O tópico de cache apareceu no PostgreSQL há 22 anos, e naquela época o foco era a confiabilidade do banco de dados.
Avançando rapidamente para 2020, os pratos de disco estão ainda mais ocultos em ambientes virtualizados, hipervisores e dispositivos de armazenamento associados. Além disso, aplicativos distribuídos e interconectados que operam em escala global estão clamando por conexões de baixa latência e, de repente, ajustar os caches do servidor, e as consultas SQL competem para garantir que os resultados sejam retornados aos clientes em milissegundos. Os caches de nível de aplicativo e de memória nascem e as consultas de leitura agora são salvas perto dos servidores de aplicativos. Como resultado, as operações de E/S são reduzidas apenas a gravações e a latência da rede é drasticamente aprimorada. Com uma captura. As implementações são responsáveis por seu próprio gerenciamento de cache, o que às vezes leva à degradação do desempenho.
Caching writes é uma questão muito mais complicada, conforme explicado no wiki do PostgreSQL.
Este blog é uma visão geral dos caches de consulta na memória e balanceadores de carga que estão sendo usados com o PostgreSQL.
Balanceamento de carga PostgreSQL
A ideia de balanceamento de carga surgiu ao mesmo tempo que o cache, em 1999, quando Bruce Momjiam escreveu:
[...] é possível que sejamos _muito_ populares em um futuro próximo.
A base para implementar o balanceamento de carga no PostgreSQL é fornecida pelo recurso Hot Standby integrado. O único requisito é que o aplicativo lide com o failover e é aí que entram as soluções de terceiros. Veremos algumas dessas soluções nas próximas seções.
Consultas com balanceamento de carga só podem retornar resultados consistentes desde que o atraso da replicação síncrona seja mantido baixo. Na prática, mesmo a infraestrutura de rede de última geração, como a AWS, pode apresentar atrasos de dezenas de milissegundos:
Normalmente, observamos tempos de atraso na ordem de 10 milissegundos. [...] No entanto, em condições típicas, é comum um atraso de um minuto na replicação. [...]
As réplicas entre regiões usando replicação lógica serão influenciadas pela taxa de alteração/aplicação e atrasos na comunicação de rede entre as regiões específicas selecionadas. As réplicas entre regiões que usam o Aurora Global Database terão um atraso típico de menos de um segundo.
Como dito anteriormente, as soluções de terceiros contam com os principais recursos do PostgreSQL. Por exemplo, o balanceamento de carga de consultas de leitura é obtido usando várias esperas síncronas.
Soluções
pgpool-II
pgpool-II é um produto rico em recursos que fornece balanceamento de carga e cache de consulta na memória. É uma substituição imediata, não são necessárias alterações no lado da aplicação.
Como balanceador de carga, o pgpool-II examina cada consulta SQL — para ter balanceamento de carga, as consultas SELECT devem atender a várias condições.
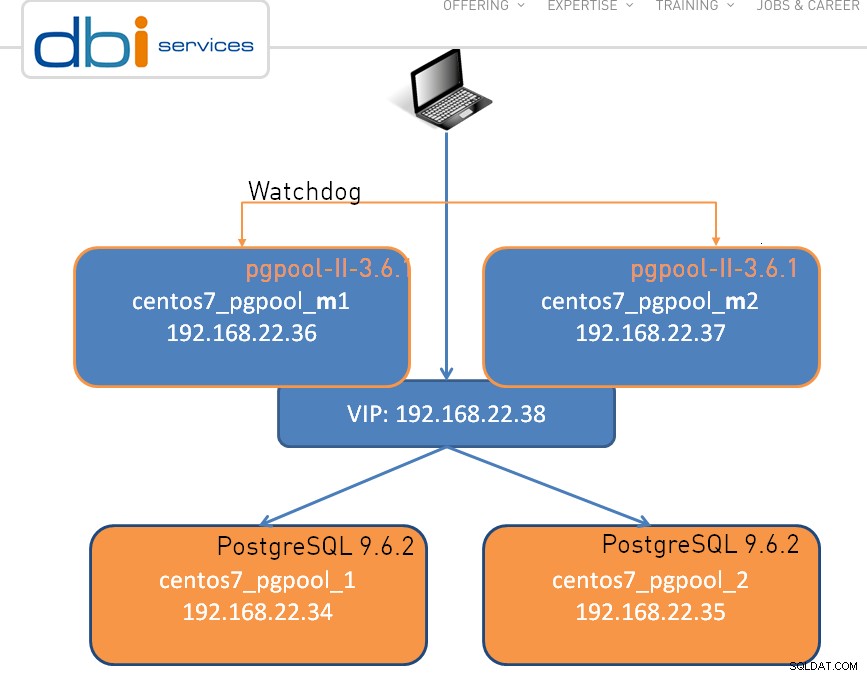
A configuração pode ser tão simples quanto um nó, mostrado abaixo é um cluster de nó duplo:
Como é o caso de qualquer grande software, existem algumas limitações , e o pgpool-II não faz exceção:
- Ele não lida com consultas de várias instruções.
- Consultas SELECT em tabelas temporárias requerem o comentário /*NO LOAD BALANCE*/ SQL.
Aplicativos executados em ambientes de alto desempenho se beneficiarão de uma configuração mista em que o pgBouncer é o pooler de conexões e o pgpool-II trata do balanceamento de carga e do armazenamento em cache. O resultado é um aumento impressionante de 4 vezes na taxa de transferência e uma redução de 40% na latência:
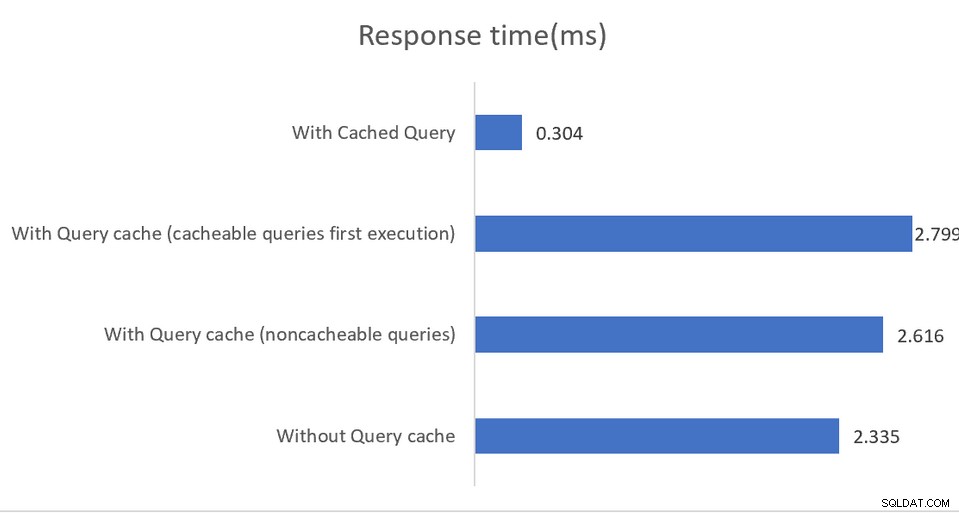
O cache na memória funciona, novamente, apenas em consultas de leitura, com cache dados sendo salvos na memória compartilhada ou em uma instalação externa do memcached. Embora a documentação seja muito boa em explicar as várias opções de configuração, ela indiretamente sugere que as implementações devem monitorar a saída SHOW POOL CACHE para alertar sobre taxas de acerto abaixo da marca de 70%, ponto em que o ganho de desempenho fornecido pelo cache é perdido.
Bucardo
Bucardo é uma ferramenta de replicação do PostgreSQL escrita em Perl e PL/Perl.
Eu mencionei o Bucardo, porque o balanceamento de carga é uma de suas características, de acordo com o wiki do PostgreSQL, no entanto, uma pesquisa na internet não apresenta resultados relevantes. Para esclarecer, fui até a documentação oficial que detalha como o software realmente funciona:

Isso deixa bem claro, Bucardo não é um balanceador de carga, assim como foi apontado pelo pessoal da Database Soup.
HAProxy
HAProxy é um balanceador de carga de uso geral que opera no nível TCP (para fins de conexões de banco de dados). As verificações de integridade garantem que as consultas sejam enviadas apenas para nós ativos.
Em comparação com o pgpool-II, os aplicativos que usam o HAProxy como balanceador de carga devem estar cientes das solicitações de despacho do endpoint para os nós do leitor.
Apache Ignite
Apache Ignite é um cache de segundo nível que entende SQL ANSI-99 e fornece suporte para transações ACID. O Apache Ignite não entende o PostgreSQL Frontend/Backend Protocol e, portanto, os aplicativos devem usar uma camada de persistência, como o Hibernate ORM. Como uma alternativa para modificar aplicativos, o Apache Ignite fornece `integração com memcached`_ que requer a extensão memcached do PostgreSQL. Infelizmente, esta última opção não é compatível com versões recentes do PostgreSQL, pois a extensão pgmemcache foi atualizada pela última vez em 2017.
Dados de Heimdall
Como um produto comercial, o Heimdall Data marca ambas as caixas:balanceamento de carga e armazenamento em cache. É um produto maduro, tendo sido apresentado em conferências do PostgreSQL desde o PGCon 2017:

Mais detalhes e uma demonstração do produto podem ser encontrados no blog Azure for PostgreSQL .
Conclusão
Na computação distribuída de hoje, o Query Caching e o Load Balancing são tão importantes para o ajuste de desempenho do PostgreSQL quanto os conhecidos GUCs, kernel do SO, armazenamento e otimização de consultas. Embora o pgpool-II e o Heimdall Data sejam o código aberto e, respectivamente, as soluções comerciais preferidas, há casos em que ferramentas feitas propositalmente podem ser usadas como blocos de construção para obter resultados semelhantes.