Azure SQL Database é a oferta de banco de dados como serviço da Microsoft que oferece uma enorme flexibilidade. Ele é construído como parte do ambiente de plataforma como serviço que fornece aos clientes monitoramento e segurança adicionais para o produto.
Azure SQL Database é a oferta de banco de dados como serviço da Microsoft que oferece uma enorme flexibilidade. Ele é construído como parte do ambiente de plataforma como serviço que fornece aos clientes monitoramento e segurança adicionais para o produto. A Microsoft está trabalhando continuamente para melhorar seus produtos e o Banco de Dados SQL do Azure não é diferente. Muitos dos recursos mais recentes que temos no SQL Server foram lançados inicialmente no Banco de Dados SQL do Azure, incluindo (mas não limitado a) Always Encrypted, Dynamic Data Masking, Row Level Security e Query Store.
Nível de preços de DTU
Quando o Banco de Dados SQL do Azure foi lançado pela primeira vez, havia uma única opção de preço conhecida como “DTUs” ou Unidades de Transação de Banco de Dados. (Andy Mallon, @AMtwo, explica DTUs em "O que diabos é uma DTU?") O modelo DTU oferece três níveis de serviço, básico, padrão e premium. A camada básica fornece até 5 DTUs com armazenamento padrão. A camada padrão oferece suporte de 10 a 3.000 DTUs com armazenamento padrão e a camada premium oferece suporte de 125 a 4.000 DTUs com armazenamento premium, que é muito mais rápido que o armazenamento padrão.
Nível de preços vCore
Avance alguns anos após o lançamento do Banco de Dados SQL do Azure para quando a Instância Gerenciada do SQL do Azure estava em visualização pública e os “vCores” (núcleos virtuais) foram anunciados para o Banco de Dados SQL do Azure. Eles introduziram os níveis de uso geral e de negócios críticos com processadores Gen 4 e Gen 5. A geração 5 é a principal opção de hardware agora para a maioria das regiões, já que a geração 4 está envelhecendo.
A geração 5 suporta apenas 2 vCores e até 80 vCores com ram sendo alocada a 5,1 GB por vCore. A camada de uso geral fornece armazenamento remoto com IOPS máximo de dados variando de 640 para um banco de dados de 2 vCore até 25.600 para um banco de dados de 80 vCore. A camada crítica para os negócios tem SSD local que oferece desempenho de E/S muito melhor com IOPS de dados máximos variando de 8.000 para um banco de dados de 2 vCore até 204.800 para um banco de dados de 80 vCore. Os níveis de uso geral e de negócios críticos atingem o máximo de 4.096 GB para armazenamento, e isso se tornou uma limitação para muitos clientes.
Banco de dados HyperScale
Para resolver o limite de 4 TB do Banco de Dados SQL do Azure, a Microsoft criou a camada de hiperescala. A hiperescala permite que os clientes escalem até 100 TB de tamanho de banco de dados, além de fornecer escalabilidade horizontal rápida para nós somente leitura. Você também pode escalar para cima e para baixo facilmente no modelo vCore. Os bancos de dados de hiperescala são provisionados usando vCores. Com a Geração 5, um banco de dados Hyperscale pode usar entre 2 a 80 vCores e 500 a 204.800 IOPS. A hiperescala alcança alto desempenho de cada nó de computação com caches baseados em SSD, o que ajuda a minimizar as viagens de ida e volta da rede para buscar dados. Há muita tecnologia incrível envolvida com o Hyperscale em como ele é arquitetado para usar caches baseados em SSD e servidores de página. Eu recomendo que você dê uma olhada no diagrama que detalha a arquitetura e como tudo funciona neste artigo.
Banco de dados sem servidor
Outra solicitação muito comum dos clientes foi a capacidade de aumentar e diminuir automaticamente o Banco de Dados SQL do Azure à medida que as cargas de trabalho aumentam e diminuem. Tradicionalmente, os clientes têm a capacidade de aumentar e diminuir programaticamente usando o PowerShell, a Automação do Azure e outros métodos. A Microsoft pegou essa ideia e criou uma nova camada de computação chamada Azure SQL Database serverless, que ficou disponível em novembro de 2019. Eles permitem que o cliente defina números mínimos e máximos de vCores. Dessa forma, eles podem saber que sempre há um nível mínimo de computação disponível e sempre podem escalar automaticamente para um nível de computação designado. Há também a capacidade de configurar um atraso de pausa automática. Essa configuração permite pausar automaticamente o banco de dados após um período específico de inatividade do banco de dados. Quando um banco de dados entra no estágio de pausa automática, os custos de computação vão para zero e apenas os custos de armazenamento são incorridos. O custo geral do serverless é a soma do custo de computação e custo de armazenamento. Quando o uso de computação está entre os limites mínimo e máximo, o custo de computação é baseado em vCores e memória usada. Se o uso real estiver abaixo do valor mínimo, o custo de computação será baseado nos vCores mínimos e na memória mínima configurada.
A camada sem servidor tem o potencial de economizar muito dinheiro aos clientes, ao mesmo tempo em que oferece a eles a capacidade de fornecer uma experiência de usuário de banco de dados consistente, com o banco de dados sendo capaz de escalar conforme a demanda exigir.
Piscinas elásticas
O Banco de Dados SQL do Azure tem um modelo de recurso compartilhado que permite que os clientes tenham uma maior utilização de recursos. Um cliente pode criar um pool elástico e mover bancos de dados para esse pool. Cada banco de dados pode então começar a compartilhar recursos predefinidos dentro desse pool. Os pools elásticos podem ser configurados usando o modelo de preços DTU ou o modelo vCore. Os clientes determinam a quantidade de recursos que o pool elástico precisa para lidar com a carga de trabalho de todos os seus bancos de dados. Os limites de recursos podem ser configurados por banco de dados para que um banco de dados não possa consumir todo o pool. Os pools elásticos são ótimos para clientes que precisam gerenciar um grande número de bancos de dados ou cenários multilocatários.
Nova configuração de hardware para o nível de computação provisionado
As configurações de hardware Gen4/Gen5 são consideradas "memória e computação balanceadas". Isso funciona bem para muitas cargas de trabalho do SQL Server, no entanto, houve casos de uso para uma latência de CPU mais baixa e uma velocidade de clock mais alta para cargas de trabalho com CPU pesada e uma necessidade de mais memória por vCore. A Microsoft mais uma vez entregou e criou uma configuração de hardware otimizada para computação e memória otimizada. No momento, eles estão em visualização e estão disponíveis apenas em determinadas regiões.
Na camada provisionada de uso geral, você pode selecionar a série Fsv2, que pode oferecer mais desempenho de CPU por vCore do que o hardware Gen 5. No geral, o tamanho de 72 vCore pode fornecer mais desempenho de CPU do que o de 80 vCore Gen 5, fornecendo uma latência de CPU menor e velocidades de clock mais altas. A série Fsv2 tem menos memória e tempdb por vCore do que Gen 5, então isso terá que ser levado em consideração.
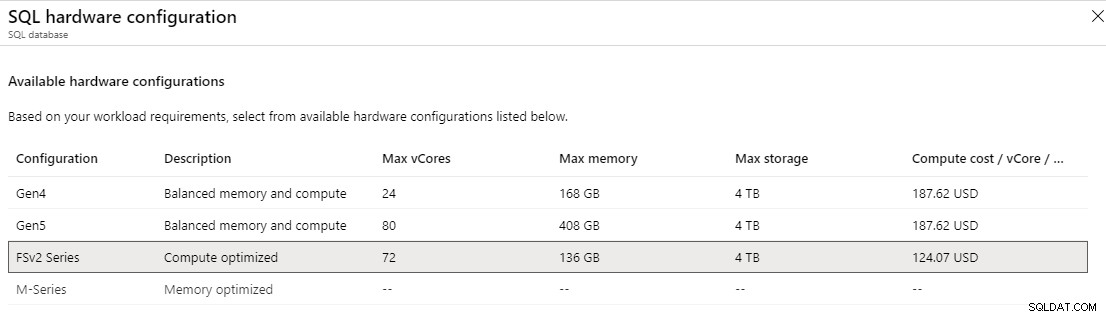
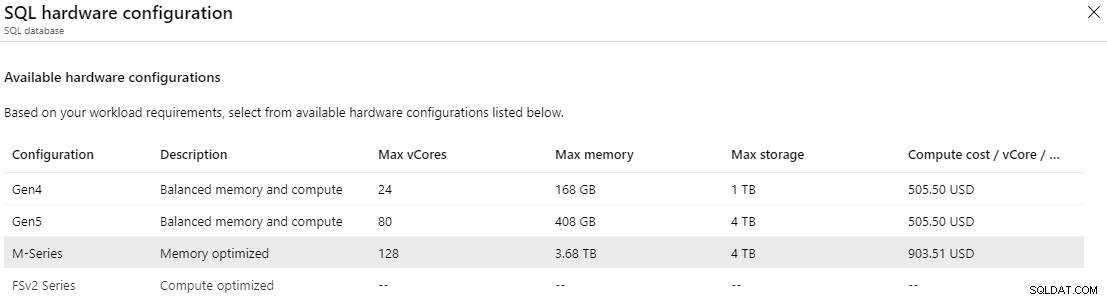
Na camada provisionada crítica para os negócios, você pode acessar a série M, que é otimizada para memória. A série M oferece 29 GB por vCore em comparação com os 5,1 GB por vCore na configuração "balance memory and compute". Com a série M, você pode dimensionar o vCore até 128, o que forneceria até 3,7 TB de memória. Para habilitar a série M, você deve estar atualmente em um Pay-As-You-Go ou Enterprise Agreement e abrir uma solicitação de suporte. Mesmo assim, a M-Series está atualmente disponível apenas no leste dos EUA, norte da Europa, oeste da Europa, oeste dos EUA 2 e também pode ter disponibilidade limitada em regiões adicionais.
Conclusão
O Banco de Dados SQL do Azure é uma plataforma de banco de dados rica em recursos que oferece uma ampla variedade de opções para computação e dimensionamento. Os clientes podem configurar a computação para um único banco de dados ou pool elástico usando DTUs ou vCores. Para bancos de dados com um grande requisito de armazenamento ou expansão de leitura, a hiperescala pode ser utilizada. Para clientes com requisitos de carga de trabalho variados, o serverless pode ser usado para aumentar e diminuir automaticamente conforme as demandas de carga de trabalho mudam. Uma novidade no Banco de Dados SQL do Azure é o recurso de visualização de uma configuração de hardware otimizada para computação e memória otimizada para os clientes que precisam de CPU de menor latência ou aqueles com alta memória para requisitos de CPU.
Para saber mais sobre os recursos do Azure, confira meus artigos anteriores:
- Opções de ajuste de desempenho do banco de dados SQL do Azure
- Considerações sobre o desempenho da instância gerenciada do SQL do Azure
- Novos tamanhos de camada padrão do banco de dados SQL do Azure
- Preenchendo a lacuna do Azure:instâncias gerenciadas
- Migrando Bancos de Dados para o Banco de Dados SQL do Azure