Eu escrevi anteriormente sobre a propriedade Real Rows Read. Ele informa quantas linhas são realmente lidas por um Index Seek, para que você possa ver o quão seletivo é o Seek Predicate, em comparação com a seletividade do Seek Predicate mais o Residual Predicate combinados.
Mas vamos dar uma olhada no que realmente está acontecendo dentro do operador Seek. Porque não estou convencido de que “Real Rows Read” seja necessariamente uma descrição precisa do que está acontecendo.
Quero ver um exemplo que consulta endereços de tipos de endereço específicos para um cliente, mas o princípio aqui se aplicaria facilmente a muitas outras situações se a forma de sua consulta se encaixar, como pesquisar atributos em uma tabela de pares de valores-chave, por exemplo.
SELECT AddressTypeID, FullAddress FROM dbo.Addresses WHERE CustomerID = 783 AND AddressTypeID IN (2,4,5);
Eu sei que não mostrei nada sobre os metadados – voltarei a isso em um minuto. Vamos pensar sobre essa consulta e que tipo de índice gostaríamos de ter para ela.
Em primeiro lugar, sabemos exatamente o CustomerID. Uma correspondência de igualdade como essa geralmente a torna uma excelente candidata para a primeira coluna em um índice. Se tivéssemos um índice nesta coluna, poderíamos mergulhar direto nos endereços desse cliente – então eu diria que é uma suposição segura.
A próxima coisa a considerar é esse filtro em AddressTypeID. Adicionar uma segunda coluna às chaves do nosso índice é perfeitamente razoável, então vamos fazer isso. Nosso índice agora está ativado (CustomerID, AddressTypeID). E vamos INCLUIR FullAddress também, para que não precisemos fazer nenhuma pesquisa para completar a imagem.
E acho que terminamos. Devemos ser capazes de assumir com segurança que o índice ideal para esta consulta é:
CREATE INDEX ixIdealIndex ON dbo.Addresses (CustomerID, AddressTypeID) INCLUDE (FullAddress);
Poderíamos declará-lo como um índice exclusivo – veremos o impacto disso mais tarde.
Então vamos criar uma tabela (estou usando tempdb, porque não preciso que ela persista além desta postagem no blog) e testar isso.
CREATE TABLE dbo.Addresses ( AddressID INT IDENTITY(1,1) PRIMARY KEY, CustomerID INT NOT NULL, AddressTypeID INT NOT NULL, FullAddress NVARCHAR(MAX) NOT NULL, SomeOtherColumn DATE NULL );
Não estou interessado em restrições de chave estrangeira ou em outras colunas que possam existir. Estou interessado apenas no meu Índice Ideal. Então crie isso também, se você ainda não o fez.
Meu plano parece muito perfeito.
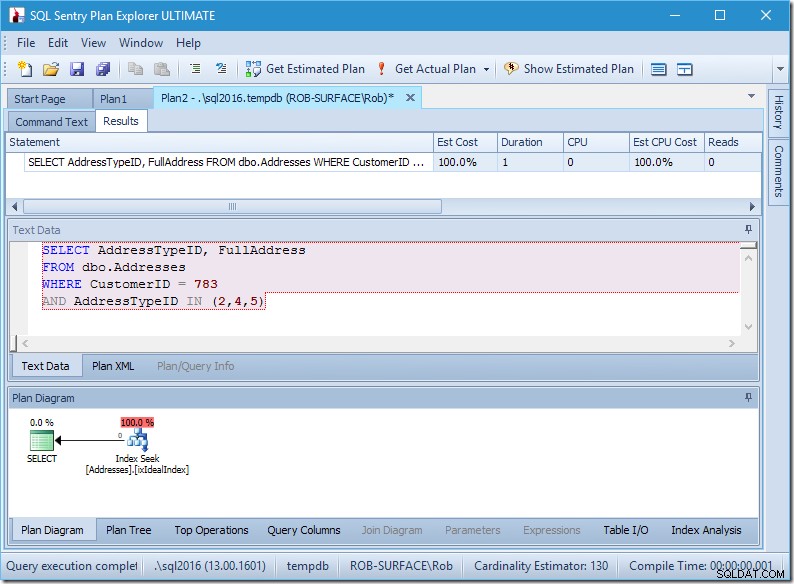
Eu tenho uma busca de índice, e é isso.
É verdade que não há dados, portanto, não há leituras, nem CPU, e também é executado rapidamente. Se ao menos todas as consultas pudessem ser ajustadas assim.
Vamos ver o que está acontecendo um pouco mais de perto, observando as propriedades do Seek.
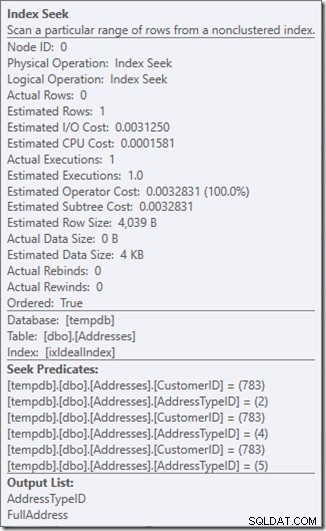
Podemos ver os Predicados de Busca. Tem seis. Três sobre o CustomerID e três sobre o AddressTypeID. O que realmente temos aqui são três conjuntos de predicados de busca, indicando três operações de busca dentro de um único operador de busca. A primeira busca está procurando pelo Cliente 783 e AddressType 2. A segunda está procurando por 783 e 4, e a última 783 e 5. Nosso operador Busca apareceu uma vez, mas havia três buscas acontecendo dentro dele.
Nós nem temos dados, mas podemos ver como nosso índice será usado.
Vamos colocar alguns dados fictícios, para que possamos analisar um pouco do impacto disso. Vou colocar endereços para os tipos 1 a 6. Todos os clientes (mais de 2.000, com base no tamanho de
master..spt_values ) terá um endereço do tipo 1. Talvez seja o endereço principal. Estou permitindo que 80% tenham um endereço tipo 2, 60% um tipo 3 e assim por diante, até 20% para o tipo 5. A linha 783 obterá endereços do tipo 1, 2, 3 e 4, mas não 5. Eu preferiria usar valores aleatórios, mas quero ter certeza de que estamos na mesma página para os exemplos. WITH nums AS (
SELECT row_number() OVER (ORDER BY (SELECT 1)) AS num
FROM master..spt_values
)
INSERT dbo.Addresses (CustomerID, AddressTypeID, FullAddress)
SELECT num AS CustomerID, 1 AS AddressTypeID, N'Some sample text for the address' AS FullAddress
FROM nums
UNION ALL
SELECT num AS CustomerID, 2 AS AddressTypeID, N'Some sample text for the address' AS FullAddress
FROM nums
WHERE num % 10 < 8
UNION ALL
SELECT num AS CustomerID, 3 AS AddressTypeID, N'Some sample text for the address' AS FullAddress
FROM nums
WHERE num % 10 < 6
UNION ALL
SELECT num AS CustomerID, 4 AS AddressTypeID, N'Some sample text for the address' AS FullAddress
FROM nums
WHERE num % 10 < 4
UNION ALL
SELECT num AS CustomerID, 5 AS AddressTypeID, N'Some sample text for the address' AS FullAddress
FROM nums
WHERE num % 10 < 2
; Agora vamos ver nossa consulta com dados. Duas fileiras estão saindo. É como antes, mas agora vemos as duas linhas saindo do operador Seek e vemos seis leituras (no canto superior direito).
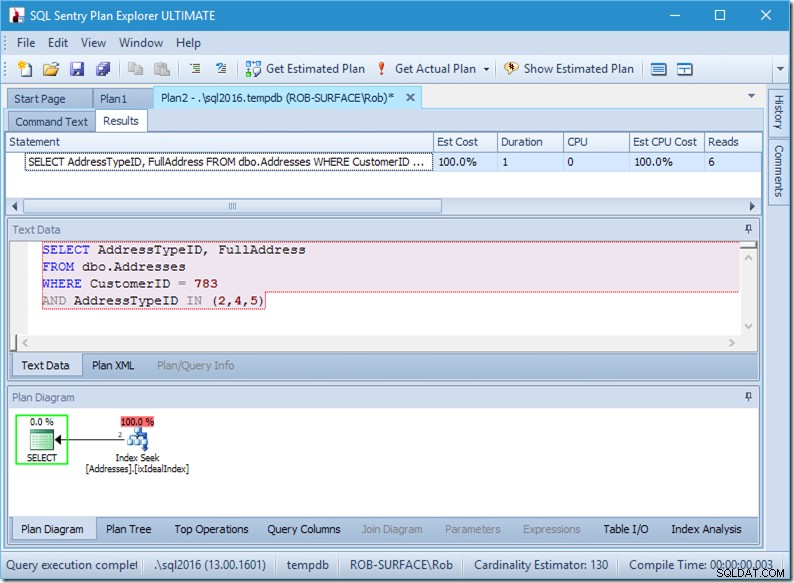
Seis leituras fazem sentido para mim. Temos uma pequena tabela e o índice se encaixa em apenas dois níveis. Estamos fazendo três buscas (dentro de nosso único operador), então o mecanismo está lendo a página raiz, descobrindo qual página descer e lendo isso, e fazendo isso três vezes.
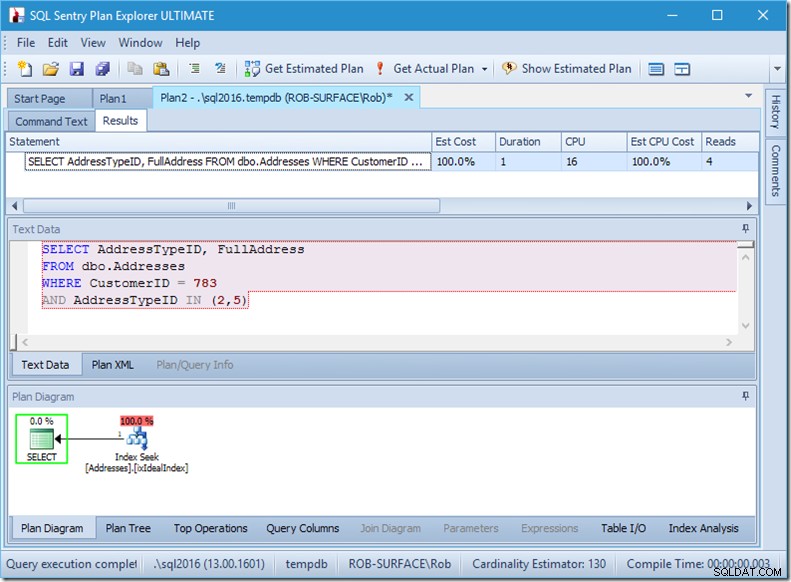
Se procurássemos apenas dois AddressTypeIDs, veríamos apenas 4 leituras (e, neste caso, uma única linha sendo emitida). Excelente.
E se estivéssemos procurando 8 tipos de endereço, veríamos 16.
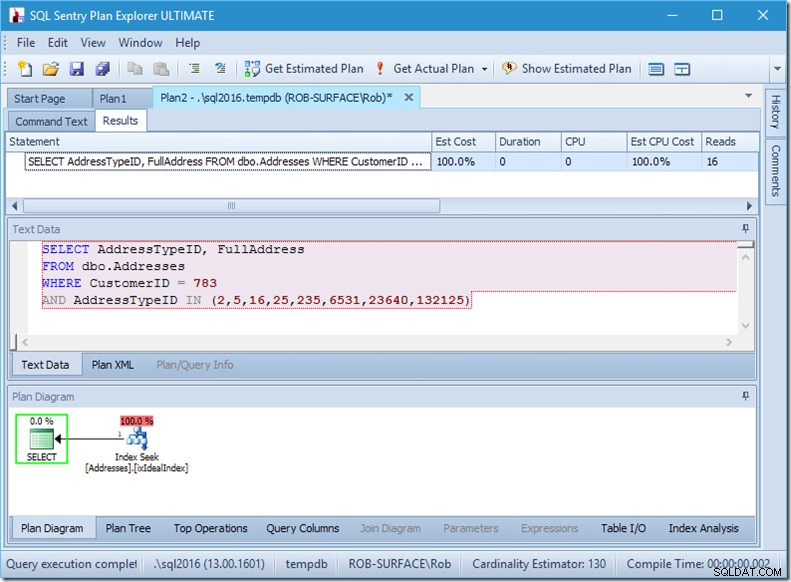
No entanto, cada um deles mostra que as linhas reais lidas correspondem exatamente às linhas reais. Nenhuma ineficiência!
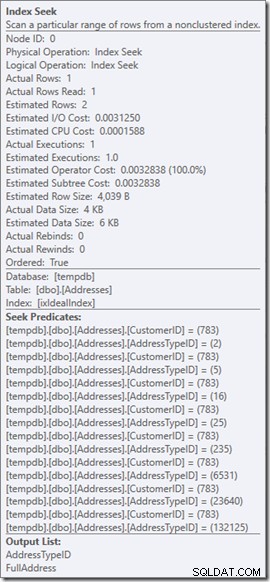
Vamos voltar à nossa consulta original, procurando os tipos de endereço 2, 4 e 5 (que retorna 2 linhas) e pensar no que está acontecendo dentro da busca.
Vou assumir que o Query Engine já fez o trabalho para descobrir que Index Seek é a operação correta e que tem o número da página da raiz do índice à mão.
Neste ponto, ele carrega essa página na memória, se ainda não estiver lá. Essa é a primeira leitura que é contada na execução da busca. Em seguida, localiza o número da página para a linha que está procurando e lê essa página. Essa é a segunda leitura.
Mas muitas vezes ignoramos esse bit "localiza o número da página".
Usando
DBCC IND(2, N'dbo.Address', 2); (o primeiro 2 é o id do banco de dados porque estou usando tempdb; o segundo 2 é o ID do índice de ixIdealIndex ), posso descobrir que o 712 no arquivo 1 é a página com o IndexLevel mais alto. Na captura de tela abaixo, posso ver que a página 668 é IndexLevel 0, que é a página raiz. 
Então agora eu posso usar
DBCC TRACEON(3604); DBCC PAGE (2,1,712,3); para ver o conteúdo da página 712. Na minha máquina, recebo 84 linhas voltando e posso dizer que CustomerID 783 estará na página 1004 do arquivo 5. 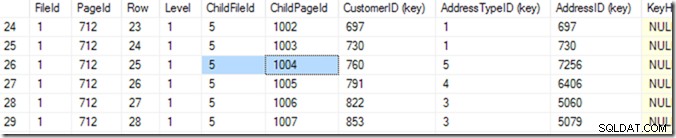
Mas eu sei disso percorrendo minha lista até ver o que eu quero. Comecei rolando um pouco para baixo e depois voltei, até encontrar a linha que queria. Um computador chama isso de busca binária, e é um pouco mais preciso do que eu. Ele está procurando a linha em que a combinação (CustomerID, AddressTypeID) é menor que a que estou procurando, com a próxima página sendo maior ou igual a ela. Digo “o mesmo” porque pode haver dois que combinem, espalhados por duas páginas. Ele sabe que há 84 linhas (0 a 83) de dados nessa página (ele lê isso no cabeçalho da página), então ele começará verificando a linha 41. A partir daí, ele sabe em qual metade procurar e (no neste exemplo), ele lerá a linha 20. Mais algumas leituras (fazendo 6 ou 7 no total)* e ele conhecerá a linha 25 (por favor, olhe para a coluna chamada 'Linha' para este valor, não para o número da linha fornecido pelo SSMS ) é muito pequeno, mas a linha 26 é muito grande – então 25 é a resposta!
*Em uma pesquisa binária, a pesquisa pode ser um pouco mais rápida se tiver sorte ao dividir o bloco em dois se não houver slot do meio e dependendo se o slot do meio pode ser eliminado ou não.
Agora ele pode ir para a página 1004 no arquivo 5. Vamos usar DBCC PAGE nesse.
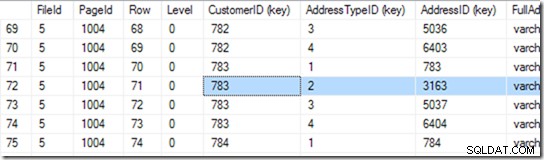
Este dá-me 94 linhas. Ele faz outra pesquisa binária para encontrar o início do intervalo que está procurando. Ele tem que olhar através de 6 ou 7 linhas para encontrar isso.
“Início do intervalo?” Eu posso ouvir você perguntar. Mas estamos procurando o tipo de endereço 2 do cliente 783.
Certo, mas não declaramos este índice como único. Então pode ser dois. Se for único, a busca pode fazer uma busca singleton e pode tropeçar durante a busca binária, mas neste caso, deve completar a busca binária, para encontrar a primeira linha no intervalo. Neste caso, é a linha 71.
Mas não paramos por aqui. Agora precisamos ver se realmente existe um segundo! Portanto, ele lê a linha 72 também e descobre que o par CustomerID+AddressTypeiD é realmente muito grande e sua busca é feita.
E isso acontece três vezes. Na terceira vez, ele não encontra uma linha para o cliente 783 e o tipo de endereço 5, mas não sabe disso com antecedência e ainda precisa concluir a busca.
Portanto, as linhas realmente lidas nessas três buscas (para encontrar duas linhas para saída) são muito mais do que o número retornado. Há cerca de 7 no nível de índice 1 e mais cerca de 7 no nível de folha apenas para encontrar o início do intervalo. Em seguida, ele lê a linha com a qual nos importamos e, em seguida, a linha depois disso. Isso soa mais como 16 para mim, e faz isso três vezes, fazendo cerca de 48 linhas.
Mas Real Rows Read não é sobre o número de linhas realmente lidas, mas o número de linhas retornadas pelo Seek Predicate, que são testadas em relação ao Residual Predicate. E nisso, são apenas as 2 linhas que são encontradas pelas 3 buscas.
Você pode estar pensando neste momento que há uma certa ineficácia aqui. A segunda busca também teria lido a página 712, verificado as mesmas 6 ou 7 linhas lá, e então lido a página 1004, e caçado através dela… como teria feito a terceira busca.
Então, talvez fosse melhor conseguir isso em uma única busca, lendo a página 712 e a página 1004 apenas uma vez cada. Afinal, se eu estivesse fazendo isso com um sistema baseado em papel, teria feito uma busca para encontrar o cliente 783 e, em seguida, escaneado todos os seus tipos de endereço. Porque eu sei que um cliente não costuma ter muitos endereços. Essa é uma vantagem que tenho sobre o mecanismo de banco de dados. O mecanismo de banco de dados sabe através de suas estatísticas que uma busca será a melhor, mas não sabe que a busca deve descer apenas um nível, quando pode dizer que tem o que parece ser o Índice Ideal.
Se eu alterar minha consulta para obter um intervalo de tipos de endereço, de 2 a 5, obterei quase o comportamento que desejo:
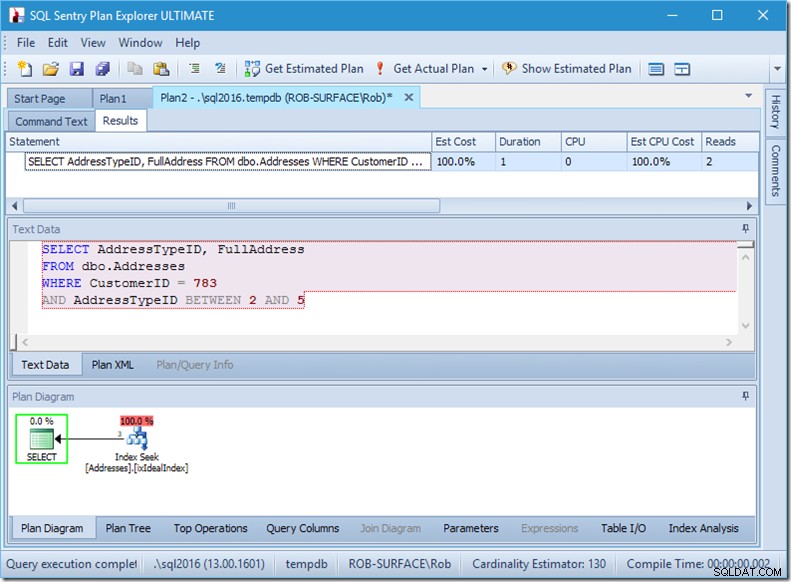
Olha – as leituras estão reduzidas a 2, e eu sei quais são as páginas…
…mas meus resultados estão errados. Porque eu só quero os tipos de endereço 2, 4 e 5, não 3. Preciso dizer para não ter 3, mas tenho que ter cuidado como faço isso. Veja os próximos dois exemplos.
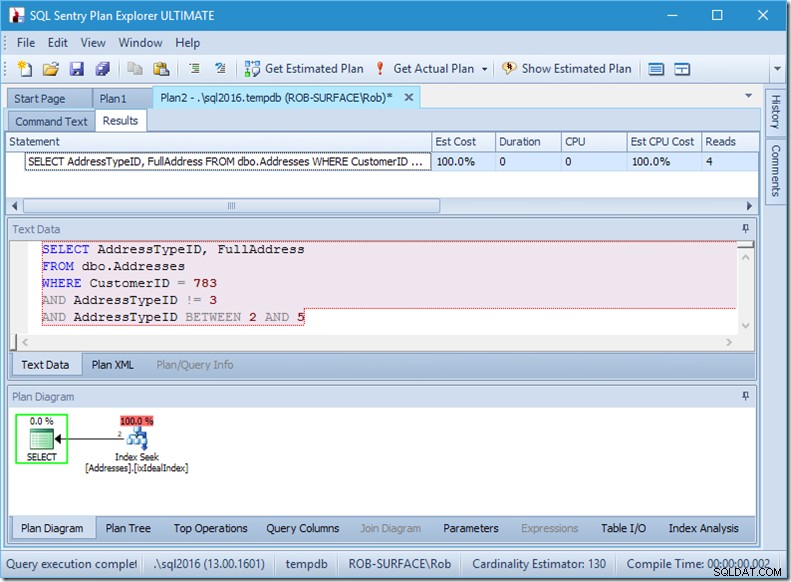
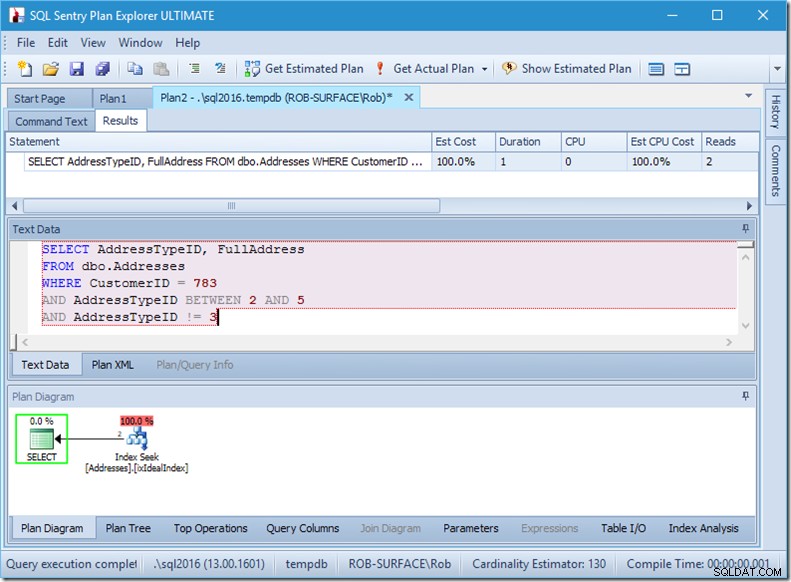
Posso garantir que a ordem dos predicados não importa, mas aqui ela claramente importa. Se colocarmos o “não 3” primeiro, ele fará duas buscas (4 leituras), mas se colocarmos o “não 3” em segundo lugar, ele fará uma busca única (2 leituras).
O problema é que AddressTypeID !=3 é convertido para (AddressTypeID> 3 OR AddressTypeID <3), que é visto como dois predicados de busca muito úteis.
Portanto, minha preferência é usar um predicado não-sargável para dizer a ele que quero apenas os tipos de endereço 2, 4 e 5. E posso fazer isso modificando AddressTypeID de alguma forma, como adicionar zero a ele.
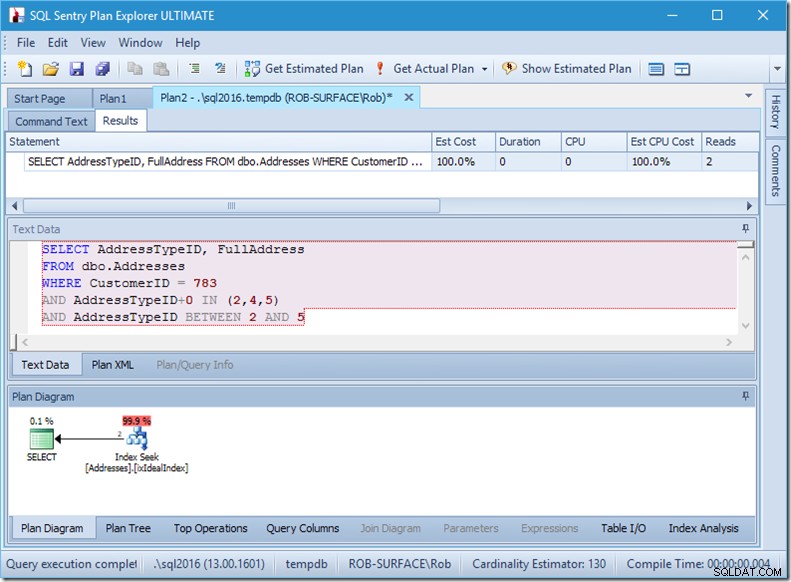
Agora eu tenho uma varredura de intervalo agradável e apertada em uma única busca, e ainda estou me certificando de que minha consulta esteja retornando apenas as linhas que eu quero.
Ah, mas essa propriedade Real Rows Read? Isso agora é maior que a propriedade Linhas Reais, porque o Predicado de Busca encontra o tipo de endereço 3, que o Predicado Residual rejeita.
Troquei três buscas perfeitas por uma única busca imperfeita, que estou consertando com um predicado residual.
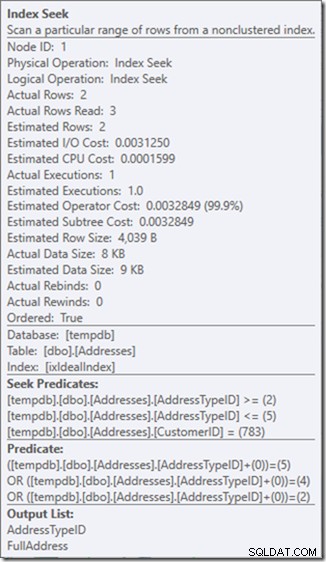
E para mim, às vezes, esse é um preço que vale a pena pagar, obtendo um plano de consulta com o qual estou muito mais feliz. Não é consideravelmente mais barato, embora tenha apenas um terço das leituras (porque haveria apenas duas leituras físicas), mas quando penso no trabalho que está fazendo, fico muito mais confortável com o que estou pedindo fazer desta forma.