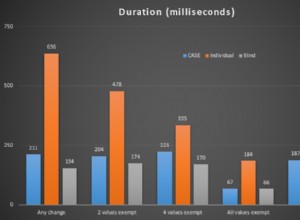
Algumas semanas atrás, comecei a configurar um ambiente de demonstração com várias configurações de Grupos de Disponibilidade AlwaysOn. Eu tinha um cluster WSFC de 5 nós – cada nó tinha uma instância nomeada autônoma do SQL Server 2012 e também havia duas instâncias de cluster de failover (FCIs) configuradas sobre esses nós. Um diagrama rápido:
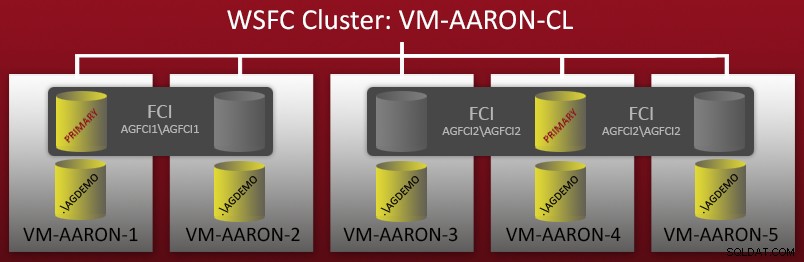
Assim, você pode ver que existem 5 instâncias nomeadas independentes (
.\AGDEMO em cada nó) e, em seguida, duas FCIs – uma com possíveis proprietários VM-AARON-1 e VM-AARON-2 (AGFCI1\AGFCI1 ), e depois um com possíveis proprietários VM-AARON-3, VM-AARON-4 e VM-AARON-5 (AGFCI2\AGFCI2 ). Agora, diagramar isso manualmente teria que ficar significativamente mais complexo (mais sobre isso depois), então vou evitá-lo por razões óbvias. Essencialmente, o requisito era ter vários tipos de configurações de AG:- Primário em uma FCI com uma réplica em uma ou mais instâncias independentes
- Primário em uma FCI com uma réplica em uma FCI diferente
- Primário em uma instância autônoma com uma réplica em uma ou mais FCIs
- Primário em uma instância autônoma com uma réplica em uma ou mais instâncias autônomas
- Primário em uma instância autônoma com réplicas em instâncias autônomas e FCIs
E, em seguida, combinações (quando possível) de confirmação síncrona versus assíncrona, failover manual versus automático e secundários somente leitura. Existem algumas limitações técnicas que limitariam as permutações possíveis aqui, por exemplo:
- O failover manual é necessário com qualquer réplica que esteja em uma FCI
- Nenhum nó WSFC pode hospedar – ou mesmo ser possível proprietário de – várias instâncias, sejam independentes ou em cluster, que estejam envolvidas no mesmo Grupo de Disponibilidade. Você recebe esta mensagem de erro:Falha ao criar, ingressar ou adicionar réplica ao grupo de disponibilidade 'MyGroup', porque o nó 'VM-AARON-1' é um possível proprietário para a réplica 'AGFCI1\AGFCI1' e 'VM-AARON-1\ AGDEMO'. Se uma réplica for uma instância de cluster de failover, remova o nó sobreposto de seus possíveis proprietários e tente novamente. (Microsoft SQL Server, erro:19405)
A maioria dos cenários que eu estava tentando representar não são práticos em cenários do mundo real, mas são em grande parte e teoricamente possíveis . Se você ainda não adivinhou, esse ambiente está sendo configurado explicitamente para testar novas funcionalidades em torno dos Grupos de Disponibilidade que planejamos oferecer em uma versão futura do SQL Sentry. Demos uma prévia de algumas dessas tecnologias durante nossa palestra com o Fusion-io na recente conferência SQL Intersection em Las Vegas.
Obstáculo nº 1
Configurar grupos de disponibilidade usando o assistente no SSMS é muito fácil. A menos que, por exemplo, você tenha caminhos de arquivo heterogêneos. O assistente tem validação que garante que os mesmos dados e caminhos de log existam em todas as réplicas. Isso pode ser um problema se você estiver usando o caminho de dados padrão para duas instâncias nomeadas diferentes ou se tiver configurações de letras de unidade diferentes (o que geralmente acontecerá quando FCIs estiverem envolvidos).
A verificação da compatibilidade do local do arquivo de banco de dados na réplica secundária resultou em um erro. (Microsoft.SqlServer.Management.HadrTasks)
Os seguintes locais de pasta não existem na instância do servidor que hospeda a réplica secundária VM-AARON-1\AGDEMO:
P:\MSSQL11.AGFCI2\MSSQL\DATA;
(Microsoft.SqlServer.Management.HadrTasks)
Agora, não é preciso dizer que você não deseja configurar esse cenário em nenhum tipo de ambiente que precise resistir ao teste do tempo. As coisas vão dar errado muito rapidamente se, por exemplo, você adicionar mais tarde um novo arquivo a um dos bancos de dados. Mas para um ambiente de teste/demonstração, prova de conceito ou um ambiente que você espera ser estável por um tempo considerável, não se preocupe:você ainda pode fazer isso sem o assistente.
Infelizmente, para adicionar insulto à injúria, o assistente não permite que você faça o script. Você não pode passar do erro de validação e não há
Script botão: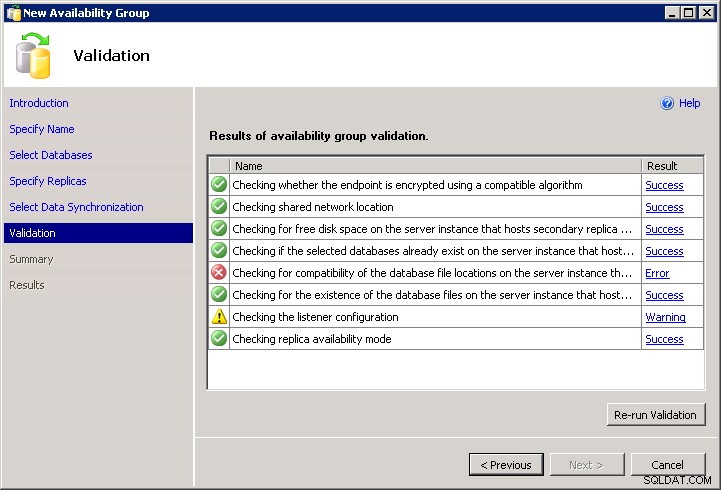
Portanto, isso significa que você precisa codificá-lo (já que o DDL não executa nenhuma validação "útil" para você). Se houver outras instâncias em que existam os mesmos caminhos, você pode fazer isso seguindo o mesmo assistente, passando pela tela de validação e clicando em
Script em vez de Finish , e altere o(s) nome(s) do servidor e adicione com WITH MOVE opções para a restauração inicial. Ou você pode simplesmente escrever o seu próprio do zero, algo assim (o script pressupõe que você já tenha os endpoints e permissões configurados e que todas as instâncias tenham o recurso Grupos de disponibilidade ativado):-- Use SQLCMD mode and uncomment the :CONNECT commands
-- or just run the two segments separately / change connection
-- :CONNECT Server1
CREATE AVAILABILITY GROUP [GroupName]
WITH (AUTOMATED_BACKUP_PREFERENCE = SECONDARY)
FOR DATABASE [Database1] --, ...
REPLICA ON -- primary:
N'Server1' WITH (ENDPOINT_URL = N'TCP://Server1:5022',
FAILOVER_MODE = MANUAL, AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
BACKUP_PRIORITY = 50, SECONDARY_ROLE(ALLOW_CONNECTIONS = NO)),
-- secondary:
N'Server2' WITH (ENDPOINT_URL = N'TCP://Server2:5022',
FAILOVER_MODE = MANUAL, AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
BACKUP_PRIORITY = 50, SECONDARY_ROLE(ALLOW_CONNECTIONS = NO));
ALTER AVAILABILITY GROUP [GroupName]
ADD LISTENER N'ListenerName'
(WITH IP ((N'10.x.x.x', N'255.255.255.0')), PORT=1433);
BACKUP DATABASE Database1 TO DISK = '\\Server1\Share\db1.bak'
WITH INIT, COPY_ONLY, COMPRESSION;
BACKUP LOG Database1 TO DISK = '\\Server1\Share\db1.trn'
WITH INIT, COMPRESSION;
-- :CONNECT Server2
ALTER AVAILABILITY GROUP [GroupName] JOIN;
RESTORE DATABASE Database1 FROM DISK = '\\Server1\Share\db1.bak'
WITH REPLACE, NORECOVERY, NOUNLOAD,
MOVE 'data_file_name' TO 'P:\path\file.mdf',
MOVE 'log_file_name' TO 'P:\path\file.ldf';
RESTORE LOG Database1 FROM DISK = '\\Server1\Share\db1.trn'
WITH NORECOVERY, NOUNLOAD;
ALTER DATABASE Database1 SET HADR AVAILABILITY GROUP = [GroupName]; Obstáculo nº 2
Se você tiver várias instâncias no mesmo servidor, poderá descobrir que ambas as instâncias não podem compartilhar a porta 5022 para o endpoint de espelhamento de banco de dados (que é o mesmo endpoint usado pelos grupos de disponibilidade). Isso significa que você terá que descartar e recriar o endpoint para defini-lo como uma porta disponível.
DROP ENDPOINT [Hadr_endpoint];
GO
CREATE ENDPOINT [Hadr_endpoint]
STATE = STARTED
AS TCP ( LISTENER_PORT = 5023 )
FOR DATABASE_MIRRORING (ROLE = ALL); Agora eu poderia especificar uma instância com um endpoint em
ServerName:5023 . Obstáculo nº 3
No entanto, uma vez que eu fiz isso, quando cheguei à última etapa do script acima, após exatamente 48 segundos - todas as vezes -, recebi esta mensagem de erro inútil:
Msg 35250, Level 16, State 7, Line 2
A conexão com a réplica primária não está ativa. O comando não pode ser processado.
Isso me fez perseguir todos os tipos de problemas em potencial – verificando firewalls e o SQL Server Configuration Manager, por exemplo, para qualquer coisa que estivesse bloqueando as portas entre as instâncias. Nada. Encontrei vários erros no log de erros do SQL Server:
Falha na tentativa de login do espelhamento de banco de dados com erro:'Falha no handshake de conexão. Não há algoritmo de criptografia compatível. Estado 22.'.
Falha na tentativa de login do espelhamento de banco de dados com erro:'Falha no handshake de conexão. Uma chamada do SO falhou:(80090303) 0x80090303(O destino especificado é desconhecido ou inacessível). Estado 66.'.
Ocorreu um tempo limite de conexão ao tentar estabelecer uma conexão com a réplica de disponibilidade 'VM-AARON-1\AGDEMO' com ID [5AF5B58D-BBD5-40BB-BE69-08AC50010BE0]. Existe um problema de rede ou firewall ou o endereço do endpoint fornecido para a réplica não é o endpoint de espelhamento de banco de dados da instância do servidor host.
Acontece (e graças a Thomas Stringer (@SQLife)) que esse problema estava sendo causado por uma combinação de sintomas:(a) Kerberos não foi configurado corretamente e (b) o algoritmo de criptografia para o hadr_endpoint que eu criei padrão para RC4. Isso seria bom se todas as instâncias autônomas também estivessem usando RC4, mas não estavam. Para encurtar a história, larguei e recriei os endpoints novamente , em todas as instâncias. Como esse era um ambiente de laboratório e eu realmente não precisava de suporte ao Kerberos (e porque já havia investido tempo suficiente nesses problemas e não queria perseguir os problemas do Kerberos também), configurei todos os endpoints para usar Negotiate com AES:
DROP ENDPOINT [Hadr_endpoint];
GO
CREATE ENDPOINT [Hadr_endpoint]
STATE = STARTED
AS TCP ( LISTENER_PORT = 5023 )
FOR DATABASE_MIRRORING (
AUTHENTICATION = WINDOWS NEGOTIATE,
ENCRYPTION = REQUIRED ALGORITHM AES,
ROLE = ALL); (Ted Krueger (@onpnt) também postou recentemente sobre um problema semelhante.)
Agora, finalmente, consegui criar grupos de disponibilidade com todos os vários requisitos que eu tinha, entre nós com caminhos de arquivos heterogêneos e utilizando várias instâncias no mesmo nó (mas não no mesmo grupo). Aqui está uma prévia de como será uma de nossas visualizações AlwaysOn Management (clique para ampliar para uma visão muito melhor):
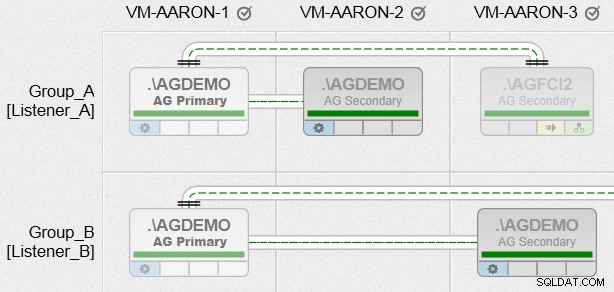
Agora, isso é apenas uma provocação, e é totalmente intencional. Estarei blogando mais sobre essa funcionalidade nas próximas semanas!
Conclusão
Quando você passa tempo suficiente olhando para um problema, pode ignorar algumas coisas bastante óbvias. Nesse caso, havia alguns problemas óbvios ocultos por algumas mensagens de erro francamente não intuitivas. Quero agradecer a Joe Sack (@JosephSack), Allan Hirt (@SQLHA) e Thomas Stringer (@SQLife) por deixarem tudo para ajudar um membro da comunidade em necessidade.