Introdução
Uma tabela é uma estrutura lógica. Ao criar uma tabela, você normalmente não se importaria em quais unidades ela fica na camada de armazenamento. No entanto, se você for um administrador de banco de dados, esse conhecimento pode se tornar essencial se você precisar mover determinadas partes do banco de dados para armazenamento ou volume alternativo. Então, você pode querer que as tabelas definidas estejam em um determinado volume ou conjunto de discos.
Os grupos de arquivos no SQL Server oferecem essa camada de abstração que nos permite controlar a localização física de nossas estruturas lógicas – tabelas, índices, etc.
Grupos de arquivos
Um grupo de arquivos é uma estrutura lógica para agrupar arquivos de dados no SQL Server. Se criarmos um grupo de arquivos e o associarmos a um conjunto de arquivos de dados, qualquer objeto lógico criado nesse grupo de arquivos estará fisicamente localizado nesse conjunto de arquivos físicos.
O objetivo principal desse agrupamento de arquivos físicos é a alocação e o posicionamento dos dados. Por exemplo, queremos nossos dados de transação armazenados em um conjunto de discos rápidos. Simultaneamente, precisamos dos dados históricos armazenados em outro conjunto de discos mais baratos. Nesse cenário, criaríamos o Tran tabela no grupo de arquivos TXN e o TranHist tabela em um grupo de arquivos HIST diferente. Mais adiante neste artigo, veremos como isso se traduz em ter os dados em discos diferentes.
Criando grupos de arquivos
A sintaxe para criar grupos de arquivos é mostrada na Listagem 1 . Observação :O contexto do banco de dados é o mestre base de dados. Ao emitir as instruções, estamos alterando o banco de dados DB2 adicionando novos grupos de arquivos a ele. Essencialmente, esses grupos de arquivos são apenas construções lógicas neste momento. Eles não contêm nenhum dado.
-- Listing 1: Creating File Groups
USE [master]
GO
ALTER DATABASE [DB2] ADD FILEGROUP [HIST]
GO
ALTER DATABASE [DB2] ADD FILEGROUP [TXN]
GO
Adicionando arquivos a grupos de arquivos
A próxima etapa é adicionar um arquivo a cada um dos grupos de arquivos. Podemos adicionar mais de um arquivo, mas o mantemos simples para fins de demonstração. Observe que cada arquivo está em uma unidade totalmente diferente e a sintaxe nos permite especificar o grupo de arquivos pretendido.
-- Listing 2: Adding Files to Filegroups
USE [master]
GO
ALTER DATABASE [DB2] ADD FILE ( NAME = N'DB2_HIST_01', FILENAME = N'E:\MSSQL\Data\DB2_HIST_01.ndf' , SIZE = 102400KB , FILEGROWTH = 131072KB ) TO FILEGROUP [HIST]
GO
ALTER DATABASE [DB2] ADD FILE ( NAME = N'DB2_TXN_01', FILENAME = N'C:\MSSQL\Data\DB2_TXN_01.ndf' , SIZE = 102400KB , FILEGROWTH = 131072KB ) TO FILEGROUP [TXN]
GO
Criando tabelas para grupos de arquivos
Aqui garantimos que as tabelas estejam nos discos desejados. A sintaxe para criar tabelas nos permite especificar o grupo de arquivos que queremos.
-- Listing 3: Creating a table on Filegroups TXN and HIST
USE [DB2]
GO
CREATE TABLE [dbo].[tran](
[TranID] [int] NULL
,TranTime [datetime]
,TranAmt [money]
) ON [TXN]
GO
CREATE CLUSTERED INDEX [IX_Clustered01] ON [dbo].[tran]
(
[TranID] ASC
) ON [TXN]
GO
CREATE TABLE [dbo].[tranhist](
[TranID] [int] NULL
,TranTime [datetime]
,TranAmt [money]
) ON [HIST]
GO
Dando um passo para trás, notamos que agora alcançamos o seguinte:
- Criado dois grupos de arquivos.
- Determinou os arquivos de dados (e discos) associados a cada grupo de arquivos.
- Determinadas as tabelas associadas a cada grupo de arquivos.
Em essência, o grupo de arquivos é a camada de abstração .
Verificando em quais grupos de arquivos nossas tabelas ficam
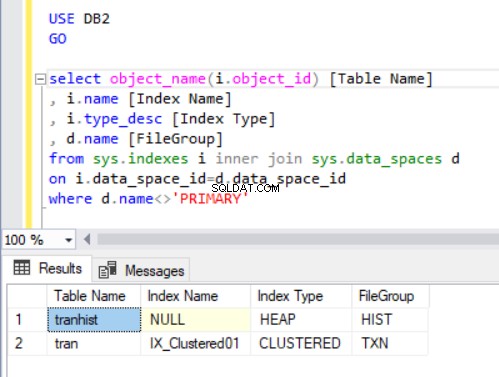
Para verificar a qual grupo de arquivos cada tabela pertence, executaremos o código na Listagem 4. Usamos duas visualizações principais do catálogo do sistema:sys.indexes e sys.data_spaces . Os sys.data_spaces A visualização de catálogo contém informações sobre grupos de arquivos e partições e as principais estruturas lógicas nas quais tabelas e índices são armazenados.
Observação:não usamos sys.tables . O SQL Server associa índices em uma tabela com espaços de dados em vez de tabelas, como podemos pensar intuitivamente.
-- Listing 4: Check the filegroup of an index or table
USE DB2
GO
select object_name(i.object_id) [Table Name]
, i.name [Index Name]
, i.type_desc [Index Type]
, d.name [FileGroup]
from sys.indexes i inner join sys.data_spaces d
on i.data_space_id=d.data_space_id
where d.name<>'PRIMARY'
A saída da consulta na Listagem 4 exibe duas tabelas que acabamos de criar. Observe que o tranhist tabela não tem um índice. Ainda assim, ele aparece no conjunto de resultados, identificado como um heap .
Um heap é uma tabela que não possui índice clusterizado determinando os dados do pedido armazenados fisicamente em uma tabela. Pode haver apenas um índice clusterizado em uma tabela.
Preenchendo a tabela Tran
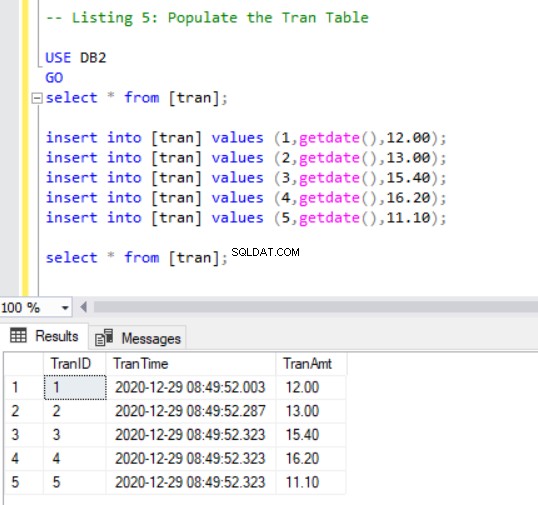
Agora, temos que adicionar alguns registros ao tran tabela usando o seguinte código:
-- Listing 5: Populate the Tran Table
USE DB2
GO
SELECT * FROM [tran];
INSERT INTO [tran] VALUES (1, GETDATE(),12.00);
INSERT INTO [tran] VALUES (2, GETDATE(),13.00);
INSERT INTO [tran] VALUES (3, GETDATE(),15.40);
INSERT INTO [tran] VALUES (4, GETDATE(),16.20);
INSERT INTO [tran] VALUES (5, GETDATE(),11.10);
SELECT * FROM [tran];
Mover uma tabela para outro grupo de arquivos
Para mover o tran tabela para outro grupo de arquivos, precisamos apenas reconstruir o índice clusterizado e especifique o novo grupo de arquivos ao fazer essa reconstrução. A Listagem 5 mostra essa abordagem.
Realizamos duas etapas:primeiro, exclua o índice e, em seguida, recrie-o. No meio, verificamos se os dados e a localização das duas tabelas que criamos anteriormente permanecem intactos.
-- Listing 6: Check what filegroup an index or table belongs to
USE [DB2]
GO
DROP INDEX [IX_Clustered01] ON [dbo].[tran] WITH ( ONLINE = OFF )
GO
CREATE CLUSTERED INDEX [IX_Clustered01] ON [dbo].[tran]
(
[TranID] ASC
) ON [HIST]
GO
Ao remover o índice clusterizado do tran tabela, nós a convertemos em um heap :
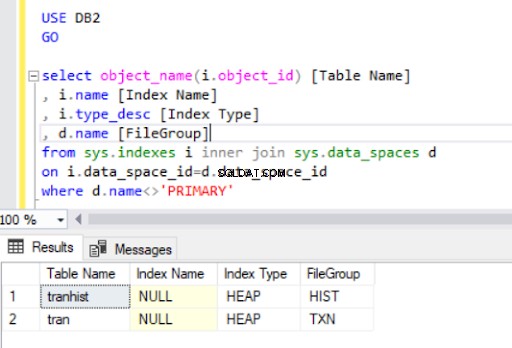
Quando recriamos o índice clusterizado, ele também é indicado na saída da Listagem 4.
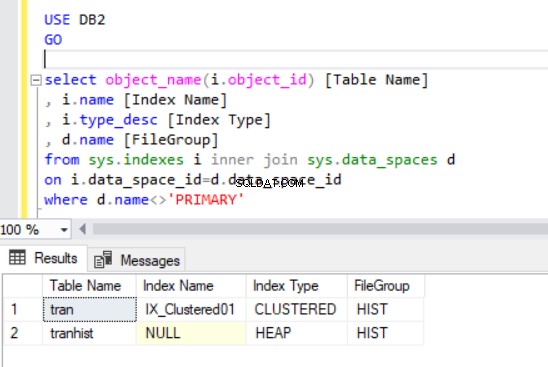
Agora temos o tran tabela no grupo de arquivos HIST.
Conclusão
Este artigo demonstrou a relação entre tabelas, índices, arquivos e grupos de arquivos em termos de armazenamento de dados do SQL Server. Também explicamos como mover uma tabela de um grupo de arquivos para outro recriando o índice clusterizado.
Essa habilidade será útil quando você precisar migrar dados para um novo armazenamento (discos mais rápidos ou discos mais lentos para arquivamento). Em cenários mais avançados, você pode usar grupos de arquivos para gerenciar o ciclo de vida dos dados implementando partições de tabela.
Referências
- Arquivos de banco de dados e grupos de arquivos
- Desativando as partições da tabela – um passo a passo