Praticamente todos os problemas de desempenho relacionados a colunas computadas que encontrei ao longo dos anos tiveram uma (ou mais) das seguintes causas principais:
- Limitações de implementação
- Falta de suporte ao modelo de custo no otimizador de consultas
- Expansão da definição de coluna calculada antes do início da otimização
Um exemplo de uma limitação de implementação é não conseguir criar um índice filtrado em uma coluna computada (mesmo quando persistido). Não há muito que possamos fazer sobre essa categoria de problemas; temos que usar soluções alternativas enquanto esperamos que as melhorias do produto cheguem.
A falta de otimizador suporte ao modelo de custo significa que o SQL Server atribui um pequeno custo fixo aos cálculos escalares, independentemente da complexidade ou implementação. Como consequência, o servidor geralmente decide recalcular um valor de coluna computado armazenado em vez de ler o valor persistente ou indexado diretamente. Isso é particularmente doloroso quando a expressão computada é cara, por exemplo, quando envolve chamar uma função escalar definida pelo usuário.
Os problemas em torno da expansão de definição são um pouco mais envolventes e têm efeitos abrangentes.
Os problemas da expansão de colunas computadas
O SQL Server normalmente expande as colunas computadas em suas definições subjacentes durante a fase de ligação da normalização da consulta. Esta é uma fase muito inicial no processo de compilação de consultas, bem antes de qualquer decisão de seleção de plano ser tomada (incluindo plano trivial).
Em teoria, realizar uma expansão antecipada pode permitir otimizações que, de outra forma, seriam perdidas. Por exemplo, o otimizador pode aplicar simplificações com base em outras informações na consulta e nos metadados (por exemplo, restrições). Este é o mesmo tipo de raciocínio que leva à expansão das definições de visualização (a menos que um
NOEXPAND dica é usada). Mais tarde no processo de compilação (mas ainda antes mesmo de um plano trivial ser considerado), o otimizador procura corresponder as expressões às colunas computadas persistentes ou indexadas. O problema é que as atividades do otimizador nesse meio tempo podem ter alterado as expressões expandidas de forma que a correspondência não seja mais possível.
Quando isso ocorre, o plano de execução final parece que o otimizador perdeu uma oportunidade "óbvia" de usar uma coluna computada persistente ou indexada. Existem poucos detalhes nos planos de execução que podem ajudar a determinar a causa, tornando esse um problema potencialmente frustrante para depurar e corrigir.
Correspondência de expressões a colunas computadas
Vale a pena ser especialmente claro que existem dois processos separados aqui:
- Expansão antecipada de colunas computadas; e
- Tentativas posteriores de corresponder expressões a colunas computadas.
Em particular, observe que qualquer expressão de consulta pode corresponder a uma coluna computada adequada posteriormente, não apenas expressões que surgiram da expansão de colunas computadas.
A correspondência de expressão de coluna computada pode permitir melhorias no plano mesmo quando o texto da consulta original não pode ser modificado. Por exemplo, criar uma coluna computada para corresponder a uma expressão de consulta conhecida permite que o otimizador use estatísticas e índices associados à coluna computada. Esse recurso é conceitualmente semelhante à correspondência de exibição indexada na Enterprise Edition. A correspondência de colunas computadas é funcional em todas as edições.
Do ponto de vista prático, minha própria experiência mostra que a correspondência de expressões de consulta gerais com colunas computadas pode realmente beneficiar o desempenho, a eficiência e a estabilidade do plano de execução. Por outro lado, raramente (ou nunca) achei que a expansão de colunas computadas valesse a pena. Simplesmente nunca parece produzir otimizações úteis.
Usos de colunas computadas
Colunas computadas que nenhum persistidos nem indexados têm usos válidos. Por exemplo, eles podem suportar estatísticas automáticas se a coluna for determinística e precisa (sem elementos de ponto flutuante). Eles também podem ser usados para economizar espaço de armazenamento (às custas de um pouco de uso extra do processador em tempo de execução). Como exemplo final, eles podem fornecer uma maneira elegante de garantir que um cálculo simples seja sempre executado corretamente, em vez de ser explicitamente escrito em consultas a cada vez.
Persistente colunas computadas foram adicionadas ao produto especificamente para permitir que os índices fossem construídos em colunas determinísticas, mas "imprecisas" (ponto flutuante). Na minha experiência, esse uso pretendido é relativamente raro. Talvez isso seja simplesmente porque eu não encontro muito dados de ponto flutuante.
Índices de ponto flutuante à parte, colunas persistentes são bastante comuns. Até certo ponto, isso pode ocorrer porque usuários inexperientes supõem que uma coluna computada sempre deve ser persistida antes de poder ser indexada. Usuários mais experientes podem empregar colunas persistentes simplesmente porque descobriram que o desempenho tende a ser melhor assim.
Indexado colunas computadas (persistentes ou não) podem ser usadas para fornecer ordenação e um método de acesso eficiente. Pode ser útil armazenar um valor calculado em um índice sem também persistir na tabela base. Da mesma forma, colunas computadas adequadas também podem ser incluídas em índices em vez de serem colunas-chave.
Desempenho ruim
Uma das principais causas de baixo desempenho é uma simples falha ao usar um valor de coluna computado indexado ou persistente conforme o esperado. Perdi a conta do número de perguntas que tive ao longo dos anos perguntando por que o otimizador escolheria um plano de execução terrível quando existe um plano obviamente melhor usando uma coluna computada indexada ou persistente.
A causa precisa em cada caso varia, mas quase sempre é uma decisão baseada em custo defeituosa (porque os escalares recebem um baixo custo fixo); ou uma falha ao corresponder uma expressão expandida de volta a uma coluna ou índice computado persistente.
As falhas de match-back são especialmente interessantes para mim, porque geralmente envolvem interações complexas com recursos ortogonais do mecanismo. Igualmente frequentemente, a falha na "correspondência" deixa uma expressão (em vez de uma coluna) em uma posição na árvore de consulta interna que impede a correspondência de uma regra de otimização importante. Em ambos os casos, o resultado é o mesmo:um plano de execução abaixo do ideal.
Agora, acho que é justo dizer que as pessoas geralmente indexam ou persistem uma coluna computada com a forte expectativa de que o valor armazenado será realmente usado. Pode ser um choque ver o SQL Server recalculando a expressão subjacente a cada vez, ignorando o valor armazenado deliberadamente fornecido. As pessoas nem sempre estão muito interessadas nas interações internas e nas deficiências do modelo de custo que levaram ao resultado indesejável. Mesmo onde existem soluções alternativas, elas exigem tempo, habilidade e esforço para serem descobertas e testadas.
Resumindo:muitas pessoas simplesmente preferem que o SQL Server use o valor persistido ou indexado. Sempre.
Uma nova opção
Historicamente, não havia como forçar o SQL Server a sempre usar o valor armazenado (sem equivalente ao
NOEXPAND dica para visualizações). Existem algumas circunstâncias em que um guia de plano funcionará, mas nem sempre é possível gerar a forma de plano necessária em primeiro lugar, e nem todos os elementos e posições do plano podem ser forçados (filtros e escalares de cálculo, por exemplo). Ainda não há uma solução clara e totalmente documentada, mas uma atualização recente do SQL Server 2016 forneceu uma nova abordagem interessante. Aplica-se a instâncias do SQL Server 2016 corrigidas com pelo menos a atualização cumulativa 2 para SQL Server 2016 SP1 ou atualização cumulativa 4 para SQL Server 2016 RTM.
A atualização relevante está documentada em:CORREÇÃO:não é possível reconstruir a partição online para uma tabela que contém uma coluna de particionamento computada no SQL Server 2016
Como costuma acontecer com a documentação de suporte, isso não diz exatamente o que foi alterado no mecanismo para resolver o problema. Certamente não parece muito relevante para nossas preocupações atuais, a julgar pelo título e descrição. No entanto, esta correção apresenta um novo sinalizador de rastreamento compatível 176 , que é verificado em um método de código chamado
FDontExpandPersistedCC . Como o nome do método sugere, isso impede que uma coluna computada persistente seja expandida. Há três advertências importantes para isso:
- A coluna computada deve ser persistente . Mesmo se indexada, a coluna também deve ser persistida.
- A correspondência de expressões de consulta gerais para colunas computadas persistentes está desativada .
- A documentação não descreve a função do sinalizador de rastreamento e não o prescreve para nenhum outro uso. Se você optar por usar o sinalizador de rastreamento 176 para evitar a expansão de colunas computadas persistentes, será por sua conta e risco.
Este sinalizador de rastreamento é eficaz como um
–T de inicialização opção, no escopo global e de sessão usando DBCC TRACEON , e por consulta com OPTION (QUERYTRACEON) . Exemplo
Esta é uma versão simplificada de uma pergunta (baseada em um problema do mundo real) que respondi no Database Administrators Stack Exchange alguns anos atrás. A definição da tabela inclui uma coluna computada persistente:
CREATE TABLE dbo.T( ID integer IDENTITY NOT NULL, A varchar(20) NOT NULL, B varchar(20) NOT NULL, C varchar(20) NOT NULL, D date NULL, Computed AS A + '-' + B + '-' + C PERSISTED, CONSTRAINT PK_T_ID PRIMARY KEY CLUSTERED (ID),);GOINSERT dbo.T WITH (TABLOCKX) (A, B, C, D)SELECT A =STR(SV.number % 10, 2 ), B =STR(SV.number % 20, 2), C =STR(SV.number % 30, 2), D =DATEADD(DAY, 0 - SV.number, SYSUTCDATETIME())FROM master.dbo.spt_values AS SVWHERE SV.[tipo] =N'P';
A consulta abaixo retorna todas as linhas da tabela em uma ordem específica, ao mesmo tempo em que retorna o próximo valor da coluna D na mesma ordem:
SELECT T1.ID, T1.Computado, T1.D, NextD =(SELECT TOP (1) t2.D FROM dbo.T AS T2 WHERE T2.Computed =T1.Computed AND T2.D> T1.D ORDER POR T2.D ASC )DE dbo.T AS T1ORDER POR T1.Computado, T1.D;
Um índice de cobertura óbvio para dar suporte à ordenação final e pesquisas na subconsulta é:
CRIAR ÍNDICE NÃO CLUSTERADO ÚNICO IX_T_Computed_D_IDON dbo.T (Computado, D, ID);
O plano de execução entregue pelo otimizador é surpreendente e decepcionante:
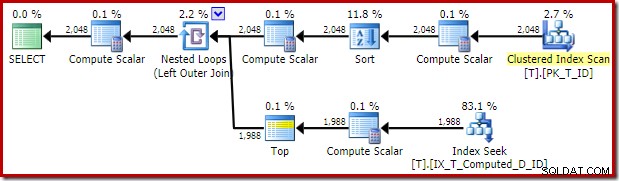
O Index Seek no lado interno do Nested Loops Join parece estar tudo bem. O Clustered Index Scan and Sort na entrada externa, no entanto, é inesperado. Em vez disso, esperávamos ver uma varredura ordenada de nosso índice não clusterizado de cobertura.
Podemos forçar o otimizador a usar o índice não clusterizado com uma dica de tabela:
SELECT T1.ID, T1.Computado, T1.D, NextD =(SELECT TOP (1) t2.D FROM dbo.T AS T2 WHERE T2.Computed =T1.Computed AND T2.D> T1.D ORDER BY T2.D ASC )FROM dbo.T AS T1 WITH (INDEX(IX_T_Computed_D_ID)) -- Novo!ORDER BY T1.Computed, T1.D;
O plano de execução resultante é:
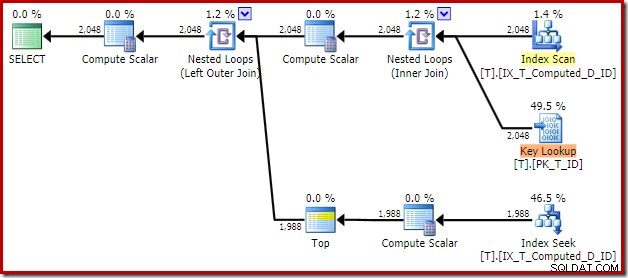
A verificação do índice não clusterizado remove a classificação, mas adiciona uma pesquisa de chave! As pesquisas neste novo plano são surpreendentes, já que nosso índice definitivamente cobre todas as colunas necessárias para a consulta.
Observando as propriedades do operador Key Lookup:
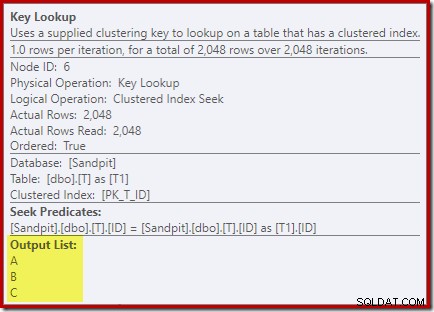
Por alguma razão, o otimizador decidiu que três colunas não mencionadas na consulta precisam ser buscadas na tabela base (já que não estão presentes em nosso índice não clusterizado por design).
Olhando ao redor do plano de execução, descobrimos que as colunas pesquisadas são necessárias para o lado interno Index Seek:

A primeira parte deste predicado de busca corresponde à correlação
T2.Computed = T1.Computed na consulta original. O otimizador expandiu as definições de ambas as colunas computadas, mas só conseguiu corresponder à coluna computada persistente e indexada para o alias do lado interno T1 . Saindo do T2 referência expandida resultou no lado externo da junção precisando fornecer as colunas da tabela base (A , B e C ) necessário para calcular essa expressão para cada linha. Como às vezes é o caso, é possível reescrever essa consulta para que o problema desapareça (uma opção é mostrada na minha resposta antiga à pergunta do Stack Exchange). Usando o SQL Server 2016, também podemos tentar rastrear o sinalizador 176 para impedir que as colunas computadas sejam expandidas:
SELECT T1.ID, T1.Computado, T1.D, NextD =(SELECT TOP (1) t2.D FROM dbo.T AS T2 WHERE T2.Computed =T1.Computed AND T2.D> T1.D ORDER POR T2.D ASC )DE dbo.T AS T1ORDER POR T1.Computado, T1.DOPTION (QUERYTRACEON 176); -- Novo!
O plano de execução agora está muito aprimorado:
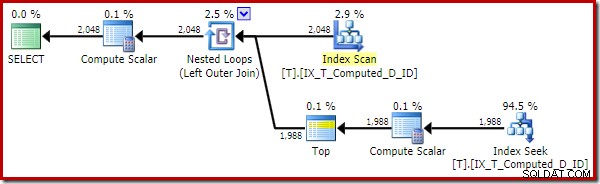
Este plano de execução contém apenas referências às colunas computadas. Os Compute Scalars não fazem nada de útil e seriam limpos se o otimizador estivesse um pouco mais organizado em casa.
O ponto importante é que o índice ideal agora é usado corretamente e a pesquisa de classificação e chave foi eliminada. Tudo impedindo o SQL Server de fazer algo que nunca esperaríamos que ele fizesse (expandir uma coluna computada persistente e indexada).
Usando LEAD
A pergunta original do Stack Exchange foi direcionada ao SQL Server 2008, onde
LEAD não está disponível. Vamos tentar expressar o requisito no SQL Server 2016 usando a sintaxe mais recente:SELECT T1.ID, T1.Computed, T1.D, NextD =LEAD(T1.D) OVER ( PARTITION BY T1.Computed ORDER BY T1.D)FROM dbo.T AS T1ORDER BY T1.Computed; pré>
O plano de execução do SQL Server 2016 é:
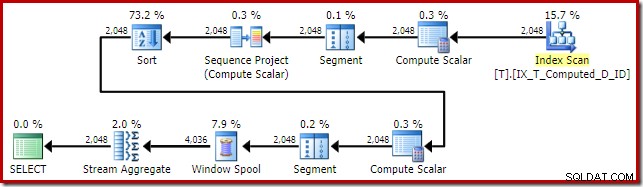
Esta forma de plano é bastante típica para uma função de janela de modo de linha simples. O único item inesperado é o operador Sort no meio. Se o conjunto de dados for grande, essa classificação poderá ter um grande impacto no desempenho e no uso de memória.
A questão, mais uma vez, é a expansão da coluna computada. Nesse caso, uma das expressões expandidas fica em uma posição que impede que a lógica normal do otimizador simplifique o Sort away.
Tentando exatamente a mesma consulta com o sinalizador de rastreamento 176:
SELECT T1.ID, T1.Computed, T1.D, NextD =LEAD(T1.D) OVER ( PARTITION BY T1.Computed ORDER BY T1.D)FROM dbo.T AS T1ORDER BY T1.ComputedOPTION (QUERYTRACEON 176 );
Produz o plano:
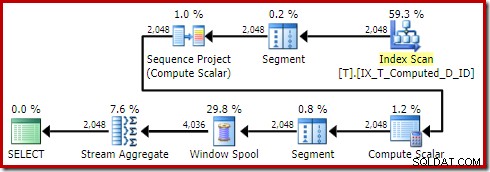
O Sort desapareceu como deveria. Observe também de passagem que essa consulta se qualificou para um plano trivial, evitando totalmente a otimização baseada em custos.
Correspondência de expressão geral desativada
Uma das advertências mencionadas anteriormente foi que o sinalizador de rastreamento 176 também desabilita a correspondência de expressões na consulta de origem para colunas computadas persistentes.
Para ilustrar, considere a seguinte versão da consulta de exemplo. OLEADcomputação foi removida e as referências à coluna computada noSELECTeORDER BYcláusulas foram substituídas pelas expressões subjacentes. Execute-o primeiro sem o sinalizador de rastreamento 176:
SELECT T1.ID, computado =T1.A + '-' + T1.B + '-' + T1.C, T1.DFROM dbo.T AS T1ORDER BY T1.A + '-' + T1.B + '-' + T1.C;
As expressões correspondem à coluna computada persistente e o plano de execução é uma varredura ordenada simples do índice não clusterizado:
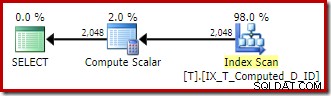
O Compute Scalar, mais uma vez, é apenas lixo arquitetônico remanescente.
Agora tente a mesma consulta com o sinalizador de rastreamento 176 ativado:
SELECT T1.ID, computado =T1.A + '-' + T1.B + '-' + T1.C, T1.DFROM dbo.T AS T1ORDER BY T1.A + '-' + T1.B + '-' + T1.COPTION (QUERYTRACEON 176); -- Novo!
O novo plano de execução é:
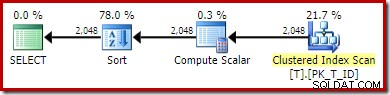
A Varredura de Índice Não Clusterizado foi substituída por uma Varredura de Índice Agrupado. O Compute Scalar avalia a expressão e o Sort ordena pelo resultado. Privado da capacidade de corresponder expressões a colunas computadas persistentes, o otimizador não pode usar o valor persistente ou o índice não clusterizado.
Observe que a limitação de correspondência de expressão se aplica apenas a persistente colunas computadas quando o sinalizador de rastreamento 176 está ativo. Se tornarmos a coluna computada indexada, mas não persistente, a correspondência de expressão funcionará corretamente.
Para eliminar o atributo persisted, precisamos primeiro eliminar o índice não clusterizado. Uma vez feita a alteração, podemos colocar o índice de volta (porque a expressão é determinística e precisa):
DROP INDEX IX_T_Computed_D_ID ON dbo.T;GOALTER TABLE dbo.TALTER COLUMN ComputedDROP PERSISTED;GOCREATE UNIQUE NONCLUSTERED INDEX IX_T_Computed_D_IDON dbo.T (Computed, D, ID);
O otimizador agora não tem problemas para corresponder a expressão de consulta à coluna computada quando o sinalizador de rastreamento 176 está ativo:
-- A coluna computada não persiste mais-- mas ainda está indexada. TF 176 active.SELECT T1.ID, Calculado =T1.A + '-' + T1.B + '-' + T1.C, T1.DFROM dbo.T AS T1ORDER BY T1.A + '-' + T1. B + '-' + T1.COPTION (QUERYTRACEON 176);
O plano de execução retorna à varredura de índice não clusterizada ideal sem uma classificação:
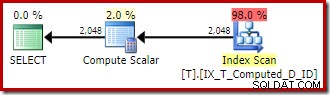
Para resumir:O sinalizador de rastreamento 176 impede a expansão de coluna computada persistente. Como efeito colateral, também impede que a expressão de consulta corresponda apenas a colunas computadas persistentes.
Os metadados do esquema são carregados apenas uma vez, durante a fase de vinculação. O sinalizador de rastreamento 176 impede a expansão para que a definição de coluna computada não seja carregada naquele momento. A correspondência posterior de expressão para coluna não pode funcionar sem a definição de coluna computada para correspondência.
A carga inicial de metadados traz todas as colunas, não apenas aquelas referenciadas na consulta (essa otimização é realizada posteriormente). Isso torna todas as colunas computadas disponíveis para correspondência, o que geralmente é uma coisa boa. Infelizmente, se uma das colunas computadas carregadas contiver uma função escalar definida pelo usuário, sua presença desabilitará o paralelismo para toda a consulta, mesmo quando a coluna problemática não for usada. O sinalizador de rastreamento 176 também pode ajudar com isso, se a coluna em questão persistir. Ao não carregar a definição, uma função escalar definida pelo usuário nunca está presente, portanto, o paralelismo não é desabilitado.
Considerações finais
Parece-me que o mundo do SQL Server seria um lugar melhor se o otimizador tratasse colunas computadas persistentes ou indexadas mais como colunas regulares. Em quase todos os casos, isso corresponderia melhor às expectativas do desenvolvedor do que o arranjo atual. Expandir colunas computadas em suas expressões subjacentes e depois tentar combiná-las de volta não é tão bem-sucedido na prática quanto a teoria pode sugerir.
Até que o SQL Server forneça suporte específico para impedir a expansão de colunas computadas persistentes ou indexadas, o novo sinalizador de rastreamento 176 é uma opção tentadora para usuários do SQL Server 2016, embora imperfeita. É um pouco lamentável que desative a correspondência de expressão geral como um efeito colateral. Também é uma pena que a coluna computada tenha que ser persistida quando indexada. Existe então o risco de usar um sinalizador de rastreamento para outra finalidade que não seja sua documentada a ser considerada.
É justo dizer que a maioria dos problemas com consultas de colunas computadas pode ser resolvida de outras maneiras, com tempo, esforço e experiência suficientes. Por outro lado, o sinalizador de rastreamento 176 geralmente parece funcionar como mágica. A escolha, como dizem, é sua.
Para terminar, aqui estão alguns problemas interessantes de colunas computadas que se beneficiam do sinalizador de rastreamento 176:
- Índice de coluna calculado não usado
- Coluna computada PERSISTED não usada no particionamento da função de janelas
- Coluna computada persistente causando verificação
- Índice de coluna calculado não usado com tipos de dados MAX
- Grave problema de desempenho com colunas e junções computadas persistentes
- Por que o SQL Server "computa escalar" quando eu SELECIONO uma coluna computada persistente?
- Colunas de base usadas em vez de coluna computada persistente por mecanismo
- Coluna computada com UDF desativa o paralelismo para consultas em *outras* colunas