Os parâmetros com valor de tabela existem desde o SQL Server 2008 e fornecem um mecanismo útil para enviar várias linhas de dados ao SQL Server, reunidas como uma única chamada parametrizada. Todas as linhas ficam disponíveis em uma variável de tabela que pode ser usada na codificação T-SQL padrão, o que elimina a necessidade de escrever uma lógica de processamento especializada para quebrar os dados novamente. Por sua própria definição, os parâmetros com valor de tabela são fortemente tipados para um tipo de tabela definido pelo usuário que deve existir dentro do banco de dados onde a chamada está sendo feita. No entanto, fortemente tipado não é estritamente “fortemente tipado” como você esperaria, como este artigo irá demonstrar, e o desempenho pode ser afetado como resultado.
Para demonstrar os possíveis impactos de desempenho de parâmetros com valor de tabela digitados incorretamente com o SQL Server, vamos criar um exemplo de tipo de tabela definido pelo usuário com a seguinte estrutura:
CREATE TYPE dbo.PharmacyData AS TABLE ( Dosage int, Drug varchar(20), FirstName varchar(50), LastName varchar(50), AddressLine1 varchar(250), PhoneNumber varchar(50), CellNumber varchar(50), EmailAddress varchar(100), FillDate datetime );
Em seguida, precisaremos de um aplicativo .NET que usará esse tipo de tabela definido pelo usuário como um parâmetro de entrada para passar dados para o SQL Server. Para usar um parâmetro com valor de tabela de nosso aplicativo, um objeto DataTable normalmente é preenchido e, em seguida, passado como o valor do parâmetro com um tipo de SqlDbType.Structured. A DataTable pode ser criada de várias maneiras no código .NET, mas uma maneira comum de criar a tabela é algo como o seguinte:
System.Data.DataTable DefaultTable = new System.Data.DataTable("@PharmacyData");
DefaultTable.Columns.Add("Dosage", typeof(int));
DefaultTable.Columns.Add("Drug", typeof(string));
DefaultTable.Columns.Add("FirstName", typeof(string));
DefaultTable.Columns.Add("LastName", typeof(string));
DefaultTable.Columns.Add("AddressLine1", typeof(string));
DefaultTable.Columns.Add("PhoneNumber", typeof(string));
DefaultTable.Columns.Add("CellNumber", typeof(string));
DefaultTable.Columns.Add("EmailAddress", typeof(string));
DefaultTable.Columns.Add("Date", typeof(DateTime)); Você também pode criar o DataTable usando a definição embutida da seguinte forma:
System.Data.DataTable DefaultTable = new System.Data.DataTable("@PharmacyData")
{
Columns =
{
{"Dosage", typeof(int)},
{"Drug", typeof(string)},
{"FirstName", typeof(string)},
{"LastName", typeof(string)},
{"AddressLine1", typeof(string)},
{"PhoneNumber", typeof(string)},
{"CellNumber", typeof(string)},
{"EmailAddress", typeof(string)},
{"Date", typeof(DateTime)},
},
Locale = CultureInfo.InvariantCulture
}; Qualquer uma dessas definições do objeto DataTable no .NET pode ser usada como um parâmetro com valor de tabela para o tipo de dados definido pelo usuário que foi criado, mas observe a definição de typeof(string) para as várias colunas de string; tudo isso pode ser "corretamente" tipado, mas na verdade não é fortemente tipado para os tipos de dados implementados no tipo de dados definido pelo usuário. Podemos preencher a tabela com dados aleatórios e passá-la para o SQL Server como um parâmetro para uma instrução SELECT muito simples que retornará exatamente as mesmas linhas da tabela que passamos, da seguinte maneira:
using (SqlCommand cmd = new SqlCommand("SELECT * FROM @tvp;", connection))
{
var pList = new SqlParameter("@tvp", SqlDbType.Structured);
pList.TypeName = "dbo.PharmacyData";
pList.Value = DefaultTable;
cmd.Parameters.Add(pList);
cmd.ExecuteReader().Dispose();
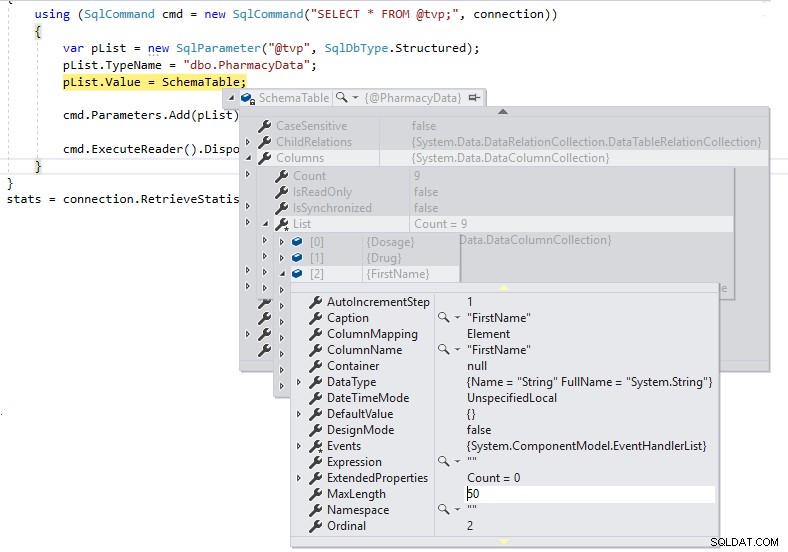
} Podemos então usar uma pausa de depuração para que possamos inspecionar a definição de DefaultTable durante a execução, conforme mostrado abaixo:
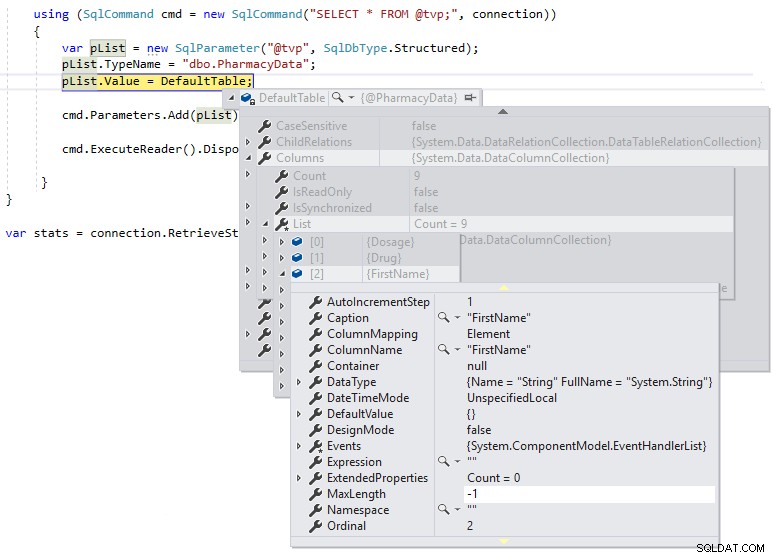
Podemos ver que o MaxLength para as colunas de string está definido em -1, o que significa que elas estão sendo passadas pelo TDS para o SQL Server como LOBs (Large Objects) ou essencialmente como colunas de tipo de dados MAX, e isso pode afetar o desempenho de maneira negativa. Se alterarmos a definição .NET DataTable para ser fortemente tipada para a definição de esquema do tipo de tabela definido pelo usuário da seguinte forma e observar o MaxLength da mesma coluna usando uma quebra de depuração:
System.Data.DataTable SchemaTable = new System.Data.DataTable("@PharmacyData")
{
Columns =
{
{new DataColumn() { ColumnName = "Dosage", DataType = typeof(int)} },
{new DataColumn() { ColumnName = "Drug", DataType = typeof(string), MaxLength = 20} },
{new DataColumn() { ColumnName = "FirstName", DataType = typeof(string), MaxLength = 50} },
{new DataColumn() { ColumnName = "LastName", DataType = typeof(string), MaxLength = 50} },
{new DataColumn() { ColumnName = "AddressLine1", DataType = typeof(string), MaxLength = 250} },
{new DataColumn() { ColumnName = "PhoneNumber", DataType = typeof(string), MaxLength = 50} },
{new DataColumn() { ColumnName = "CellNumber", DataType = typeof(string), MaxLength = 50} },
{new DataColumn() { ColumnName = "EmailAddress", DataType = typeof(string), MaxLength = 100} },
{new DataColumn() { ColumnName = "Date", DataType = typeof(DateTime)} },
},
Locale = CultureInfo.InvariantCulture
}; 
Agora temos comprimentos corretos para as definições de coluna e não as passaremos como LOBs sobre TDS para o SQL Server.
Como isso afeta o desempenho, você pode se perguntar? Ela afeta o número de buffers TDS que são enviados pela rede para o SQL Server e também afeta o tempo geral de processamento dos comandos.
Usar exatamente o mesmo conjunto de dados para as duas tabelas de dados e alavancar o método RetrieveStatistics no objeto SqlConnection nos permite obter as métricas estatísticas ExecutionTime e BuffersSent para as chamadas para o mesmo comando SELECT e apenas usar as duas definições de DataTable diferentes como parâmetros e chamar o método ResetStatistics do objeto SqlConnection permite que as estatísticas de execução sejam limpas entre os testes.
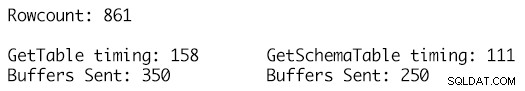
A definição de GetSchemaTable especifica o MaxLength para cada uma das colunas de string corretamente, onde GetTable apenas adiciona colunas do tipo string que têm um valor de MaxLength definido como -1, resultando em 100 buffers TDS adicionais sendo enviados para 861 linhas de dados na tabela e um tempo de execução de 158 milissegundos em comparação com apenas 250 buffers enviados para a definição de DataTable fortemente tipada e um tempo de execução de 111 milissegundos. Embora isso possa não parecer muito no grande esquema das coisas, esta é uma única chamada, execução única e o impacto acumulado ao longo do tempo para muitos milhares ou milhões de tais execuções é onde os benefícios começam a se somar e ter um impacto perceptível no desempenho e na taxa de transferência da carga de trabalho.
Onde isso realmente pode fazer a diferença é nas implementações de nuvem, onde você está pagando por mais do que apenas recursos de computação e armazenamento. Além de ter os custos fixos dos recursos de hardware para VM do Azure, Banco de Dados SQL ou AWS EC2 ou RDS, há um custo adicional para o tráfego de rede de e para a nuvem que é adicionado ao faturamento de cada mês. Reduzir os buffers que atravessam a rede reduzirá o TCO da solução ao longo do tempo, e as alterações de código necessárias para implementar essa economia são relativamente simples.