Não importa em que lado da equação você esteja, às vezes é difícil encontrar uma pessoa qualificada para um trabalho específico. Neste post, analisamos um modelo de dados para ajudar os recrutadores e os departamentos de RH a se manterem organizados durante o processo de contratação.
A maioria de nós esteve envolvida no processo de contratação – na maioria das vezes como candidato a emprego. No entanto, também podemos nos envolver no lado da contratação, talvez testando o conhecimento técnico do candidato. O processo de recrutamento leva um certo tempo, e o grupo de candidatos diminui continuamente à medida que nos aproximamos da decisão final. O resultado deve ser a seleção da melhor pessoa para o trabalho.
O recrutamento em si é bastante complicado, então discutiremos um modelo de dados bastante abrangente para cobrir todos os aspectos do processo. Sente-se em sua cadeira e aproveite o artigo de hoje!
Como funciona o processo de recrutamento
A maioria das partes do processo de recrutamento é de conhecimento comum, mas discutiremos exatamente como funciona antes de passarmos para o modelo de dados.
-
Detectando uma necessidade
Esta é uma necessidade absoluta no processo de recrutamento; não haverá processo se a gestão não estiver ciente da necessidade de contratar um novo funcionário. Essa necessidade pode ser resultado do início de uma nova empresa, do crescimento de uma empresa existente ou da saída de um funcionário atual.
A menos que uma empresa tenha cargos estritamente definidos (por exemplo, bancos), nem sempre é fácil determinar quando contratar um novo funcionário. Conversar com os funcionários e ver muitas horas extras pode estimular uma nova contratação. Os regulamentos internos ou externos também podem exigir que determinados cargos sejam concedidos apenas a pessoas com um conjunto de habilidades específico e experiência de trabalho relevante (por exemplo, revisor interno).
-
Descrevendo o cargo e suas habilidades necessárias
Para ter uma ideia dessa etapa, pense em uma descrição de trabalho muito bem escrita. Contém:
- Uma lista de todas as tarefas relacionadas ao trabalho
- Qualificações mínimas de experiência profissional e educacional
- Habilidades específicas essenciais para funções de trabalho
- Habilidades adicionais ou preferenciais
- Um resumo do que o empregador espera do candidato e o que o candidato pode esperar deste trabalho
- Uma faixa salarial e talvez um pacote de benefícios
Esta informação é importante para recrutadores e candidatos. De nada adianta convidar dez candidatos para o processo seletivo se nenhum deles ficar satisfeito com a oferta financeira. E quanto mais detalhada a descrição do trabalho, mais fácil será atrair candidatos qualificados.
-
Definir quem vai gerenciar o processo e quando cada tarefa deve acontecer
O próximo passo é definir datas específicas em que cada parte do processo acontecerá. Além disso, as empresas podem atribuir funcionários a cada etapa. Se a empresa tiver um departamento de Recursos Humanos, provavelmente ele gerenciará cada parte do processo de recrutamento, embora outros funcionários possam contribuir com seus conhecimentos específicos quando necessário (por exemplo, se estivermos contratando um especialista em TI, o gerente do departamento de TI deve avaliar os candidatos ' habilidades técnicas).
Se não houver um departamento de RH, podemos esperar que o pessoal da administração seja responsável pelo processo. Nas pequenas e médias empresas, isso não é apenas necessário, é desejável.
-
Postagem da vaga
Agora estamos prontos para publicar uma descrição do trabalho em nosso site, em quadros de empregos ou agregadores, ou em um jornal. A postagem de trabalho deve conter os pontos listados na Etapa 2. Isso ajudará os candidatos em potencial a decidir se desejam se candidatar ao cargo. É essencial tornar a descrição do trabalho precisa; todos nós perdemos nosso tempo em entrevistas para um trabalho que não correspondia à sua descrição ou às nossas expectativas.
-
Selecionar, testar e entrevistar candidatos
Após o término do período de inscrição, os candidatos com o conjunto de habilidades e experiência mais relevantes serão convidados para uma fase de avaliação inicial (geralmente uma entrevista ou teste). Os demais candidatos serão informados de que não foram selecionados para a vaga. Uma grande empresa deve convidar um número mínimo predefinido de candidatos para a avaliação inicial. Isso economiza tempo para os candidatos e para a empresa.
As pequenas e médias empresas podem decidir continuar o processo até encontrar o melhor ajuste. Nesses casos, o período de inscrição permanecerá aberto até que o candidato certo seja encontrado e todas as outras datas serão definidas ao longo do caminho.
O processo de entrevista e teste varia de acordo com o tamanho e a organização da empresa. Em grandes empresas com departamentos de RH, provavelmente haverá um conjunto de testes para verificar as habilidades profissionais dos candidatos. Outros testes podem medir traços psicológicos e de personalidade para determinar a correspondência candidato-emprego, correspondência candidato-empresa ou até mesmo a sanidade do candidato. ☺
Esses testes geralmente serão divididos em várias etapas, e cada etapa reduzirá o número de candidatos.
-
A entrevista final
Esta etapa provavelmente será uma entrevista com alguns dos principais candidatos. É a etapa mais importante do processo, porque os candidatos podem falar por si mesmos, demonstrar sua competência e personalidade e determinar se a empresa e o cargo serão adequados para eles. Após esta etapa, o melhor candidato receberá uma oferta. Se aceitarem, o processo de recrutamento para essa posição está encerrado. Se o candidato recusar a oferta de emprego, a empresa fará uma oferta para sua próxima escolha.
-
Existem diferenças no processo de recrutamento para pequenas, médias e grandes empresas? Como vamos resolvê-los em nosso modelo?
Haverá certas diferenças nos processos de recrutamento de pequenas, médias e grandes empresas. Além disso, o processo varia de acordo com as posições que estão sendo recrutadas. Pense em quão diferentes são as habilidades e experiências necessárias para um gerente de conteúdo, um ornitólogo e um capitão de navio de cruzeiro. Alguns trabalhos terão mais testes e entrevistas, outros podem ter apenas alguns. Mas, no final, tudo se resume a obter as respostas certas e classificar os candidatos.
Neste modelo, tratarei todos os testes e entrevistas da mesma maneira. Armazenaremos as respostas de cada candidato, relacionaremos com a pergunta relevante e armazenaremos a pontuação do candidato para cada etapa do processo.
-
Quem pode usar este modelo de dados?
Este modelo é muito específico e deve ser utilizado apenas para o processo de recrutamento. Mas não se limita aos departamentos de RH; você também pode usar esse modelo para executar um serviço de recrutamento profissional.
-
O modelo de dados
O modelo de dados consiste em cinco áreas principais:
JobsApplicants, Recruiters and DocumentsApplicationsTest detailsApplication tests
Descreverei cada área de assunto separadamente, na mesma ordem em que estão listadas.
Seção 1:Trabalhos
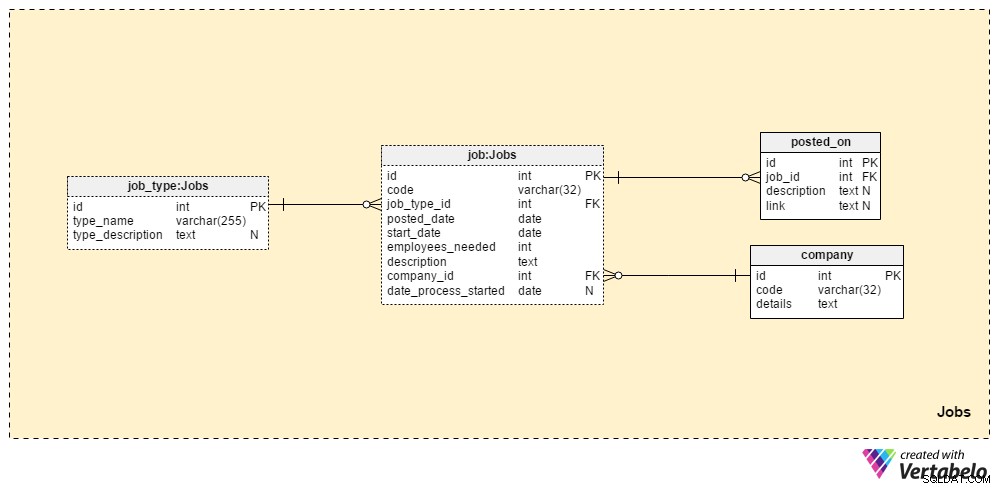
Os Jobs seção irá armazenar todos os detalhes para todas as posições que já postamos. As duas tabelas de dicionário, a company tabela e o job_type table, fazem parte da configuração inicial. As duas tabelas restantes, job e posted_on , contêm dados “reais” relacionados com anúncios de emprego.
O job_type dicionário contém uma lista de tipos de trabalho diferentes e ÚNICOS. Podemos esperar valores como “administrador de banco de dados sênior” ou “jornalista de TI” para ser armazenado no type_name atributo. O type_description O atributo pode armazenar uma descrição mais detalhada do trabalho.
A company dicionário contém uma lista de todas as empresas com as quais trabalhamos. Se contratarmos funcionários apenas para nossa empresa, este dicionário conterá apenas o nome da nossa empresa. Se formos uma agência de recrutamento, ela armazenará os nomes de todas as empresas que nos contrataram.
Uma lista de todos os cargos que já publicamos é armazenada na tabela “job”. Os atributos nesta tabela são:
code– Nosso ID ÚNICO interno usado para denotar um trabalho.job_type_id– Refere-se ao tipo de trabalho relacionado.posted_date– A data em que este cargo foi publicado.start_date– A data de início prevista (primeiro dia útil) para esse trabalho.employees_needed– O número de funcionários que queremos contratar durante este processo de recrutamento. Principalmente isso terá um valor de "1", mas em alguns casos - por exemplo ao iniciar uma nova empresa ou estabelecer um novo departamento – podemos esperar valores maiores.description– Uma descrição detalhada dessa posição. Este é o local onde listaremos todas as habilidades profissionais necessárias, preferidas e desejadas.company_id– Referencia o ID da empresa que nos contratou. Se formos uma agência de recrutamento, isso se referirá a um nome comercial armazenado nacompanytabela. Caso contrário, será o ID da nossa própria empresa.date_process_started– A data de início do processo de recrutamento. Isso pode ser NULL se precisarmos definir etapas e ações futuras em relação a este trabalho.
A última tabela nesta área de assunto é a
posted_on tabela. Para cada job_id , armazenaremos um link ao post de trabalho e à description relacionada . Poderíamos usar esses dados para saber onde os candidatos encontram nossos postos de trabalho. Seção 2:Candidatos, Recrutadores e Documentos
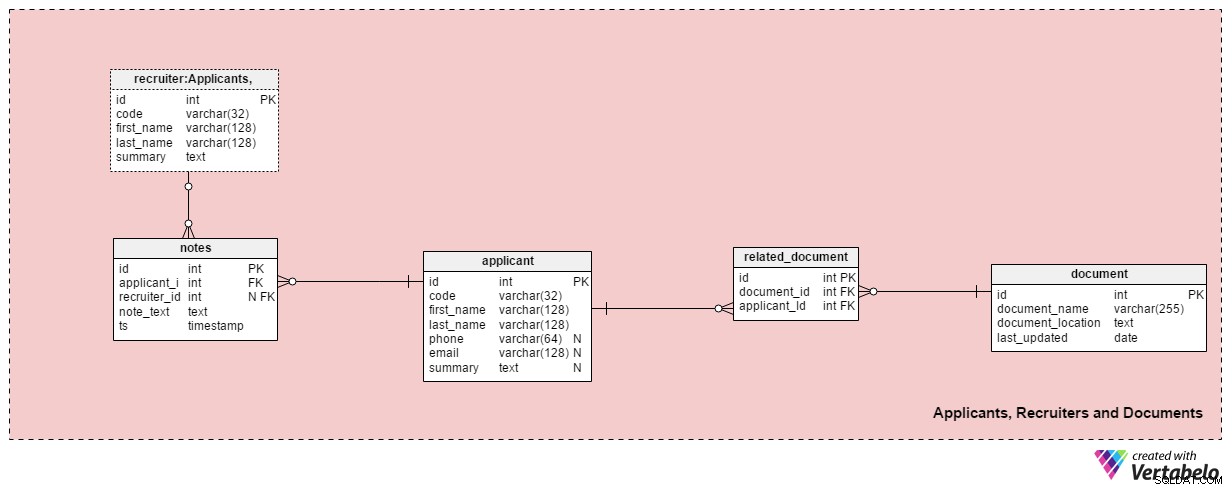
Esta área de assunto contém todas as tabelas necessárias para armazenar informações sobre recrutadores, candidatos e seus documentos relacionados.
O applicant tabela lista todos os candidatos com quem já tivemos contato. Cada candidato é definido EXCLUSIVAMENTE em nosso sistema com um “código”. Além disso, armazenaremos o nome e sobrenome de cada candidato, phone número, email endereço e seu summary . Esta tabela pode ser ajustada para necessidades específicas, por ex. adicionar números de telefone, e-mails ou endereços físicos adicionais.
Relacionaremos os candidatos com os documentos disponíveis. Uma lista de todos os documentos disponíveis (CV ou currículo, diplomas ou diplomas, históricos escolares, certificações etc.) é armazenada no document tabela. Para cada documento, armazenaremos seu nome no sistema, sua localização e a hora da atualização mais recente.
Relacionaremos os candidatos com documentos usando o related_document tabela. Ele contém apenas duas chaves estrangeiras, que formam o document_id – applicant_id Par ÚNICO.
O recruiter A tabela lista os funcionários que podem ser atribuídos a uma solicitação de emprego ou que inserem notas relacionadas a um candidato. Cada recrutador é definido EXCLUSIVAMENTE por seu code . Armazenaremos apenas detalhes básicos como first_name , last_name e o summary do recrutador .
A última tabela nesta área de assunto são as notes tabela. É aqui que armazenaremos todas as notas relacionadas a um candidato. Poderíamos armazenar notas como “O candidato perdeu a reunião” ou “O candidato se saiu muito bem na primeira entrevista” . Para cada nota, armazenaremos o ID do recrutador que fez a nota, o ID do candidato relacionado, o note_text e o carimbo de data/hora em que a nota foi criada.
Seção 3:detalhes do teste
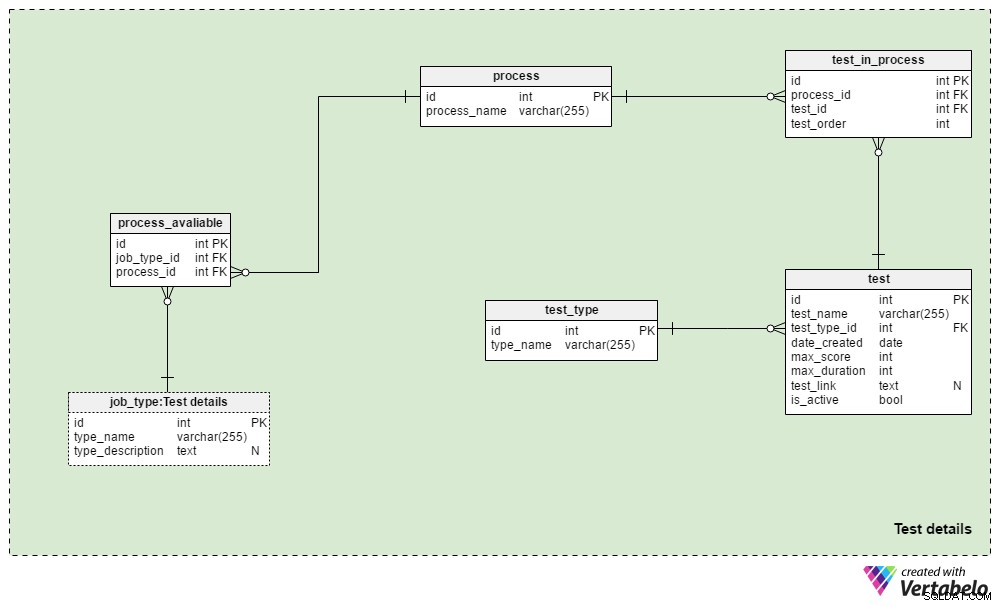
Os Test details área de assunto contém as tabelas utilizadas para definir os processos de recrutamento e os testes utilizados durante esses processos. Geralmente, sempre usaremos o mesmo processo de seleção para o mesmo tipo de trabalho:as alterações são feitas apenas quando exigidas pelas circunstâncias de negócios. Poderíamos usar alguns processos diferentes para cada tipo de trabalho e quase certamente usaremos o mesmo processo para diferentes tipos de trabalho.
O process table é um dicionário simples contendo apenas um process_name ÚNICO atributo. Ele lista todos os processos de recrutamento que já usamos e estamos usando atualmente.
Relacionaremos processos com diferentes tipos de trabalho. Armazenaremos essas relações no process_available tabela. Seus únicos atributos são o par UNIQUE job_type_id – process_id . Quando há vários processos disponíveis para um tipo de trabalho, isso permite que o recrutador escolha um.
O test_in_process tabela é usada para definir a ordem dos testes durante esse processo. Os atributos nesta tabela são:
process_idetest_id– Refere-se ao processo e teste relacionados.test_order– O número ordinal desse teste ou etapa do processo. Junto comprocess_id, isso forma a chave UNIQUE da tabela. Podemos ter apenas uma etapa de cada vez durante o processo.
O
test tabela lista todos os testes usados atualmente e anteriormente no processo de recrutamento. Também trataremos as revisões de currículos e entrevistas como testes. Embora não precisem de perguntas e respostas definidas, fazem parte de uma avaliação. Para cada teste, armazenaremos:test_name– Uma designação ÚNICA para cada teste.test_type_id– Refere-se aotest_typedicionário.date_created– A data em que criamos este teste em nosso sistema.max_score– A pontuação máxima alcançável para este teste. Esse valor é a soma de todas as respostas corretas neste teste ou a nota mais alta que os recrutadores podem dar a um currículo ou entrevista.max_duration– Quanto tempo (em minutos) o candidato tem para completar o teste.test_link– Contém um link para o local do teste. Esse valor pode ser NULL quando não usamos um teste no processo.is_active– Indica se atualmente usamos este teste.
Já mencionamos o
test_type dicionário. Ele contém todos os nomes de teste UNIQUE por formato, por exemplo, “Revisão de currículo” , “teste de habilidade online” , "teste de habilidade em papel" e “entrevista” . Este modelo não inclui a estrutura necessária para armazenar perguntas e respostas de teste. Em vez disso, ele armazena um link para os locais que contêm essas informações. O mesmo design será usado em
Applications área de estudo. Seção 4:inscrições
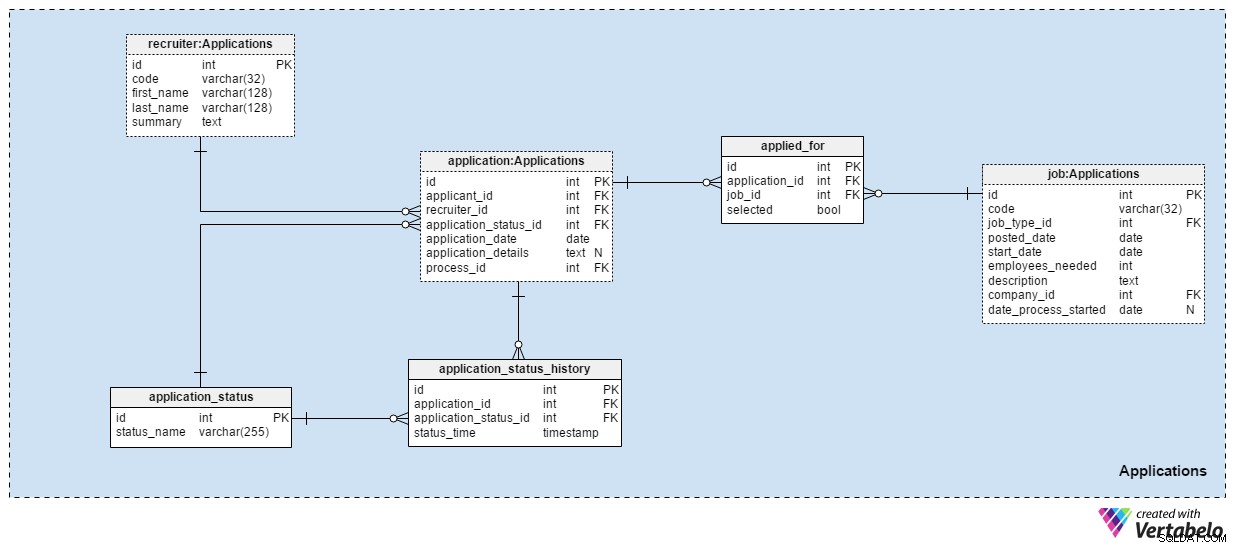
Os Applications área de assunto é provavelmente a mais importante neste modelo de dados. Todas as outras áreas temáticas mencionadas até agora descreveram aplicações. Este armazena as coisas reais.
Todos os aplicativos que recebemos estão registrados no application tabela. Para cada inscrição, armazenaremos o ID dos candidatos relacionados, o ID dos recrutadores e uma referência ao status atual dessa inscrição. Atualizaremos esse status ao mesmo tempo em que fizermos uma nova entrada no application_status_history tabela. O application_date O atributo é usado para armazenar a data relevante, enquanto todos os detalhes adicionais são armazenados em formato de texto. O process_id O atributo armazena uma referência ao processo selecionado para esse aplicativo.
Os aplicativos mudarão de status ao longo do tempo. Uma lista de todos os status do aplicativo é armazenada no application_status dicionário. O único atributo é status_name e só pode conter valores UNIQUE. Os valores esperados incluem:"aplicado" , "CV revisado" , "escolhido para o teste" , "rejeitado após revisão do CV" , "passou no teste" , "convidado para uma entrevista" e "rescindido pelo candidato" .
Armazenaremos todos os status de aplicativos no application_status_history tabela. Esta tabela contém referências ao application tabela e o application_status dicionário. Também armazenaremos o status_time exato quando esse status foi atribuído ao aplicativo. O application_id – status_time par forma a chave UNIQUE desta tabela.
Na maioria dos casos, um candidato se candidatará a apenas uma posição com uma inscrição. É possível que um candidato se candidate a mais de um cargo e escolheremos a função mais adequada para ele durante o processo de seleção. No applied_for tabela, armazenaremos o par UNIQUE application_id – job_id . Também registraremos se o candidato relacionado a essa inscrição foi selected para essa posição. Podemos esperar que todos os selected os valores serão definidos como “Falso” no início do processo de seleção e que atualizaremos apenas um por cada cargo para “Verdadeiro” .
Seção 5:Testes de aplicativos
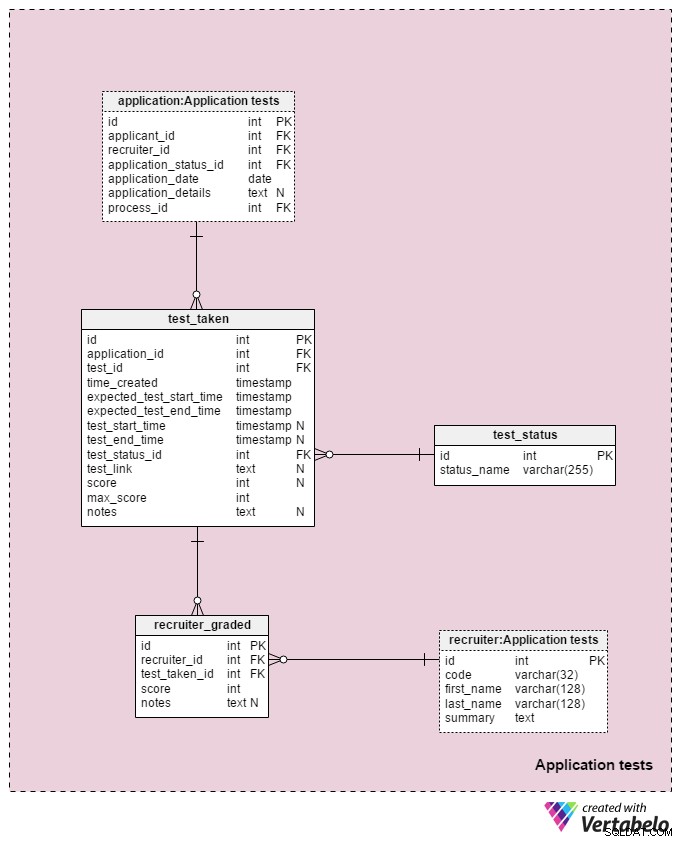
A última área do nosso modelo será usada para armazenar os resultados de cada teste realizado durante o processo de seleção. Duas tabelas usadas nesta área de assunto são cópias de outras áreas de assunto:application e recruiter . Eles são usados aqui para simplificar o modelo.
Todos os detalhes relacionados a cada teste são armazenados no test_taken tabela. Esta tabela também contém todas as outras etapas do processo que podem ser avaliadas, como uma revisão de currículo. Os atributos nesta tabela são:
application_id– Faz referência aoapplicationtabela. Isso relaciona um teste com o candidato que fez esse teste.test_id– Faz referência aotestCatálogo. Também podemos fazer referência aotest_in_processtabela aqui, que nos forneceria mais informações sobre o teste realizado. Decidi não porque essa estrutura nos dá mais flexibilidade. (Por exemplo, se quisermos permitir que os candidatos façam um teste duas vezes ou fora do horário normal).time_created– A hora real em que inserimos este teste em nosso sistema.expected_test_start_timeeexpected_test_end_time– Os horários de início e término, conforme discutido com o solicitante. Poderíamos alterar esses valores caso o candidato ou o recrutador precise adiar o teste.test_start_timeetest_end_time–As horas reais de início e término do teste. Eles conterão valores NULL quando o teste for criado; os valores serão atualizados quando o candidato iniciar e encerrar este teste.test_status_id– Refere-se aotest_statusdicionário.test_link– Links para o teste com as respostas do candidato. Ele será atualizado quando o candidato enviar o teste.score– A pontuação do candidato nesse teste. Isso é determinado manualmente por um recrutador (por exemplo, para uma revisão de currículo) ou automaticamente (a soma de todas as pontuações dos itens de teste). Também pode conter um valor NULL para testes que não são pontuados ou classificados em alguma escala predefinida. Além disso, um teste agendado, mas ainda não concluído, pode ter um valor NULL.max_score– A pontuação máxima alcançável do teste. Este é o mesmo que o valor armazenado notest.”max_scoreatributo. Quero manter esse valor porque o recrutador pode modificar o teste enquanto ele está sendo aplicado e, portanto, alterar a pontuação máxima que pode ser alcançada.notes– Quaisquer notas ou observações adicionais inseridas pelos recrutadores em relação a esse teste específico.
A combinação do
test_id – application_id – expected_test_start_time atributos formam a chave UNIQUE desta tabela. Antes de adicionar uma nova sessão de teste, ainda devemos verificar se há intervalos de teste sobrepostos para o candidato relacionado e todos os recrutadores relacionados. O
test_status dicionário contém uma lista de cada status_name ÚNICO que poderia ser atribuído a um teste. Alguns valores esperados incluem:"não iniciado" , "em andamento" , "concluído com sucesso" , "concluído sem sucesso" , "adiado" , "cancelado" e "candidato cancelado" . A última tabela em nosso modelo é a
recruiter_graded tabela, que armazena todas as notas que os recrutadores deram ao avaliar cada teste. Portanto, armazenaremos referências ao recruiter e test_taken mesas. Também armazenaremos a score alcançado, bem como quaisquer notes . Esta informação é muito importante, especialmente quando estamos avaliando testes manualmente (ou seja, para revisões de currículos e entrevistas). Hoje discutimos um modelo de dados que pode cobrir praticamente qualquer situação no processo de seleção e recrutamento – incluindo exceções incomuns.
A maioria de nós tem alguma experiência com este tópico. Por favor, compartilhe sua experiência enquanto estava na função de recrutador ou do outro lado da mesa. Este modelo cobre as situações que você enfrentou? Se não, que mudanças você proporia?



