A replicação Galera é relativamente nova se comparada à replicação MySQL, que é suportada nativamente desde o MySQL v3.23. Embora a replicação do MySQL seja projetada para replicação unidirecional mestre-escravo, ela pode ser configurada como uma configuração mestre-mestre ativa com replicação bidirecional. Embora seja fácil de configurar e alguns casos de uso possam se beneficiar desse “hack”, há várias ressalvas. Por outro lado, o cluster Galera é um tipo diferente de tecnologia para aprender e gerenciar. Vale a pena?
Nesta postagem do blog, vamos comparar a replicação mestre-mestre com o cluster Galera.
Conceitos de replicação
Antes de entrarmos na comparação, vamos explicar os conceitos básicos por trás desses dois mecanismos de replicação.
Geralmente, qualquer modificação no banco de dados MySQL gera um evento em formato binário. Este evento é transportado para os outros nós dependendo do método de replicação escolhido - replicação MySQL (nativa) ou replicação Galera (patched com API wsrep).
Replicação MySQL
Os diagramas a seguir ilustram o fluxo de dados de uma transação bem-sucedida de um nó para outro ao usar a replicação do MySQL:
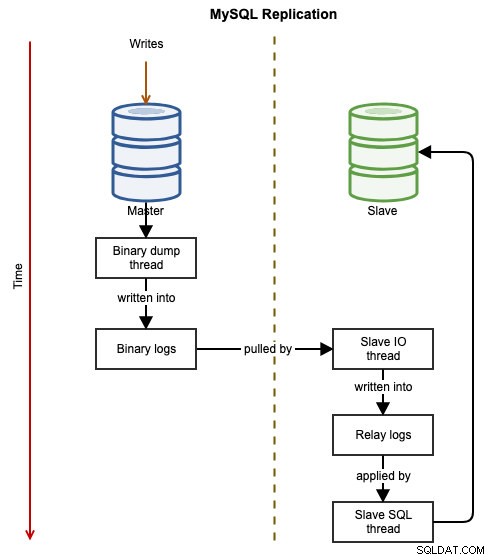
O evento binário é gravado no log binário do mestre. O(s) escravo(s) via slave_IO_thread puxará os eventos binários do log binário do mestre e os replicará em seu log de retransmissão. O slave_SQL_thread irá então aplicar o evento do log de retransmissão de forma assíncrona. Devido à natureza assíncrona da replicação, não é garantido que o servidor escravo tenha os dados quando o mestre realizar a alteração.
Idealmente, a replicação do MySQL terá o escravo configurado como um servidor somente leitura definindo read_only=ON ou super_read_only=ON. Esta é uma precaução para proteger o escravo de gravações acidentais que podem levar à inconsistência de dados ou falha durante o failover do mestre (por exemplo, transações errôneas). No entanto, em uma configuração de replicação ativo-ativo mestre-mestre, somente leitura deve ser desabilitado no outro mestre para permitir que as gravações sejam processadas simultaneamente. O mestre primário deve ser configurado para replicar do mestre secundário usando a instrução CHANGE MASTER para habilitar a replicação circular.
Replicação Galera
Os diagramas a seguir ilustram o fluxo de replicação de dados de uma transação bem-sucedida de um nó para outro para o Galera Cluster:
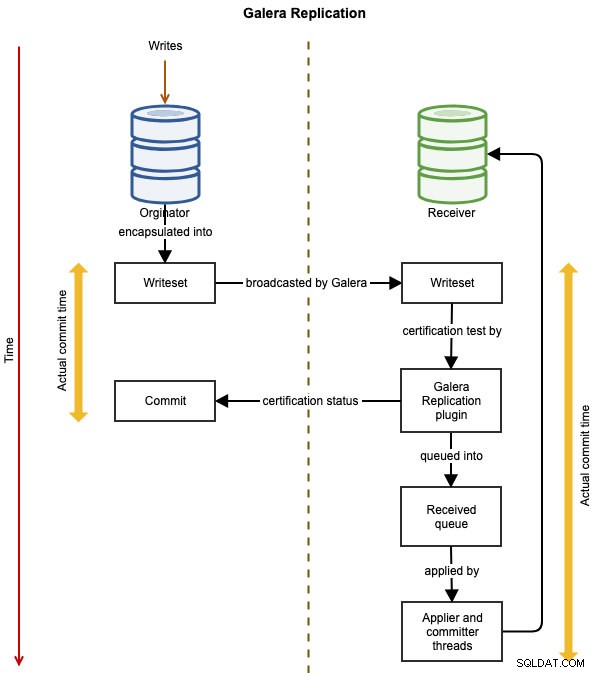
O evento é encapsulado em um conjunto de gravação e transmitido do nó originador para os outros nós do cluster usando a replicação Galera. O writeset passa por certificação em cada nó Galera e, se for aprovado, os threads do aplicador aplicarão o writeset de forma assíncrona. Isso significa que o servidor escravo eventualmente se tornará consistente, após a concordância de todos os nós participantes na ordenação total global. É logicamente síncrono, mas a escrita real e a confirmação no tablespace acontecem de forma independente e, portanto, de forma assíncrona em cada nó, com garantia de que a mudança se propague em todos os nós.
Evitando colisão de chave primária
Para implantar a replicação do MySQL na configuração mestre-mestre, é necessário ajustar o valor de incremento automático para evitar colisão de chave primária para INSERT entre dois ou mais mestres replicantes. Isso permite que o valor da chave primária nos mestres se intercalem e evite que o mesmo número de incremento automático seja usado duas vezes em qualquer um dos nós. Esse comportamento deve ser configurado manualmente, dependendo do número de mestres na configuração de replicação. O valor de auto_increment_increment é igual ao número de mestres replicantes e o auto_increment_offset deve ser único entre eles. Por exemplo, as seguintes linhas devem existir dentro do my.cnf correspondente:
Mestre1:
log-slave-updates
auto_increment_increment=2
auto_increment_offset=1Mestre2:
log-slave-updates
auto_increment_increment=2
auto_increment_offset=2Da mesma forma, Galera Cluster usa esse mesmo truque para evitar colisões de chave primária, controlando o valor de incremento automático e o deslocamento automaticamente com wsrep_auto_increment_control variável. Se definido como 1 (o padrão), ajustará automaticamente o auto_increment_increment e auto_increment_offset variáveis de acordo com o tamanho do cluster e quando o tamanho do cluster muda. Isso evita conflitos de replicação devido a auto_increment. Em um ambiente mestre-escravo, esta variável pode ser definida como OFF.
A consequência dessa configuração é que o valor do incremento automático não estará em ordem sequencial, conforme mostrado na tabela a seguir de um Galera Cluster de três nós:
| Nó | auto_increment_increment | auto_increment_offset | Valor de incremento automático |
|---|---|---|---|
| Nó 1 | 3 | 1 | 1, 4, 7, 10, 13, 16... |
| Nó 2 | 3 | 2 | 2, 5, 8, 11, 14, 17... |
| Nó 3 | 3 | 3 | 3, 6, 9, 12, 15, 18... |
Se um aplicativo executa operações de inserção nos seguintes nós na seguinte ordem:
- Nó1, Nó3, Nó2, Nó3, Nó3, Nó1, Nó3 ..
Então o valor da chave primária que será armazenado na tabela será:
- 1, 6, 8, 9, 12, 13, 15 ..
Simplificando, ao usar a replicação mestre-mestre (replicação MySQL ou Galera), seu aplicativo deve ser capaz de tolerar valores de incremento automático não sequenciais em seu conjunto de dados.
Para usuários do ClusterControl, observe que ele oferece suporte à implantação da replicação mestre-mestre do MySQL com um limite de dois mestres por cluster de replicação, apenas para configuração ativa-passiva. Portanto, o ClusterControl não configura deliberadamente os mestres com auto_increment_increment e auto_increment_offset variáveis.
Consistência de dados
O Galera Cluster vem com seu mecanismo de controle de fluxo, onde cada nó do cluster deve acompanhar ao replicar, caso contrário, todos os outros nós terão que desacelerar para permitir que o nó mais lento alcance. Isso basicamente minimiza a probabilidade de atraso do escravo, embora ainda possa acontecer, mas não tão significativo quanto na replicação do MySQL. Por padrão, o Galera permite que os nós tenham pelo menos 16 transações atrasadas na aplicação por meio da variável gcs.fc_limit . Se você quiser fazer leituras críticas (um SELECT que deve retornar as informações mais atualizadas), provavelmente desejará usar a variável de sessão, wsrep_sync_wait .
O Galera Cluster, por outro lado, vem com uma proteção contra a inconsistência de dados em que um nó será despejado do cluster se não aplicar qualquer writeset por qualquer motivo. Por exemplo, quando um nó Galera falha ao aplicar o conjunto de gravação devido a um erro interno do mecanismo de armazenamento subjacente (MySQL/MariaDB), o nó será retirado do cluster com o seguinte erro:
150305 16:13:14 [ERROR] WSREP: Failed to apply trx 1 4 times
150305 16:13:14 [ERROR] WSREP: Node consistency compromized, aborting..Para corrigir a consistência dos dados, o nó incorreto deve ser sincronizado novamente antes de poder ingressar no cluster. Isso pode ser feito manualmente ou apagando o diretório de dados para acionar a transferência de estado do instantâneo (sincronização completa de um doador).
A replicação mestre-mestre do MySQL não impõe proteção de consistência de dados e um escravo pode divergir, por exemplo, replicar um subconjunto de dados ou ficar para trás, o que torna o escravo inconsistente com o mestre. Ele foi projetado para replicar dados em um fluxo - do mestre até os escravos. As verificações de consistência de dados devem ser realizadas manualmente ou por meio de ferramentas externas como Percona Toolkit pt-table-checksum ou mysql-replication-check.
Resolução de conflitos
Geralmente, a replicação mestre-mestre (ou multimestre ou bidirecional) permite que mais de um membro no cluster processe gravações. Com a replicação do MySQL, em caso de conflito de replicação, o thread SQL do escravo simplesmente para de aplicar a próxima consulta até que o conflito seja resolvido, seja pulando manualmente o evento de replicação, corrigindo as linhas incorretas ou ressincronizando o escravo. Dito de forma simples, não há suporte para resolução automática de conflitos para a replicação do MySQL.
O Galera Cluster oferece uma alternativa melhor ao tentar novamente a transação incorreta durante a replicação. Usando wsrep_retry_autocommit variável, pode-se instruir o Galera a repetir automaticamente uma transação com falha devido a conflitos em todo o cluster, antes de retornar um erro ao cliente. Se definido como 0, nenhuma tentativa será feita, enquanto um valor de 1 (o padrão) ou mais especifica o número de tentativas tentadas. Isso pode ser útil para ajudar os aplicativos que usam o autocommit para evitar deadlocks.
Consenso de nós e failover
O Galera usa o Group Communication System (GCS) para verificar o consenso e a disponibilidade dos nós entre os membros do cluster. Se um nó não estiver íntegro, ele será automaticamente despejado do cluster após gmcast.peer_timeout valor, padrão para 3 segundos. Um nó Galera íntegro no estado "Sincronizado" é considerado um nó confiável para servir leituras e gravações, enquanto outros não. Esse design simplifica bastante os procedimentos de verificação de integridade das camadas superiores (balanceador de carga ou aplicativo).
Na replicação do MySQL, um mestre não se importa com seu(s) escravo(s), enquanto um escravo só tem consenso com seu único mestre através do slave_IO_thread processo ao replicar os eventos binários do log binário do mestre. Se um mestre cair, isso interromperá a replicação e uma tentativa de restabelecer o link será feita a cada slave_net_timeout (padrão para 60 segundos). Do ponto de vista do aplicativo ou do balanceador de carga, os procedimentos de verificação de integridade para o escravo de replicação devem envolver pelo menos a verificação do seguinte estado:
- Seconds_Behind_Master
- Slave_IO_Running
- Slave_SQL_Running
- variável somente leitura
- variável super_read_only (MySQL 5.7.8 e posterior)
Em termos de failover, geralmente, a replicação mestre-mestre e os nós Galera são iguais. Eles mantêm o mesmo conjunto de dados (embora você possa replicar um subconjunto de dados na replicação do MySQL, mas isso é incomum para mestre-mestre) e compartilham a mesma função que os mestres, capazes de lidar com leituras e gravações simultaneamente. Portanto, na verdade não há failover do ponto de vista do banco de dados devido a esse equilíbrio. Somente do lado do aplicativo que exigiria failover para ignorar os nós não operacionais. Tenha em mente que, como a replicação do MySQL é assíncrona, é possível que nem todas as alterações feitas no mestre sejam propagadas para o outro mestre.
Aprovisionamento de nós
O processo de sincronizar um nó com o cluster antes do início da replicação é conhecido como provisionamento. Na replicação do MySQL, o provisionamento de um novo nó é um processo manual. É preciso fazer um backup do mestre e restaurá-lo no novo nó antes de configurar o link de replicação. Para um nó de replicação existente, se os logs binários do mestre tiverem sido alternados (com base em expire_logs_days , o padrão 0 significa que não há remoção automática), talvez seja necessário provisionar novamente o nó usando este procedimento. Existem também ferramentas externas como Percona Toolkit pt-table-sync e ClusterControl para ajudá-lo nisso. O ClusterControl suporta a ressincronização de um escravo com apenas dois cliques. Você tem opções para ressincronizar fazendo um backup do mestre ativo ou de um backup existente.
No Galera, existem duas maneiras de fazer isso - transferência de estado incremental (IST) ou transferência de instantâneo de estado (SST). O processo IST é o método preferido onde apenas as transações ausentes são transferidas do cache de um doador. O processo SST é semelhante a fazer um backup completo do doador, geralmente consome muitos recursos. O Galera determinará automaticamente qual processo de sincronização será acionado com base no estado do joiner. Na maioria dos casos, se um nó falhar ao ingressar em um cluster, simplesmente limpe o diretório de dados do MySQL do nó problemático e inicie o serviço MySQL. O processo de provisionamento do Galera é muito mais simples, é muito útil ao dimensionar seu cluster ou reintroduzir um nó problemático de volta ao cluster.
Frouxamente Acoplado vs Fortemente Acoplado
A replicação do MySQL funciona muito bem mesmo em conexões mais lentas e com conexões que não são contínuas. Ele também pode ser usado em diferentes hardwares, ambientes e sistemas operacionais. A maioria dos mecanismos de armazenamento o suporta, incluindo MyISAM, Aria, MEMORY e ARCHIVE. Essa configuração fracamente acoplada permite que a replicação mestre-mestre do MySQL funcione bem em um ambiente misto com menos restrições.
Os nós Galera são fortemente acoplados, onde o desempenho da replicação é tão rápido quanto o nó mais lento. Galera usa um mecanismo de controle de fluxo para controlar o fluxo de replicação entre os membros e eliminar qualquer atraso escravo. A replicação pode ser toda rápida ou toda lenta em cada nó e é ajustada automaticamente pelo Galera. Assim, é recomendado usar especificações de hardware uniformes para todos os nós do Galera, especialmente com relação à CPU, RAM, subsistema de disco, placa de interface de rede e latência de rede entre os nós do cluster.
Conclusões
Em resumo, Galera Cluster é superior se comparado à replicação mestre-mestre MySQL devido ao seu suporte a replicação síncrona com forte consistência, além de recursos mais avançados como controle automático de associação, provisionamento automático de nós e escravos multi-thread. Em última análise, isso depende de como o aplicativo interage com o servidor de banco de dados. Alguns aplicativos legados criados para um servidor de banco de dados autônomo podem não funcionar bem em uma configuração em cluster.
Para simplificar nossos pontos acima, os seguintes motivos justificam quando usar a replicação mestre-mestre do MySQL:
- Coisas que não são suportadas pelo Galera:
- Replicação para tabelas não InnoDB/XtraDB como MyISAM, Aria, MEMORY ou ARCHIVE.
- Transações XA.
- Replicação baseada em instruções entre mestres (por exemplo, quando a largura de banda é muito cara).
- Contando com o bloqueio explícito como a instrução LOCK TABLES.
- O log de consulta geral e o log de consulta lenta devem ser direcionados para uma tabela, em vez de um arquivo.
- Configuração fracamente acoplada em que as especificações de hardware, a versão do software e a velocidade de conexão são significativamente diferentes em cada master.
- Quando você já tem uma cadeia de replicação MySQL e deseja adicionar outro mestre ativo/backup para redundância para acelerar o failover e o tempo de recuperação caso um dos mestres não esteja disponível.
- Se seu aplicativo não puder ser modificado para contornar as limitações do Galera Cluster e ter um balanceador de carga compatível com MySQL, como ProxySQL ou MaxScale, não for uma opção.
Razões para escolher o Galera Cluster sobre a replicação mestre-mestre do MySQL:
- Capacidade de gravar com segurança em vários mestres.
- Consistência de dados gerenciada automaticamente (e garantida) nos bancos de dados.
- Novos nós de banco de dados facilmente introduzidos e sincronizados.
- Falhas ou inconsistências detectadas automaticamente.
- Em geral, recursos de alta disponibilidade mais avançados e robustos.