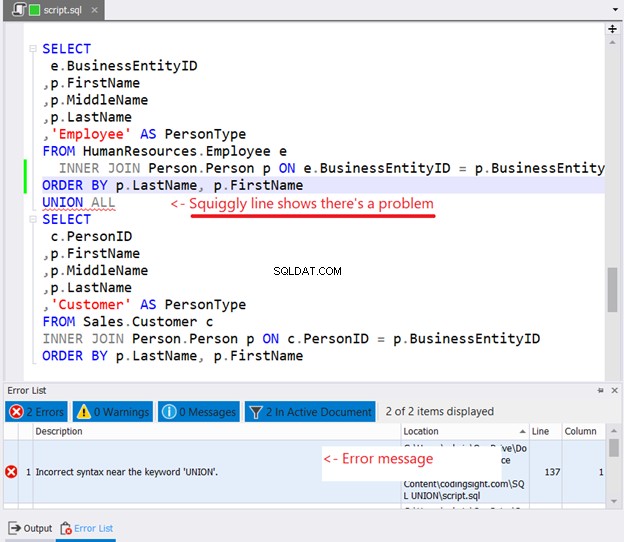
Você viu a linha ondulada na Figura 10? É um aviso. Se você não percebeu e continuou, um erro aparecerá na janela da lista de erros do dbForge Studio.
7. As cláusulas WHERE e GROUP BY podem ser usadas em cada instrução SELECT com SQL UNION
A cláusula ORDER BY não funciona em cada instrução SELECT com UNION no meio. No entanto, as cláusulas WHERE e GROUP BY funcionam.
Por que isso é importante?
Você pode combinar os resultados de diferentes consultas que filtram, contam ou resumem dados. Por exemplo, você pode fazer isso para obter o total de pedidos de vendas de janeiro de 2012 e compará-lo com janeiro de 2013, janeiro de 2014 e assim por diante.
Como usar
Coloque as cláusulas WHERE e/ou GROUP BY em cada instrução SELECT. Confira o exemplo abaixo:
USE AdventureWorks
GO
-- Get the number of orders for January 2012, 2013, 2014 for comparison
SELECT
YEAR(soh.OrderDate) AS OrderYear
,COUNT(*) AS NumberOfJanuaryOrders
FROM Sales.SalesOrderHeader soh
WHERE soh.OrderDate BETWEEN '01/01/2012' AND '01/31/2012'
GROUP BY YEAR(soh.OrderDate)
UNION
SELECT
YEAR(soh.OrderDate) AS OrderYear
,COUNT(*) AS NumberOfJanuaryOrders
FROM Sales.SalesOrderHeader soh
WHERE soh.OrderDate BETWEEN '01/01/2013' AND '01/31/2013'
GROUP BY YEAR(soh.OrderDate)
UNION
SELECT
YEAR(soh.OrderDate) AS OrderYear
,COUNT(*) AS NumberOfJanuaryOrders
FROM Sales.SalesOrderHeader soh
WHERE soh.OrderDate BETWEEN '01/01/2014' AND '01/31/2014'
GROUP BY YEAR(soh.OrderDate)
O código acima combina o número de pedidos de janeiro por três anos consecutivos. Agora, verifique a saída:
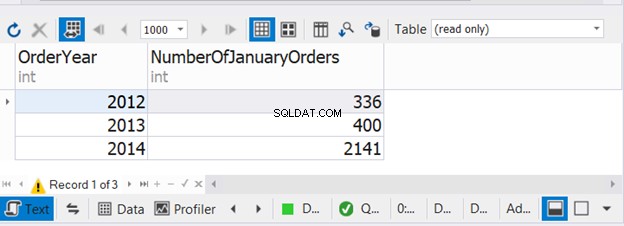
Este exemplo mostra que é possível usar WHERE e GROUP BY em cada uma das três instruções SELECT com UNION.
8. SELECT INTO Funciona com SQL UNION
Quando você precisar inserir os resultados de uma consulta com SQL UNION em uma tabela, poderá fazê-lo usando SELECT INTO.
Por que isso é importante?
Haverá momentos em que você precisará colocar os resultados de uma consulta com UNION em uma tabela para processamento adicional.
Como usar
Coloque a cláusula INTO na primeira instrução SELECT. Aqui está um exemplo:
SELECT
YEAR(soh.OrderDate) AS OrderYear
,COUNT(*) AS NumberOfJanuaryOrders
INTO JanuaryOrders
FROM Sales.SalesOrderHeader soh
WHERE soh.OrderDate BETWEEN '01/01/2012' AND '01/31/2012'
GROUP BY YEAR(soh.OrderDate)
UNION
SELECT
YEAR(soh.OrderDate) AS OrderYear
,COUNT(*) AS NumberOfJanuaryOrders
FROM Sales.SalesOrderHeader soh
WHERE soh.OrderDate BETWEEN '01/01/2013' AND '01/31/2013'
GROUP BY YEAR(soh.OrderDate)
UNION
SELECT
YEAR(soh.OrderDate) AS OrderYear
,COUNT(*) AS NumberOfJanuaryOrders
FROM Sales.SalesOrderHeader soh
WHERE soh.OrderDate BETWEEN '01/01/2014' AND '01/31/2014'
GROUP BY YEAR(soh.OrderDate)
Lembre-se de colocar apenas uma cláusula INTO na primeira instrução SELECT.
Como funciona
O SQL Server segue o padrão de processamento UNION. Em seguida, ele insere o resultado na tabela especificada na cláusula INTO.
9. Diferencie SQL UNION de SQL JOIN
Tanto o SQL UNION quanto o SQL JOIN combinam os dados da tabela, mas a diferença na sintaxe e nos resultados é como a noite e o dia.
Por que isso é importante?
Se o seu relatório ou qualquer requisito precisar de um JOIN, mas você fez um UNION, a saída estará errada.
Como SQL UNION e SQL JOIN são usados
É SQL UNION vs. JOIN. Esta é uma das consultas de pesquisa e perguntas relacionadas que um novato faz no Google ao aprender sobre SQL UNION. Segue a tabela de diferenças:
| SQL UNION | SQL JOIN | |
| O que é combinado | Linhas | Colunas (usando uma chave) |
| Número de colunas por tabela | O mesmo para todas as tabelas | Variável (zero para todas as colunas/tabela) |
Em todos os projetos com os quais estive, o SQL JOIN se aplica na maioria das vezes. Eu só tive alguns casos que usaram SQL UNION. Mas como você viu até agora, o SQL UNION está longe de ser inútil.
10. SQL UNION ALL é mais rápido que UNION
Os diagramas de plano na Figura 2 e na Figura 4 anteriores sugerem que UNION requer um operador extra para garantir resultados exclusivos. É por isso que UNION ALL é mais rápido.
Por que isso é importante?
Você, seus usuários, seus clientes, seu chefe, todos querem resultados rápidos. Saber que UNION ALL é mais rápido do que UNION faz você se perguntar o que fazer se precisar de resultados combinados exclusivos. Há uma solução, como você verá mais tarde.
SQL UNION ALL vs. Desempenho de UNION
A Figura 2 e a Figura 4 já deram uma ideia de qual é mais rápido. Mas os exemplos de código usados são simples com um pequeno conjunto de resultados. Vamos adicionar mais algumas comparações usando milhões de registros para torná-lo atraente.
Para começar, vamos preparar os dados:
SELECT TOP (2000000)
val = ROW_NUMBER() OVER (ORDER BY sod.SalesOrderDetailID)
INTO dbo.TestNumbers
FROM AdventureWorks.Sales.SalesOrderDetail sod
CROSS JOIN AdventureWorks.Sales.SalesOrderDetail sod2
São 2 milhões de registros. Espero que seja convincente o suficiente. Agora, vamos ter os próximos dois exemplos de consulta abaixo.
-- Using UNION ALL
SELECT
val
FROM TestNumbers tn
UNION ALL
SELECT
val
FROM TestNumbers tn
-- Using UNION
SELECT
val
FROM TestNumbers tn
UNION
SELECT
val
FROM TestNumbers tn
Vamos examinar os processos envolvidos nessas consultas começando pela mais rápida.
Análise do Diagrama do Plano
O diagrama na Figura 12 parece típico de um processo UNION ALL. No entanto, o resultado são 4 milhões de resultados combinados. Veja a seta saindo do operador Concatenação. Ainda assim, normalmente é porque não lida com as duplicatas.
Agora, vamos ter o diagrama da consulta UNION na Figura 13:
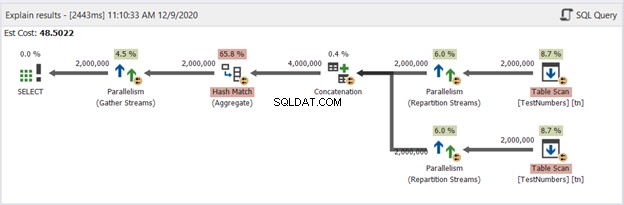
Este já não é típico. O plano se torna um plano de consulta paralela para lidar com a remoção de duplicatas em quatro milhões de linhas. O plano de consulta paralela significa que o SQL Server precisa dividir o processo pelo número de núcleos de processador disponíveis para ele.
Vamos interpretá-lo, começando pelos operadores da direita indo para a esquerda:
- Como estamos combinando uma tabela com ela mesma, o SQL Server precisa recuperá-la duas vezes. Veja as duas verificações de tabela com dois milhões de registros cada.
- Os operadores do Repartition Stream controlarão a distribuição de cada linha para o próximo encadeamento disponível.
- A concatenação dobra o resultado para quatro milhões. Isso ainda está considerando o número de núcleos do processador.
- Uma correspondência de hash se aplica para remover as duplicatas. Este é um processo caro com um custo de operador de 65,8%. Como resultado, dois milhões de registros foram descartados.
- Gather Streams recombinam os resultados obtidos em cada núcleo ou thread do processador em um.
Isso é muito trabalho, mesmo que o processo seja dividido em vários segmentos. Portanto, você concluirá que ele será executado mais lentamente. Mas e se houver uma solução para obter registros exclusivos com UNION ALL, mas mais rápido que isso?
Resultados únicos, mas soluções mais rápidas com UNION ALL – Como?
Eu não vou fazer você esperar. Aqui está o código:
SELECT DISTINCT
val
FROM
(
SELECT
val
FROM TestNumbers tn
UNION ALL
SELECT
val
FROM TestNumbers tn
) AS uniqtn
Esta pode ser uma solução esfarrapada. Mas confira seu Diagrama de Plano na Figura 14:
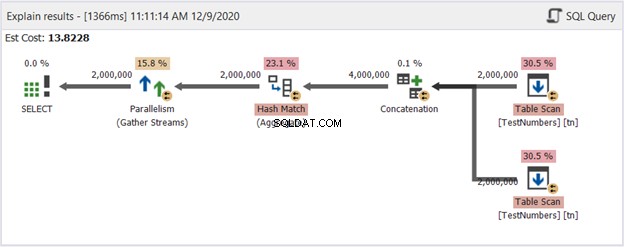
Então, o que melhorou? Se você comparar com a Figura 13, verá que os operadores do Repartição Stream desapareceram. No entanto, ele ainda utiliza vários threads para fazer o trabalho. Por outro lado, isso implica que o otimizador de consultas considere esse processo mais simples de fazer do que a consulta usando UNION.
Podemos concluir com segurança que devemos evitar o uso de UNION e usar essa abordagem? De jeito nenhum! Sempre verifique o diagrama do plano de execução! Sempre depende do que você deseja que o SQL Server forneça. Este mostra apenas que, se você esbarrar em uma parede de desempenho, precisará alterar sua abordagem de consulta.
E as estatísticas de E/S?
Não podemos descartar quantos recursos o SQL Server precisa para processar nossos exemplos de consulta. É por isso que também precisamos examinar suas ESTATÍSTICAS IO. Comparando as três consultas acima, obtemos as leituras lógicas abaixo:
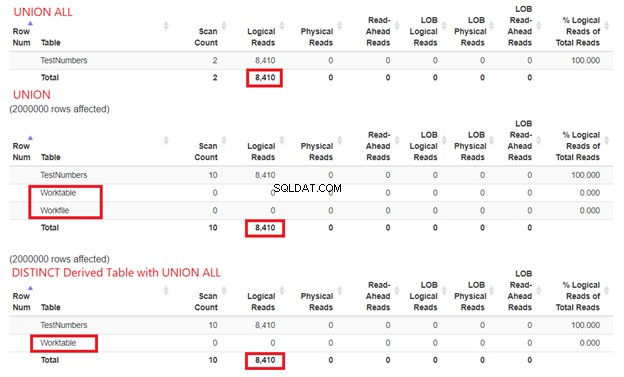
Da Figura 15, ainda podemos concluir que UNION ALL é mais rápido que UNION, embora as leituras lógicas sejam as mesmas. A presença de Worktable e Arquivo de trabalho mostra usando tempdb para fazer o trabalho. Enquanto isso, quando usamos SELECT DISTINCT de uma tabela derivada com UNION ALL, o tempdb o uso é menor em comparação com UNION. Isso reconfirma ainda mais que nossa análise dos Diagramas de Plano anteriores está correta.
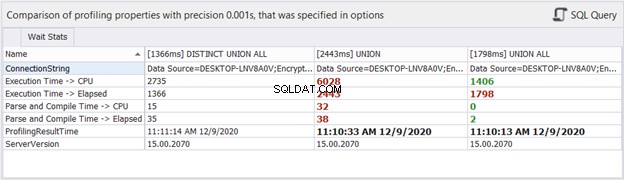
E as estatísticas de tempo?
Embora o tempo decorrido possa mudar em cada execução que fazemos para as mesmas consultas, ele pode nos dar uma ideia e adicionar mais evidências à nossa análise. O dbForge Studio exibe as diferenças de tempo das três consultas acima. Essa comparação é consistente com a análise anterior que fizemos.
Conclusão
Cobrimos muitos antecedentes para fornecer o que você precisa para usar SQL UNION e UNION ALL. Você pode não se lembrar de tudo depois de ler este post, então certifique-se de marcar esta página.
Se você gostou do post, sinta-se à vontade para compartilhá-lo nas redes sociais.