Nos últimos dois blogs, abordamos como executar um Galera Cluster no Docker, seja no Docker autônomo ou no Docker Swarm de vários hosts com rede de sobreposição. Nesta postagem do blog, veremos como executar o Galera Cluster no Kubernetes, uma ferramenta de orquestração para executar contêineres em escala. Algumas partes são diferentes, como como o aplicativo deve se conectar ao cluster, como o Kubernetes lida com o failover e como o balanceamento de carga funciona no Kubernetes.
Kubernetes x Docker Swarm
Nosso objetivo final é garantir que o Galera Cluster seja executado de forma confiável em um ambiente de contêiner. Anteriormente, abordamos o Docker Swarm e descobrimos que a execução do Galera Cluster nele possui vários bloqueadores, o que impede que ele esteja pronto para produção. Nossa jornada agora continua com o Kubernetes, uma ferramenta de orquestração de contêineres de nível de produção. Vamos ver qual nível de “prontidão de produção” ele pode suportar ao executar um serviço com estado como o Galera Cluster.
Antes de prosseguirmos, vamos destacar algumas das principais diferenças entre o Kubernetes (1.6) e o Docker Swarm (17.03) ao executar o Galera Cluster em contêineres:
- O Kubernetes oferece suporte a duas sondagens de verificação de integridade - vivacidade e prontidão. Isso é importante ao executar um Galera Cluster em contêineres, porque um contêiner Galera ativo não significa que está pronto para servir e deve ser incluído no conjunto de balanceamento de carga (pense em um estado de associado/doador). O Docker Swarm suporta apenas uma sonda de verificação de integridade semelhante à atividade do Kubernetes, um contêiner está íntegro e continua em execução ou não íntegro e é reagendado. Leia aqui para mais detalhes.
- O Kubernetes tem um painel de interface do usuário acessível por meio do "proxy kubectl".
- O Docker Swarm é compatível apenas com balanceamento de carga round-robin (entrada), enquanto o Kubernetes usa menos conexão.
- O Docker Swarm oferece suporte a malha de roteamento para publicar um serviço na rede externa, enquanto o Kubernetes oferece suporte a algo semelhante chamado NodePort, bem como balanceadores de carga externos (GCE GLB/AWS ELB) e nomes DNS externos (como na v1.7)
Instalando o Kubernetes usando o Kubeadm
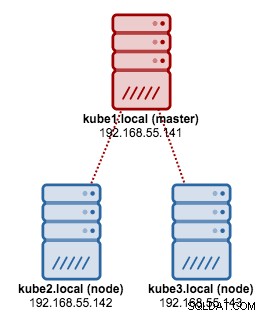
Vamos usar o kubeadm para instalar um cluster Kubernetes de 3 nós no CentOS 7. Ele consiste em 1 mestre e 2 nós (minions). Nossa arquitetura física fica assim:
1. Instale o kubelet e o Docker em todos os nós:
$ ARCH=x86_64
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://packages.cloud.google.com/yum/repos/kubernetes-el7-${ARCH}
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://packages.cloud.google.com/yum/doc/yum-key.gpg
https://packages.cloud.google.com/yum/doc/rpm-package-key.gpg
EOF
$ setenforce 0
$ yum install -y docker kubelet kubeadm kubectl kubernetes-cni
$ systemctl enable docker && systemctl start docker
$ systemctl enable kubelet && systemctl start kubelet2. No master, inicialize o master, copie o arquivo de configuração, configure a rede do Pod usando o Weave e instale o Kubernetes Dashboard:
$ kubeadm init
$ cp /etc/kubernetes/admin.conf $HOME/
$ export KUBECONFIG=$HOME/admin.conf
$ kubectl apply -f https://git.io/weave-kube-1.6
$ kubectl create -f https://git.io/kube-dashboard3. Em seguida, nos outros nós restantes:
$ kubeadm join --token 091d2a.e4862a6224454fd6 192.168.55.140:64434. Verifique se os nós estão prontos:
$ kubectl get nodes
NAME STATUS AGE VERSION
kube1.local Ready 1h v1.6.3
kube2.local Ready 1h v1.6.3
kube3.local Ready 1h v1.6.3Agora temos um cluster Kubernetes para implantação do Galera Cluster.
Galera Cluster no Kubernetes
Neste exemplo, vamos implantar um MariaDB Galera Cluster 10.1 usando a imagem Docker extraída de nosso repositório DockerHub. Os arquivos de definição YAML usados nesta implantação podem ser encontrados no diretório example-kubernetes no repositório do Github.
O Kubernetes oferece suporte a vários controladores de implantação. Para implantar um Galera Cluster, pode-se usar:
- Conjunto de réplicas
- StatefulSet
Cada um deles tem seus prós e contras. Vamos analisar cada um deles e ver qual é a diferença.
Pré-requisitos
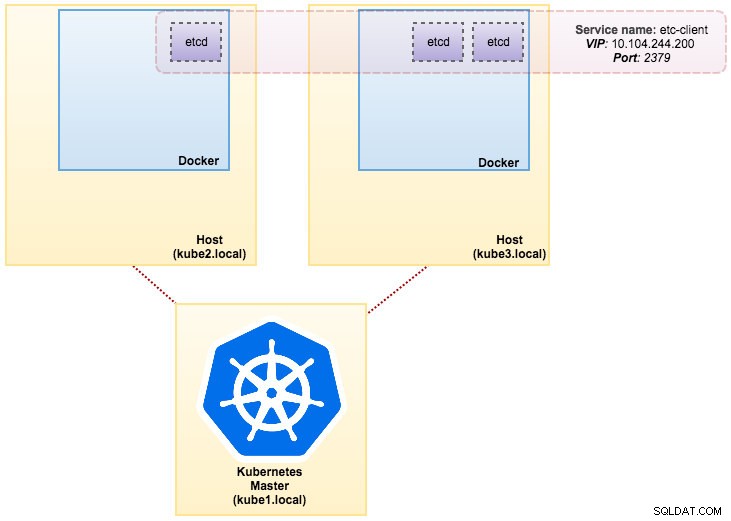
A imagem que construímos requer um etcd (independente ou cluster) para descoberta de serviço. Para executar um cluster etcd requer que cada instância etcd esteja sendo executada com comandos diferentes, então usaremos o controlador Pods em vez de Deployment e criaremos um serviço chamado “etcd-client” como endpoint para os pods etcd. O arquivo de definição etcd-cluster.yaml diz tudo.
Para implantar um cluster etcd de 3 pods, basta executar:
$ kubectl create -f etcd-cluster.yamlVerifique se o cluster etcd está pronto:
$ kubectl get po,svc
NAME READY STATUS RESTARTS AGE
po/etcd0 1/1 Running 0 1d
po/etcd1 1/1 Running 0 1d
po/etcd2 1/1 Running 0 1d
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
svc/etcd-client 10.104.244.200 <none> 2379/TCP 1d
svc/etcd0 10.100.24.171 <none> 2379/TCP,2380/TCP 1d
svc/etcd1 10.108.207.7 <none> 2379/TCP,2380/TCP 1d
svc/etcd2 10.101.9.115 <none> 2379/TCP,2380/TCP 1dNossa arquitetura agora está mais ou menos assim:
 Vários MySQL no Docker:como conteinerizar seu banco de dadosDescubra tudo o que você precisa entender ao considerar executar um serviço MySQL em topo da virtualização de contêiner do DockerBaixe o white paper
Vários MySQL no Docker:como conteinerizar seu banco de dadosDescubra tudo o que você precisa entender ao considerar executar um serviço MySQL em topo da virtualização de contêiner do DockerBaixe o white paper Usando ReplicaSet
Um ReplicaSet garante que um número específico de “réplicas” de pod esteja em execução a qualquer momento. No entanto, uma implantação é um conceito de nível superior que gerencia ReplicaSets e fornece atualizações declarativas para pods junto com muitos outros recursos úteis. Portanto, é recomendável usar Deployments em vez de usar ReplicaSets diretamente, a menos que você precise de orquestração de atualização personalizada ou não precise de atualizações. Ao usar Deployments, você não precisa se preocupar em gerenciar os ReplicaSets que eles criam. As implantações possuem e gerenciam seus ReplicaSets.
Em nosso caso, usaremos Deployment como o controlador de carga de trabalho, conforme mostrado nesta definição YAML. Podemos criar diretamente o Galera Cluster ReplicaSet and Service executando o seguinte comando:
$ kubectl create -f mariadb-rs.ymlVerifique se o cluster está pronto observando o ReplicaSet (rs), pods (po) e serviços (svc):
$ kubectl get rs,po,svc
NAME DESIRED CURRENT READY AGE
rs/galera-251551564 3 3 3 5h
NAME READY STATUS RESTARTS AGE
po/etcd0 1/1 Running 0 1d
po/etcd1 1/1 Running 0 1d
po/etcd2 1/1 Running 0 1d
po/galera-251551564-8c238 1/1 Running 0 5h
po/galera-251551564-swjjl 1/1 Running 1 5h
po/galera-251551564-z4sgx 1/1 Running 1 5h
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
svc/etcd-client 10.104.244.200 <none> 2379/TCP 1d
svc/etcd0 10.100.24.171 <none> 2379/TCP,2380/TCP 1d
svc/etcd1 10.108.207.7 <none> 2379/TCP,2380/TCP 1d
svc/etcd2 10.101.9.115 <none> 2379/TCP,2380/TCP 1d
svc/galera-rs 10.107.89.109 <nodes> 3306:30000/TCP 5h
svc/kubernetes 10.96.0.1 <none> 443/TCP 1dA partir da saída acima, podemos ilustrar nossos Pods e Serviço conforme abaixo:
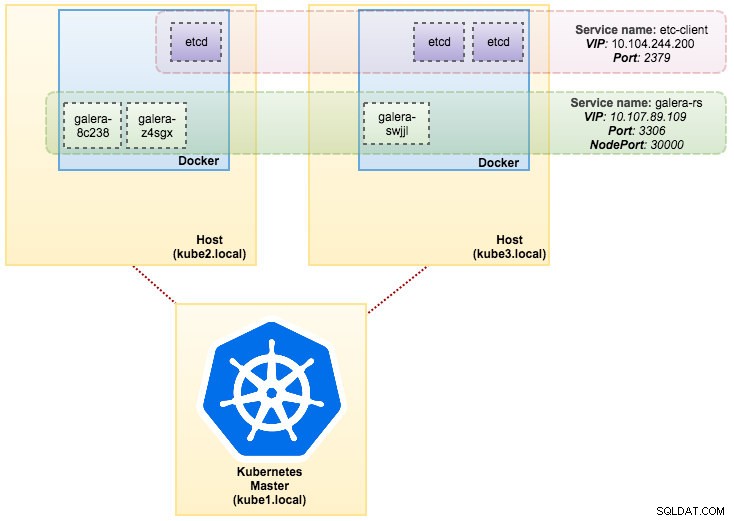
A execução do Galera Cluster no ReplicaSet é semelhante a tratá-lo como um aplicativo sem estado. Ele orquestra a criação, exclusão e atualizações de pods e pode ser direcionado para Horizontal Pod Autoscales (HPA), ou seja, um ReplicaSet pode ser dimensionado automaticamente se atender a determinados limites ou destinos (uso da CPU, pacotes por segundo, solicitação por segundo etc).
Se um dos nós do Kubernetes ficar inativo, novos pods serão agendados em um nó disponível para atender às réplicas desejadas. Os volumes associados ao Pod serão excluídos se o Pod for excluído ou reprogramado. O nome do host do pod será gerado aleatoriamente, dificultando o rastreamento de onde o contêiner pertence simplesmente observando o nome do host.
Tudo isso funciona muito bem em ambientes de teste e preparação, onde você pode executar um ciclo de vida completo do contêiner, como implantar, dimensionar, atualizar e destruir sem dependências. O escalonamento para cima e para baixo é simples, atualizando o arquivo YAML e postando-o no cluster Kubernetes ou usando o comando scale:
$ kubectl scale replicaset galera-rs --replicas=5Usando StatefulSet
Conhecido como PetSet na versão pré 1.6, o StatefulSet é a melhor maneira de implantar o Galera Cluster em produção, pois:
- Excluir e/ou reduzir um StatefulSet não excluirá os volumes associados ao StatefulSet. Isso é feito para garantir a segurança dos dados, que geralmente é mais valioso do que uma limpeza automática de todos os recursos StatefulSet relacionados.
- Para um StatefulSet com N réplicas, quando os pods estão sendo implantados, eles são criados sequencialmente, na ordem de {0 .. N-1 }.
- Quando os pods estão sendo excluídos, eles são encerrados na ordem inversa, de {N-1 .. 0}.
- Antes de uma operação de dimensionamento ser aplicada a um pod, todos os seus predecessores devem estar em execução e prontos.
- Antes que um pod seja encerrado, todos os seus sucessores devem ser completamente encerrados.
StatefulSet fornece suporte de primeira classe para contêineres com estado. Ele fornece uma garantia de implantação e dimensionamento. Quando um Galera Cluster de três nós é criado, três Pods serão implantados na ordem db-0, db-1, db-2. db-1 não será implementado antes de db-0 estar “Running and Ready”, e db-2 não será implementado até db-1 estar “Running and Ready”. Se o db-0 falhar, após o db-1 estar “Running and Ready”, mas antes do db-2 ser iniciado, o db-2 não será iniciado até que o db-0 seja reiniciado com sucesso e se torne “Running and Ready”.
Vamos usar a implementação do Kubernetes de armazenamento persistente chamado PersistentVolume e PersistentVolumeClaim. Isso para garantir a persistência dos dados se o pod for reprogramado para o outro nó. Embora o Galera Cluster forneça a cópia exata dos dados em cada réplica, ter os dados persistentes em cada pod é bom para fins de solução de problemas e recuperação.
Para criar um armazenamento persistente, primeiro temos que criar PersistentVolume para cada pod. PVs são plugins de volume como Volumes no Docker, mas têm um ciclo de vida independente de qualquer pod individual que use o PV. Como vamos implantar um Galera Cluster de 3 nós, precisamos criar 3 PVs:
apiVersion: v1
kind: PersistentVolume
metadata:
name: datadir-galera-0
labels:
app: galera-ss
podindex: "0"
spec:
accessModes:
- ReadWriteOnce
capacity:
storage: 10Gi
hostPath:
path: /data/pods/galera-0/datadir
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: datadir-galera-1
labels:
app: galera-ss
podindex: "1"
spec:
accessModes:
- ReadWriteOnce
capacity:
storage: 10Gi
hostPath:
path: /data/pods/galera-1/datadir
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: datadir-galera-2
labels:
app: galera-ss
podindex: "2"
spec:
accessModes:
- ReadWriteOnce
capacity:
storage: 10Gi
hostPath:
path: /data/pods/galera-2/datadirA definição acima mostra que vamos criar 3 PV, mapeados para o caminho físico dos nós do Kubernetes com 10 GB de espaço de armazenamento. Definimos ReadWriteOnce, o que significa que o volume pode ser montado como leitura-gravação por apenas um único nó. Salve as linhas acima em mariadb-pv.yml e poste no Kubernetes:
$ kubectl create -f mariadb-pv.yml
persistentvolume "datadir-galera-0" created
persistentvolume "datadir-galera-1" created
persistentvolume "datadir-galera-2" createdEm seguida, defina os recursos PersistentVolumeClaim:
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: mysql-datadir-galera-ss-0
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
selector:
matchLabels:
app: galera-ss
podindex: "0"
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: mysql-datadir-galera-ss-1
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
selector:
matchLabels:
app: galera-ss
podindex: "1"
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: mysql-datadir-galera-ss-2
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
selector:
matchLabels:
app: galera-ss
podindex: "2"A definição acima mostra que gostaríamos de reivindicar os recursos PV e usar o spec.selector.matchLabels para procurar nosso PV (metadata.labels.app:galera-ss ) com base no respectivo índice de pod (metadata.labels.podindex ) atribuído pelo Kubernetes. O metadata.name O recurso deve usar o formato “{volumeMounts.name}-{pod}-{ordinal index}” definido em spec.templates.containers para que o Kubernetes saiba qual ponto de montagem mapear a declaração no pod.
Salve as linhas acima em mariadb-pvc.yml e poste no Kubernetes:
$ kubectl create -f mariadb-pvc.yml
persistentvolumeclaim "mysql-datadir-galera-ss-0" created
persistentvolumeclaim "mysql-datadir-galera-ss-1" created
persistentvolumeclaim "mysql-datadir-galera-ss-2" createdNosso armazenamento persistente está pronto. Podemos então iniciar a implantação do Galera Cluster criando um recurso StatefulSet junto com o recurso de serviço Headless, conforme mostrado em mariadb-ss.yml:
$ kubectl create -f mariadb-ss.yml
service "galera-ss" created
statefulset "galera-ss" createdAgora, recupere o resumo de nossa implantação do StatefulSet:
$ kubectl get statefulsets,po,pv,pvc -o wide
NAME DESIRED CURRENT AGE
statefulsets/galera-ss 3 3 1d galera severalnines/mariadb:10.1 app=galera-ss
NAME READY STATUS RESTARTS AGE IP NODE
po/etcd0 1/1 Running 0 7d 10.36.0.1 kube3.local
po/etcd1 1/1 Running 0 7d 10.44.0.2 kube2.local
po/etcd2 1/1 Running 0 7d 10.36.0.2 kube3.local
po/galera-ss-0 1/1 Running 0 1d 10.44.0.4 kube2.local
po/galera-ss-1 1/1 Running 1 1d 10.36.0.5 kube3.local
po/galera-ss-2 1/1 Running 0 1d 10.44.0.5 kube2.local
NAME CAPACITY ACCESSMODES RECLAIMPOLICY STATUS CLAIM STORAGECLASS REASON AGE
pv/datadir-galera-0 10Gi RWO Retain Bound default/mysql-datadir-galera-ss-0 4d
pv/datadir-galera-1 10Gi RWO Retain Bound default/mysql-datadir-galera-ss-1 4d
pv/datadir-galera-2 10Gi RWO Retain Bound default/mysql-datadir-galera-ss-2 4d
NAME STATUS VOLUME CAPACITY ACCESSMODES STORAGECLASS AGE
pvc/mysql-datadir-galera-ss-0 Bound datadir-galera-0 10Gi RWO 4d
pvc/mysql-datadir-galera-ss-1 Bound datadir-galera-1 10Gi RWO 4d
pvc/mysql-datadir-galera-ss-2 Bound datadir-galera-2 10Gi RWO 4dNeste ponto, nosso Galera Cluster rodando em StatefulSet pode ser ilustrado como no diagrama a seguir:
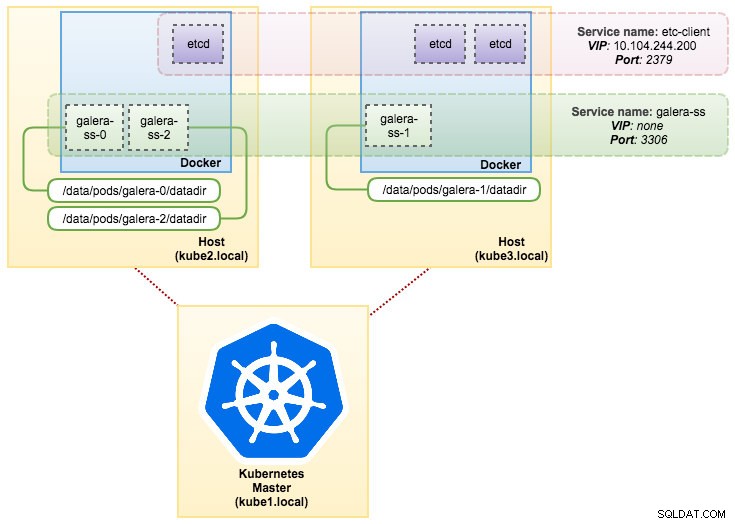
A execução no StatefulSet garante identificadores consistentes, como nome do host, endereço IP, ID da rede, domínio do cluster, Pod DNS e armazenamento. Isso permite que o Pod se diferencie facilmente de outros em um grupo de Pods. O volume será retido no host e não será excluído se o Pod for excluído ou reprogramado em outro nó. Isso permite a recuperação de dados e reduz o risco de perda total de dados.
Do lado negativo, o tempo de implantação será N-1 vezes (N =réplicas) por mais tempo porque o Kubernetes obedecerá à sequência ordinal ao implantar, reprogramar ou excluir os recursos. Seria um pouco trabalhoso preparar o PV e as declarações antes de pensar em dimensionar seu cluster. Observe que a atualização de um StatefulSet existente é atualmente um processo manual, onde você só pode atualizar spec.replicas no momento.
Conectando-se ao Galera Cluster Service e aos pods
Há algumas maneiras de se conectar ao cluster de banco de dados. Você pode se conectar diretamente à porta. No exemplo do serviço “galera-rs”, usamos o NodePort, expondo o serviço no IP de cada Node em uma porta estática (o NodePort). Um serviço ClusterIP, para o qual o serviço NodePort será roteado, é criado automaticamente. Você poderá entrar em contato com o serviço NodePort, de fora do cluster, solicitando {NodeIP}:{NodePort} .
Exemplo de conexão externa ao Galera Cluster:
(external)$ mysql -udb_user -ppassword -h192.168.55.141 -P30000
(external)$ mysql -udb_user -ppassword -h192.168.55.142 -P30000
(external)$ mysql -udb_user -ppassword -h192.168.55.143 -P30000No espaço de rede do Kubernetes, os pods podem se conectar internamente por meio do IP do cluster ou do nome do serviço, que pode ser recuperado usando o seguinte comando:
$ kubectl get services -o wide
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
etcd-client 10.104.244.200 <none> 2379/TCP 1d app=etcd
etcd0 10.100.24.171 <none> 2379/TCP,2380/TCP 1d etcd_node=etcd0
etcd1 10.108.207.7 <none> 2379/TCP,2380/TCP 1d etcd_node=etcd1
etcd2 10.101.9.115 <none> 2379/TCP,2380/TCP 1d etcd_node=etcd2
galera-rs 10.107.89.109 <nodes> 3306:30000/TCP 4h app=galera-rs
galera-ss None <none> 3306/TCP 3m app=galera-ss
kubernetes 10.96.0.1 <none> 443/TCP 1d <none>Na lista de serviços, podemos ver que o Galera Cluster ReplicaSet Cluster-IP é 10.107.89.109. Internamente, outro pod pode acessar o banco de dados por meio desse endereço IP ou nome de serviço usando a porta exposta, 3306:
(etcd0 pod)$ mysql -udb_user -ppassword -hgalera-rs -P3306 -e 'select @@hostname'
+------------------------+
| @@hostname |
+------------------------+
| galera-251551564-z4sgx |
+------------------------+Você também pode se conectar ao NodePort externo de dentro de qualquer pod na porta 30000:
(etcd0 pod)$ mysql -udb_user -ppassword -h192.168.55.143 -P30000 -e 'select @@hostname'
+------------------------+
| @@hostname |
+------------------------+
| galera-251551564-z4sgx |
+------------------------+A conexão com os pods de back-end será balanceada de acordo com o algoritmo de conexão mínimo.
Resumo
Neste ponto, executar o Galera Cluster no Kubernetes em produção parece muito mais promissor em comparação com o Docker Swarm. Conforme discutido na última postagem do blog, as preocupações levantadas são abordadas de maneira diferente com a maneira como o Kubernetes orquestra os contêineres no StatefulSet (embora ainda seja um recurso beta na v1.6). Esperamos que a abordagem sugerida ajude a executar o Galera Cluster em contêineres em escala na produção.