Monitorar as alterações do esquema do banco de dados no MySQL/MariaDB fornece uma grande ajuda, pois economiza tempo analisando o crescimento do banco de dados, alterações na definição da tabela, tamanho dos dados, tamanho do índice ou tamanho da linha. Para MySQL/MariaDB, executar uma consulta referenciando information_schema junto com performance_schema fornece resultados coletivos para análise posterior. O esquema sys fornece exibições que servem como métricas coletivas que são muito úteis para rastrear alterações ou atividades do banco de dados.
Se você tiver muitos servidores de banco de dados, seria tedioso executar uma consulta o tempo todo. Você também tem que digerir esse resultado em um mais legível e mais fácil de entender.
Neste blog, criaremos uma automação que seria útil como sua ferramenta de utilidade para monitorar seu banco de dados existente e coletar métricas relacionadas a alterações de banco de dados ou operações de alteração de esquema.
Criando automação para verificação de objeto de esquema de banco de dados
Neste exercício, vamos monitorar as seguintes métricas:
-
Nenhuma tabela de chave primária
-
Índices duplicados
-
Gere um gráfico para o número total de linhas em nossos esquemas de banco de dados
-
Gere um gráfico para o tamanho total de nossos esquemas de banco de dados
Este exercício lhe dará um alerta e pode ser modificado para reunir métricas mais avançadas de seu banco de dados MySQL/MariaDB.
Usando o Puppet para nosso IaC e automação
Este exercício deve usar o Puppet para fornecer automação e gerar os resultados esperados com base nas métricas que queremos monitorar. Não abordaremos a instalação e configuração do Puppet, incluindo servidor e cliente, portanto, espero que você saiba como usar o Puppet. Você pode visitar nosso antigo blog Automated Deployment of MySQL Galera Cluster to Amazon AWS with Puppet, que aborda a configuração e instalação do Puppet.
Usaremos a versão mais recente do Puppet neste exercício, mas como nosso código consiste em sintaxe básica, ele seria executado em versões mais antigas do Puppet.
Servidor de banco de dados MySQL preferido
Neste exercício, usaremos o Percona Server 8.0.22-13, pois prefiro o Percona Server principalmente para testes e algumas implantações menores, seja para uso comercial ou pessoal.
Ferramenta de gráficos
Existem várias opções para usar, especialmente usando o ambiente Linux. Neste blog, usarei o mais fácil que encontrei e uma ferramenta opensource https://quickchart.io/.
Vamos brincar com fantoches
A suposição que fiz aqui é que você configurou o servidor mestre com o cliente registrado que está pronto para se comunicar com o servidor mestre para receber implantações automáticas.
Antes de prosseguirmos, aqui estão as informações do meu servidor:
Servidor mestre:192.168.40.200
Servidor cliente/agente:192.168.40.160
Neste blog, nosso servidor cliente/agente é onde nosso servidor de banco de dados está sendo executado. Em um cenário do mundo real, não precisa ser especialmente para monitoramento. Contanto que seja capaz de se comunicar com o nó de destino com segurança, essa também é uma configuração perfeita.
Configure o módulo e o código
-
Vá para o servidor mestre e no caminho /etc/puppetlabs/code/environments/production/module, vamos criar os diretórios necessários para este exercício:
mkdir schema_change_mon/{files,manifests}-
Crie os arquivos que precisamos
touch schema_change_mon/files/graphing_gen.sh
touch schema_change_mon/manifests/init.pp
-
Preencha o script init.pp com o seguinte conteúdo:
class schema_change_mon (
$db_provider = "mysql",
$db_user = "root",
$db_pwd = "example@sqldat.com",
$db_schema = []
) {
$dbs = ['pauldb', 'sbtest']
service { $db_provider :
ensure => running,
enable => true,
hasrestart => true,
hasstatus => true
}
exec { "mysql-without-primary-key" :
require => Service['mysql'],
command => "/usr/bin/sudo MYSQL_PWD=\"${db_pwd}\" /usr/bin/mysql -u${db_user} -Nse \"select concat(tables.table_schema,'.',tables.table_name,', ', tables.engine) from information_schema.tables left join ( select table_schema , table_name from information_schema.statistics group by table_schema , table_name , index_name having sum( case when non_unique = 0 and nullable != 'YES' then 1 else 0 end ) = count(*) ) puks on tables.table_schema = puks.table_schema and tables.table_name = puks.table_name where puks.table_name is null and tables.table_type = 'BASE TABLE' and tables.table_schema not in ('performance_schema', 'information_schema', 'mysql');\" >> /opt/schema_change_mon/assets/no-pk.log"
}
$dbs.each |String $db| {
exec { "mysql-duplicate-index-$db" :
require => Service['mysql'],
command => "/usr/bin/sudo MYSQL_PWD=\"${db_pwd}\" /usr/bin/mysql -u${db_user} -Nse \"SELECT concat(t.table_schema,'.', t.table_name, '.', t.index_name, '(', t.idx_cols,')') FROM ( SELECT table_schema, table_name, index_name, Group_concat(column_name) idx_cols FROM ( SELECT table_schema, table_name, index_name, column_name FROM statistics WHERE table_schema='${db}' ORDER BY index_name, seq_in_index) t GROUP BY table_name, index_name) t JOIN ( SELECT table_schema, table_name, index_name, Group_concat(column_name) idx_cols FROM ( SELECT table_schema, table_name, index_name, column_name FROM statistics WHERE table_schema='pauldb' ORDER BY index_name, seq_in_index) t GROUP BY table_name, index_name) u where t.table_schema = u.table_schema AND t.table_name = u.table_name AND t.index_name<>u.index_name AND locate(t.idx_cols,u.idx_cols);\" information_schema >> /opt/schema_change_mon/assets/dupe-indexes.log"
}
}
$genscript = "/tmp/graphing_gen.sh"
file { "${genscript}" :
ensure => present,
owner => root,
group => root,
mode => '0655',
source => 'puppet:///modules/schema_change_mon/graphing_gen.sh'
}
exec { "generate-graph-total-rows" :
require => [Service['mysql'],File["${genscript}"]],
path => [ '/bin/', '/sbin/' , '/usr/bin/', '/usr/sbin/' ],
provider => "shell",
logoutput => true,
command => "/tmp/graphing_gen.sh total_rows"
}
exec { "generate-graph-total-len" :
require => [Service['mysql'],File["${genscript}"]],
path => [ '/bin/', '/sbin/' , '/usr/bin/', '/usr/sbin/' ],
provider => "shell",
logoutput => true,
command => "/tmp/graphing_gen.sh total_len"
}
}-
Preencha o arquivo graphing_gen.sh. Este script será executado no nó de destino e gerará gráficos para o número total de linhas em nosso banco de dados e também o tamanho total de nosso banco de dados. Para este script, vamos simplificar e permitir apenas o tipo de banco de dados MyISAM ou InnoDB.
#!/bin/bash
graph_ident="${1:-total_rows}"
unset json myisam innodb nmyisam ninnodb; json='' myisam='' innodb='' nmyisam='' ninnodb='' url=''; json=$(MYSQL_PWD="example@sqldat.com" mysql -uroot -Nse "select json_object('dbschema', concat(table_schema,' - ', engine), 'total_rows', sum(table_rows), 'total_len', sum(data_length+data_length), 'fragment', sum(data_free)) from information_schema.tables where table_schema not in ('performance_schema', 'sys', 'mysql', 'information_schema') and engine in ('myisam','innodb') group by table_schema, engine;" | jq . | sed ':a;N;$!ba;s/\n//g' | sed 's|}{|},{|g' | sed 's/^/[/g'| sed 's/$/]/g' | jq '.' ); innodb=""; myisam=""; for r in $(echo $json | jq 'keys | .[]'); do if [[ $(echo $json| jq .[$r].'dbschema') == *"MyISAM"* ]]; then nmyisam=$(echo $nmyisam || echo '')$(echo $json| jq .[$r]."${graph_ident}")','; myisam=$(echo $myisam || echo '')$(echo $json| jq .[$r].'dbschema')','; else ninnodb=$(echo $ninnodb || echo '')$(echo $json| jq .[$r]."${graph_ident}")','; innodb=$(echo $innodb || echo '')$(echo $json| jq .[$r].'dbschema')','; fi; done; myisam=$(echo $myisam|sed 's/,$//g'); nmyisam=$(echo $nmyisam|sed 's/,$//g'); innodb=$(echo $innodb|sed 's/,$//g');ninnodb=$(echo $ninnodb|sed 's/,$//g'); echo $myisam "|" $nmyisam; echo $innodb "|" $ninnodb; url=$(echo "{type:'bar',data:{labels:['MyISAM','InnoDB'],datasets:[{label:[$myisam],data:[$nmyisam]},{label:[$innodb],data:[$ninnodb]}]},options:{title:{display:true,text:'Database Schema Total Rows Graph',fontSize:20,}}}"); curl -L -o /vagrant/schema_change_mon/assets/db-${graph_ident}.png -g https://quickchart.io/chart?c=$(python -c "import urllib,os,sys; print urllib.quote(os.environ['url'])")
-
Por último, vá para o diretório do caminho do módulo ou /etc/puppetlabs/code/environments /produção na minha configuração. Vamos criar o arquivo manifests/schema_change_mon.pp.
touch manifests/schema_change_mon.pp-
Em seguida, preencha o arquivo manifests/schema_change_mon.pp com o seguinte conteúdo,
node 'pupnode16.puppet.local' { # Applies only to mentioned node. If nothing mentioned, applies to all.
class { 'schema_change_mon':
}
}Se você terminar, você deve ter a seguinte estrutura de árvore como a minha,
example@sqldat.com:/etc/puppetlabs/code/environments/production/modules# tree schema_change_mon
schema_change_mon
├── files
│ └── graphing_gen.sh
└── manifests
└── init.ppO que nosso módulo faz?
Nosso módulo chamado schema_change_mon coleta o seguinte,
exec { "mysql-without-primary-key" :...
Que executa um comando mysql e executa uma consulta para recuperar tabelas sem chaves primárias. Então,
$dbs.each |String $db| {
exec { "mysql-duplicate-index-$db" :que coleta índices duplicados que existem nas tabelas do banco de dados.
A seguir, as linhas geram gráficos com base nas métricas coletadas. Estas são as seguintes linhas,
exec { "generate-graph-total-rows" :
...
exec { "generate-graph-total-len" :
…Uma vez que a consulta é executada com sucesso, ela gera o gráfico, que depende da API fornecida por https://quickchart.io/.
Aqui estão os seguintes resultados do gráfico:
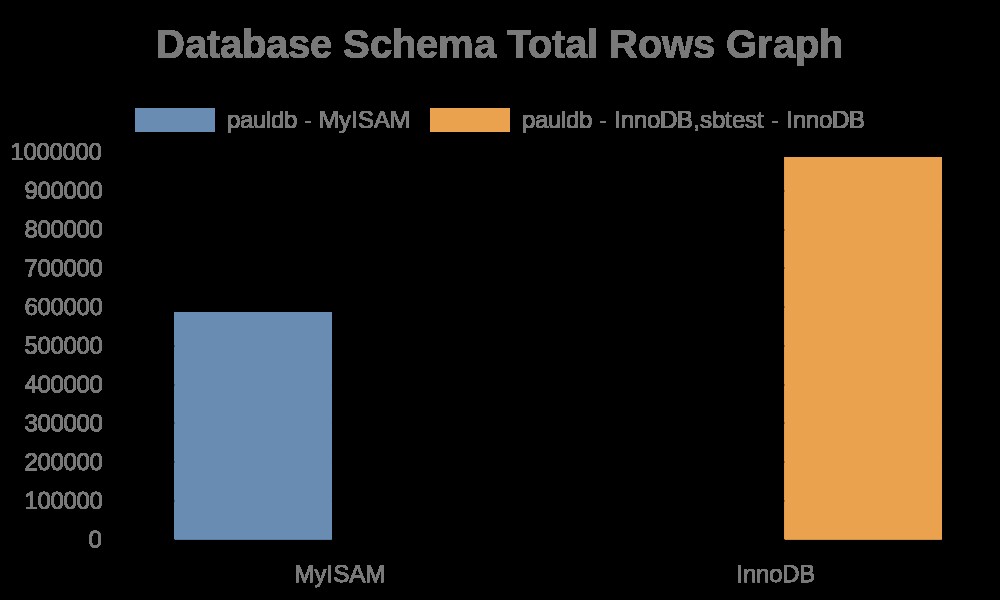
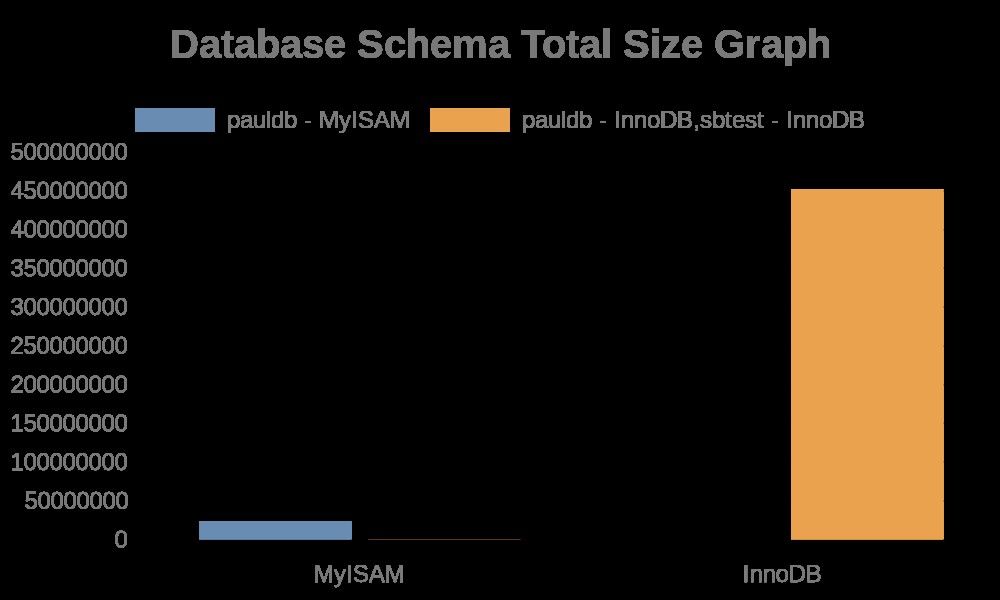
Enquanto os logs de arquivo simplesmente contêm strings com seus nomes de tabela, nomes de índice. Veja o resultado abaixo,
example@sqldat.com:~# tail -n+1 /opt/schema_change_mon/assets/*.log
==> /opt/schema_change_mon/assets/dupe-indexes.log <==
pauldb.c.my_index(n,i)
pauldb.c.my_index2(n,i)
pauldb.d.a_b(a,b)
pauldb.d.a_b2(a,b)
pauldb.d.a_b3(a)
pauldb.d.a_b3(a)
pauldb.t3.b(b)
pauldb.c.my_index(n,i)
pauldb.c.my_index2(n,i)
pauldb.d.a_b(a,b)
pauldb.d.a_b2(a,b)
pauldb.d.a_b3(a)
pauldb.d.a_b3(a)
pauldb.t3.b(b)
==> /opt/schema_change_mon/assets/no-pk.log <==
pauldb.b, MyISAM
pauldb.c, InnoDB
pauldb.t2, InnoDB
pauldb.d, InnoDB
pauldb.b, MyISAM
pauldb.c, InnoDB
pauldb.t2, InnoDB
pauldb.d, InnoDBPor que não usar o ClusterControl?
Como nosso exercício mostra a automação e a obtenção das estatísticas do esquema do banco de dados, como alterações ou operações, o ClusterControl também fornece isso. Além disso, existem outros recursos e você não precisa reinventar a roda. O ClusterControl pode fornecer os logs de transações, como deadlocks, conforme mostrado acima, ou consultas de longa duração, conforme mostrado abaixo:
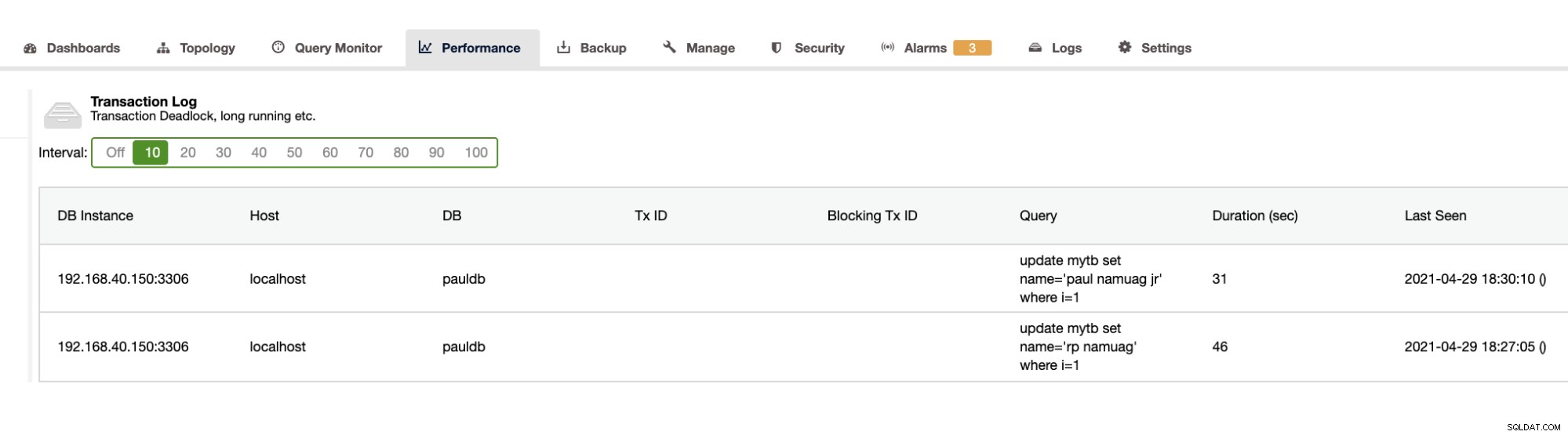
ClusterControl também mostra o crescimento do banco de dados conforme mostrado abaixo,
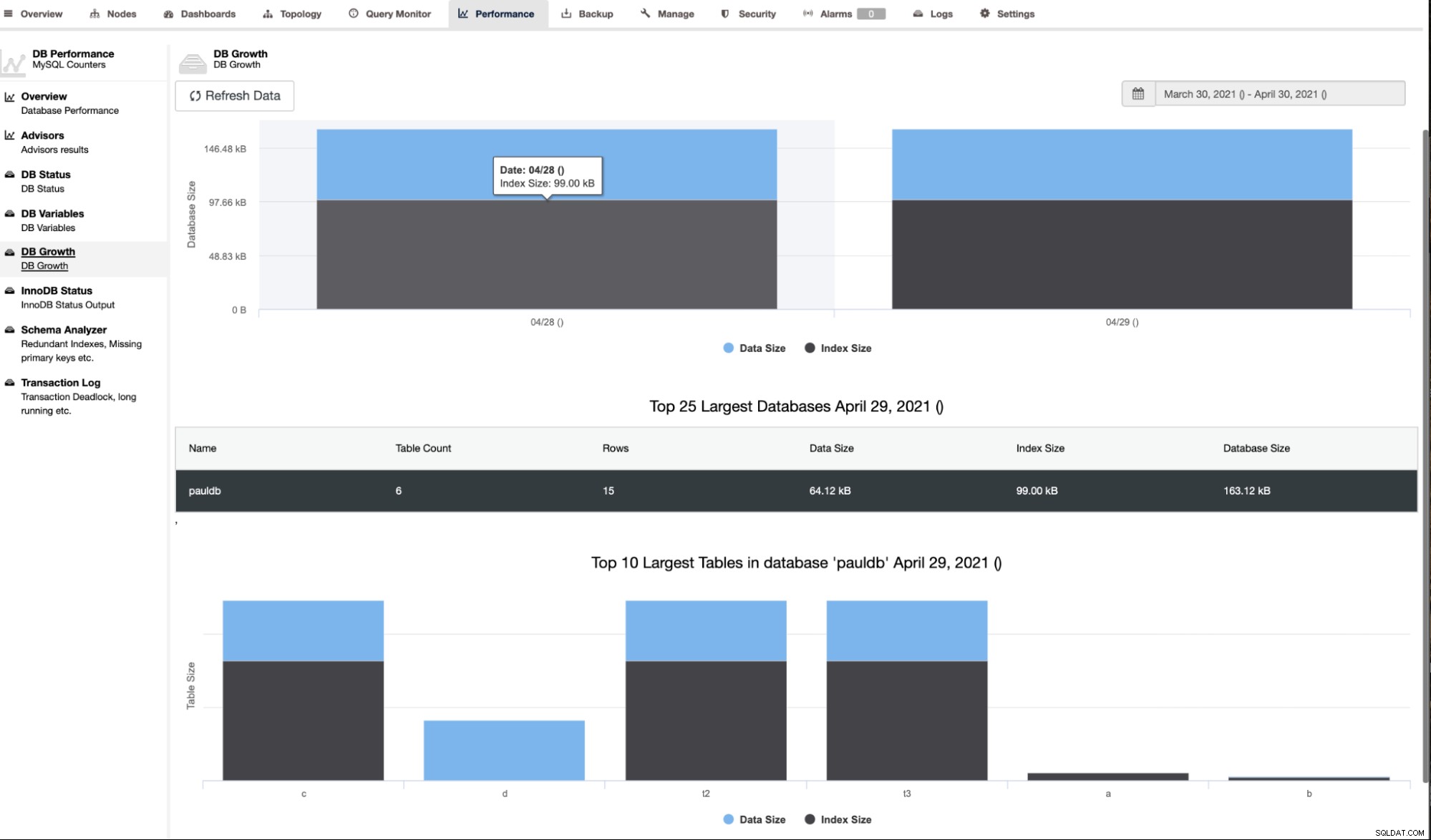
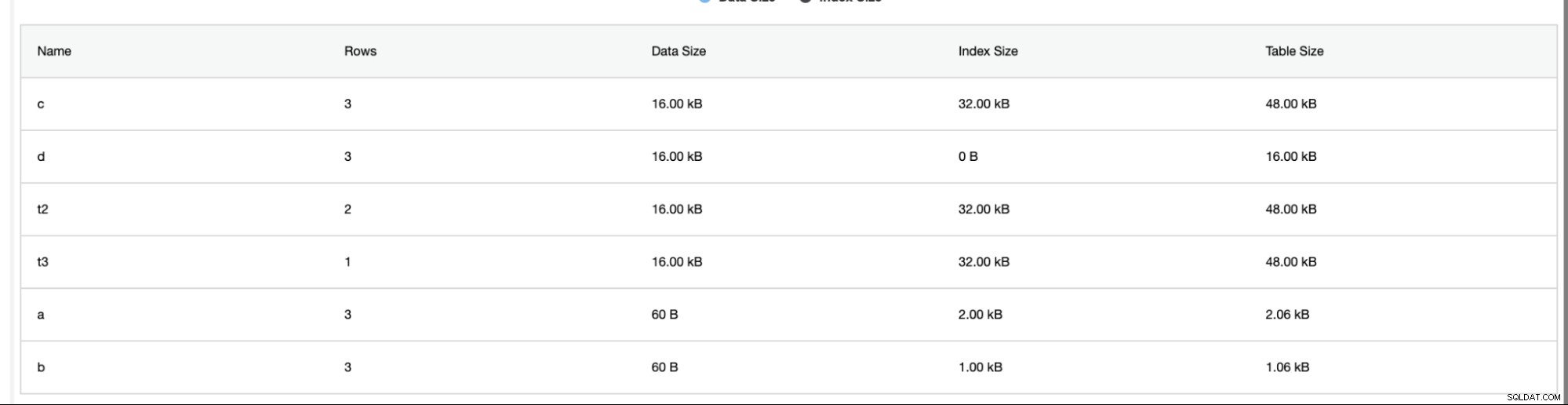
ClusterControl também fornece informações adicionais, como número de linhas, tamanho do disco, tamanho do índice e tamanho total.
O analisador de esquema na guia Desempenho -> Analisador de esquema é muito útil. Fornece tabelas sem chaves primárias, tabelas MyISAM e índices duplicados,

Também fornece alarmes caso sejam detectados índices duplicados ou tabelas sem primário teclas como abaixo,

Você pode conferir mais informações sobre o ClusterControl e seus outros recursos na página do nosso Produto.
Conclusão
Fornecer automação para monitorar suas alterações de banco de dados ou quaisquer estatísticas de esquema, como gravações, índices duplicados, atualizações de operação, como alterações de DDL e muitas atividades de banco de dados, é muito benéfico para os DBAs. Ele ajuda a identificar rapidamente os links fracos e as consultas problemáticas que forneceriam uma visão geral de uma possível causa de consultas inválidas que bloqueariam seu banco de dados ou deixariam seu banco de dados obsoleto.