Introdução à coleta em massa PL/SQL
Uma consulta bem estruturada, escrita hoje, pode salvá-lo de eventos catastróficos no futuro. O desempenho da consulta é algo que todos procuramos, mas poucos realmente o encontram. Aprender pequenos conceitos pode ajudá-lo a ganhar experiência, o que pode levar a uma melhor habilidade de escrita de consultas. Hoje neste blog você vai aprender um desses pequenos conceitos que é o “Coleta em Massa ”.
A coleta em massa visa reduzir as alterações de contexto e melhorando o desempenho da consulta. Assim, para entender o que é coleta em massa, precisamos primeiro aprender o que é Mudança de contexto ?
O que é troca de contexto?
Sempre que você escreve um bloco PL/SQL ou diz um programa PL/SQL e o executa, o mecanismo de tempo de execução PL/SQL começa a processá-lo linha por linha. Esse mecanismo processa todas as instruções PL/SQL sozinho, mas passa todas as instruções SQL que você codificou nesse bloco PL/SQL para o mecanismo de tempo de execução SQL. Essas instruções SQL serão processadas separadamente pelo mecanismo SQL. Assim que terminar de processá-los, o mecanismo SQL retorna o resultado de volta ao mecanismo PL/SQL. Para que um resultado combinado possa ser produzido por este último. Esse salto de controle para lá e para cá é chamado de mudança de contexto.
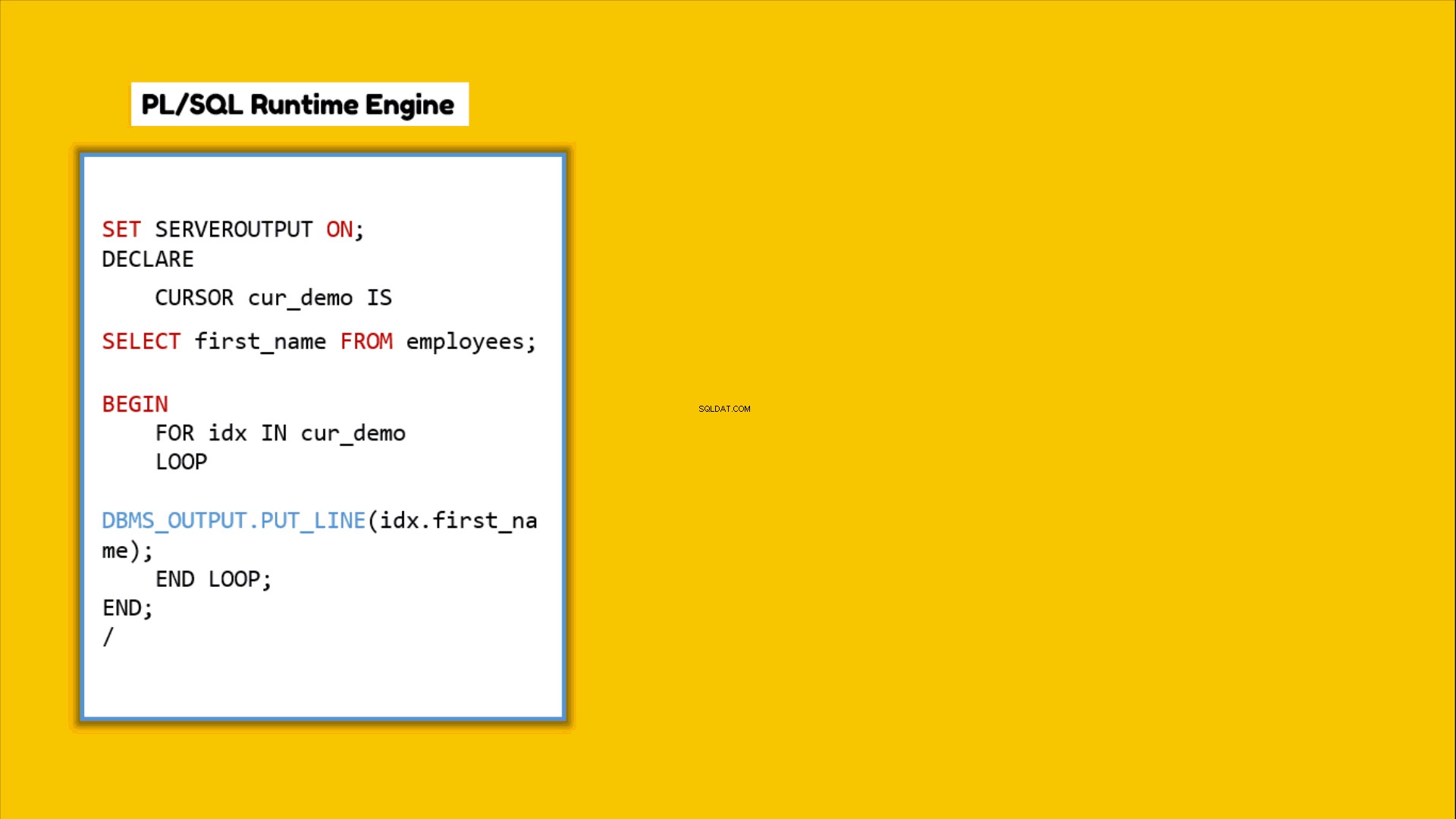
Como a mudança de contexto afeta o desempenho da consulta?
A alternância de contexto tem um impacto direto no desempenho da consulta. Quanto maior o salto dos controles, maior será a sobrecarga que, por sua vez, degradará o desempenho. Isso significa que quanto menor a troca de contexto, melhor será o desempenho da consulta.
Agora você deve estar pensando “Não podemos fazer algo sobre isso?” Podemos reduzir essas transições de controle? Existe alguma maneira de reduzir as trocas de contexto? A resposta para todas essas perguntas é sim, temos uma opção que pode nos ajudar. Essa opção é a cláusula de coleta em massa .
O que é a cláusula de coleta em massa?
A cláusula de coleta em massa compacta vários switches em um único switch de contexto e aumenta a eficiência e o desempenho de um programa PL/SQL.
A cláusula de coleta em massa reduz o salto de controle múltiplo coletando todas as chamadas de instrução SQL do programa PL/SQL e enviando-as para o SQL Engine de uma só vez e vice-versa.
Onde podemos usar a cláusula de coleta em massa?
A cláusula de coleta em massa pode ser usada com as cláusulas SELECT-INTO, FETCH-INTO e RETURN-INTO.
Com a ajuda do Bulk Collect Statement, podemos SELECT, INSERT, UPDATE ou DELETE grandes conjuntos de dados de objetos de banco de dados, como Tabelas ou Exibições.
O que é processamento de dados em massa?
O processo de buscar lotes de dados do mecanismo de tempo de execução PL/SQL para o mecanismo SQL e vice-versa é chamado de Processamento de Dados em Massa.
Quantas instruções de processamento de dados em massa temos?
Temos uma cláusula de processamento de dados em massa que é a coleta em massa e uma declaração de processamento de dados em massa que é FORALL no banco de dados Oracle.
Ouvi dizer que a cláusula de coleta em massa usa cursores implícitos e explícitos?
Sim, você ouviu direito. Podemos usar a cláusula de coleta em massa dentro de uma instrução SQL ou com a instrução FETCH. Quando usamos a cláusula de coleta em massa com a instrução SQL, ou seja, SELECT INTO, ela usa o cursor implícito. Considerando que, se usarmos a cláusula de coleta em massa com a instrução FETCH, ela usará o cursor explícito.
Esta foi uma introdução rápida à primeira cláusula de processamento de dados em massa PL/SQL, que é BULK COLLECT. Aprenderemos sobre a segunda instrução de processamento de dados em massa assim que terminarmos com a primeira. Enquanto isso, certifique-se de se inscrever em nosso canal do YouTube, porque no próximo tutorial aprenderemos como podemos melhorar a eficiência de uma instrução SQL usando uma cláusula Bulk Collect.
Obrigado e tenha um ótimo dia!