Introdução
O envio de logs de transações é uma tecnologia muito conhecida usada no SQL Server para manter uma cópia do banco de dados ativo no site de recuperação de desastres. A tecnologia depende de três tarefas principais:a tarefa de backup, a tarefa de cópia e a tarefa de restauração. Enquanto a tarefa de backup é executada no servidor principal, as tarefas de cópia e restauração são executadas no servidor secundário. Essencialmente, o processo envolve backups periódicos do log de transações para um compartilhamento do qual o trabalho de cópia é movido para o servidor secundário; posteriormente, a tarefa de restauração aplica os backups de log ao servidor secundário. Antes de tudo isso começar, o Banco de Dados Secundário deve ser inicializado com um backup completo do servidor Primário restaurado com a opção NORECOVERY.
A Microsoft fornece um conjunto de procedimentos armazenados que podem ser usados para configurar o Log Shipping de ponta a ponta, bem como equivalentes de GUI a partir do item de propriedades de cada banco de dados para o qual você deseja configurar o Log Shipping. Vale ressaltar que o Banco de Dados Secundário pode ser configurado no modo NORECOVERY ou no modo STANDBY. No modo NORECOVERY, o banco de dados nunca está disponível para consultas, mas no modo STANDBY, o banco de dados secundário pode ser consultado quando nenhuma operação de restauração do log de transações estiver em andamento.
Configurando o ambiente
Para dar o pontapé inicial, criamos duas instâncias do SQL Server na AWS com uma imagem idêntica do Amazon EC2. Esta instância do Amazon EC2 está executando o SQL Server 2017 RTM-CU5 no Windows Server 2016. Em seguida, restauramos uma cópia do banco de dados WideWorldImporters usando um conjunto de backup adquirido do GitHub para a primeira instância, nossa instância primária. Usamos o mesmo conjunto de backup para criar dois bancos de dados idênticos chamados BranchDB e CorporateDB.
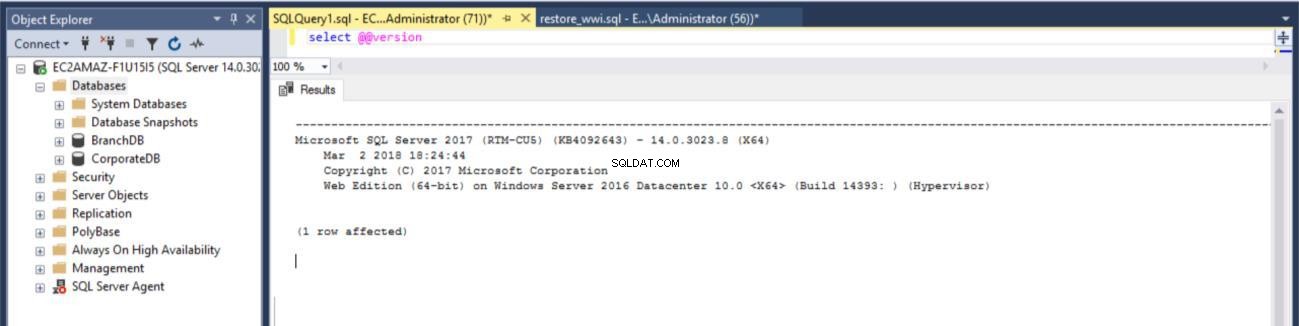
Fig. 1 Versão do SQL Server
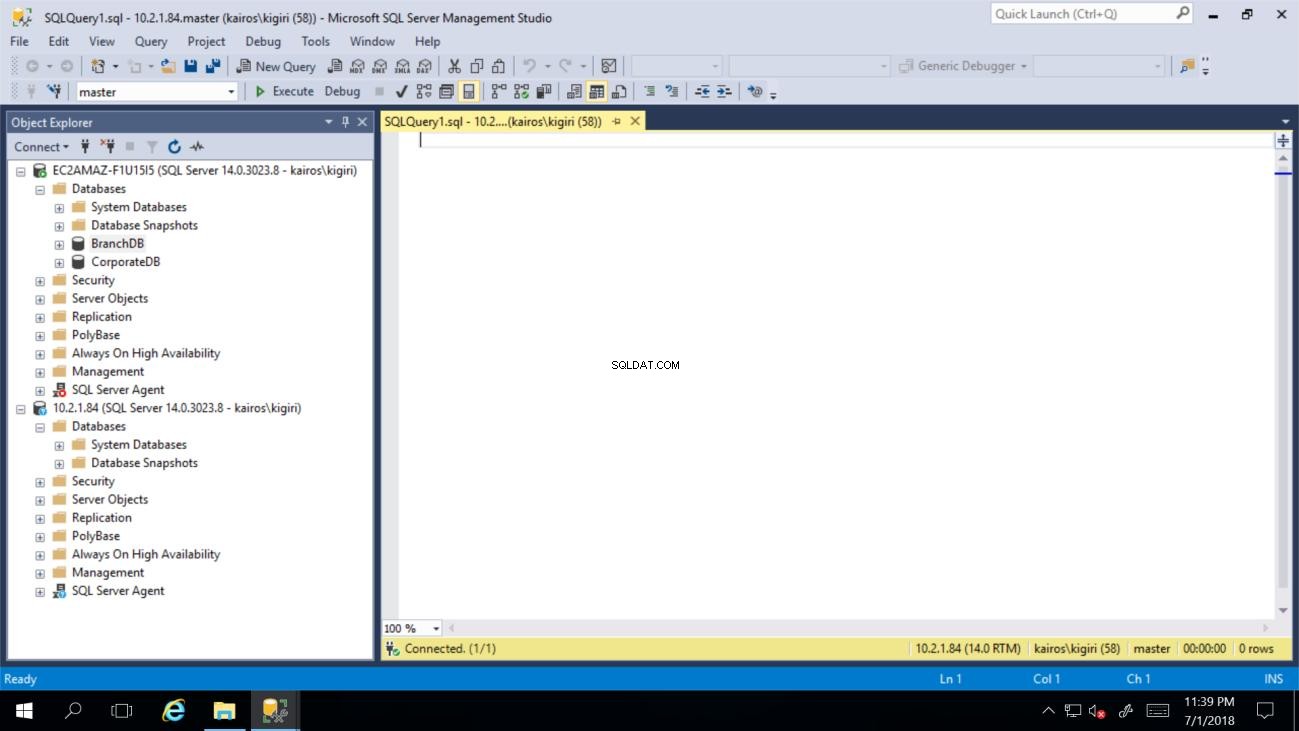
Fig. 2 BranchDB e CorporateDB na instância primária (instância secundária em branco)
Lista 1:Restaurando o banco de dados de amostra WideWorldImporters
restore filelistonly from disk='WideWorldImporters-Full.bak' restore database CorporateDB from disk='WideWorldImporters-Full.bak' with stats=10,recovery, move 'WWI_Primary' to 'M:\MSSQL\Data\WWI_Primary.mdf' , move 'WWI_UserData' to 'M:\MSSQL\Data\WWI_UserData.ndf' , move 'WWI_Log' to 'N:\MSSQL\Log\WWI_Log.ldf', move 'WWI_InMemory_Data_1' to 'M:\MSSQL\Data\WWI_InMemory_Data_1.ndf' restore database BranchDB from disk='WideWorldImporters-Full.bak' with stats=10,recovery, move 'WWI_Primary' to 'M:\MSSQL\Data\WWI_Primary1.mdf' , move 'WWI_UserData' to 'M:\MSSQL\Data\WWI_UserData1.ndf' , move 'WWI_Log' to 'N:\MSSQL\Log\WWI_Log1.ldf', move 'WWI_InMemory_Data_1' to 'M:\MSSQL\Data\WWI_InMemory_Data_11.ndf
Agora temos duas instâncias, a Instância Primária que hospeda os dois bancos de dados Primários (BranchDB e CorporateDB e a instância Secundária sem bancos de dados de usuário. Continuamos com a configuração de Envio de Log de Transação em ambos os bancos de dados, mas os diferenciamos aplicando um atraso à configuração de restauração do primeiro banco de dados. Lembre-se que os bancos de dados são realmente idênticos em termos de dados que contêm. Os gráficos a seguir mostram as principais opções selecionadas na configuração de envio de logs.
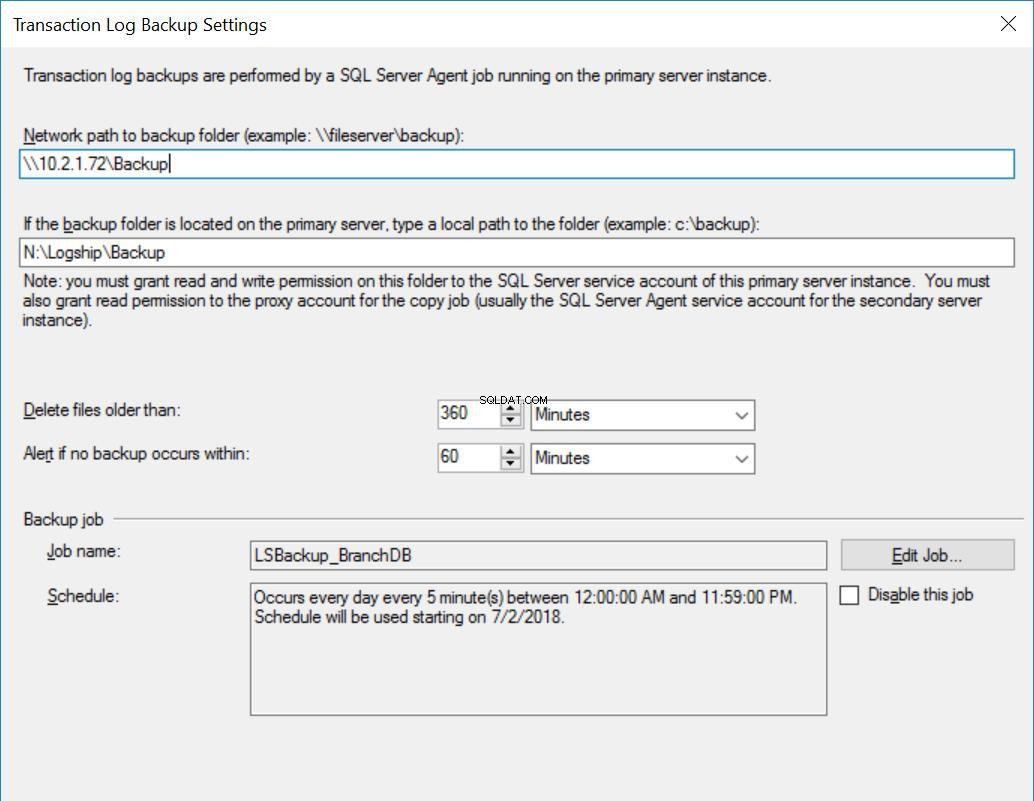
Fig. 3 Configurações de backup para BranchDB
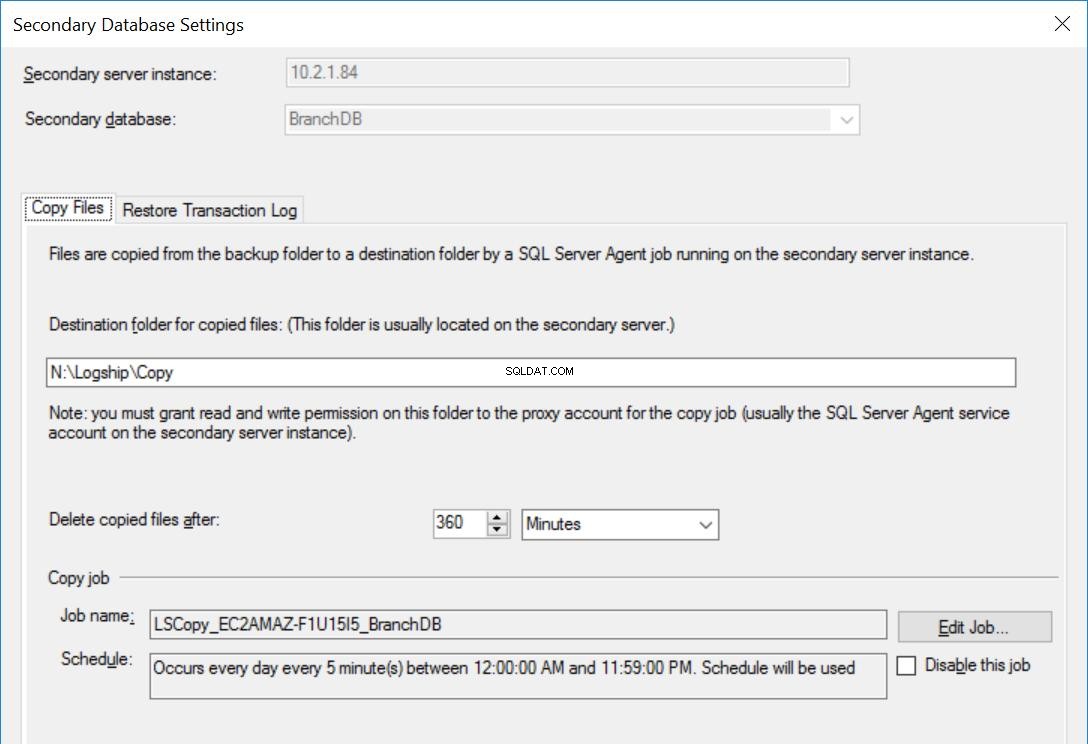
Fig. 4 Copiar configurações para BranchDB
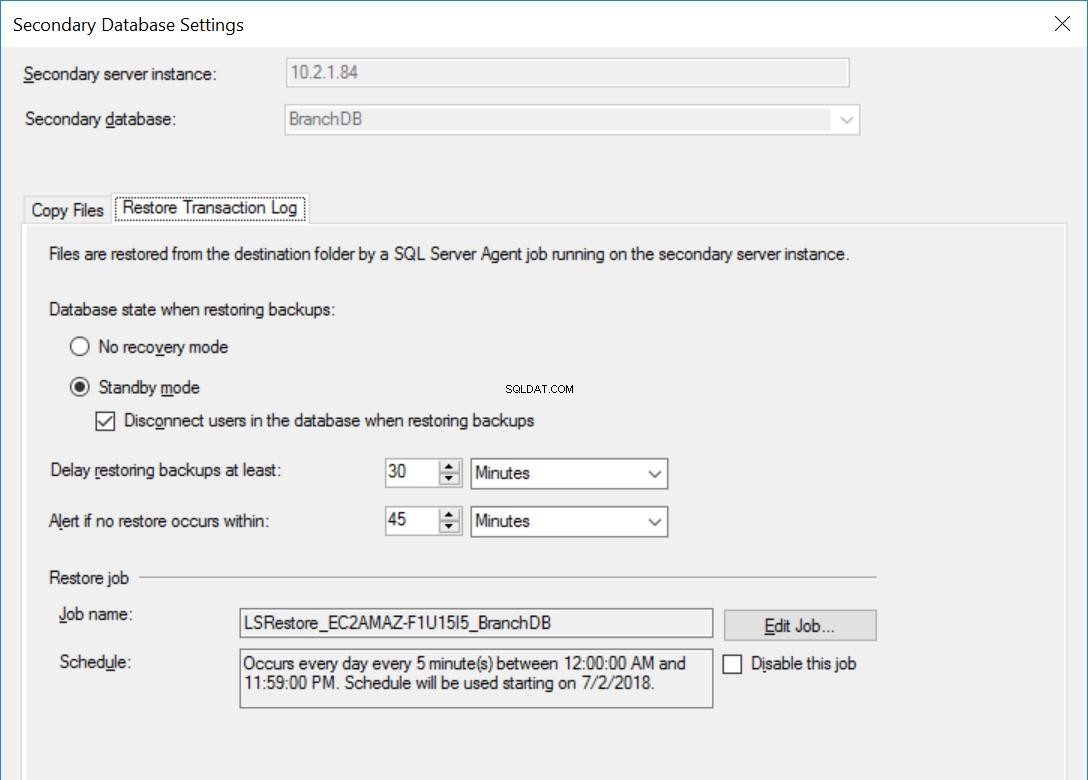
Fig. 5 Restaurar configurações para BranchDB
Cada trabalho de envio de log é configurado para ser executado a cada cinco minutos. Para processar “Delay Restoring Backups”, devemos usar o modo Standby Recovery na configuração de Log Shipping. É lógico, pois tem o Banco de Dados Secundário em modo de espera e indica que podemos consultar o Banco de Dados Secundário sempre que uma Restauração do Log de Transação não estiver em andamento. O valor que especificamos nesta opção (30 minutos neste caso) nos dá uma boa janela durante a qual podemos executar relatórios do Banco de Dados Secundário, além do requisito principal deste artigo, que é ser capaz de se recuperar de um erro do usuário.
Além disso, devemos mencionar que a restauração dos backups do log de transações está realmente atrasada. Seu carimbo de data/hora é posterior ao valor de atraso. Isso significa que todos os backups de log de transações serão copiados para o servidor secundário, que é baseado no agendamento e especificado na tarefa de cópia. Na verdade, a tarefa de restauração ainda será executada conforme a programação, mas os backups de log de transações (com menos de 30 minutos) não serão restaurados. Em essência, o banco de dados BranchDB Standby está 30 minutos atrás do banco de dados principal BranchDB. Para demonstrar essa defasagem, na próxima seção, criaremos uma tabela nos dois bancos de dados e criaremos um trabalho que insere um registro a cada minuto. Examinaremos esta tabela nas Bases de Dados Secundárias.
As configurações para o banco de dados CorporateDB são as mesmas das Figs. 3 a 5, exceto para o trabalho de restauração que NÃO está definido para atrasar os backups do log de transações.
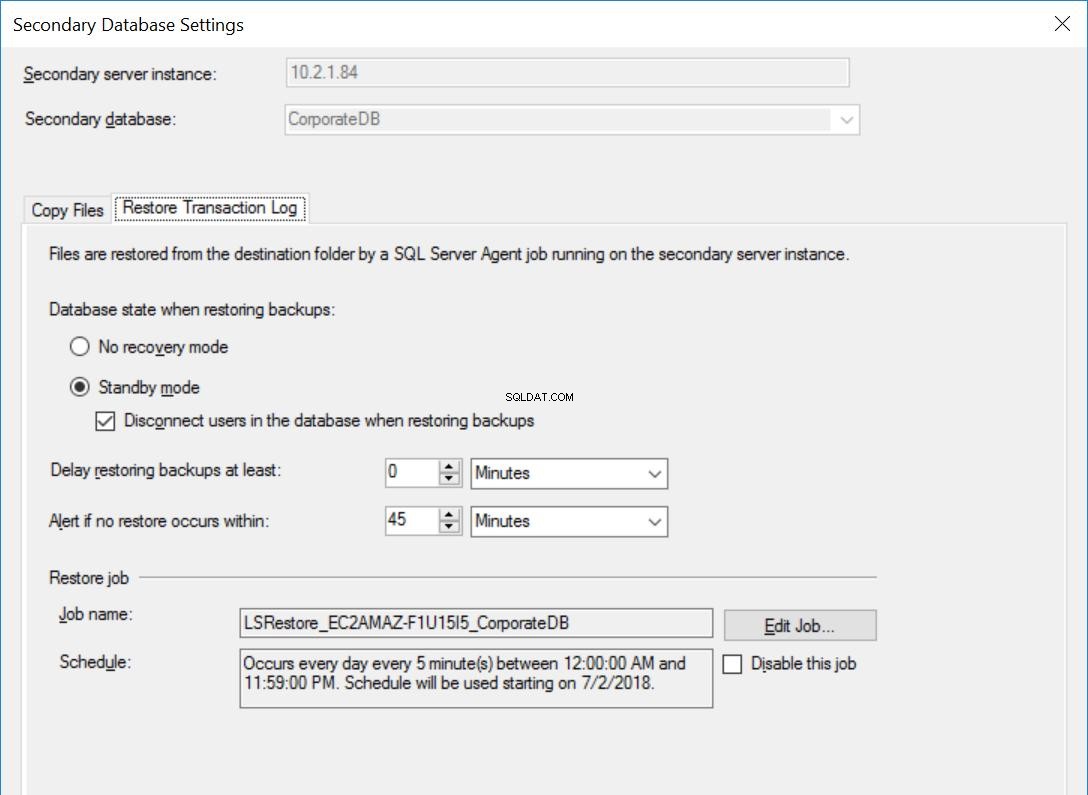
Fig. 6 Restaurar configurações para CorporateDB
Verificando a configuração
Feita a configuração, podemos verificar se a configuração está OK e começar a observar o seu funcionamento. O relatório de envio do log de transações nos mostra que o banco de dados da filial está realmente atrasado em relação ao CorporateDB em termos de restaurações:
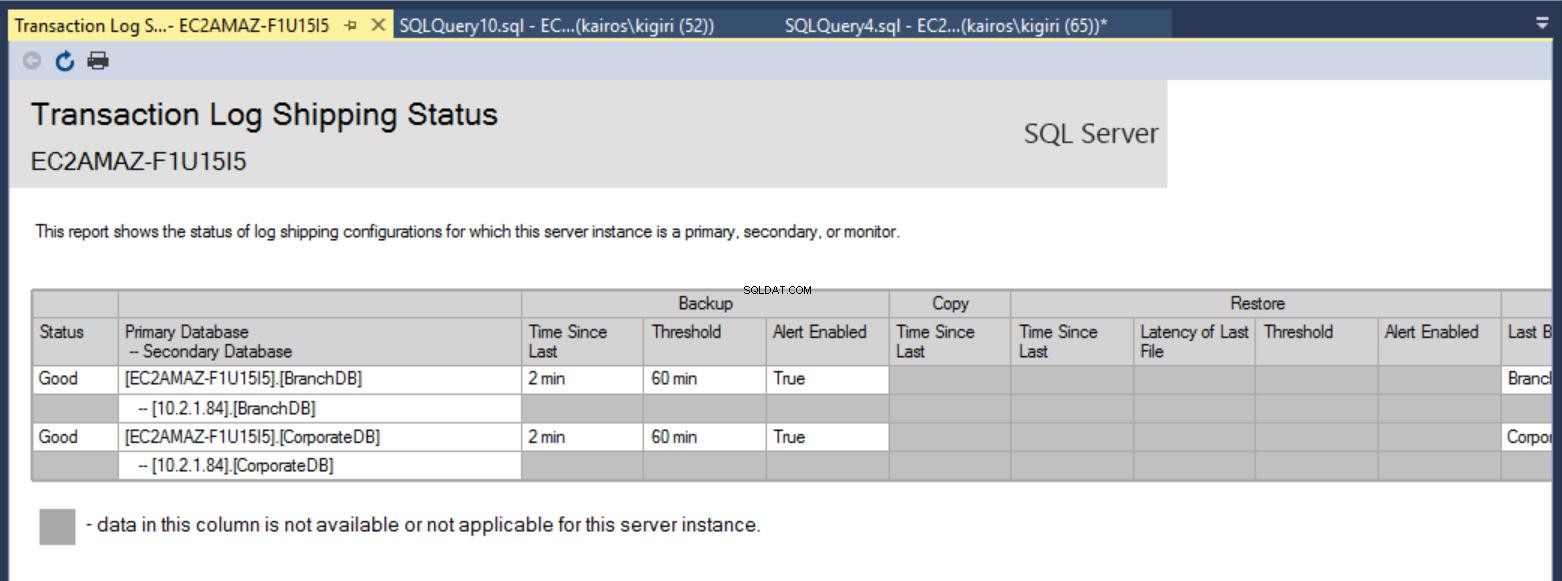
Fig. 7a Relatório de envio de log de transações no servidor principal
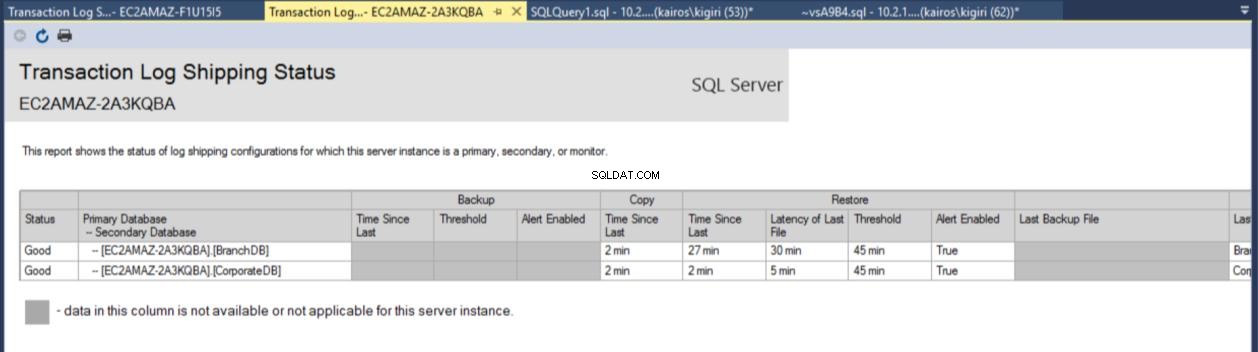
Fig. 7b Relatório de envio de log de transações no servidor secundário
Além disso, você notará a mensagem abaixo no histórico de tarefas de restauração para o BranchDB:
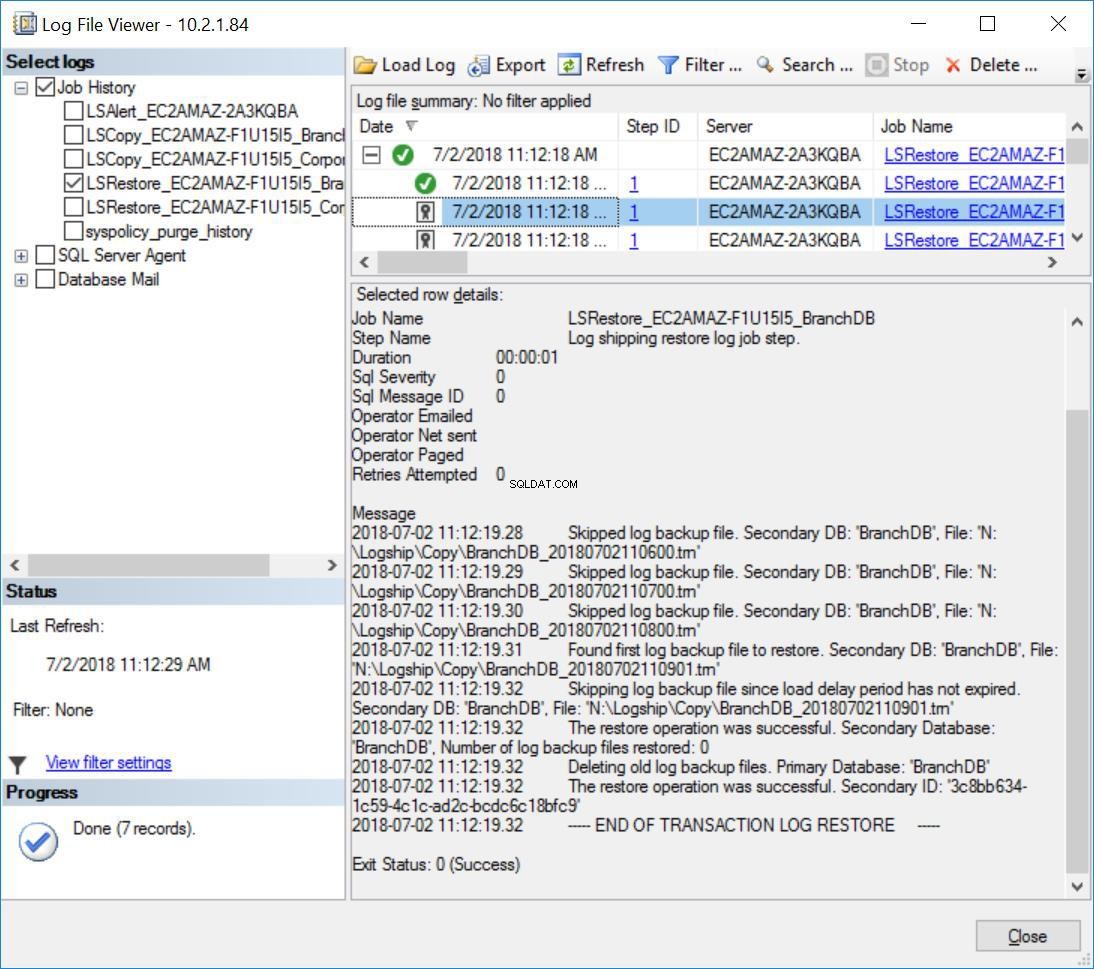
Fig. 8 Restaurações de log de transações ignoradas no servidor secundário
Podemos ir mais longe com essa verificação criando uma tabela e usando um trabalho para preencher essa tabela com linhas a cada minuto. O trabalho é uma maneira simples de simular o que um aplicativo pode estar fazendo em uma tabela de usuário. Isso pode nos mostrar que esse atraso é definitivamente mostrado nos dados do usuário.
Lista 2 – Criar tabela de rastreamento de log
use BranchDB go create table log_ship_tracker ( ID int identity (100,1) ,Database_Name sysname default db_name() ,RecordTime datetime default getdate() ,ServerName sysname default @@servername) use CorporateDB go create table log_ship_tracker ( ID int identity (100,1) ,Database_Name sysname default db_name() ,RecordTime datetime default getdate() ,ServerName sysname default @@servername)
Lista 3 – Criar trabalho para preencher a tabela do rastreador de log
/* ==Scripting Parameters== Source Server Version : SQL Server 2017 (14.0.3023) Source Database Engine Edition : Microsoft SQL Server Standard Edition Source Database Engine Type : Standalone SQL Server Target Server Version : SQL Server 2017 Target Database Engine Edition : Microsoft SQL Server Standard Edition Target Database Engine Type : Standalone SQL Server */ USE [msdb] GO /****** Object: Job [InsertRecords] Script Date: 7/2/2018 3:32:00 PM ******/ BEGIN TRANSACTION DECLARE @ReturnCode INT SELECT @ReturnCode = 0 /****** Object: JobCategory [[Uncategorized (Local)]] Script Date: 7/2/2018 3:32:00 PM ******/ IF NOT EXISTS (SELECT name FROM msdb.dbo.syscategories WHERE name=N'[Uncategorized (Local)]' AND category_class=1) BEGIN EXEC @ReturnCode = msdb.dbo.sp_add_category @class=N'JOB', @type=N'LOCAL', @name=N'[Uncategorized (Local)]' IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback END DECLARE @jobId BINARY(16) EXEC @ReturnCode = msdb.dbo.sp_add_job @job_name=N'InsertRecords', @enabled=1, @notify_level_eventlog=0, @notify_level_email=0, @notify_level_netsend=0, @notify_level_page=0, @delete_level=0, @description=N'No description available.', @category_name=N'[Uncategorized (Local)]', @owner_login_name=N'kairos\kigiri', @job_id = @jobId OUTPUT IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback /****** Object: Step [InsertRecords] Script Date: 7/2/2018 3:32:00 PM ******/ EXEC @ReturnCode = msdb.dbo.sp_add_jobstep @example@sqldat.com, @step_name=N'InsertRecords', @step_id=1, @cmdexec_success_code=0, @on_success_action=1, @on_success_step_id=0, @on_fail_action=2, @on_fail_step_id=0, @retry_attempts=0, @retry_interval=0, @os_run_priority=0, @subsystem=N'TSQL', @command=N'use BranchDB go insert into log_ship_tracker values (db_name(),getdate(),@@servername) use CorporateDB go insert into log_ship_tracker values (db_name(),getdate(),@@servername) GO', @database_name=N'master', @flags=0 IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback EXEC @ReturnCode = msdb.dbo.sp_update_job @job_id = @jobId, @start_step_id = 1 IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback EXEC @ReturnCode = msdb.dbo.sp_add_jobschedule @example@sqldat.com, @name=N'Schedule', @enabled=1, @freq_type=4, @freq_interval=1, @freq_subday_type=4, @freq_subday_interval=1, @freq_relative_interval=0, @freq_recurrence_factor=0, @active_start_date=20180702, @active_end_date=99991231, @active_start_time=0, @active_end_time=235959, @schedule_uid=N'03e5f1b2-2e0b-4b30-8d60-3643c84aa08d' IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback EXEC @ReturnCode = msdb.dbo.sp_add_jobserver @job_id = @jobId, @server_name = N'(local)' IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback COMMIT TRANSACTION GOTO EndSave QuitWithRollback: IF (@@TRANCOUNT > 0) ROLLBACK TRANSACTION EndSave: GO
Quando consultamos a tabela nos Bancos de Dados Primários, respectivamente, podemos confirmar (usando a coluna RecordTime) que as linhas correspondem em BranchDB e CorporateDB. Quando examinamos a tabela nos Bancos de Dados Secundários, da mesma forma, vemos claramente que temos um intervalo de 30 minutos entre BranchDB e CorporateDB.
Listagem 4 – Como consultar a tabela do rastreador de registros
select top 10 @@servername [Current_Server],* from BranchDB.dbo.log_ship_tracker order by RecordTime desc select top 10 @@servername [Current_Server], * from CorporateDB.dbo.log_ship_tracker order by RecordTime desc
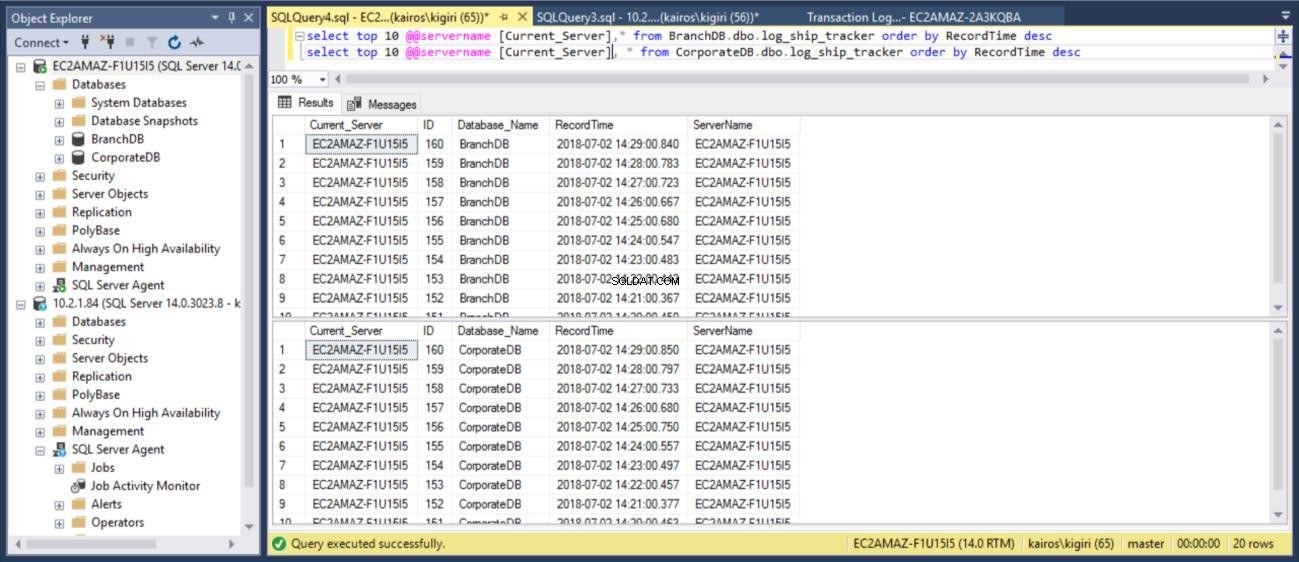
Fig. 9 correspondências de tabelas do rastreador de registros em bancos de dados primários
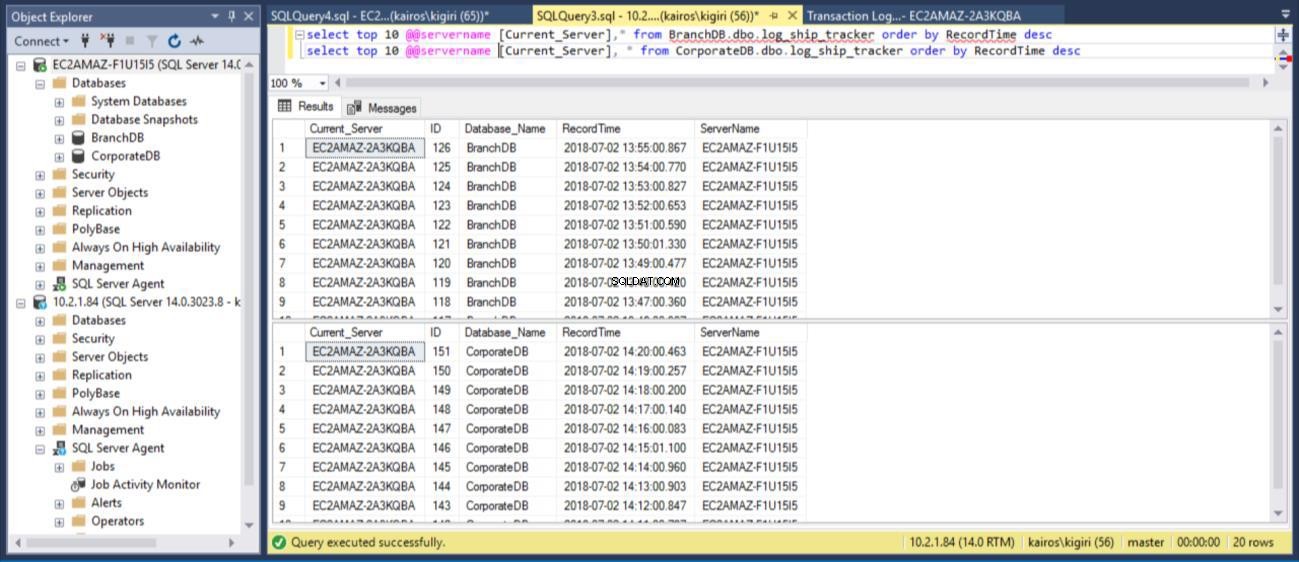
Fig. 10 tabelas do rastreador de logs têm um intervalo de aproximadamente 30 minutos em bancos de dados secundários
Recuperando do erro do usuário
Agora vamos falar sobre o principal benefício desse atraso. No cenário em que um usuário descarta inadvertidamente uma tabela, podemos recuperar os dados rapidamente do Banco de Dados Secundário, desde que o período de atraso não tenha decorrido. Neste exemplo, descartamos a tabela Sales.Orderlines em AMBOS os bancos de dados e verificamos se a tabela não existe mais em AMBOS os bancos de dados.
Lista 5 – Tabela de Descarte de Linhas de Pedido
drop table BranchDB.Sales.Orderlines drop table CorporateDB.Sales.Orderlines GO use BranchDB go select @@servername [Current_Server] , db_name() [Database_Name] , name , schema_name(schema_id) [schema] , type_desc , create_date , modify_date from sys.tables where name='Orderlines' GO use CorporateDB go select @@servername [Current_Server] , db_name() [Database_Name] , name , schema_name(schema_id) [schema] , type_desc , create_date , modify_date from sys.tables where name='Orderlines' GO
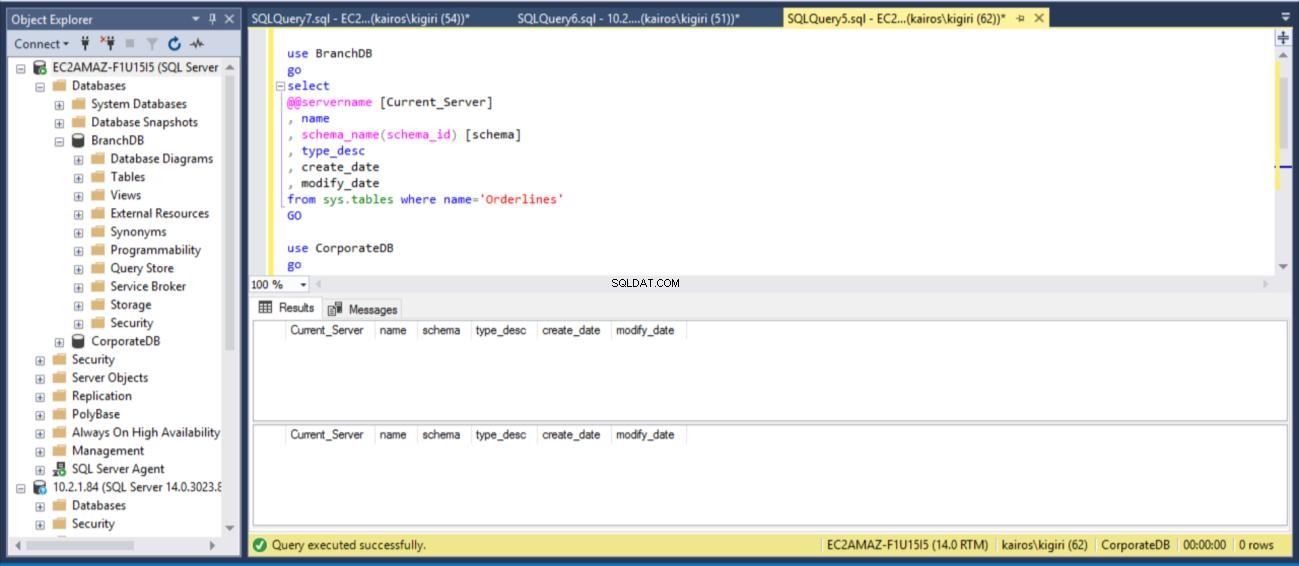
Fig. 11 Queda de Vendas de Mesa. Linhas de Pedido
Quando procuramos a tabela no Servidor Secundário, descobrimos que a tabela ainda está disponível em AMBOS os bancos de dados. Assim, para o CorporateDB temos menos de cinco minutos para recuperar os dados. (Fig. 12). Mas uma vez que o próximo ciclo de restauração é executado, perdemos a tabela no banco de dados Corporate DB. Para recuperar essa tabela, precisamos fazer uma recuperação pontual usando um backup completo em um ambiente separado e, em seguida, extrair essa tabela específica. Você vai concordar que vai levar algum tempo. Para a tabela BranchDB Orderlines, temos um pouco mais de tempo e podemos recuperar a tabela com uma única instrução SQL em um servidor vinculado (consulte a Listagem 6).
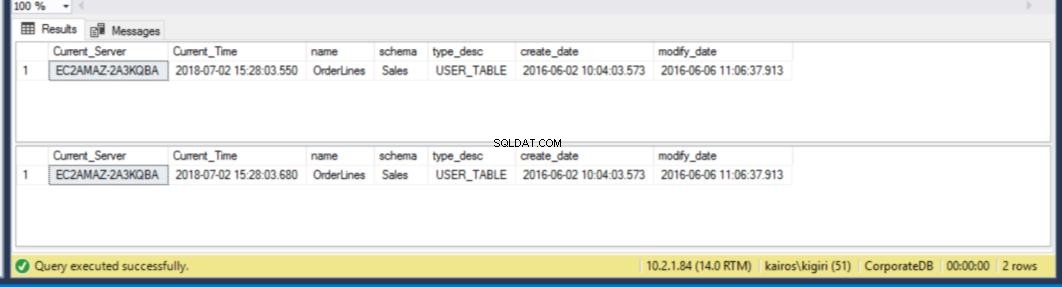
Fig. Contagem regressiva de 12 minutos:a tabela existe em ambos os bancos de dados secundários
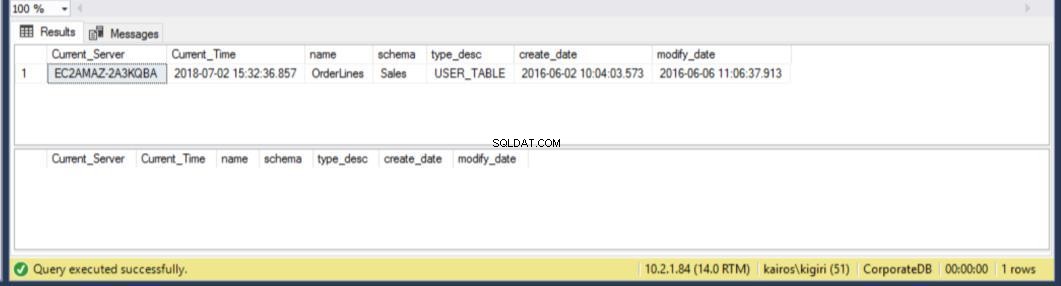
Fig. 13 25 minutos adicionais para recuperar a tabela BranchDB
Listagem 6 – Tabela de Recuperação de Pedidos
USE [master] GO /****** Object: LinkedServer [10.2.1.84] Script Date: 7/2/2018 4:14:59 PM ******/ EXEC master.dbo.sp_addlinkedserver @server = N'10.2.1.84', @srvproduct=N'SQL Server' /* For security reasons the linked server remote logins password is changed with ######## */ EXEC master.dbo.sp_addlinkedsrvlogin @rmtsrvname=N'10.2.1.84',@useself=N'True',@locallogin=NULL,@rmtuser=NULL,@rmtpasswo rd=NULL GO select * into BranchDB.Sales.Orderlines from [10.2.1.84].BranchDB.Sales.Orderlines
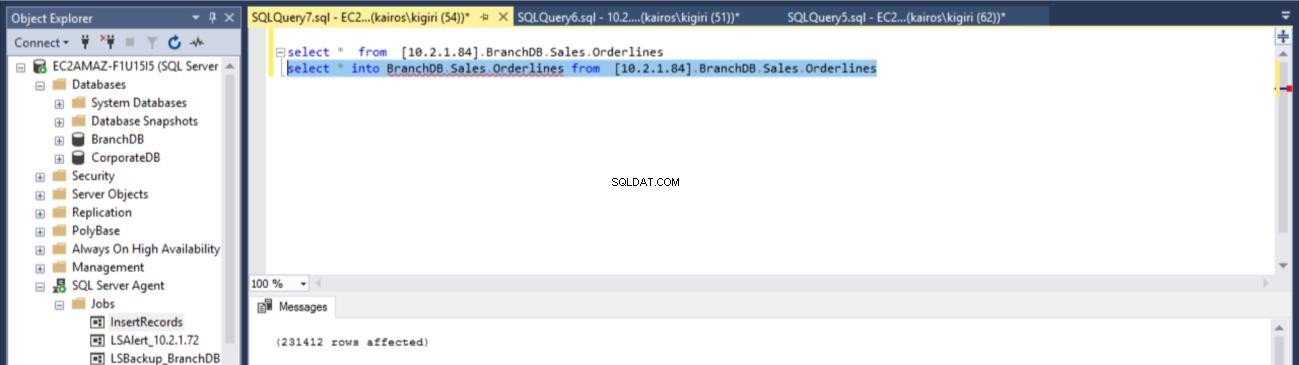
Fig. 14 Recupere a tabela BranchDB Sales.Orderlines
Em seguida, verificamos no Servidor Principal (Banco de Dados BranchDB) que a tabela foi restaurada.
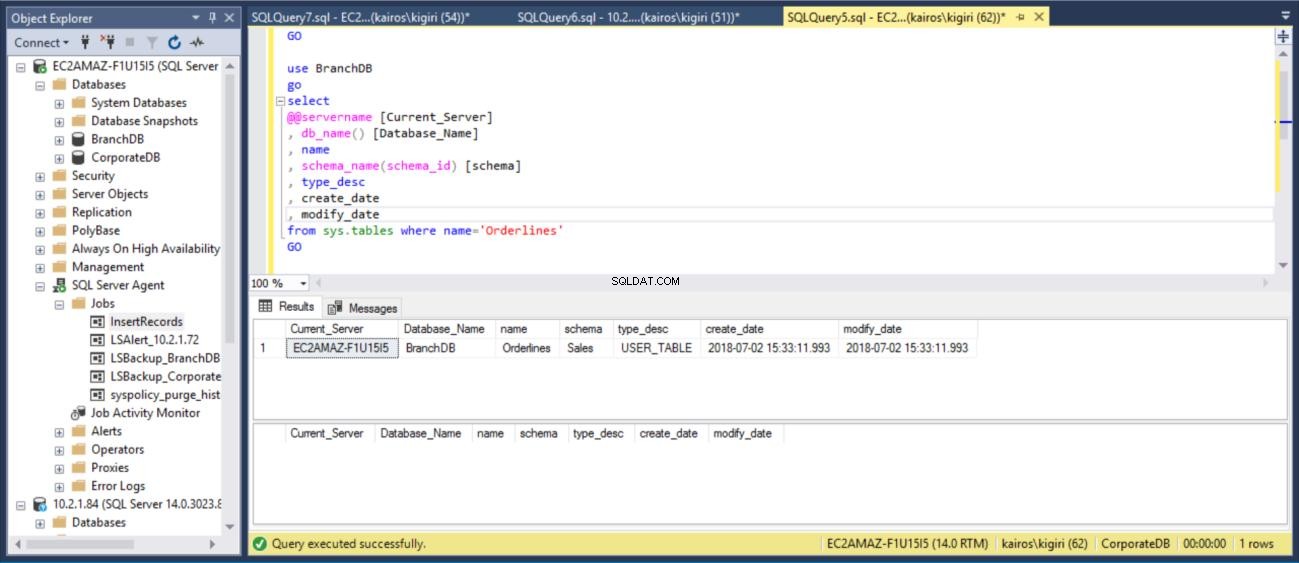
Fig. 15 Recupere a tabela BranchDB Sales.Orderlines
Conclusão
O SQL Server oferece várias maneiras de se recuperar da perda de dados de uma variedade de causas principais – falha de disco, corrupção, erro do usuário etc. A recuperação pontual de backups é provavelmente o mais conhecido desses métodos. Para certos casos simples de erro do usuário ou caso semelhante, onde um ou dois objetos são perdidos, o uso do Transaction Log Shipping com Recuperação Atrasada é uma boa abordagem a ser considerada. No entanto, deve-se observar que um banco de dados secundário, configurado estritamente para necessidades de DR, deve ser selecionado para RPOs mais baixos.