Assim que você começar a executar um servidor de banco de dados e seu uso aumentar, você estará exposto a muitos tipos de problemas técnicos, degradação de desempenho e mau funcionamento do banco de dados. Cada um deles pode levar a problemas muito maiores, como falha catastrófica ou perda de dados. É como uma reação em cadeia, onde uma coisa pode levar a outra, causando mais e mais problemas. Contramedidas proativas devem ser executadas para que você tenha um ambiente estável o maior tempo possível.
Nesta postagem do blog, veremos vários recursos interessantes oferecidos pelo ClusterControl que podem nos ajudar muito a solucionar problemas e corrigir nossos problemas de banco de dados MySQL quando eles ocorrerem.
Alarmes e notificações do banco de dados
Para todos os eventos indesejados, o ClusterControl registrará tudo em Alarmes, acessível na Atividade (Menu Superior) da página ClusterControl. Geralmente, esse é o primeiro passo para iniciar a solução de problemas quando algo dá errado. Nesta página, podemos ter uma ideia do que realmente está acontecendo com nosso cluster de banco de dados:
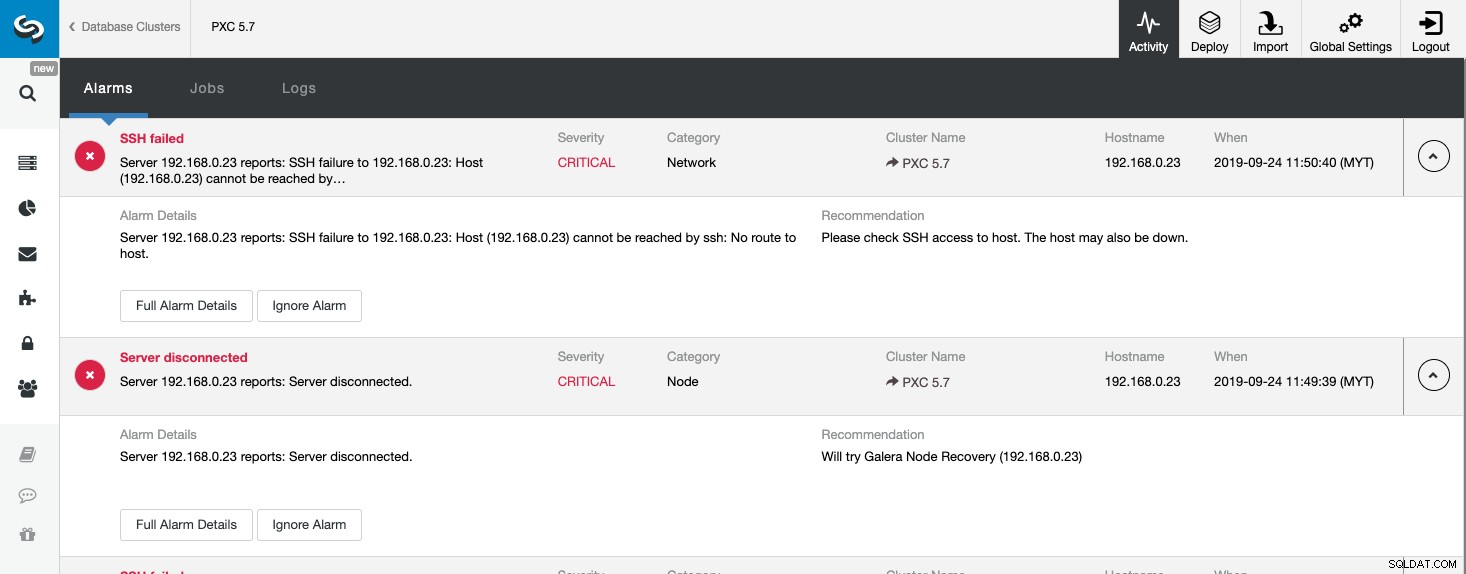
A captura de tela acima mostra um exemplo de um evento inacessível do servidor, com gravidade CRITICAL , detectado por dois componentes, Network e Node. Se você configurou a configuração de notificações por e-mail, deverá obter uma cópia desses alarmes em sua caixa de correio.
Ao clicar em “Detalhes completos do alarme”, você pode obter os detalhes importantes do alarme, como nome do host, carimbo de data/hora, nome do cluster e assim por diante. Ele também fornece a próxima etapa recomendada a ser tomada. Você também pode enviar este alarme como um e-mail para outros destinatários configurados nas Configurações de notificação por e-mail.
Você também pode optar por silenciar um alarme clicando no botão “Ignorar alarme” e ele não aparecerá na lista novamente. Ignorar um alarme pode ser útil se você tiver um alarme de baixa gravidade e souber como lidar com ele ou contorná-lo. Por exemplo, se o ClusterControl detectar um índice duplicado em seu banco de dados, onde em alguns casos seria necessário para seus aplicativos legados.
Ao olhar para esta página, podemos obter uma compreensão imediata do que está acontecendo com nosso cluster de banco de dados e qual o próximo passo a ser feito para resolver o problema. Como neste caso, um dos nós do banco de dados ficou inativo e tornou-se inacessível via SSH do host ClusterControl. Mesmo um SysAdmin iniciante saberia agora o que fazer se este alarme aparecer.
Arquivos de log do banco de dados centralizado
É aqui que podemos detalhar o que havia de errado com nosso servidor de banco de dados. Em ClusterControl -> Logs -> System Logs, você pode ver todos os arquivos de log relacionados ao cluster de banco de dados. Quanto ao cluster de banco de dados baseado em MySQL, o ClusterControl extrai o log do ProxySQL, o log de erros do MySQL e os logs de backup:
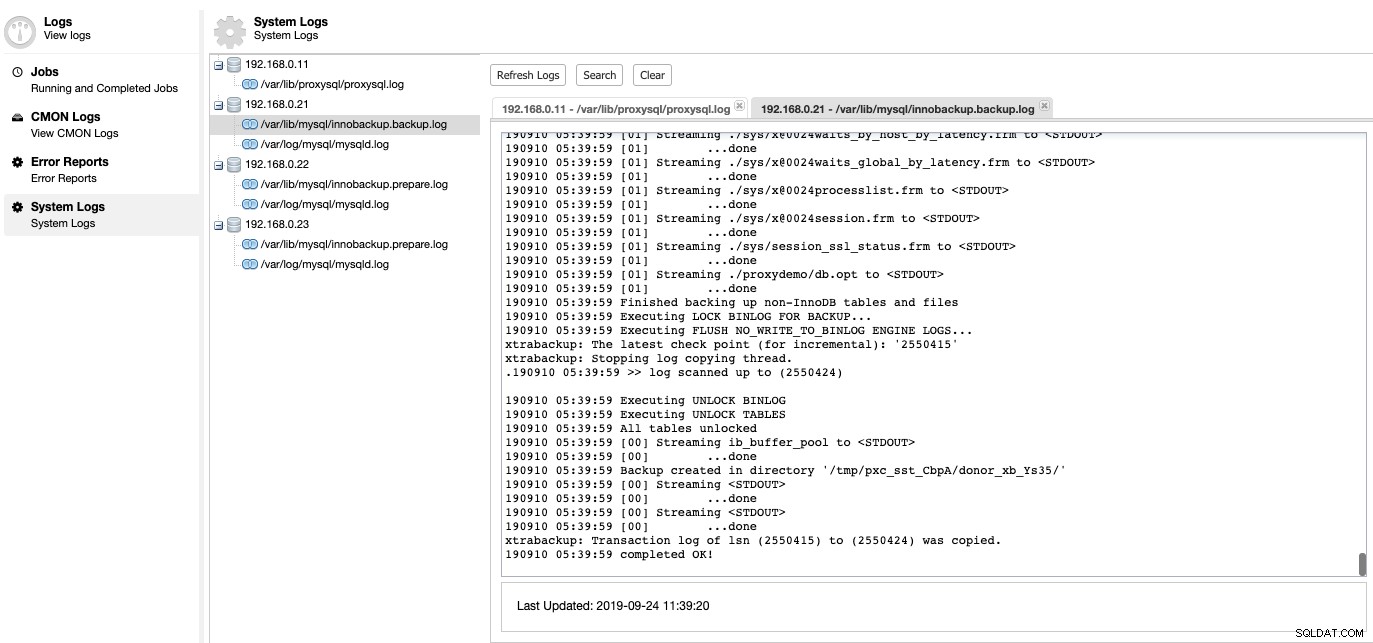
Clique em "Atualizar log" para recuperar o log mais recente de todos os hosts acessíveis naquele momento específico. Se um nó estiver inacessível, o ClusterControl ainda visualizará o login desatualizado, pois essas informações são armazenadas no banco de dados CMON. Por padrão, o ClusterControl continua recuperando os logs do sistema a cada 10 minutos, configurável em Configurações -> Intervalo de log.
O ClusterControl acionará o trabalho para extrair o log mais recente de cada servidor, conforme mostrado no seguinte trabalho "Coletar logs":
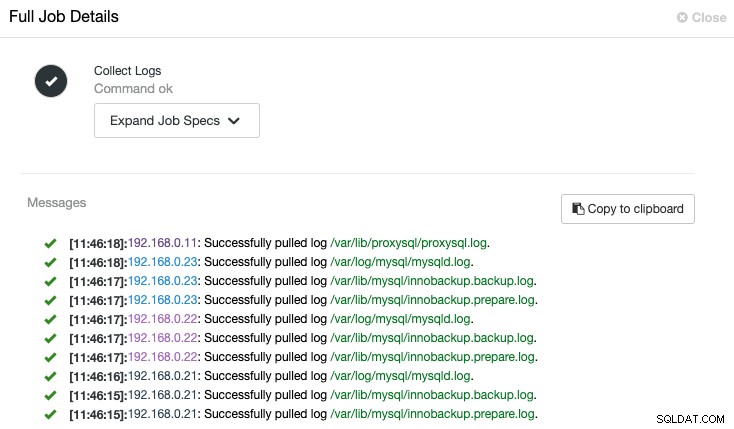
Uma visão centralizada do arquivo de log nos permite ter uma compreensão mais rápida sobre o que aconteceu errado. Para um cluster de banco de dados que geralmente envolve vários nós e camadas, esse recurso melhorará muito a leitura do log, onde um SysAdmin pode comparar esses logs lado a lado e identificar eventos críticos, reduzindo o tempo total de solução de problemas.
Console SSH da Web
O ClusterControl fornece um console SSH baseado na Web para que você possa acessar o servidor de banco de dados diretamente por meio da interface do usuário do ClusterControl (já que o usuário SSH está configurado para se conectar aos hosts do banco de dados). A partir daqui, podemos reunir muito mais informações que nos permitem corrigir o problema ainda mais rápido. Todo mundo sabe quando um problema de banco de dados atinge o sistema de produção, cada segundo de tempo de inatividade conta.
Para acessar o console SSH via web, basta escolher os nós em Nodes -> Node Actions -> SSH Console, ou simplesmente clicar no ícone de engrenagem para um atalho:
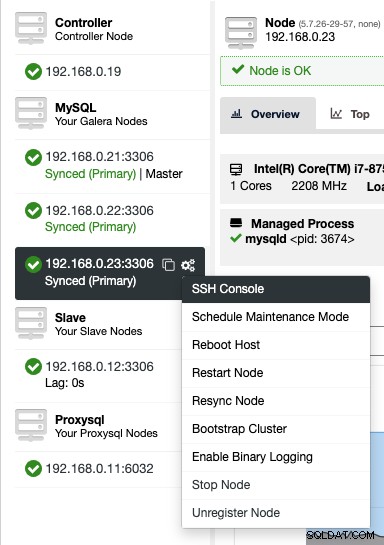
Devido a questões de segurança que podem ser impostas com este recurso, especialmente para -user ou ambiente multi-tenant, pode-se desativá-lo indo para /var/www/html/clustercontrol/bootstrap.php no servidor ClusterControl e definir a seguinte constante como false:
define('SSH_ENABLED', false);Atualize a página ClusterControl UI para carregar as novas alterações.
Problemas de desempenho do banco de dados
Além dos recursos de monitoramento e tendências, o ClusterControl envia proativamente vários alarmes e consultores relacionados ao desempenho do banco de dados, por exemplo:
- Uso excessivo - Recurso que ultrapassa determinados limites, como CPU, memória, uso de swap e espaço em disco.
- Degradação do cluster - particionamento de cluster e rede.
- Desvio de tempo do sistema - Diferença de tempo entre todos os nós no cluster (incluindo o nó ClusterControl).
- Vários outros consultores relacionados ao MySQL:
- Replicação - atraso na replicação, expiração do log binário, localização e crescimento
- Galera - método SST, arquivo de log GRA de varredura, verificador de endereço de cluster
- Verificação de esquema - Existência de tabela não transacional no Galera Cluster.
- Conexões - Proporção de threads conectados
- InnoDB - Proporção de páginas sujas, crescimento do arquivo de log do InnoDB
- Consultas lentas - Por padrão, o ClusterControl acionará um alarme se encontrar uma consulta em execução por mais de 30 segundos. Obviamente, isso é configurável em Configurações -> Configuração de tempo de execução -> Consulta longa.
- Deadlocks - deadlock de transações InnoDB e deadlock Galera.
- Índices - Chaves duplicadas, tabela sem chaves primárias.
Confira a página Advisors em Performance -> Advisors para obter os detalhes de coisas que podem ser melhoradas conforme sugerido pelo ClusterControl. Para cada orientador, ele fornece justificativas e conselhos, conforme mostrado no exemplo a seguir para o orientador "Verificando o uso do espaço em disco":
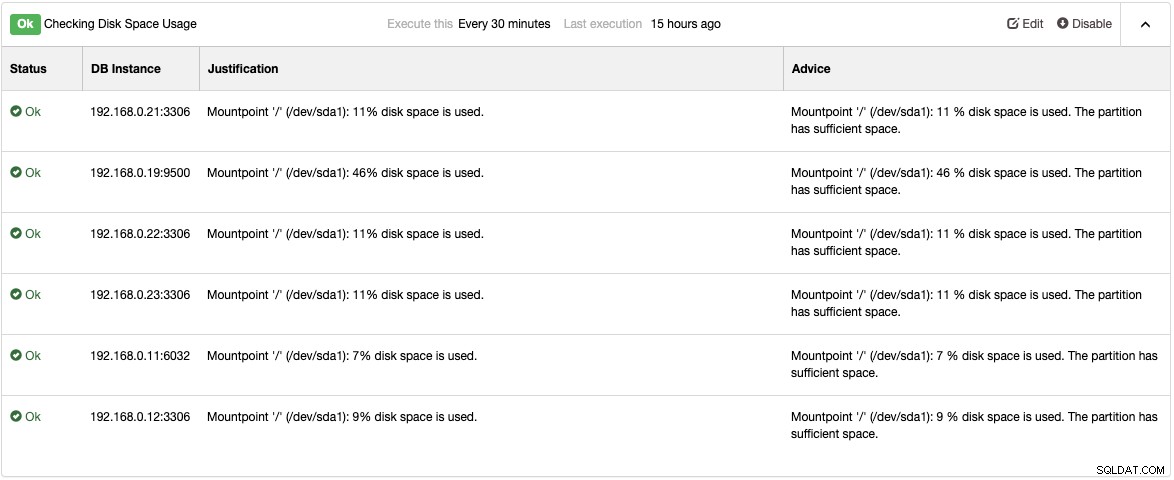
Quando ocorrer um problema de desempenho, você receberá "Aviso" (amarelo) ou Status "Crítico" (vermelho) nesses consultores. Mais ajustes são normalmente necessários para superar o problema. Os consultores emitem alarmes, o que significa que os usuários receberão uma cópia desses alarmes dentro da caixa de correio se as notificações por e-mail estiverem configuradas adequadamente. Para cada alarme gerado pelo ClusterControl ou seus consultores, os usuários também receberão um e-mail se o alarme tiver sido apagado. Eles são pré-configurados no ClusterControl e não requerem configuração inicial. Mais personalização é sempre possível em Gerenciar -> Developer Studio. Você pode conferir esta postagem no blog sobre como escrever seu próprio orientador.
ClusterControl também fornece uma página dedicada em relação ao desempenho do banco de dados em ClusterControl -> Performance. Ele fornece todos os tipos de insights de banco de dados seguindo as práticas recomendadas, como visualização centralizada do status do banco de dados, variáveis, status do InnoDB, analisador de esquema, logs de transações. Estes são bastante auto-explicativos e fáceis de entender.
Para o desempenho da consulta, você pode inspecionar as principais consultas e as consultas atípicas, onde o ClusterControl destaca as consultas que tiveram um desempenho significativamente diferente da consulta média. Cobrimos esse tópico em detalhes nesta postagem do blog, Ajuste de desempenho de consulta do MySQL.
Relatórios de erros do banco de dados
O ClusterControl vem com uma ferramenta geradora de relatórios de erros, para coletar informações de depuração sobre seu cluster de banco de dados para ajudar a entender a situação e o status atuais. Para gerar um relatório de erros, basta acessar ClusterControl -> Logs -> Relatórios de Erros -> Criar Relatório de Erros:
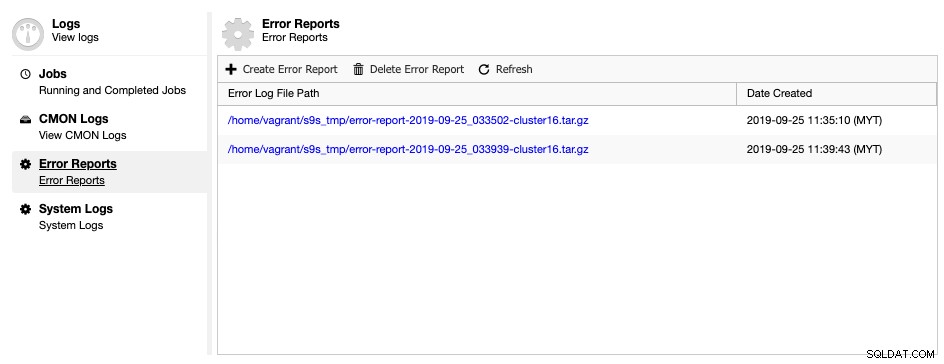
O relatório de erro gerado pode ser baixado desta página assim que estiver pronto. Este relatório gerado estará no formato TAR ball (tar.gz) e você poderá anexá-lo a uma solicitação de suporte. Como o ticket de suporte tem o limite de 10 MB de tamanho de arquivo, se o tamanho do tarball for maior que isso, você poderá carregá-lo em uma unidade na nuvem e compartilhar conosco o link de download apenas com a devida permissão. Você pode removê-lo mais tarde quando já tivermos o arquivo. Você também pode gerar o relatório de erros por meio da linha de comando, conforme explicado na página de documentação do Relatório de Erros.
No caso de uma interrupção, é altamente recomendável gerar vários relatórios de erros durante e logo após a interrupção. Esses relatórios serão muito úteis para tentar entender o que deu errado, as consequências da interrupção e verificar se o cluster está de fato de volta ao status operacional após um evento desastroso.
Conclusão
O monitoramento proativo do ClusterControl, juntamente com um conjunto de recursos de solução de problemas, fornece uma plataforma eficiente para que os usuários solucionem qualquer tipo de problema de banco de dados MySQL. Longe está a maneira herdada de solução de problemas, onde é preciso abrir várias sessões SSH para acessar vários hosts e executar vários comandos repetidamente para identificar a causa raiz.
Se os recursos mencionados acima não estiverem ajudando você a resolver o problema ou solucionar o problema do banco de dados, você sempre contata a equipe de suporte da Variousnines para fazer o backup. Nossos especialistas técnicos dedicados 24/7/365 estão disponíveis para atender sua solicitação a qualquer momento. Nosso tempo médio de primeira resposta geralmente é inferior a 30 minutos.