Neste artigo, continuo explorando soluções para o desafio da oferta com a demanda. Obrigado a Luca, Kamil Kosno, Daniel Brown, Brian Walker, Joe Obbish, Rainer Hoffmann, Paul White, Charlie, Ian e Peter Larsson, por enviarem suas soluções.
No mês passado, abordei soluções baseadas em uma abordagem de interseções de intervalo revisada em comparação com a clássica. A mais rápida dessas soluções combinou ideias de Kamil, Luca e Daniel. Ele unificou duas consultas com predicados sargáveis disjuntos. A solução levou 1,34 segundos para ser concluída em uma entrada de 400 mil linhas. Isso não é muito ruim, considerando que a solução baseada na abordagem clássica de interseções de intervalo levou 931 segundos para ser concluída com a mesma entrada. Lembre-se também de que Joe apresentou uma solução brilhante que se baseia na abordagem clássica de interseção de intervalos, mas otimiza a lógica de correspondência agrupando intervalos com base no maior comprimento de intervalo. Com a mesma entrada de 400 mil linhas, a solução de Joe levou 0,9 segundos para ser concluída. A parte complicada dessa solução é que seu desempenho diminui à medida que o maior comprimento de intervalo aumenta.
Este mês, exploro soluções fascinantes que são mais rápidas do que a solução de Interseções Revisadas de Kamil/Luca/Daniel e são neutras em relação ao comprimento do intervalo. As soluções neste artigo foram criadas por Brian Walker, Ian, Peter Larsson, Paul White e eu.
Testei todas as soluções neste artigo na tabela de entrada Auctions com 100K, 200K, 300K e 400K linhas e com os seguintes índices:
-- Índice para suportar a solução CREATE UNIQUE NONCLUSTERED INDEX idx_Code_ID_i_Quantity ON dbo.Auctions(Code, ID) INCLUDE(Quantity); -- Ativar Agregação de Janelas em modo de lote CREATE NONCLUSTERED COLUMNSTORE INDEX idx_cs ON dbo.Auctions(ID) WHERE ID =-1 AND ID =-2;
Ao descrever a lógica por trás das soluções, assumirei que a tabela Leilões é preenchida com o seguinte pequeno conjunto de dados de exemplo:
Código ID Quantidade----------- ---- ---------1 D 5.0000002 D 3.0000003 D 8.0000005 D 2.0000006 D 8.0000007 D 4.0000008 D 2.0000001000 S 8.0000002000 S 6.0000003000 S 2.0000004000 S 2.0000005000 S 4.0000006000 S 3.0000007000 S 2.000000
A seguir está o resultado desejado para esses dados de amostra:
DemandID SupplyID TradeQuantity---------- ----------- --------------1 1000 5,0000002 1000 3,0000003 2000 6,0000003 3000 2,0000005 4000 2,0000006 5000 4,0000006 6000 3,0000006 7000 1,0000007 7000 1,000000
Solução de Brian Walker
As junções externas são bastante usadas em soluções de consulta SQL, mas, de longe, quando você as usa, usa as unilaterais. Ao ensinar sobre junções externas, geralmente recebo perguntas pedindo exemplos de casos de uso práticos de junções externas completas, e não há muitas. A solução de Brian é um belo exemplo de um caso de uso prático de junções externas completas.
Aqui está o código completo da solução de Brian:
DROP TABLE SE EXISTE #MyPairings; CREATE TABLE #MyPairings(DemandID INT NOT NULL, SupplyID INT NOT NULL, TradeQuantity DECIMAL(19,06) NOT NULL); WITH D AS( SELECT A.ID, SUM(A.Quantity) OVER (PARTIÇÃO POR A.Code ORDER POR A.ID ROWS UNBOUNDED PRECEDING) AS Executando DE dbo.Leilões AS A WHERE A.Code ='D'),S AS( SELECT A.ID, SUM(A.Quantity) OVER (PARTIÇÃO POR A.Code ORDER POR A.ID ROWS UNBOUNDED PRECEDING) AS Executando FROM dbo.Leilões AS A WHERE A.Code ='S'),W AS( SELECT D.ID AS DemandID, S.ID AS SupplyID, ISNULL(D.Running, S.Running) AS Running FROM D FULL JOIN S ON D.Running =S.Running),Z AS( SELECT CASE W.DemandID IS NOT NULL THEN W.DemandID ELSE MIN(W.DemandID) OVER (ORDEM POR W.Running ROWS ENTRE CURRENT ROW E UNBOUNDED SEGUINTE) END AS DemandID, CASE W.SupplyID NÃO É NULL ENTÃO W.SupplyID ELSE MIN(W.SupplyID ) OVER (ORDEM POR W.Running ROWS ENTRE A CURRENT ROW E UNBOUNDING SEGUINTE) END AS SupplyID, W.Running FROM W)INSERT #MyPair ings( DemandID, SupplyID, TradeQuantity ) SELECT Z.DemandID, Z.SupplyID, Z.Running - ISNULL(LAG(Z.Running) OVER (ORDER BY Z.Running), 0.0) AS TradeQuantity FROM Z WHERE Z.DemandID IS NOT NULL E Z.SupplyID NÃO É NULO;
Revisei o uso original de Brian de tabelas derivadas com CTEs para maior clareza.
O CTE D calcula as quantidades totais de demanda em execução em uma coluna de resultado chamada D.Running, e o CTE S calcula as quantidades totais de fornecimento em execução em uma coluna de resultado chamada S.Running. O CTE W então executa uma junção externa completa entre D e S, combinando D.Running com S.Running e retorna o primeiro não NULL entre D.Running e S.Running como W.Running. Aqui está o resultado que você obtém se consultar todas as linhas de W ordenadas por Running:
DemandID SupplyID Running----------- ----------- ----------1 NULL 5.0000002 1000 8.000000NULL 2000 14.0000003 3000 16.0000005 4000 18.000000 NULL 5000 22.000000NULL 6000 25.0000006 NULL 26.000000NULL 7000 27.0000007 NULL 30.0000008 NULL 32.000000
A ideia de usar uma junção externa completa com base em um predicado que compara os totais de demanda e oferta em execução é um golpe de gênio! A maioria das linhas neste resultado - as primeiras 9 no nosso caso - representam pares de resultados com um pouco de computação extra faltando. As linhas com IDs NULL à direita de um dos tipos representam entradas que não podem ser correspondidas. No nosso caso, as duas últimas linhas representam entradas de demanda que não podem ser correspondidas com entradas de oferta. Então, o que resta aqui é calcular o DemandID, SupplyID e TradeQuantity dos pares de resultados e filtrar as entradas que não podem ser correspondidas.
A lógica que calcula o resultado DemandID e SupplyID é feita no CTE Z da seguinte forma (assumindo ordenação em W por Running):
- DemandID:se DemandID não for NULL, DemandID, caso contrário, o DemandID mínimo começa com a linha atual
- SupplyID:se SupplyID não for NULL, SupplyID, caso contrário, o SupplyID mínimo começando com a linha atual
Aqui está o resultado que você obtém se consultar Z e ordenar as linhas por Running:
DemandID SupplyID Running----------- ----------- ----------1 1000 5,0000002 1000 8,0000003 2000 14,0000003 3000 16,0000005 4000 18,0000006 5000 22.0000006 6000 25.0000006 7000 26.0000007 7000 27.0000007 NULL 30.0000008 NULL 32.000000
A consulta externa filtra as linhas de Z representando entradas de um tipo que não podem ser correspondidas por entradas de outro tipo, garantindo que DemandID e SupplyID não sejam NULL. A quantidade de negociação dos pares de resultados é calculada como o valor em execução atual menos o valor em execução anterior usando uma função LAG.
Aqui está o que é escrito na tabela #MyPairings, que é o resultado desejado:
DemandID SupplyID TradeQuantity---------- ----------- --------------1 1000 5,0000002 1000 3,0000003 2000 6,0000003 3000 2,0000005 4000 2,0000006 5000 4,0000006 6000 3,0000006 7000 1,0000007 7000 1,000000
O plano para esta solução é mostrado na Figura 1.
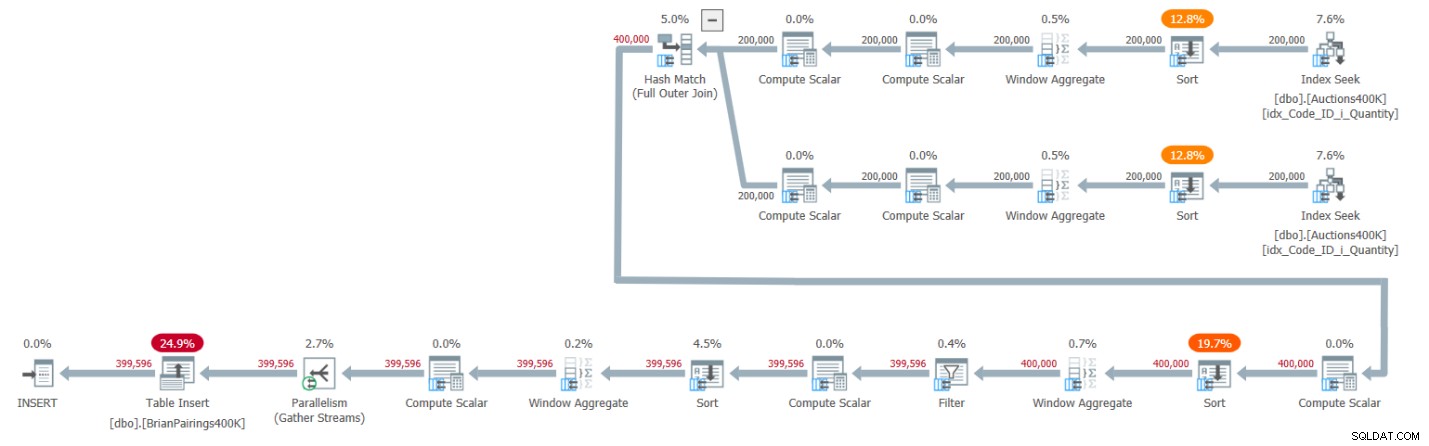 Figura 1:plano de consulta para a solução de Brian
Figura 1:plano de consulta para a solução de Brian As duas principais ramificações do plano calculam os totais em execução de demanda e oferta usando um operador Window Aggregate em modo de lote, cada um após recuperar as respectivas entradas do índice de suporte. Como expliquei em artigos anteriores da série, como o índice já tem as linhas ordenadas como os operadores Window Aggregate precisam, você pensaria que os operadores de classificação explícitos não deveriam ser necessários. Mas o SQL Server atualmente não oferece suporte a uma combinação eficiente de operação de índice de preservação de ordem paralela antes de um operador Window Aggregate de modo de lote paralelo, portanto, um operador Sort paralelo explícito precede cada um dos operadores Window Aggregate paralelos.
O plano usa uma junção de hash em modo de lote para manipular a junção externa completa. O plano também usa dois operadores Window Aggregate de modo de lote adicionais precedidos por operadores Sort explícitos para calcular as funções de janela MIN e LAG.
Esse é um plano bastante eficiente!
Aqui estão os tempos de execução que obtive para esta solução em relação aos tamanhos de entrada que variam de 100 mil a 400 mil linhas, em segundos:
100K:0,368200K:0,845300K:1,255400K:1,315
Solução de Itzik
A próxima solução para o desafio é uma das minhas tentativas de resolvê-lo. Aqui está o código completo da solução:
DROP TABLE SE EXISTE #MyPairings; WITH C1 AS( SELECT *, SUM(Quantity) OVER(PARTITION by Code ORDER BY ID ROWS UNBOUNDED PRECEDING) AS SumQty FROM dbo.Leilões),C2 AS( SELECT *, SUM(Quantity * CASE Code WHEN 'D' THEN -1 WHEN 'S' THEN 1 END) OVER(ORDER BY SumQty, Code ROWS UNBOUNDED PRECEDING) AS StockLevel, LAG(SumQty, 1, 0.0) OVER(ORDER BY SumQty, Code) AS PrevSumQty, MAX(CASE WHEN Code ='D' THEN ID END) OVER(ORDER BY SumQty, Code ROWS UNBOUNDED PRECEDING) AS PrevDemandID, MAX(CASE WHEN Code ='S' THEN ID END) OVER(ORDER BY SumQty, Code ROWS UNBOUNDED PRECEDING) AS PrevSupplyID, MIN(CASE WHEN Code ='D' THEN ID END) OVER(ORDER BY SumQty, Code ROWS BETWEEN CURRENT ROW E UNBOUNDED FOLLOWING) AS NextDemandID, MIN(CASE WHEN Code ='S' THEN ID END) OVER(ORDER BY SumQty, Code ROWS BETWEEN CURRENT ROW E SEGUINTE ILIMITADO) AS NextSupplyID FROM C1),C3 AS(SELECT *, CASE Code WHEN 'D ' THEN ID WHEN 'S' THEN CASE WHEN StockLevel> 0 THEN NextDemandID ELSE PrevDemandID END END AS DemandID, CASE Code WHEN 'S' THEN ID WHEN 'D' THEN CASE WHEN StockLevel <=0 THEN NextSupplyID ELSE PrevSupplyID END END AS SupplyID, SumQty - PrevSumQty AS TradeQuantity FROM C2)SELECT DemandID, SupplyID, TradeQuantityINTO #MyPairingsFROM C3WHERE TradeQuantity> 0.0 AND DemandID NÃO É NULO E SupplyID NÃO É NULO;
O CTE C1 consulta a tabela Leilões e usa uma função de janela para calcular as quantidades totais de demanda e oferta em execução, chamando a coluna de resultado SumQty.
O CTE C2 consulta C1 e calcula vários atributos usando funções de janela com base em SumQty e ordenação de código:
- StockLevel:O nível de estoque atual após o processamento de cada entrada. Isso é calculado atribuindo um sinal negativo às quantidades de demanda e um sinal positivo às quantidades de oferta e somando essas quantidades até e incluindo a entrada atual.
- PrevSumQty:valor SumQty da linha anterior.
- PrevDemandID:último ID de demanda não NULL.
- PrevSupplyID:último ID de fornecimento não NULL.
- NextDemandID:próximo ID de demanda não NULL.
- NextSupplyID:próximo ID de fornecimento não NULL.
Aqui está o conteúdo do C2 ordenado por SumQty e Code:
Código de ID Quantidade SumQty StockLevel PrevSumQty PrevDemandID PrevSupplyID NextDemandID NextSupplyID----- ---- --------- ---------- ------------- -- ----------- ------------ ------------ ------------ - ----------- 1 D 5.000000 5.000000 -5.000000 0,000000 1 NULL 1 10002 D 3.000000 8.000000 -8.000000 5.000000 2 NULL 2 10001000 S 8.000000 8.000000 0,0000 8.000000 2 1000 3 10002000 S 6. D 8.000000 16.000000 -2.000000 14.000000 3 2000 3 30003000 S 2.000000 16.000000 0.000000 16.000000 3 3000 5 30005 D 2.000000 18.0000000000000000 16.000000 5 3000 5 40004000 S 2,0000 18.. 40005000 S 4.000000 22.000000 4.000000 18.000000 5 5000 6 50006000 S 3,000000 25.000000 7.000000 22.000000 5 6000 60006 D 8.000000 26.00000000000000000000200000 6000 6000 777000 S 2. 32.000000 -5.000000 30.000000 8 7000 8 NULL
O CTE C3 consulta C2 e calcula os pares de resultados DemandID, SupplyID e TradeQuantity, antes de remover algumas linhas supérfluas.
A coluna C3.DemandID do resultado é calculada da seguinte forma:
- Se a entrada atual for uma entrada de demanda, retorne DemandID.
- Se a entrada atual for uma entrada de suprimento e o nível de estoque atual for positivo, retorne NextDemandID.
- Se a entrada atual for uma entrada de suprimento e o nível de estoque atual não for positivo, retorne PrevDemandID.
A coluna C3.SupplyID do resultado é calculada da seguinte forma:
- Se a entrada atual for uma entrada de fornecimento, retorne SupplyID.
- Se a entrada atual for uma entrada de demanda e o nível de estoque atual não for positivo, retorne NextSupplyID.
- Se a entrada atual for uma entrada de demanda e o nível de estoque atual for positivo, retorne PrevSupplyID.
O resultado TradeQuantity é calculado como SumQty da linha atual menos PrevSumQty.
Aqui está o conteúdo das colunas relevantes para o resultado de C3:
DemandID SupplyID TradeQuantity---------- ----------- --------------1 1000 5,0000002 1000 3,0000002 1000 0,0000003 2000 6.0000003 3000 2.0000003 3000 0,0000005 4000 2.0000005 4000 0,0000006 5000 4.0000006 6000 3.0000006 7000 1.0000007 7000 1.0000007 NULL 3.0000008 NULL 2.000000
O que resta para a consulta externa é filtrar as linhas supérfluas de C3. Esses incluem dois casos:
- Quando os totais correntes de ambos os tipos são os mesmos, a entrada de fornecimento tem uma quantidade de negociação zero. Lembre-se de que o pedido é baseado em SumQty e Code, portanto, quando os totais em execução são os mesmos, a entrada de demanda aparece antes da entrada de fornecimento.
- Entradas finais de um tipo que não podem ser correspondidas com entradas de outro tipo. Essas entradas são representadas por linhas em C3 em que DemandID é NULL ou SupplyID é NULL.
O plano para esta solução é mostrado na Figura 2.
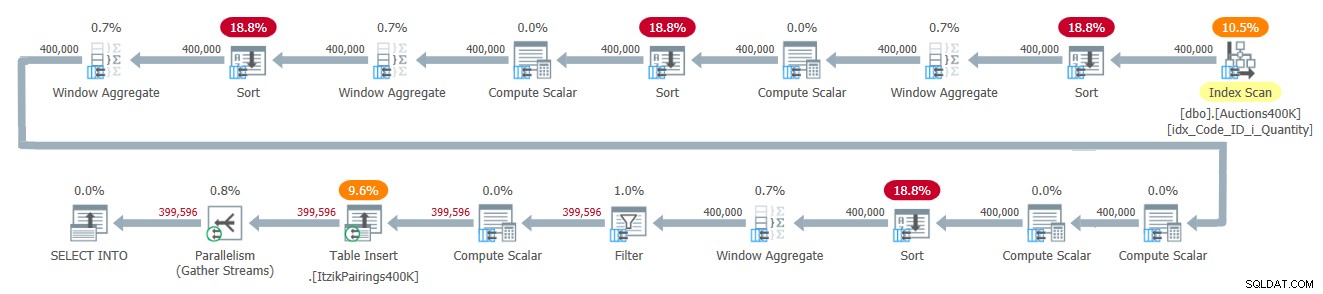 Figura 2:plano de consulta para a solução de Itzik
Figura 2:plano de consulta para a solução de Itzik O plano aplica uma passagem sobre os dados de entrada e usa quatro operadores Window Aggregate em modo de lote para lidar com os vários cálculos em janela. Todos os operadores Window Aggregate são precedidos por operadores Sort explícitos, embora apenas dois deles sejam inevitáveis aqui. Os outros dois têm a ver com a implementação atual do operador Window Aggregate de modo de lote paralelo, que não pode depender de uma entrada paralela de preservação de pedidos. Uma maneira simples de ver quais operadores de classificação são devidos a esse motivo é forçar um plano serial e ver quais operadores de classificação desaparecem. Quando forço um plano serial com esta solução, o primeiro e o terceiro operadores de classificação desaparecem.
Aqui estão os tempos de execução em segundos que obtive para esta solução:
100K:0,246200K:0,427300K:0,616400K:0,841>
Solução de Ian
A solução de Ian é curta e eficiente. Aqui está o código completo da solução:
DROP TABLE SE EXISTE #MyPairings; WITH A AS ( SELECT *, SUM(Quantity) OVER (PARTITION BY Code ORDER BY ID ROWS UNBOUNDED PRECEDING) AS CumulativeQuantity FROM dbo.Leilões), B AS (SELECT CumulativeQuantity, CumulativeQuantity - LAG(CumulativeQuantity, 1, 0) OVER (ORDER BY CumulativeQuantity) AS TradeQuantity, MAX(CASE WHEN Código ='D' THEN ID END) AS DemandID, MAX(CASE WHEN Code ='S' THEN ID END) AS SupplyID DE UM GRUPO BY CumulativeQuantity, ID/ID -- agrupamento falso para melhorar a estimativa de linha -- (contagem de linhas de leilões em vez de 2 linhas)), C AS ( -- preencha NULLs com a próxima oferta / demanda -- FIRST_VALUE(ID) IGNORE NULLS OVER ... -- seria melhor, mas isso funcionará porque os IDs estão na ordem CumulativeQuantity SELECT MIN(DemandID) OVER (ORDER BY CumulativeQuantity ROWS BETWEEN CURRENT ROW E UNBOUNDED FOLLOWING) AS DemandID, MIN(SupplyID) OVER (ORDER BY CumulativeQ uantity ROWS ENTRE CURRENT ROW E UNBOUNDED SEGUINTE) AS SupplyID, TradeQuantity FROM B)SELECT DemandID, SupplyID, TradeQuantityINTO #MyPairingsFROM CWHERE SupplyID NÃO É NULO -- apara demandas não atendidas E DemandID NÃO É NULO; -- cortar suprimentos não utilizados
O código no CTE A consulta a tabela Leilões e calcula as quantidades totais de demanda e oferta em execução usando uma função de janela, nomeando a coluna de resultado CumulativeQuantity.
O código no CTE B consulta o CTE A e agrupa as linhas por CumulativeQuantity. Esse agrupamento obtém um efeito semelhante ao da junção externa de Brian com base nos totais de demanda e oferta em execução. Ian também adicionou o ID/ID da expressão fictícia ao conjunto de agrupamento para melhorar a cardinalidade original do agrupamento sob estimativa. Na minha máquina, isso também resultou no uso de um plano paralelo em vez de um serial.
Na lista SELECT, o código calcula DemandID e SupplyID recuperando o ID do respectivo tipo de entrada no grupo usando o agregado MAX e uma expressão CASE. Se o ID não estiver presente no grupo, o resultado será NULL. O código também calcula uma coluna de resultado chamada TradeQuantity como a quantidade cumulativa atual menos a anterior, recuperada usando a função de janela LAG.
Aqui está o conteúdo de B:
CumulativeQuantity TradeQuantity DemandId SupplyId-------- -------------- --------- - -------- 5.000000 5.000000 1 NULL 8.000000 3.000000 2 100014.000000 6.000000 NULL 200016.000000 2.000000 3 300018.000000 2.000000 5 400022.000000 4.000000 NULL 500025.000000 3.000000 NULL 600026.000000 1.000000 6 NULL27.000000 1.000000 NULL 700030.000000 3.000000 7 NULL32.000000 2.000000 8 NULL
O código no CTE C então consulta o CTE B e preenche os IDs de demanda e fornecimento NULL com os próximos IDs de demanda e fornecimento não NULL, usando a função de janela MIN com o quadro ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING.
Aqui está o conteúdo de C:
DemandID SupplyID TradeQuantity --------- --------- --------------1 1000 5,000000 2 1000 3,000000 3 2000 6,000000 3 3000 2,000000 5 4000 2,000000 6 5000 4,000000 6 6000 3,000000 6 7000 1,000000 7 7000 1,000000 7 NULL 3,000000 8 NULL 2,000000
A última etapa tratada pela consulta externa em C é remover entradas de um tipo que não podem ser correspondidas com entradas de outro tipo. Isso é feito filtrando as linhas em que SupplyID é NULL ou DemandID é NULL.
O plano para esta solução é mostrado na Figura 3.
 Figura 3:plano de consulta para a solução de Ian
Figura 3:plano de consulta para a solução de Ian Esse plano executa uma varredura dos dados de entrada e usa três operadores de agregação de janela de modo de lote paralelos para calcular as várias funções de janela, todas precedidas por operadores de classificação paralelos. Dois deles são inevitáveis, como você pode verificar forçando um plano serial. O plano também usa um operador Hash Aggregate para lidar com o agrupamento e agregação no CTE B.
Aqui estão os tempos de execução em segundos que obtive para esta solução:
100K:0,214200K:0,363300K:0,546400K:0,701
Solução de Peter Larsson
A solução de Peter Larsson é incrivelmente curta, doce e altamente eficiente. Aqui está o código completo da solução de Peter:
DROP TABLE SE EXISTE #MyPairings; WITH cteSource(ID, Code, RunningQuantity)AS(SELECT ID, Code, SUM(Quantity) OVER (PARTITION BY Code ORDER BY ID) AS RunningQuantity FROM dbo.Auctions)SELECT DemandID, SupplyID, TradeQuantityINTO #MyPairingsFROM ( SELECT MIN(CASE WHEN) Código ='D' THEN ID ELSE 2147483648 END) OVER (ORDEM POR RunningQuantity, Code ROWS ENTRE CURRENT ROW E UNBOUNDED SEGUINTE) AS DemandID, MIN(CASE WHEN Code ='S' THEN ID ELSE 2147483648 END) OVER (ORDER POR RunningQuantity, Código LINHAS ENTRE LINHA ATUAL E SEGUINTE ILIMITADO) AS SupplyID, RunningQuantity - COALESCE(LAG(RunningQuantity) OVER (ORDEM POR RunningQuantity, Código), 0.0) AS TradeQuantity FROM cteSource ) AS dWHERE DemandID <2147483648 AND SupplyID <2147483648 AND TradeQuantity> 0.0;
O CTE cteSource consulta a tabela Leilões e usa uma função de janela para calcular as quantidades totais de demanda e oferta em execução, chamando a coluna de resultado RunningQuantity.
O código que define a tabela derivada d consulta cteSource e calcula os pares de resultados DemandID, SupplyID e TradeQuantity, antes de remover algumas linhas supérfluas. Todas as funções de janela usadas nesses cálculos são baseadas na ordenação de RunningQuantity e Code.
A coluna de resultado d.DemandID é calculada como o ID de demanda mínimo começando com o atual ou 2147483648 se nenhum for encontrado.
A coluna de resultado d.SupplyID é calculada como o ID de fornecimento mínimo começando com o atual ou 2147483648 se nenhum for encontrado.
O resultado TradeQuantity é calculado como o valor RunningQuantity da linha atual menos o valor RunningQuantity da linha anterior.
Aqui está o conteúdo de d:
DemandID SupplyID TradeQuantity-------- ----------- --------------1 1000 5,0000002 1000 3,0000003 1000 0,0000003 2000 6,0000003 3000 2.0000005 3000 0,0000005 4000 2.0000006 4000 0,0000006 5000 4.0000006 6000 3.0000006 7000 1.0000007 7000 1.0000007 2147483648 3.0000008 2147483648 2.000000
O que resta para a consulta externa é filtrar as linhas supérfluas de d. São casos em que a quantidade de negociação é zero ou entradas de um tipo que não podem ser correspondidas com entradas de outro tipo (com ID 2147483648).
O plano para esta solução é mostrado na Figura 4.
 Figura 4:plano de consulta para a solução de Peter
Figura 4:plano de consulta para a solução de Peter Assim como o plano de Ian, o plano de Peter depende de uma varredura dos dados de entrada e usa três operadores de agregação de janela paralelos em modo de lote para calcular as várias funções de janela, todas precedidas por operadores Sort paralelos. Dois deles são inevitáveis, como você pode verificar forçando um plano serial. No plano de Peter, não há necessidade de um operador agregado agrupado como no plano de Ian.
O insight crítico de Peter que permitiu uma solução tão curta foi a percepção de que, para uma entrada relevante de qualquer um dos tipos, o ID correspondente do outro tipo sempre aparecerá mais tarde (com base em RunningQuantity e ordenação de código). Depois de ver a solução de Peter, com certeza parecia que eu compliquei demais as coisas na minha!
Aqui estão os tempos de execução em segundos que obtive para esta solução:
100K:0,197200K:0,412300K:0,558400K:0,696
Solução de Paul White
Nossa última solução foi criada por Paul White. Aqui está o código completo da solução:
DROP TABLE SE EXISTE #MyPairings; CREATE TABLE #MyPairings( DemandID integer NOT NULL, SupplyID integer NOT NULL, TradeQuantity decimal(19, 6) NOT NULL);GO INSERT #MyPairings WITH (TABLOCK)( DemandID, SupplyID, TradeQuantity)SELECT Q3.DemandID, Q3.SupplyID, Q3.TradeQuantityFROM ( SELECT Q2.DemandID, Q2.SupplyID, TradeQuantity =-- Intervalo de sobreposição CASO QUANDO Q2.Code ='S' ENTÃO CASO QUANDO Q2.CumDemand>=Q2.IntEnd ENTÃO Q2.IntLength QUANDO Q2.CumDemand> Q2. IntStart ENTÃO Q2.CumDemand - Q2.IntStart ELSE 0.0 END Q2.CumSupply ='D' ENTÃO CASO Q2.CumSupply>=Q2.IntEnd ENTÃO Q2.IntLength Q2.CumSupply> Q2.IntStart ENTÃO Q2.CumSupply - Q2. IntStart ELSE 0.0 END END FROM ( SELECT Q1.Code, Q1.IntStart, Q1.IntEnd, Q1.IntLength, DemandID =MAX(IIF(Q1.Code ='D', Q1.ID, 0)) OVER ( ORDER BY Q1.IntStart, Q1.ID ROWS UNBOUNDED PRECEDING), SupplyID =MAX(IIF(Q1.Code ='S', Q1.ID, 0)) OVER ( ORDER POR Q1.IntStart, Q1.ID ROWS UNBOUNDED PRECEDING), CumSupply =SUM(IIF(Q1.Code ='S', Q1.IntLength, 0)) OVER (ORDER POR Q1.IntStart, Q1.ID LINHAS ILIMITADAS ANTERIORES), CumDemand =SOMA(IIF(Q1.Code ='D', Q1.IntLength, 0)) OVER ( ORDER BY Q1.IntStart, Q1.ID LINHAS ANTERIORES ILIMITADAS) FROM ( -- Intervalos de demanda SELECT A.ID, A.Code, IntStart =SUM(A.Quantity) OVER ( ORDER BY A.ID LINHAS ANTERIORES ILIMITADAS) - A. Quantidade, IntEnd =SUM(A.Quantity) OVER ( ORDER POR A.ID ROWS UNBOUNDED PRECEDING), IntLength =A.Quantity FROM dbo.Leilões AS A WHERE A.Code ='D' UNION ALL -- Intervalos de fornecimento SELECT A.ID, A.Código, IntStart =SOMA(A.Quantidade) ACIMA ( ORDEM POR LINHAS A.ID ILIMITADAS ANTERIORES) - A.Quantidade, IntEnd =SOMA(A.Quantidade) ACIMA ( ORDEM POR LINHAS A.ID ILIMITADAS ANTERIORES), IntLength =A.Quantity FROM dbo.Leilões AS A WHERE A.Code ='S' ) AS Q1 ) AS Q2) AS Q3WHERE Q3.TradeQuantity> 0;
O código que define a tabela derivada Q1 usa duas consultas separadas para calcular os intervalos de demanda e fornecimento com base nos totais em execução e unifica os dois. Para cada intervalo, o código calcula seu início (IntStart), final (IntEnd) e comprimento (IntLength). Aqui estão os conteúdos do Q1 ordenados por IntStart e ID:
Código ID IntStart IntEnd IntLength----- ---- ---------- ---------- ----------1 D 0,000000 5.000000 5.0000001000 S 0.000000 8.000000 8.0000002 D 5.000000 8.000000 3.0000003 D 8.000000 16.000000 8.0000002000 S 8.000000 14.000000 6.0000003000 S 14.000000 16.000000 2.0000005 D 16.000000 18.000000 2.0000004000 S 16.000000 18.000000 2.0000006 D 18.000000 26.000000 8.0000005000 S 18.000000 22.000000 4.0000006000 S 22.000000 25.000000 3.0000007000 S 25.000000 27.000000 2.0000007 D 26.000000 30.000000 4.0000008 D 30.000000 32.000000 2.000000
O código que define a tabela derivada Q2 consulta Q1 e calcula colunas de resultado chamadas DemandID, SupplyID, CumSupply e CumDemand. Todas as funções de janela usadas por este código são baseadas na ordem IntStart e ID e no quadro ROWS UNBOUNDED PRECEDING (todas as linhas até a atual).
DemandID é o ID de demanda máximo até a linha atual ou 0 se não existir.
SupplyID é o ID de fornecimento máximo até a linha atual ou 0 se não existir.
CumSupply são as quantidades cumulativas de fornecimento (comprimentos de intervalo de fornecimento) até a linha atual.
CumDemand são as quantidades de demanda acumulada (comprimentos de intervalo de demanda) até a linha atual.
Aqui está o conteúdo do Q2:
Código IntStart IntEnd IntLength DemandID SupplyID CumSupply CumDemand---- ---------- ---------- ---------- ----- ---- --------- ---------- ---------- D 0,000000 5,000000 5,000000 1 0 0,000000 5,000000S 0,000000 8,000000 8,000000 1 1000 8,000000 5,000000D 5.000000 8.000000 3.000000 2 1000 8.000000 8.000000D 8.000000 16.000000 8.000000 3 1000 8.000000 16.000000S 8.000000 14.000000 6.000000 3 2000 14.000000 16.000000S 14.000000 16.000000 2.000000 3 3000 16.000000 16.000000D 16.000000 18.000000 2.000000 5 3000 16.000000 18.000000S 16.000000 18.000000 2.000000 5 4000 18.000000 18.000000D 18.000000 26.000000 8,000000 6 4000 18,000000 26,000000S 18,000000 22,000000 4,000000 6 5000 22,000000 26,000000S 22,000000 25,000000 3,000000 25.000000 26.000000s 25.000000 27.000000 2.000000 6 7000 27.000000 26.0000D 26.000000 30.000000 4.000000 7 7000 27.000000 30.0000D 30.000000 32.000000 2,0000 8 7000 27.0000 32.00 32.0000 32.00000000 2,0000 8 7000 27.
Q2 já tem os valores corretos de DemandID e SupplyID dos pares de resultados finais. O código que define a tabela derivada Q3 consulta Q2 e calcula os valores de TradeQuantity dos pares de resultados como os segmentos sobrepostos dos intervalos de demanda e oferta. Finally, the outer query against Q3 filters only the relevant pairings where TradeQuantity is positive.
The plan for this solution is shown in Figure 5.
Figure 5:Query plan for Paul’s solution
The top two branches of the plan are responsible for computing the demand and supply intervals. Both rely on Index Seek operators to get the relevant rows based on index order, and then use parallel batch-mode Window Aggregate operators, preceded by Sort operators that theoretically could have been avoided. The plan concatenates the two inputs, sorts the rows by IntStart and ID to support the subsequent remaining Window Aggregate operator. Only this Sort operator is unavoidable in this plan. The rest of the plan handles the needed scalar computations and the final filter. That’s a very efficient plan!
Here are the run times in seconds I got for this solution:
100K:0.187200K:0.331300K:0.369400K:0.425
These numbers are pretty impressive!
Performance Comparison
Figure 6 has a performance comparison between all solutions covered in this article.
Figure 6:Performance comparison
At this point, we can add the fastest solutions I covered in previous articles. Those are Joe’s and Kamil/Luca/Daniel’s solutions. The complete comparison is shown in Figure 7.
Figure 7:Performance comparison including earlier solutions
These are all impressively fast solutions, with the fastest being Paul’s and Peter’s.
Conclusão
When I originally introduced Peter’s puzzle, I showed a straightforward cursor-based solution that took 11.81 seconds to complete against a 400K-row input. The challenge was to come up with an efficient set-based solution. It’s so inspiring to see all the solutions people sent. I always learn so much from such puzzles both from my own attempts and by analyzing others’ solutions. It’s impressive to see several sub-second solutions, with Paul’s being less than half a second!
It's great to have multiple efficient techniques to handle such a classic need of matching supply with demand. Bem feito a todos!
[ Jump to:Original challenge | Solutions:Part 1 | Part 2 | Part 3 ]