[ Parte 1 | Parte 2 | Parte 3]
Recentemente, alguém no trabalho pediu mais espaço para acomodar uma mesa que cresce rapidamente. Na época, tinha 3,75 bilhões de linhas, apresentadas em 143 milhões de páginas e ocupando ~1,14 TB. É claro que sempre podemos jogar mais disco em uma mesa, mas eu queria ver se poderíamos dimensionar isso com mais eficiência do que a tendência linear atual. Parece um ótimo trabalho para compressão, certo? Mas eu também queria experimentar algumas outras soluções, incluindo columnstore – que as pessoas estão surpreendentemente relutantes em tentar. Não sou Niko, mas queria fazer um esforço para ver o que isso poderia fazer por nós aqui.
Observe que não estou me concentrando em relatar a carga de trabalho ou outro desempenho de consulta de leitura no momento. Só quero ver o impacto que posso ter no armazenamento (e memória) desses dados.
Aqui está a tabela original. Mudei os nomes das tabelas e colunas para proteger os inocentes, mas todo o resto é relativamente preciso.
CREATE TABLE dbo.tblOriginal
(
OID bigint IDENTITY(1,1) NOT NULL PRIMARY KEY, -- there are gaps!
IN1 int NOT NULL,
IN2 int NOT NULL,
VC1 varchar(3) NULL,
BI1 bigint NULL,
IN3 int NULL,
VC2 varchar(128) NOT NULL,
VC3 varchar(128) NOT NULL,
VC4 varchar(128) NULL,
NM1 numeric(24,12) NULL,
NM2 numeric(24,12) NULL,
NM3 numeric(24,12) NULL,
BI2 bigint NULL,
IN4 int NULL,
BI3 bigint NULL,
NM4 numeric(24,12) NULL,
IN5 int NULL,
NM5 numeric(24,12) NULL,
DT1 date NULL,
VC5 varchar(128) NULL,
BI4 bigint NULL,
BI5 bigint NULL,
BI6 bigint NULL,
BT1 bit NOT NULL,
NV1 nvarchar(512) NULL,
VB1 AS (HASHBYTES('MD5',VC2+VC3)),
IN6 int NULL,
IN7 int NULL,
IN8 int NULL
); Existem algumas outras pequenas coisas que são mais largas do que deveriam ser e/ou que a compactação de linha pode ser limpa, como aquelas
numeric(24,12) e bigint colunas que podem ser prematuramente superdimensionadas, mas não vou voltar para a equipe de aplicativos e descobrir se há pouca eficiência lá, e vou pular a compactação de linhas para este exercício e focar na compactação de páginas e colunas. Esta é uma cópia dos dados, em um servidor ocioso (8 núcleos, 64 GB de RAM), com bastante espaço em disco (mais de 6 TB). Então, primeiro, vamos adicionar alguns grupos de arquivos, um para columnstore clusterizado padrão e outro para uma versão particionada da tabela (onde todas, exceto a partição mais recente, serão compactadas com
COLUMNSTORE_ARCHIVE , já que todos esses dados mais antigos agora são "somente leitura e com pouca frequência"):ALTER DATABASE OCopy ADD FILEGROUP FG_CCI; ALTER DATABASE OCopy ADD FILEGROUP FG_CCI_PARTITIONED;
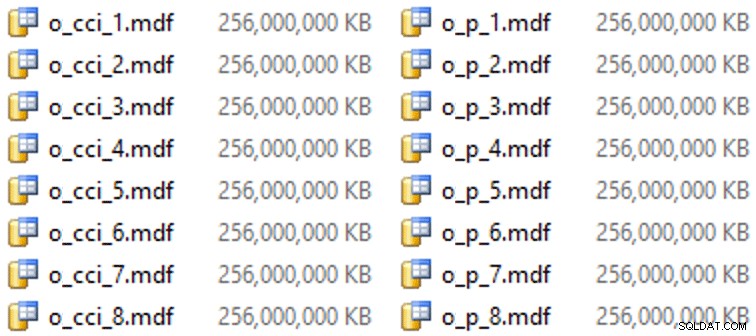
E, em seguida, alguns arquivos para esses grupos de arquivos (um arquivo por núcleo, bom e uniformemente dimensionado em 256 GB):
ALTER DATABASE OCopy ADD FILE (name = N'CCI_1', size = 250000, filename = 'K:\Data\o_cci_1.mdf') TO FILEGROUP FG_CCI; -- ... 6 more ... ALTER DATABASE OCopy ADD FILE (name = N'CCI_8', size = 250000, filename = 'K:\Data\o_cci_8.mdf') TO FILEGROUP FG_CCI; ALTER DATABASE OCopy ADD FILE (name = N'CCI_P_1', size = 250000, filename = 'K:\Data\o_p_1.mdf') TO FILEGROUP FG_CCI_PARTITIONED; -- ... 6 more ... ALTER DATABASE OCopy ADD FILE (name = N'CCI_P_8', size = 250000, filename = 'K:\Data\o_p_8.mdf') TO FILEGROUP FG_CCI_PARTITIONED;
Nesse hardware específico (YMMV!), isso levou cerca de 10 segundos por arquivo e gerou o seguinte:
Para gerar as partições, eu ingenuamente dividi os dados "uniformemente" - ou assim pensei. Acabei de pegar os 3,75 bilhões de linhas e particionar em algo que achei que seria gerenciável:38 partições com 100 milhões de linhas nas primeiras 37 partições e o restante na última. (Lembre-se, esta é apenas a parte 1! Há uma suposição inerente aqui sobre a distribuição uniforme de valores na tabela de origem e também sobre o que é ideal para a população de grupos de linhas na tabela de destino.) Criar o esquema de partição e a função para isso é tão segue:
CREATE PARTITION FUNCTION PF_OID([bigint]) AS RANGE LEFT FOR VALUES (100000000, 200000000, /* ... 33 more ... */ , 3600000000, 3700000000); CREATE PARTITION SCHEME PS_OID AS PARTITION PF_OID ALL TO (FG_CCI_PARTITIONED);
Eu uso
RANGE LEFT porque, como Cathrine Wilhelmsen continua a me lembrar, isso significa que o valor do limite é uma parte da partição à sua esquerda. Em outras palavras, os valores que estou especificando são os valores máximos em cada partição (com datas, você geralmente deseja RANGE RIGHT ). Em seguida, criei duas cópias da tabela, uma em cada grupo de arquivos. O primeiro tinha um índice columnstore clusterizado padrão, as únicas diferenças sendo o
OID coluna não é uma IDENTITY e a coluna computada é apenas um varbinary(8000) :CREATE TABLE dbo.tblCCI ( OID bigint NOT NULL, -- ... other columns ... ) ON FG_CCI; GO CREATE CLUSTERED COLUMNSTORE INDEX CCI_IX ON dbo.tblCCI;
O segundo foi construído no esquema de partição, então precisava primeiro de um PK nomeado, que então teve que ser substituído por um índice columnstore clusterizado (embora Brent Ozar mostre neste breve post que existe alguma sintaxe não intuitiva que fará isso em menos etapas ):
CREATE TABLE dbo.tblCCI_Partitioned ( OID bigint NOT NULL, -- ... other columns ..., CONSTRAINT PK_CCI_Part PRIMARY KEY CLUSTERED (OID) ON PS_OID (OID) ); GO ALTER TABLE dbo.tblCCI_Partitioned DROP CONSTRAINT PK_CCI_Part; GO CREATE CLUSTERED COLUMNSTORE INDEX CCI_Part ON dbo.tblCCI_Partitioned ON PS_OID (OID);
Então, para colocar a compactação de arquivo em todas as partições, exceto na última, executei o seguinte:
ALTER TABLE dbo.tblCCI_Part
REBUILD PARTITION = ALL WITH
(
DATA_COMPRESSION = COLUMNSTORE ON PARTITIONS (38),
DATA_COMPRESSION = COLUMNSTORE_ARCHIVE ON PARTITIONS (1 TO 37)
); Agora, eu estava pronto para preencher essas tabelas com dados, medir o tempo gasto e o tamanho resultante e comparar. Modifiquei um script de lote útil de Andy Mallon e inseri as linhas em ambas as tabelas sequencialmente, com um tamanho de lote de 10 milhões de linhas. Há muito mais do que isso no script real (incluindo atualizar uma tabela de filas com progresso), mas basicamente:
DECLARE @BatchSize int = 10000000, @MaxID bigint, @LastID bigint = 0;
SELECT @MaxID = MAX(OID) FROM dbo.tblOriginal;
WHILE @LastID < @MaxID
BEGIN
INSERT dbo.tblCCI
(
-- all columns except the computed column
)
SELECT -- all columns except the computed column
FROM dbo.tblOriginal AS o
WHERE o.CostID >= @LastID
AND o.CostID < @LastID + @BatchSize;
SET @LastID += @BatchSize;
END Depois de preencher ambas as tabelas columnstore da fonte original (descompactada), reconstruí essas partições novamente para limpar qualquer bagunça de grupo de linhas e dicionário. Por fim, apliquei a compactação de página, no local, à tabela de origem. Aqui estão os tempos e os resultados de compressão de cada tipo:
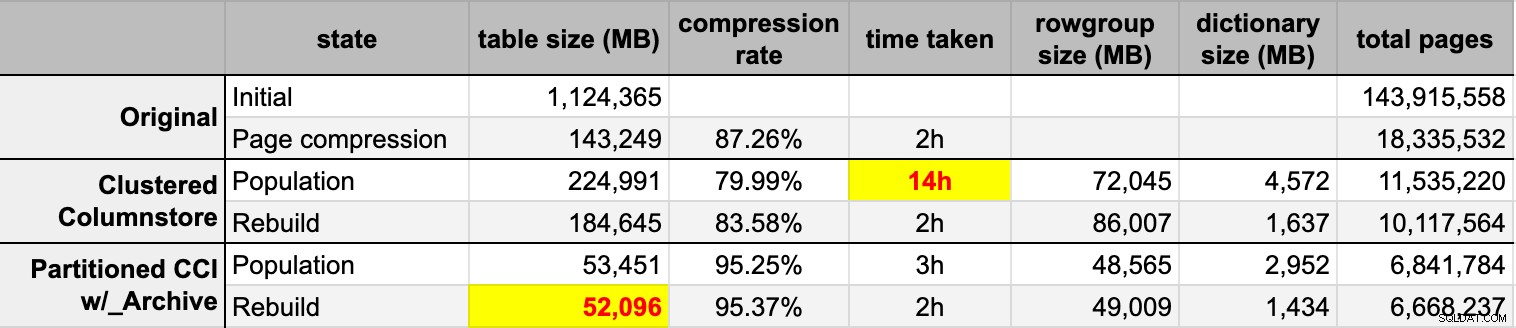
Estou impressionado e decepcionado. Impressionado porque esses dados são compactados muito bem – reduzir o espaço de armazenamento para 5% do 1 TB original é incrível. Decepcionada porque:
- Eu criei esses arquivos de dados caminho muito grande.
- Não entendo o que aconteceu com a compactação inicial do columnstore de 14 horas:
- Não observei nenhuma pressão de memória ou log.
- Não houve eventos de crescimento de arquivo.
- Infelizmente, não pensei em rastrear esperas. Não, não vou tentar de novo. :-)
- A compactação de página superou a compactação de armazenamento de colunas regular – talvez devido aos dados.
- A reconstrução das partições do arquivo columnstore consumia muito tempo de CPU para ganho quase zero.
Nas próximas postagens, e depois de revisar minhas notas de uma incrível apresentação de coluna de Joe Obbish no PASS Summit (que eu ligaria diretamente, se o PASS soubesse como UI), falarei um pouco sobre as mudanças que farei make para a configuração do servidor e meu script de preenchimento para ver se consigo obter um melhor desempenho da população de columnstore.
[ Parte 1 | Parte 2 | Parte 3]