O SQL Server 2008 introduziu colunas esparsas como um método para reduzir o armazenamento para valores nulos e fornecer esquemas mais extensíveis. A desvantagem é que há sobrecarga adicional quando você armazena e recupera valores não NULL. Eu estava interessado em entender o custo para armazenar valores não NULL, depois de conversar com um cliente que estava usando esse tipo de dados em um ambiente de teste. Eles estão procurando otimizar o desempenho de gravação, e eu me perguntei se o uso de colunas esparsas teve algum efeito, pois o método deles exigia inserir uma linha na tabela e depois atualizá-la. Eu criei um exemplo artificial para esta demonstração, explicado abaixo, para determinar se essa era uma boa metodologia para eles usarem.
Revisão Interna
Como uma revisão rápida, lembre-se de que quando você cria uma coluna para uma tabela que permite valores NULL, se for uma coluna de comprimento fixo (por exemplo, um INT), ela sempre consumirá toda a largura da coluna na página, mesmo quando a coluna for NULO. Se for uma coluna de comprimento variável (por exemplo, VARCHAR), consumirá pelo menos dois bytes na matriz de deslocamento da coluna quando NULL, a menos que as colunas estejam após a última coluna preenchida (consulte a postagem do blog de Kimberly A ordem das colunas não importa… geralmente , mas – DEPENDE). Uma coluna esparsa não requer nenhum espaço na página para valores NULL, seja uma coluna de comprimento fixo ou variável e independentemente de quais outras colunas são preenchidas na tabela. A desvantagem é que quando uma coluna esparsa é preenchida, são necessários quatro (4) bytes a mais de armazenamento do que uma coluna não esparsa. Por exemplo:
| Tipo de coluna | Requisito de armazenamento |
|---|---|
| Coluna BIGINT, não esparsa, com não valor | 8 bytes |
| Coluna BIGINT, não esparsa, com um valor | 8 bytes |
| Coluna BIGINT, esparsa, com não valor | 0 bytes |
| Coluna BIGINT, esparsa, com um valor | 12 bytes |
Portanto, é essencial confirmar que o benefício de armazenamento supera o possível impacto no desempenho da recuperação – que pode ser insignificante com base no equilíbrio de leituras e gravações em relação aos dados. A economia de espaço estimada para diferentes tipos de dados está documentada no link Manuais Online fornecido acima.
Cenários de teste
Configurei quatro cenários diferentes para teste, descritos abaixo, e cada tabela tinha uma coluna ID (INT), uma coluna Name (VARCHAR(100)) e uma coluna Type (INT) e, em seguida, 997 colunas NULLABLE.
| ID do teste | Descrição da tabela | Operações DML |
|---|---|---|
| 1 | 997 colunas do tipo de dados INT, NULLABLE, não esparsas | Insira uma linha por vez, preenchendo ID, Nome, Tipo e dez (10) colunas NULLABLE aleatórias |
| 2 | 997 colunas do tipo de dados INT, NULLABLE, esparsas | Insira uma linha por vez, preenchendo ID, Nome, Tipo e dez (10) colunas NULLABLE aleatórias |
| 3 | 997 colunas do tipo de dados INT, NULLABLE, não esparsas | Insira uma linha de cada vez, preenchendo ID, Nome, Tipo apenas e, em seguida, atualize a linha, adicionando valores para dez (10) colunas NULLABLE aleatórias |
| 4 | 997 colunas do tipo de dados INT, NULLABLE, esparsas | Insira uma linha de cada vez, preenchendo ID, Nome, Tipo apenas e, em seguida, atualize a linha, adicionando valores para dez (10) colunas NULLABLE aleatórias |
| 5 | 997 colunas de tipo de dados VARCHAR, NULLABLE, não esparsas | Insira uma linha por vez, preenchendo ID, Nome, Tipo e dez (10) colunas NULLABLE aleatórias |
| 6 | 997 colunas de tipo de dados VARCHAR, NULLABLE, esparsas | Insira uma linha por vez, preenchendo ID, Nome, Tipo e dez (10) colunas NULLABLE aleatórias |
| 7 | 997 colunas de tipo de dados VARCHAR, NULLABLE, não esparsas | Insira uma linha de cada vez, preenchendo ID, Nome, Tipo apenas e, em seguida, atualize a linha, adicionando valores para dez (10) colunas NULLABLE aleatórias |
| 8 | 997 colunas de tipo de dados VARCHAR, NULLABLE, esparsas | Insira uma linha de cada vez, preenchendo ID, Nome, Tipo apenas e, em seguida, atualize a linha, adicionando valores para dez (10) colunas NULLABLE aleatórias |
Cada teste foi executado duas vezes com um conjunto de dados de 10 milhões de linhas. Os scripts anexados podem ser usados para replicar testes, e as etapas foram as seguintes para cada teste:
- Crie um novo banco de dados com dados e arquivos de log pré-dimensionados
- Crie a tabela apropriada
- Estatísticas de espera de instantâneos e estatísticas de arquivos
- Anote a hora de início
- Execute o DML (uma inserção ou uma inserção e uma atualização) para 10 milhões de linhas
- Observe o tempo de parada
- Capturar estatísticas de espera e estatísticas de arquivos e gravar em uma tabela de registro em um banco de dados separado em armazenamento separado
- Instantâneo dm_db_index_physical_stats
- Solte o banco de dados
O teste foi feito em um Dell PowerEdge R720 com 64 GB de memória e 12 GB alocados para a instância do SQL Server 2014 SP1 CU4. Os SSDs Fusion-IO foram usados para armazenamento de dados para os arquivos de banco de dados.
Resultados
Os resultados do teste são apresentados abaixo para cada cenário de teste.
Duração
Em todos os casos, levou menos tempo (média de 11,6 minutos) para preencher a tabela quando colunas esparsas foram usadas, mesmo quando a linha foi inserida pela primeira vez e depois atualizada. Quando a linha foi inserida pela primeira vez e depois atualizada, o teste levou quase o dobro do tempo para ser executado em comparação com quando a linha foi inserida, pois o dobro de modificações de dados foi executada.
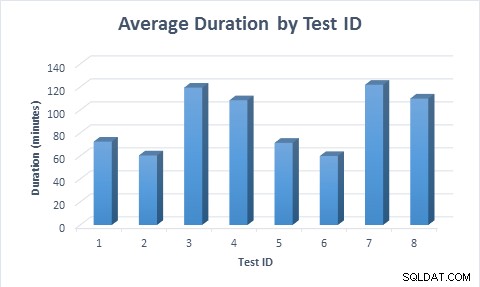 Duração média para cada cenário de teste
Duração média para cada cenário de teste Estatísticas de espera
| ID do teste | Porcentagem média | Espera média (segundos) |
|---|---|---|
| 1 | 16,47 | 0,0001 |
| 2 | 14h00 | 0,0001 |
| 3 | 16,65 | 0,0001 |
| 4 | 15.07 | 0,0001 |
| 5 | 12,80 | 0,0001 |
| 6 | 13,99 | 0,0001 |
| 7 | 14,85 | 0,0001 |
| 8 | 15.02 | 0,0001 |
As estatísticas de espera foram consistentes para todos os testes e nenhuma conclusão pode ser feita com base nesses dados. O hardware atendeu suficientemente às demandas de recursos em todos os casos de teste.
Estatísticas de arquivo
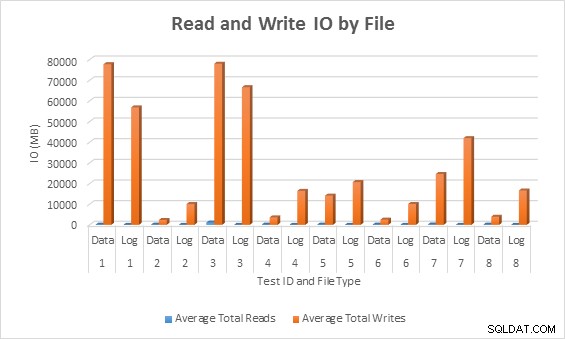 E/S média (leitura e gravação) por arquivo de banco de dados
E/S média (leitura e gravação) por arquivo de banco de dados Em todos os casos, os testes com colunas esparsas geraram menos E/S (principalmente gravações) em comparação com colunas não esparsas.
Indexar estatísticas físicas
| Caso de teste | Contagem de linhas | Contagem total de páginas (índice clusterizado) | Espaço total (GB) | Espaço médio usado para páginas de folha em CI (%) | Tamanho médio do registro (bytes) |
|---|---|---|---|---|---|
| 1 | 10.000.000 | 10.037.312 | 76 | 51,70 | 4.184,49 |
| 2 | 10.000.000 | 301.429 | 2 | 98,51 | 237,50 |
| 3 | 10.000.000 | 10.037.312 | 76 | 51,70 | 4.184,50 |
| 4 | 10.000.000 | 460.960 | 3 | 64,41 | 237,50 |
| 5 | 10.000.000 | 1.823.083 | 13 | 90,31 | 1.326,08 |
| 6 | 10.000.000 | 324.162 | 2 | 98,40 | 255,28 |
| 7 | 10.000.000 | 3.161.224 | 24 | 52,09 | 1.326,39 |
| 8 | 10.000.000 | 503.592 | 3 | 63,33 | 255,28 |
Existem diferenças significativas no uso do espaço entre as tabelas não esparsas e esparsas. Isso é mais notável ao observar os casos de teste 1 e 3, onde um tipo de dados de comprimento fixo foi usado (INT), comparado aos casos de teste 5 e 7, onde um tipo de dados de comprimento variável foi usado (VARCHAR(255)). As colunas inteiras consomem espaço em disco mesmo quando NULL. As colunas de comprimento variável consomem menos espaço em disco, pois apenas dois bytes são usados na matriz de deslocamento para colunas NULL e nenhum byte para as colunas NULL que estão após a última coluna preenchida na linha.
Além disso, o processo de inserir uma linha e depois atualizá-la causa fragmentação para o teste de coluna de comprimento variável (caso 7), em comparação com a simples inserção da linha (caso 5). O tamanho da tabela quase dobra quando a inserção é seguida pela atualização, devido às divisões de página que ocorrem ao atualizar as linhas, o que deixa as páginas meio cheias (versus 90% cheias).
Resumo
Em conclusão, vemos uma redução significativa no espaço em disco e E/S quando colunas esparsas são usadas, e elas têm um desempenho ligeiramente melhor do que colunas não esparsas em nossos testes simples de modificação de dados (observe que o desempenho de recuperação também deve ser considerado; talvez o assunto de outro publicar).
Colunas esparsas têm um cenário de uso muito específico e é importante examinar a quantidade de espaço em disco economizado, com base no tipo de dados da coluna e no número de colunas que normalmente serão preenchidas na tabela. Em nosso exemplo, tínhamos 997 colunas esparsas e preenchemos apenas 10 delas. No máximo, no caso em que o tipo de dados usado fosse inteiro, uma linha no nível folha do índice clusterizado consumiria 188 bytes (4 bytes para o ID, 100 bytes no máximo para o Nome, 4 bytes para o tipo e, em seguida, 80 bytes para 10 colunas). Quando 997 colunas não eram esparsas, então 4 bytes eram alocados para cada coluna, mesmo quando NULL, então cada linha tinha pelo menos 4.000 bytes no nível folha. Em nosso cenário, colunas esparsas são absolutamente aceitáveis. Mas se preenchermos 500 ou mais colunas esparsas com valores para uma coluna INT, a economia de espaço será perdida e o desempenho da modificação poderá não ser mais melhor.
Dependendo do tipo de dados de suas colunas e do número esperado de colunas a serem preenchidas do total, convém realizar testes semelhantes para garantir que, ao usar colunas esparsas, o desempenho de inserção e o armazenamento sejam comparáveis ou melhores do que ao usar não -colunas esparsas. Para casos em que nem todas as colunas são preenchidas, definitivamente vale a pena considerar as colunas esparsas.