Considere a seguinte consulta do AdventureWorks que retorna IDs de transação da tabela de histórico para a ID de produto 421:
SELECT TH.TransactionID FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 421;
O otimizador de consulta encontra rapidamente um plano de execução eficiente com uma estimativa de cardinalidade (contagem de linhas) exatamente correta, conforme mostrado no SQL Sentry Plan Explorer:

Agora digamos que queremos encontrar IDs de transação de histórico para o produto AdventureWorks chamado "Metal Plate 2". Há muitas maneiras de expressar essa consulta em T-SQL. Uma formulação natural é:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID =
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
); O plano de execução é o seguinte:
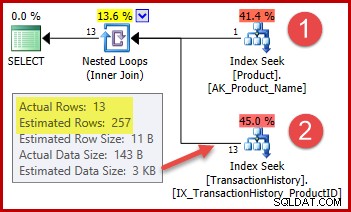
A estratégia é:
- Procure o ID do produto na tabela Produto a partir do nome fornecido
- Localize as linhas desse ID do produto na tabela Histórico
O número estimado de linhas para a etapa 1 está exatamente correto porque o índice usado é declarado como exclusivo e digitado apenas no nome do produto. O teste de igualdade em "Metal Plate 2" é, portanto, garantido para retornar exatamente uma linha (ou zero linhas se especificarmos um nome de produto que não existe).
A estimativa de 257 linhas realçada para a etapa dois é menos precisa:apenas 13 linhas são realmente encontradas. Essa discrepância ocorre porque o otimizador não sabe qual ID de produto específico está associada ao produto denominado "Metal Plate 2". Ele trata o valor como desconhecido, gerando uma estimativa de cardinalidade usando informações de densidade média. O cálculo usa elementos do objeto de estatísticas mostrado abaixo:
DBCC SHOW_STATISTICS
(
'Production.TransactionHistory',
'IX_TransactionHistory_ProductID'
)
WITH STAT_HEADER, DENSITY_VECTOR; 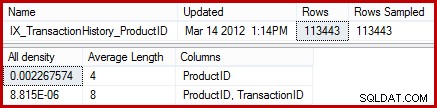
As estatísticas mostram que a tabela contém 113.443 linhas com 441 IDs de produtos exclusivos (1 / 0,002267574 =441). Supondo que a distribuição de linhas entre os IDs do produto seja uniforme, a estimativa de cardinalidade espera que um ID do produto corresponda (113443/441) =257,24 linhas em média. Como se vê, a distribuição não é particularmente uniforme; existem apenas 13 linhas para o produto "Metal Plate 2".
Um aparte
Você pode estar pensando que a estimativa de 257 linhas deveria ser mais precisa. Por exemplo, considerando que as IDs e os nomes dos produtos são restritos a serem exclusivos, o SQL Server pode manter automaticamente as informações sobre esse relacionamento de um para um. Ele saberia então que "Metal Plate 2" está associado ao ID do produto 479 e usaria esse insight para gerar uma estimativa mais precisa usando o histograma ProductID:
DBCC SHOW_STATISTICS
(
'Production.TransactionHistory',
'IX_TransactionHistory_ProductID'
)
WITH HISTOGRAM; 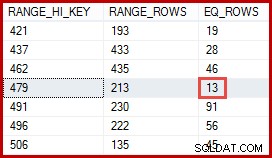
Uma estimativa de 13 linhas derivadas dessa maneira teria sido exatamente correta. No entanto, a estimativa de 257 linhas não era irracional, dadas as informações estatísticas disponíveis e as suposições simplificadoras normais (como distribuição uniforme) aplicadas pela estimativa de cardinalidade hoje. Estimativas exatas são sempre boas, mas estimativas "razoáveis" também são perfeitamente aceitáveis.
Combinando as duas consultas
Digamos que agora queremos ver todos os IDs do histórico de transações em que o ID do produto é 421 OU o nome do produto é "Metal Plate 2". Uma maneira natural de combinar as duas consultas anteriores é:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = 421
OR TH.ProductID =
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
); O plano de execução é um pouco mais complexo agora, mas ainda contém elementos reconhecíveis dos planos de predicado único:
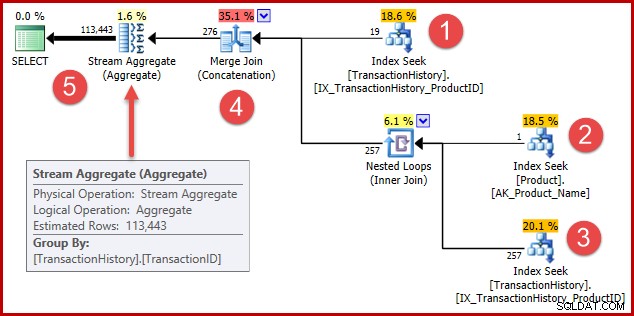
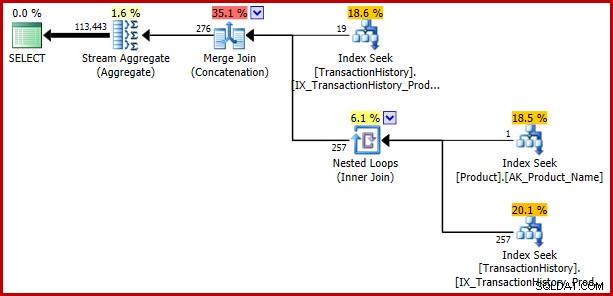
A estratégia é:
- Encontre registros de histórico para o produto 421
- Procure o ID do produto chamado "Metal Plate 2"
- Encontre registros de histórico para o ID do produto encontrado na etapa 2
- Combine linhas das etapas 1 e 3
- Remova quaisquer duplicatas (porque o produto 421 também pode ser aquele chamado "Metal Plate 2")
As etapas 1 a 3 são exatamente as mesmas de antes. As mesmas estimativas são produzidas pelas mesmas razões. A etapa 4 é nova, mas muito simples:ela concatena 19 linhas esperadas com 257 linhas esperadas, para fornecer uma estimativa de 276 linhas.
O passo 5 é o mais interessante. O Stream Aggregate de remoção de duplicatas tem uma entrada estimada de 276 linhas e uma saída estimada de 113443 linhas. Um agregado que produz mais linhas do que recebe parece impossível, certo?
* Você verá uma estimativa de 102.099 linhas aqui se estiver usando o modelo de estimativa de cardinalidade anterior a 2014.
O erro de estimativa de cardinalidade
A estimativa impossível do Stream Aggregate em nosso exemplo é causada por um bug na estimativa de cardinalidade. É um exemplo interessante, por isso vamos explorá-lo com um pouco de detalhe.
Remoção de subconsulta
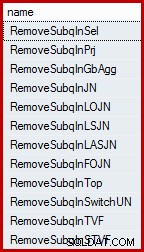
Você pode se surpreender ao saber que o otimizador de consulta do SQL Server não funciona diretamente com subconsultas. Eles são removidos da árvore de consulta lógica no início do processo de compilação e substituídos por uma construção equivalente com a qual o otimizador está configurado para trabalhar e raciocinar. O otimizador possui várias regras que removem subconsultas. Eles podem ser listados por nome usando a seguinte consulta (o DMV referenciado é minimamente documentado, mas não é suportado):
SELECT name FROM sys.dm_exec_query_transformation_stats WHERE name LIKE 'RemoveSubq%';
Resultados (no SQL Server 2014):
A consulta de teste combinada tem dois predicados ("seleções" em termos relacionais) na tabela de histórico, conectados por
OR . Um desses predicados inclui uma subconsulta. A subárvore inteira (ambos os predicados e a subconsulta) é transformada pela primeira regra na lista ("remover subconsulta na seleção") em uma semijunção sobre a união dos predicados individuais. Embora não seja possível representar o resultado dessa transformação interna exatamente usando a sintaxe T-SQL, está bem próximo de ser:SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE EXISTS
(
SELECT 1
WHERE TH.ProductID = 421
UNION ALL
SELECT 1
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
AND P.ProductID = TH.ProductID
)
OPTION (QUERYRULEOFF ApplyUAtoUniSJ); É um pouco lamentável que minha aproximação T-SQL da árvore interna após a remoção da subconsulta contenha uma subconsulta, mas na linguagem do processador de consultas ela não contém (é uma semi-junção). Se você preferir ver o formulário interno bruto em vez da minha tentativa de um equivalente em T-SQL, tenha certeza de que isso acontecerá em breve.
A dica de consulta não documentada incluída no T-SQL acima serve para impedir uma transformação subsequente para aqueles que desejam ver a lógica transformada no formulário de plano de execução. As anotações abaixo mostram as posições dos dois predicados após a transformação:
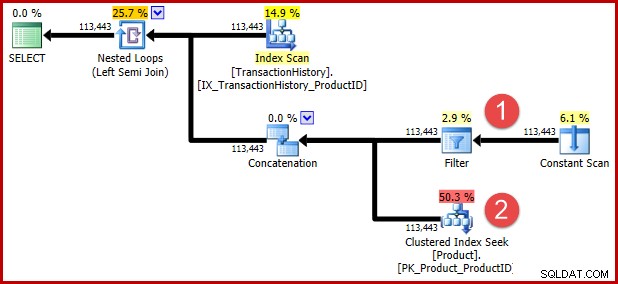
A intuição por trás da transformação é que uma linha do histórico se qualifica se um dos predicados for satisfeito. Independentemente de quão útil você ache minha ilustração aproximada de T-SQL e plano de execução, espero que seja pelo menos razoavelmente claro que a reescrita expressa o mesmo requisito da consulta original.
Devo enfatizar que o otimizador não gera literalmente uma sintaxe T-SQL alternativa ou produz planos de execução completos em estágios intermediários. As representações do T-SQL e do plano de execução acima destinam-se apenas a auxiliar na compreensão. Se você estiver interessado nos detalhes brutos, a representação interna prometida da árvore de consulta transformada (ligeiramente editada para maior clareza/espaço) é:
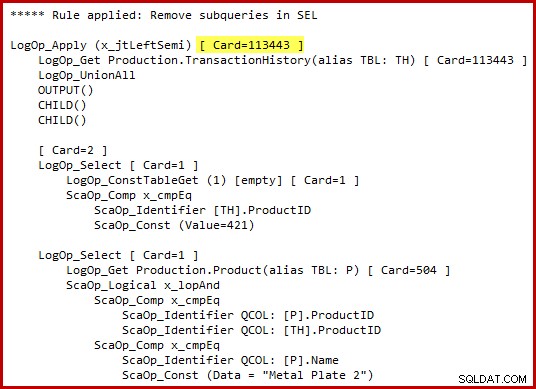
Observe a estimativa de cardinalidade de aplicação de semijunção destacada. São 113.443 linhas ao usar o estimador de cardinalidade de 2014 (102.099 linhas ao usar o CE antigo). Lembre-se de que a tabela de histórico do AdventureWorks contém 113.443 linhas no total, portanto, isso representa 100% de seletividade (90% para o CE antigo).
Vimos anteriormente que a aplicação de qualquer um desses predicados sozinho resulta em apenas um pequeno número de correspondências:19 linhas para a ID do produto 421 e 13 linhas (estimada em 257) para "Metal Plate 2". Estimando que a disjunção
(OR) dos dois predicados retornará todas as linhas na tabela base parece totalmente maluco. Detalhes do bug
Os detalhes do cálculo de seletividade para a semijunção são visíveis apenas no SQL Server 2014 ao usar o novo estimador de cardinalidade com o sinalizador de rastreamento (não documentado) 2363. Provavelmente, é possível ver algo semelhante com eventos estendidos, mas a saída do sinalizador de rastreamento é mais conveniente para usar aqui. A seção relevante da saída é mostrada abaixo:
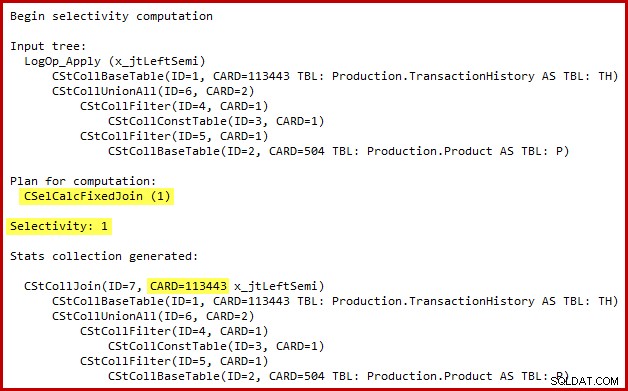
O estimador de cardinalidade usa a calculadora Fixed Join com 100% de seletividade. Como consequência, a cardinalidade de saída estimada da semijunção é a mesma de sua entrada, o que significa que todas as 113.443 linhas da tabela de histórico devem se qualificar.
A natureza exata do bug é que o cálculo da seletividade de semijunção perde todos os predicados posicionados além de uma união na árvore de entrada. Na ilustração abaixo, a falta de predicados na própria semijunção significa que todas as linhas serão qualificadas; ele ignora o efeito dos predicados abaixo da concatenação (união todos).
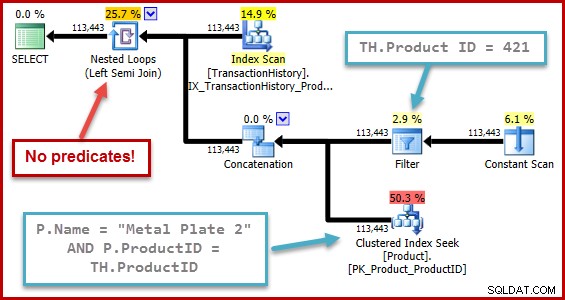
Esse comportamento é ainda mais surpreendente quando você considera que a computação de seletividade está operando em uma representação em árvore que o próprio otimizador gerou (a forma da árvore e o posicionamento dos predicados é o resultado da remoção da subconsulta).
Um problema semelhante ocorre com o estimador de cardinalidade pré-2014, mas a estimativa final é fixada em 90% da entrada de semijunção estimada (por razões divertidas relacionadas a uma estimativa de predicado fixa invertida de 10% que é muito desvio para obter para dentro).
Exemplos
Como mencionado acima, esse bug se manifesta quando a estimativa é realizada para uma semi-junção com predicados relacionados posicionados além de uma união all. Se essa organização interna ocorre durante a otimização da consulta depende da sintaxe T-SQL original e da sequência precisa das operações de otimização interna. Os exemplos a seguir mostram alguns casos em que o bug ocorre e não ocorre:
Exemplo 1
Este primeiro exemplo incorpora uma alteração trivial na consulta de teste:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = (SELECT 421) -- The only change
OR TH.ProductID =
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
); O plano de execução estimado é:
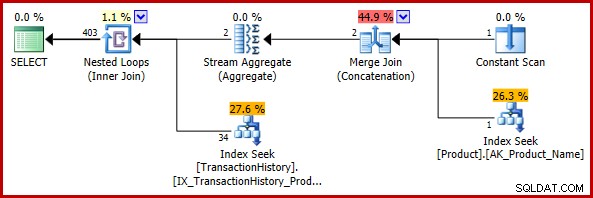
A estimativa final de 403 linhas é inconsistente com as estimativas de entrada da junção de loops aninhados, mas ainda é razoável (no sentido discutido anteriormente). Se o bug tivesse sido encontrado, a estimativa final seria de 113.443 linhas (ou 102.099 linhas ao usar o modelo CE anterior a 2014).
Exemplo 2
Caso você esteja prestes a se apressar e reescrever todas as suas comparações constantes como subconsultas triviais para evitar esse bug, veja o que acontece se fizermos outra alteração trivial, desta vez substituindo o teste de igualdade no segundo predicado por IN. O significado da consulta permanece inalterado:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = (SELECT 421) -- Change 1
OR TH.ProductID IN -- Change 2
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
); O erro retorna:
Exemplo 3
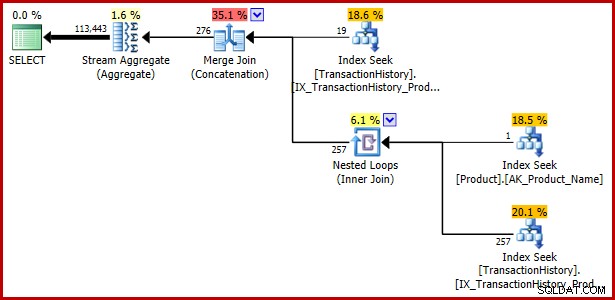
Embora este artigo tenha se concentrado até agora em um predicado disjuntivo contendo uma subconsulta, o exemplo a seguir mostra que a mesma especificação de consulta expressa usando EXISTS e UNION ALL também é vulnerável:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE EXISTS
(
SELECT 1
WHERE TH.ProductID = 421
UNION ALL
SELECT 1
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
AND P.ProductID = TH.ProductID
); Plano de execução:
Exemplo 4
Aqui estão mais duas maneiras de expressar a mesma consulta lógica em T-SQL:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = 421
UNION
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID =
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
);
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = 421
UNION
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
JOIN Production.Product AS P
ON P.ProductID = TH.ProductID
AND P.Name = N'Metal Plate 2'; Nenhuma consulta encontra o bug e ambas produzem o mesmo plano de execução:
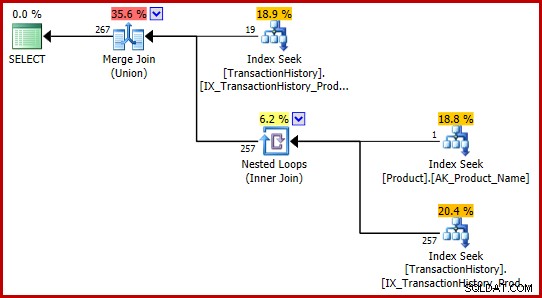
Essas formulações T-SQL produzem um plano de execução com estimativas totalmente consistentes (e razoáveis).
Exemplo 5
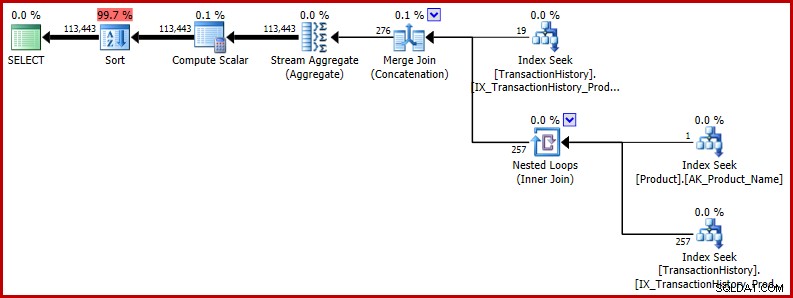
Você pode estar se perguntando se a estimativa imprecisa é importante. Nos casos apresentados até agora, não é, pelo menos não diretamente. Os problemas surgem quando o bug ocorre em uma consulta maior e a estimativa incorreta afeta as decisões do otimizador em outros lugares. Como um exemplo minimamente estendido, considere retornar os resultados de nossa consulta de teste em uma ordem aleatória:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = 421
OR TH.ProductID =
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
)
ORDER BY NEWID(); -- New O plano de execução mostra que a estimativa incorreta afeta as operações posteriores. Por exemplo, é a base para a concessão de memória reservada para a classificação:
Se você quiser ver um exemplo mais real do impacto potencial desse bug, dê uma olhada nesta pergunta recente de Richard Mansell no site de perguntas e respostas SQLPerformance.com, answers.SQLPerformance.com.
Resumo e Considerações Finais
Esse bug é acionado quando o otimizador realiza a estimativa de cardinalidade para uma semijunção, em circunstâncias específicas. É um bug difícil de detectar e contornar por vários motivos:
- Não há sintaxe T-SQL explícita para especificar uma semi-junção, então é difícil saber com antecedência se uma consulta específica será vulnerável a esse bug.
- O otimizador pode introduzir uma semijunção em uma ampla variedade de circunstâncias, nem todas são candidatas óbvias à semijunção.
- A semi-junção problemática geralmente é transformada em outra coisa pela atividade posterior do otimizador, portanto, não podemos nem contar com uma operação de semi-junção no plano de execução final.
- Nem todas as estimativas de cardinalidade de aparência estranha são causadas por esse bug. De fato, muitos exemplos desse tipo são um efeito colateral esperado e inofensivo da operação normal do otimizador.
- A estimativa de seletividade de semijunção errônea sempre será 90% ou 100% de sua entrada, mas isso geralmente não corresponderá à cardinalidade de uma tabela usada no plano. Além disso, a cardinalidade de entrada de semijunção usada no cálculo pode nem ser visível no plano de execução final.
- Normalmente, há muitas maneiras de expressar a mesma consulta lógica em T-SQL. Alguns deles acionarão o bug, enquanto outros não.
Essas considerações tornam difícil oferecer conselhos práticos para identificar ou contornar esse bug. Certamente vale a pena verificar os planos de execução para estimativas "ultrajantes" e investigar consultas com desempenho muito pior do que o esperado, mas ambos podem ter causas que não estão relacionadas a esse bug. Dito isso, vale a pena verificar particularmente as consultas que incluem uma disjunção de predicados e uma subconsulta. Como os exemplos neste artigo mostram, essa não é a única maneira de encontrar o bug, mas espero que seja comum.
Se você tiver a sorte de estar executando o SQL Server 2014, com o novo estimador de cardinalidade habilitado, poderá confirmar o bug verificando manualmente a saída do sinalizador de rastreamento 2363 para uma estimativa de seletividade fixa de 100% em uma semijunção, mas isso é dificilmente conveniente. Você não vai querer usar sinalizadores de rastreamento não documentados em um sistema de produção, naturalmente.
O relatório de bug do User Voice para este problema pode ser encontrado aqui. Por favor, vote e comente se você gostaria de ver este problema investigado (e possivelmente corrigido).