A manipulação de NULL é um dos aspectos mais complicados da modelagem e manipulação de dados com SQL. Vamos começar com o fato de que uma tentativa de explicar exatamente o que é um NULL não é trivial em si. Mesmo entre as pessoas que têm uma boa compreensão da teoria relacional e SQL, você ouvirá opiniões muito fortes tanto a favor quanto contra o uso de NULLs em seu banco de dados. Goste deles ou não, como um profissional de banco de dados, muitas vezes você tem que lidar com eles, e dado que os NULLs adicionam complexidade à sua escrita de código SQL, é uma boa ideia priorizar entendê-los bem. Dessa forma, você pode evitar erros e armadilhas desnecessárias.
Este artigo é o primeiro de uma série sobre complexidades NULL. Começo com a cobertura do que são NULLs e como eles se comportam em comparações. Em seguida, abordo as inconsistências de tratamento NULL em diferentes elementos de linguagem. Por fim, abordo os recursos padrão ausentes relacionados ao tratamento de NULL em T-SQL e sugiro alternativas disponíveis em T-SQL.
A maior parte da cobertura é relevante para qualquer plataforma que implemente um dialeto do SQL, mas em alguns casos menciono aspectos específicos do T-SQL.
Em meus exemplos, usarei um banco de dados de exemplo chamado TSQLV5. Você pode encontrar o script que cria e preenche esse banco de dados aqui e seu diagrama ER aqui.
NULL como um marcador para um valor ausente
Vamos começar entendendo o que são NULLs. No SQL, um NULL é um marcador ou um espaço reservado para um valor ausente. É a tentativa do SQL de representar em seu banco de dados uma realidade onde um determinado valor de atributo às vezes está presente e às vezes ausente. Por exemplo, suponha que você precise armazenar dados de funcionários em uma tabela Funcionários. Você tem atributos para nome, nome do meio e sobrenome. Os atributos firstname e lastname são obrigatórios e, portanto, você os define como não permitindo NULLs. O atributo middlename é opcional e, portanto, você o define como permitindo NULLs.
Se você está se perguntando o que o modelo relacional tem a dizer sobre valores ausentes, o criador do modelo, Edgar F. Codd, acreditou neles. Na verdade, ele até fez uma distinção entre dois tipos de valores ausentes:ausentes, mas aplicáveis (marcador de valores A) e ausentes, mas inaplicáveis (marcador de valores-I). Se tomarmos o atributo middlename como exemplo, em um caso em que um funcionário tenha um nome do meio, mas por motivos de privacidade opte por não compartilhar as informações, você usaria o marcador A-Values. Em um caso em que um funcionário não tem um nome do meio, você usaria o marcador I-Values. Aqui, o mesmo atributo pode às vezes ser relevante e presente, às vezes ausente, mas aplicável e às vezes ausente, mas inaplicável. Outros casos poderiam ser mais claros, suportando apenas um tipo de valores ausentes. Por exemplo, suponha que você tenha uma tabela Orders com um atributo chamado shippingdate contendo a data de envio do pedido. Um pedido que foi enviado sempre terá uma data de envio atual e relevante. O único caso para não ter uma data de envio conhecida seria para pedidos que ainda não foram enviados. Portanto, aqui, um valor relevante de data de envio deve estar presente ou o marcador I-Values deve ser usado.
Os projetistas do SQL optaram por não entrar na distinção de valores ausentes aplicáveis versus inaplicáveis e nos forneceram o NULL como um marcador para qualquer tipo de valor ausente. Na maioria das vezes, o SQL foi projetado para assumir que NULLs representam o tipo Missing But Applicable de valor ausente. Conseqüentemente, especialmente quando o uso do NULL é como um espaço reservado para um valor inaplicável, o tratamento padrão do SQL NULL pode não ser aquele que você percebe como correto. Às vezes, você precisará adicionar uma lógica de manipulação NULL explícita para obter o tratamento que você considera o correto para você.
Como prática recomendada, se você souber que um atributo não deve permitir NULLs, certifique-se de aplicá-lo com uma restrição NOT NULL como parte da definição da coluna. Existem algumas razões importantes para isso. Uma razão é que, se você não aplicar isso, em um ponto ou outro, os NULLs chegarão lá. Pode ser o resultado de um bug no aplicativo ou da importação de dados incorretos. Usando uma restrição, você sabe que NULLs nunca chegarão à tabela. Outra razão é que o otimizador avalia restrições como NOT NULL para melhor otimização, evitando trabalho desnecessário procurando por NULLs e habilitando certas regras de transformações.
Comparações envolvendo NULLs
Há alguma dificuldade na avaliação de predicados do SQL quando NULLs estão envolvidos. Primeiro, abordarei comparações envolvendo constantes. Mais tarde, abordarei comparações envolvendo variáveis, parâmetros e colunas.
Quando você usa predicados que comparam operandos em elementos de consulta como WHERE, ON e HAVING, os possíveis resultados da comparação dependem se algum dos operandos pode ser NULL. Se você sabe com certeza que nenhum dos operandos pode ser NULL, o resultado do predicado sempre será TRUE ou FALSE. Isso é o que é conhecido como lógica de predicado de dois valores ou, em resumo, simplesmente lógica de dois valores. Este é o caso, por exemplo, quando você está comparando uma coluna definida como não permitindo NULLs com algum outro operando não NULL.
Se qualquer um dos operandos na comparação pode ser um NULL, digamos, uma coluna que permite NULLs, usando operadores de igualdade (=) e desigualdade (<>,>, <,>=, <=, etc.), você está agora à mercê da lógica de predicados de três valores. Se em uma determinada comparação os dois operandos forem valores não NULL, você ainda obterá TRUE ou FALSE como resultado. No entanto, se algum dos operandos for NULL, você obterá um terceiro valor lógico chamado UNKNOWN. Observe que esse é o caso mesmo ao comparar dois NULLs. O tratamento de TRUE e FALSE pela maioria dos elementos do SQL é bastante intuitivo. O tratamento do DESCONHECIDO nem sempre é tão intuitivo. Além disso, diferentes elementos do SQL lidam com o caso UNKNOWN de maneira diferente, como explicarei em detalhes mais adiante no artigo em “Inconsistências de tratamento NULL”.
Como exemplo, suponha que você precise consultar a tabela Sales.Orders no banco de dados de exemplo TSQLV5 e devolver pedidos que foram enviados em 2 de janeiro de 2019. Você usa a seguinte consulta:
USE TSQLV5; SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate = '20190102';
Está claro que o predicado do filtro é avaliado como TRUE para linhas em que a data de envio é 2 de janeiro de 2019 e que essas linhas devem ser retornadas. Também está claro que o predicado é avaliado como FALSE para linhas em que a data de envio está presente, mas não é 2 de janeiro de 2019, e que essas linhas devem ser descartadas. Mas e as linhas com uma data de envio NULL? Lembre-se de que tanto os predicados baseados em igualdade quanto os predicados baseados em desigualdade retornam UNKNOWN se algum dos operandos for NULL. O filtro WHERE foi projetado para descartar essas linhas. Você precisa lembrar que o filtro WHERE retorna linhas para as quais o predicado do filtro é avaliado como TRUE e descarta as linhas para as quais o predicado é avaliado como FALSE ou UNKNOWN.
Essa consulta gera a seguinte saída:
orderid shippeddate ----------- ----------- 10771 2019-01-02 10794 2019-01-02 10802 2019-01-02
Suponha que você precise devolver pedidos que não foram enviados em 2 de janeiro de 2019. No que diz respeito a você, os pedidos que ainda não foram enviados devem ser incluídos na saída. Você usa uma consulta semelhante à última, apenas negando o predicado, assim:
SELECT orderid, shippeddate FROM Sales.Orders WHERE NOT (shippeddate = '20190102');
Esta consulta retorna a seguinte saída:
orderid shippeddate ----------- ----------- 10249 2017-07-10 10252 2017-07-11 10250 2017-07-12 ... 11050 2019-05-05 11055 2019-05-05 11063 2019-05-06 11067 2019-05-06 11069 2019-05-06 (806 rows affected)
A saída exclui naturalmente as linhas com a data de envio 2 de janeiro de 2019, mas também exclui as linhas com uma data de envio NULL. O que pode ser contra-intuitivo aqui é o que acontece quando você usa o operador NOT para negar um predicado que é avaliado como UNKNOWN. Obviamente, NOT TRUE é FALSE e NOT FALSE é TRUE. No entanto, NÃO DESCONHECIDO permanece DESCONHECIDO. A lógica do SQL por trás desse design é que, se você não sabe se uma proposição é verdadeira, também não sabe se a proposição não é verdadeira. Isso significa que ao usar operadores de igualdade e desigualdade no predicado de filtro, nem as formas positiva nem negativa do predicado retornam as linhas com os NULLs.
Este exemplo é bem simples. Existem casos mais complicados envolvendo subconsultas. Há um bug comum quando você usa o predicado NOT IN com uma subconsulta, quando a subconsulta retorna um NULL entre os valores retornados. A consulta sempre retorna um resultado vazio. O motivo é que a forma positiva do predicado (a parte IN) retorna TRUE quando o valor externo é encontrado e UNKNOWN quando não é encontrado devido à comparação com o NULL. Então a negação do predicado com o operador NOT sempre retorna FALSE ou UNKNOWN, respectivamente—nunca um TRUE. Eu abordo esse bug em detalhes em bugs, armadilhas e práticas recomendadas do T-SQL – subconsultas, incluindo soluções sugeridas, considerações de otimização e práticas recomendadas. Se você ainda não conhece esse bug clássico, verifique este artigo, pois o bug é bastante comum e existem medidas simples que você pode tomar para evitá-lo.
Voltando à nossa necessidade, que tal tentar devolver pedidos com data de envio diferente de 2 de janeiro de 2019, usando o operador diferente de (<>):
SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate <> '20190102';
Infelizmente, os operadores de igualdade e desigualdade geram UNKNOWN quando qualquer um dos operandos é NULL, portanto, esta consulta gera a seguinte saída como a consulta anterior, excluindo os NULLs:
orderid shippeddate ----------- ----------- 10249 2017-07-10 10252 2017-07-11 10250 2017-07-12 ... 11050 2019-05-05 11055 2019-05-05 11063 2019-05-06 11067 2019-05-06 11069 2019-05-06 (806 rows affected)
Para isolar o problema de comparações com NULLs gerando UNKNOWN usando igualdade, desigualdade e negação dos dois tipos de operadores, todas as consultas a seguir retornam um conjunto de resultados vazio:
SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate = NULL; SELECT orderid, shippeddate FROM Sales.Orders WHERE NOT (shippeddate = NULL); SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate <> NULL; SELECT orderid, shippeddate FROM Sales.Orders WHERE NOT (shippeddate <> NULL);
De acordo com o SQL, você não deve verificar se algo é igual a NULL ou diferente de NULL, mas sim se algo é NULL ou não é NULL, usando os operadores especiais IS NULL e IS NOT NULL, respectivamente. Esses operadores usam lógica de dois valores, sempre retornando TRUE ou FALSE. Por exemplo, use o operador IS NULL para retornar pedidos não enviados, assim:
SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate IS NULL;
Essa consulta gera a seguinte saída:
orderid shippeddate ----------- ----------- 11008 NULL 11019 NULL 11039 NULL ... (21 rows affected)
Use o operador IS NOT NULL para devolver pedidos enviados, assim:
SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate IS NOT NULL;
Essa consulta gera a seguinte saída:
orderid shippeddate ----------- ----------- 10249 2017-07-10 10252 2017-07-11 10250 2017-07-12 ... 11050 2019-05-05 11055 2019-05-05 11063 2019-05-06 11067 2019-05-06 11069 2019-05-06 (809 rows affected)
Use o código a seguir para devolver pedidos que foram enviados em uma data diferente de 2 de janeiro de 2019, bem como pedidos não enviados:
SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate <> '20190102' OR shippeddate IS NULL;
Essa consulta gera a seguinte saída:
orderid shippeddate ----------- ----------- 11008 NULL 11019 NULL 11039 NULL ... 10249 2017-07-10 10252 2017-07-11 10250 2017-07-12 ... 11050 2019-05-05 11055 2019-05-05 11063 2019-05-06 11067 2019-05-06 11069 2019-05-06 (827 rows affected)
Em uma parte posterior da série, abordo os recursos padrão para tratamento NULL que estão faltando no T-SQL, incluindo o predicado DISTINCT , que têm o potencial de simplificar bastante o tratamento de NULL.
Comparações com variáveis, parâmetros e colunas
A seção anterior focou em predicados que comparam uma coluna com uma constante. Na realidade, porém, você comparará principalmente uma coluna com variáveis/parâmetros ou com outras colunas. Tais comparações envolvem outras complexidades.
Do ponto de vista de manipulação de NULL, variáveis e parâmetros são tratados da mesma forma. Usarei variáveis em meus exemplos, mas os pontos que faço sobre seu manuseio são igualmente relevantes para os parâmetros.
Considere a seguinte consulta básica (vou chamá-la de Consulta 1), que filtra os pedidos que foram enviados em uma determinada data:
DECLARE @dt AS DATE = '20190212'; SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate = @dt;
Eu uso uma variável neste exemplo e a inicializo com alguma data de amostra, mas isso também poderia ter sido uma consulta parametrizada em um procedimento armazenado ou uma função definida pelo usuário.
Essa execução de consulta gera a seguinte saída:
orderid shippeddate ----------- ----------- 10865 2019-02-12 10866 2019-02-12 10876 2019-02-12 10878 2019-02-12 10879 2019-02-12
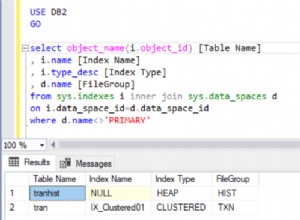
O plano para a Consulta 1 é mostrado na Figura 1.
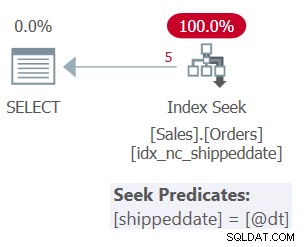 Figura 1:plano para a consulta 1
Figura 1:plano para a consulta 1 A tabela tem um índice de cobertura para dar suporte a essa consulta. O índice é chamado idx_nc_shippeddate e é definido com a lista de chaves (shippeddate, orderid). O predicado de filtro da consulta é expresso como um argumento de pesquisa (SARG) , o que significa que permite que o otimizador considere a aplicação de uma operação de busca no índice de suporte, indo direto para o intervalo de linhas qualificadas. O que torna o predicado de filtro SARGable é que ele usa um operador que representa um intervalo consecutivo de linhas qualificadas no índice e não aplica manipulação à coluna filtrada. O plano que você obtém é o plano ideal para essa consulta.
Mas e se você quiser permitir que os usuários solicitem pedidos não enviados? Esses pedidos têm uma data de envio NULA. Aqui está uma tentativa de passar um NULL como a data de entrada:
DECLARE @dt AS DATE = NULL; SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate = @dt;
Como você já sabe, um predicado usando um operador de igualdade produz UNKNOWN quando qualquer um dos operandos é NULL. Consequentemente, esta consulta retorna um resultado vazio:
orderid shippeddate ----------- ----------- (0 rows affected)
Embora o T-SQL ofereça suporte a um operador IS NULL, ele não oferece suporte a um operador IS
DECLARE @dt AS DATE = NULL; SELECT orderid, shippeddate FROM Sales.Orders WHERE ISNULL(shippeddate, '99991231') = ISNULL(@dt, '99991231');
Esta consulta gera a saída correta:
orderid shippeddate ----------- ----------- 11008 NULL 11019 NULL 11039 NULL ... 11075 NULL 11076 NULL 11077 NULL (21 rows affected)
Mas o plano para essa consulta, conforme mostrado na Figura 2, não é o ideal.
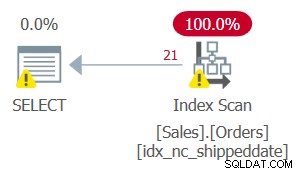 Figura 2:plano para a consulta 2
Figura 2:plano para a consulta 2 Como você aplicou a manipulação à coluna filtrada, o predicado do filtro não é mais considerado um SARG. O índice ainda está cobrindo, então pode ser usado; mas em vez de aplicar uma busca no índice indo direto para o intervalo de linhas qualificadas, toda a folha do índice é verificada. Suponha que a tabela tenha 50.000.000 de pedidos, com apenas 1.000 sendo pedidos não enviados. Esse plano examinaria todas as 50.000.000 linhas em vez de fazer uma busca que vá direto para as 1.000 linhas qualificadas.
Uma forma de predicado de filtro que tem o significado correto que estamos procurando e é considerado um argumento de pesquisa é (data de envio =@dt OR (data de envio É NULO E @dt É NULO)). Aqui está uma consulta usando este predicado SARGable (vamos chamá-lo de Consulta 3):
DECLARE @dt AS DATE = NULL; SELECT orderid, shippeddate FROM Sales.Orders WHERE (shippeddate = @dt OR (shippeddate IS NULL AND @dt IS NULL));
O plano para esta consulta é mostrado na Figura 3.
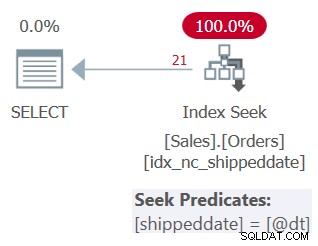 Figura 3:planejar a consulta 3
Figura 3:planejar a consulta 3 Como você pode ver, o plano aplica uma busca no índice de suporte. O predicado de busca diz data de envio =@dt, mas é projetado internamente para lidar com NULLs como valores não NULL para fins de comparação.
Esta solução é geralmente considerada razoável. É padrão, ideal e correto. Sua principal desvantagem é que é verboso. E se você tivesse vários predicados de filtro com base em colunas NULLable? Você acabaria rapidamente com uma cláusula WHERE longa e complicada. E fica muito pior quando você precisa escrever um predicado de filtro envolvendo uma coluna NULLable procurando por linhas onde a coluna é diferente do parâmetro de entrada. O predicado torna-se então:(data de envio <> @dt AND ((data de envio É NULO E @dt NÃO É NULO) OR (data de envio NÃO É NULO e @dt É NULO))).
Você pode ver claramente a necessidade de uma solução mais elegante que seja concisa e ideal. Infelizmente, alguns recorrem a uma solução não padrão em que você desativa a opção de sessão ANSI_NULLS. Essa opção faz com que o SQL Server use manipulação não padrão dos operadores de igualdade (=) e diferente de (<>) com lógica de dois valores em vez de lógica de três valores, tratando NULLs como valores não NULL para fins de comparação. Esse é pelo menos o caso, desde que um dos operandos seja um parâmetro/variável ou um literal.
Execute o seguinte código para desativar a opção ANSI_NULLS na sessão:
SET ANSI_NULLS OFF;
Execute a seguinte consulta usando um predicado simples baseado em igualdade:
DECLARE @dt AS DATE = NULL; SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate = @dt;
Esta consulta retorna os 21 pedidos não enviados. Você obtém o mesmo plano mostrado anteriormente na Figura 3, mostrando uma busca no índice.
Execute o seguinte código para voltar ao comportamento padrão em que ANSI_NULLS está ativado:
SET ANSI_NULLS ON;
Confiar em tal comportamento fora do padrão é fortemente desencorajado. A documentação também afirma que o suporte para essa opção será removido em alguma versão futura do SQL Server. Além disso, muitos não percebem que esta opção só é aplicável quando pelo menos um dos operandos é um parâmetro/variável ou uma constante, mesmo que a documentação seja bastante clara sobre isso. Não se aplica ao comparar duas colunas, como em uma junção.
Então, como você lida com junções envolvendo colunas de junção NULLable se você deseja obter uma correspondência quando os dois lados são NULLs? Como exemplo, use o código a seguir para criar e preencher as tabelas T1 e T2:
DROP TABLE IF EXISTS dbo.T1, dbo.T2; GO CREATE TABLE dbo.T1(k1 INT NULL, k2 INT NULL, k3 INT NULL, val1 VARCHAR(10) NOT NULL, CONSTRAINT UNQ_T1 UNIQUE CLUSTERED(k1, k2, k3)); CREATE TABLE dbo.T2(k1 INT NULL, k2 INT NULL, k3 INT NULL, val2 VARCHAR(10) NOT NULL, CONSTRAINT UNQ_T2 UNIQUE CLUSTERED(k1, k2, k3)); INSERT INTO dbo.T1(k1, k2, k3, val1) VALUES (1, NULL, 0, 'A'),(NULL, NULL, 1, 'B'),(0, NULL, NULL, 'C'),(1, 1, 0, 'D'),(0, NULL, 1, 'F'); INSERT INTO dbo.T2(k1, k2, k3, val2) VALUES (0, 0, 0, 'G'),(1, 1, 1, 'H'),(0, NULL, NULL, 'I'),(NULL, NULL, NULL, 'J'),(0, NULL, 1, 'K');
O código cria índices de cobertura em ambas as tabelas para suportar uma junção com base nas chaves de junção (k1, k2, k3) em ambos os lados.
Use o código a seguir para atualizar as estatísticas de cardinalidade, inflando os números para que o otimizador pense que você está lidando com tabelas maiores:
UPDATE STATISTICS dbo.T1(UNQ_T1) WITH ROWCOUNT = 1000000; UPDATE STATISTICS dbo.T2(UNQ_T2) WITH ROWCOUNT = 1000000;
Use o código a seguir em uma tentativa de unir as duas tabelas usando predicados simples baseados em igualdade:
SELECT T1.k1, T1.K2, T1.K3, T1.val1, T2.val2
FROM dbo.T1
INNER JOIN dbo.T2
ON T1.k1 = T2.k1
AND T1.k2 = T2.k2
AND T1.k3 = T2.k3; Assim como nos exemplos de filtragem anteriores, também aqui as comparações entre NULLs usando um operador de igualdade geram UNKNOWN, resultando em não correspondências. Esta consulta gera uma saída vazia:
k1 K2 K3 val1 val2 ----------- ----------- ----------- ---------- ---------- (0 rows affected)
Usando ISNULL ou COALESCE como em um exemplo de filtragem anterior, substituindo um NULL por um valor que normalmente não pode aparecer nos dados em ambos os lados, resulta em uma consulta correta (vou me referir a esta consulta como Consulta 4):
SELECT T1.k1, T1.K2, T1.K3, T1.val1, T2.val2
FROM dbo.T1
INNER JOIN dbo.T2
ON ISNULL(T1.k1, -2147483648) = ISNULL(T2.k1, -2147483648)
AND ISNULL(T1.k2, -2147483648) = ISNULL(T2.k2, -2147483648)
AND ISNULL(T1.k3, -2147483648) = ISNULL(T2.k3, -2147483648); Essa consulta gera a seguinte saída:
k1 K2 K3 val1 val2 ----------- ----------- ----------- ---------- ---------- 0 NULL NULL C I 0 NULL 1 F K
No entanto, assim como a manipulação de uma coluna filtrada quebra a SARGability do predicado do filtro, a manipulação de uma coluna de junção impede a capacidade de confiar na ordem do índice. Isso pode ser visto no plano para esta consulta, conforme mostrado na Figura 4.
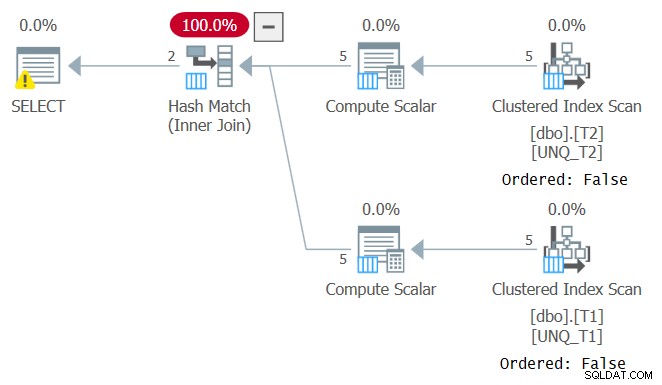 Figura 4:planejar a consulta 4
Figura 4:planejar a consulta 4 Um plano ideal para essa consulta é aquele que aplica varreduras ordenadas dos dois índices de cobertura seguidos por um algoritmo Merge Join, sem classificação explícita. O otimizador escolheu um plano diferente, pois não podia depender da ordem do índice. Se você tentar forçar um algoritmo Merge Join usando INNER MERGE JOIN, o plano ainda dependerá de varreduras não ordenadas dos índices, seguidas de classificação explícita. Tente!
Claro que você pode usar os predicados longos semelhantes aos predicados SARGable mostrados anteriormente para filtrar tarefas:
SELECT T1.k1, T1.K2, T1.K3, T1.val1, T2.val2
FROM dbo.T1
INNER JOIN dbo.T2
ON (T1.k1 = T2.k1 OR (T1.k1 IS NULL AND T2.K1 IS NULL))
AND (T1.k2 = T2.k2 OR (T1.k2 IS NULL AND T2.K2 IS NULL))
AND (T1.k3 = T2.k3 OR (T1.k3 IS NULL AND T2.K3 IS NULL)); Essa consulta produz o resultado desejado e permite que o otimizador confie na ordem do índice. No entanto, nossa esperança é encontrar uma solução que seja ótima e concisa.
Existe uma técnica elegante e concisa pouco conhecida que você pode usar tanto em junções quanto em filtros, tanto para identificar correspondências quanto para identificar não correspondências. Essa técnica já foi descoberta e documentada anos atrás, como no excelente artigo de Paul White, Undocumented Query Plans:Equality Comparisons from 2011. Mas, por algum motivo, parece que muitas pessoas ainda não a conhecem e, infelizmente, acabam usando soluções não padronizadas. Certamente merece mais exposição e amor.
A técnica se baseia no fato de que operadores de conjunto como INTERSECT e EXCEPT usam uma abordagem de comparação baseada em distinção ao comparar valores, e não uma abordagem de comparação baseada em igualdade ou desigualdade.
Considere nossa tarefa de junção como um exemplo. Se não precisássemos retornar colunas além das chaves de junção, teríamos usado uma consulta simples (vou me referir a ela como Consulta 5) com um operador INTERSECT, assim:
SELECT k1, k2, k3 FROM dbo.T1 INTERSECT SELECT k1, k2, k3 FROM dbo.T2;
Essa consulta gera a seguinte saída:
k1 k2 k3 ----------- ----------- ----------- 0 NULL NULL 0 NULL 1
O plano para esta consulta é mostrado na Figura 5, confirmando que o otimizador foi capaz de confiar na ordem do índice e usar um algoritmo Merge Join.
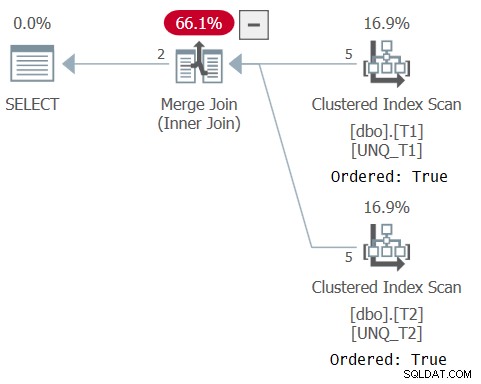 Figura 5:planejar a consulta 5
Figura 5:planejar a consulta 5 Como Paul observa em seu artigo, o plano XML para o operador set usa um operador de comparação IS implícito (CompareOp="IS" ) em oposição ao operador de comparação EQ usado em uma junção normal (CompareOp="EQ" ). O problema com uma solução que depende apenas de um operador de conjunto é que ela limita você a retornar apenas as colunas que você está comparando. O que realmente precisamos é de um híbrido entre um operador de junção e um conjunto, permitindo que você compare um subconjunto de elementos enquanto retorna outros adicionais, como uma junção faz, e usando comparação baseada em distinção (IS) como um operador de conjunto. Isso é possível usando uma junção como a construção externa e um predicado EXISTS na cláusula ON da junção com base em uma consulta com um operador INTERSECT comparando as chaves de junção dos dois lados, assim (vou me referir a esta solução como Query 6):
SELECT T1.k1, T1.K2, T1.K3, T1.val1, T2.val2 FROM dbo.T1 INNER JOIN dbo.T2 ON EXISTS(SELECT T1.k1, T1.k2, T1.k3 INTERSECT SELECT T2.k1, T2.k2, T2.k3);
O operador INTERSECT opera em duas consultas, cada uma formando um conjunto de uma linha com base nas chaves de junção de cada lado. Quando as duas linhas são iguais, a consulta INTERSECT retorna uma linha; o predicado EXISTS retorna TRUE, resultando em uma correspondência. Quando as duas linhas não são iguais, a consulta INTERSECT retorna um conjunto vazio; o predicado EXISTS retorna FALSE, resultando em uma não correspondência.
Esta solução gera a saída desejada:
k1 K2 K3 val1 val2 ----------- ----------- ----------- ---------- ---------- 0 NULL NULL C I 0 NULL 1 F K
O plano para esta consulta é mostrado na Figura 6, confirmando que o otimizador foi capaz de confiar na ordem do índice.
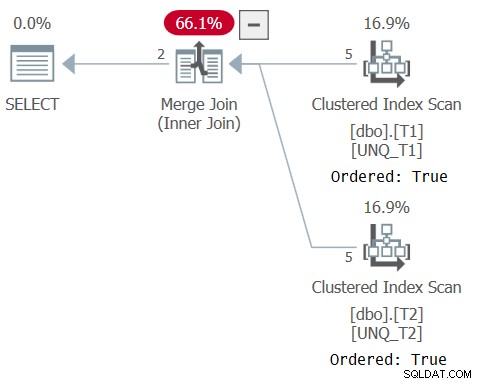 Figura 6:planejar a consulta 6
Figura 6:planejar a consulta 6 Você pode usar uma construção semelhante como um predicado de filtro envolvendo uma coluna e um parâmetro/variável para procurar correspondências com base na distinção, assim:
DECLARE @dt AS DATE = NULL; SELECT orderid, shippeddate FROM Sales.Orders WHERE EXISTS(SELECT shippeddate INTERSECT SELECT @dt);
O plano é o mesmo que o mostrado anteriormente na Figura 3.
Você também pode negar o predicado para procurar não correspondências, assim:
DECLARE @dt AS DATE = '20190212'; SELECT orderid, shippeddate FROM Sales.Orders WHERE NOT EXISTS(SELECT shippeddate INTERSECT SELECT @dt);
Essa consulta gera a seguinte saída:
orderid shippeddate ----------- ----------- 11008 NULL 11019 NULL 11039 NULL ... 10847 2019-02-10 10856 2019-02-10 10871 2019-02-10 10867 2019-02-11 10874 2019-02-11 10870 2019-02-13 10884 2019-02-13 10840 2019-02-16 10887 2019-02-16 ... (825 rows affected)
Como alternativa, você pode usar um predicado positivo, mas substitua INTERSECT por EXCEPT, assim:
DECLARE @dt AS DATE = '20190212'; SELECT orderid, shippeddate FROM Sales.Orders WHERE EXISTS(SELECT shippeddate EXCEPT SELECT @dt);
Observe que os planos nos dois casos podem ser diferentes, portanto, experimente as duas maneiras com grandes quantidades de dados.
Conclusão
NULLs adicionam sua parcela de complexidade à escrita de seu código SQL. Você sempre quer pensar sobre o potencial da presença de NULLs nos dados e certificar-se de usar as construções de consulta corretas e adicionar a lógica relevante às suas soluções para lidar com NULLs corretamente. Ignorá-los é uma maneira segura de acabar com bugs em seu código. Este mês foquei no que são NULLs e como eles são tratados em comparações envolvendo constantes, variáveis, parâmetros e colunas. No próximo mês, continuarei a cobertura discutindo inconsistências de tratamento NULL em diferentes elementos de linguagem e recursos padrão ausentes para manipulação de NULL.