Em 2014, comecei uma série de posts aqui para falar sobre tipos específicos de espera e o que eles fazem e não significam. Isso me deu a ideia de criar as bibliotecas de espera e travas que mantenho (mais sobre isso posteriormente).
Se você está lendo isso e pensando “do que ele está falando?” então este post é para você. Vou apresentar as estatísticas de espera e explicar como elas são críticas para solucionar problemas de desempenho da carga de trabalho no SQL Server.
Programação
A execução do código interno do SQL Server é feita usando um mecanismo chamado threads . Cada thread pode estar executando o código do SQL Server e vários threads se coordenam quando uma consulta é executada em paralelo. Esses threads são criados quando o SQL Server é iniciado, dependendo do número de núcleos de processador disponíveis para uso do SQL Server.
Os threads são colocados em um agendador quando uma consulta é iniciada, com um agendador por núcleo de processador, e não saia desse agendador até que a consulta seja concluída. Um escalonador tem três “partes” básicas:
- O processador , que tem exatamente um código em execução no momento.
- A lista de garçons , que tem todos os encadeamentos que estão basicamente presos, esperando que um determinado recurso fique disponível.
- A fila executável , que tem todas as threads que podem ser executadas, mas estão esperando para entrar no processador.
Os encadeamentos passam do estado 1 para o estado 2 para o 3 para o 1, girando e girando até que a consulta seja concluída.
Aguarda
Do nosso ponto de vista, a parte mais interessante do agendamento é quando uma thread precisa esperar por um recurso antes de continuar. Alguns exemplos disso são:
- Um encadeamento precisa ler uma página e a página não está na memória, então o encadeamento emite uma E/S física assíncrona e precisa esperar, fora do processador, até que a E/S seja concluída.
- Um encadeamento precisa adquirir um bloqueio de compartilhamento em uma linha para lê-lo, mas outro encadeamento já possui um bloqueio exclusivo conflitante enquanto está atualizando a linha.
Quando um thread encontra a necessidade de um recurso que não pode obter, ele não tem escolha a não ser parar e esperar que o recurso fique disponível (o mecanismo de como o thread é notificado sobre a disponibilidade do recurso está além do escopo deste artigo). Quando isso acontece, o SQL Server anota o motivo pelo qual o encadeamento teve que esperar e isso é chamado de tipo de espera . Alguns exemplos disso são:
- Quando um thread está esperando que uma página seja lida na memória para que possa ser lida, o tipo de espera é PAGEIOLATCH_SH (se o encadeamento estiver aguardando uma página que será alterada, o tipo de espera será PAGEIOLATCH_EX ).
- Quando um encadeamento aguarda um bloqueio de compartilhamento em uma linha, o tipo de espera é LCK_M_S (modo de bloqueio-compartilhamento)
O SQL Server também controla quanto tempo o thread tem que esperar. Isso é chamado de tempo de espera do recurso , e geralmente é conhecido como tempo de espera .
Estatísticas de espera
O conjunto geral de métricas de quantos threads esperaram por quais recursos e por quanto tempo em média é chamado de estatísticas de espera . Essas informações são extremamente úteis para solucionar problemas de desempenho da carga de trabalho, pois você pode ver facilmente onde podem estar os gargalos de desempenho.
A ideia básica é que o SQL Server tenha as informações sobre por que os threads precisam parar e esperar e o que eles estão esperando. Portanto, em vez de ter que adivinhar por onde começar a solucionar problemas, uma análise cuidadosa das estatísticas de espera geralmente pode indicar uma direção a seguir.
Por exemplo, se a maioria das esperas no servidor for PAGEIOLATCH_SH , isso pode indicar que há pressão de memória no servidor ou que há consultas fazendo grandes varreduras de tabela em vez de usar índices não clusterizados, ou que há um problema com o subsistema de E/S subjacente ou vários outros motivos.
Há um grande número de tipos de espera, mas a maioria deles não aparece com muita frequência, então há um conjunto principal que você verá repetidamente em seus servidores. Entender o que isso significa e como investigá-los é fundamental para que você não sucumba ao que chamo de “ajuste de desempenho instintivo” e perca tempo e esforço tentando corrigir um problema que não é realmente um problema. Eu escrevi uma série de posts aqui que entram em detalhes lá, e Aaron Bertrand também escreveu um post resumido das 10 principais estatísticas de espera no ano passado.
Aguardas de rastreamento
Existem várias maneiras de rastrear esperas. O mais simples é observar quais esperas estão ocorrendo no servidor agora, usando um script que examina o sys.dm_os_waiting_tasks DMV. Você pode encontrar um script para fazer isso aqui e que tenha URLs gerados automaticamente na biblioteca de espera.
Outra maneira é observar as estatísticas de espera agregadas de todo o servidor, com um script que examina o sys.dm_os_wait_stats DMV. Você pode encontrar um script para fazer isso aqui e que tenha URLs gerados automaticamente na biblioteca de espera. Você precisa ter cuidado com esse método, pois ele mostrará todas as esperas que ocorreram desde que o servidor foi iniciado. Uma maneira melhor é rastrear esperas em pequenos intervalos, digamos meia hora, e um script para fazer isso está aqui.
Você também pode obter estatísticas de espera usando o suplemento Relatórios do Servidor para a nova ferramenta Azure Data Studio e usando o Repositório de Consultas do SQL Server 2017 em diante.
Lembre-se, você ainda precisa entender o que significam os tipos de espera depois de coletar as métricas.
Recursos de espera
Para ajudar com isso, e porque a Microsoft não tem documentação sobre como interpretar as estatísticas de espera, em 2016 eu lancei uma biblioteca de tipos de espera, com detalhes de centenas de tipos de espera comuns e como solucioná-los. Você pode acessar a biblioteca em https://www.SQLskills.com/help/waits. E então, em 2017, o SentryOne criou um sistema automatizado para fornecer um infográfico para cada página da biblioteca que você pode usar rapidamente para ver se o tipo de espera que você está interessado é realmente comum ou não (veja este post para detalhes) . Um exemplo de infográfico está abaixo, para o PAGEIOLATCH_SH tipo de espera:
No eixo horizontal está uma escala (alternável entre linear e logarítmica) de qual porcentagem de instâncias (monitoradas remotamente pelo SentryOne) experimentaram essa espera no mês anterior, e no eixo vertical está a porcentagem de tempo que essas instâncias que passaram por isso wait realmente tinha um thread esperando por esse tipo de espera.
Um outro recurso para ajudá-lo a entender as esperas é um curso de treinamento online que gravei para o Pluralsight – veja aqui.
No mínimo, você deve ler as várias postagens do blog nas seções Estatísticas de espera e Acompanhamento de esperas acima.
Rastreamento de esperas usando as ferramentas SentryOne
O SQL Sentry rastreia as esperas em nível de instância para você automaticamente ao longo do tempo, para que você não precise pegar esperas altas "no ato". Alguém reclamou de um sistema lento ontem à tarde ou de um relatório que expirou na terça-feira passada? Sem problemas. Você pode analisar todas as esperas em qualquer ponto no tempo ou em um intervalo e correlacioná-las com várias outras métricas de desempenho coletadas no momento - sejam outras tendências no painel, como backup ou atividade de E/S do banco de dados, saltando para todos os principais comandos SQL que estavam sendo executados na mesma janela, investigando bloqueios de longa duração ou usam linhas de base para comparar o perfil de esperas com outros períodos.
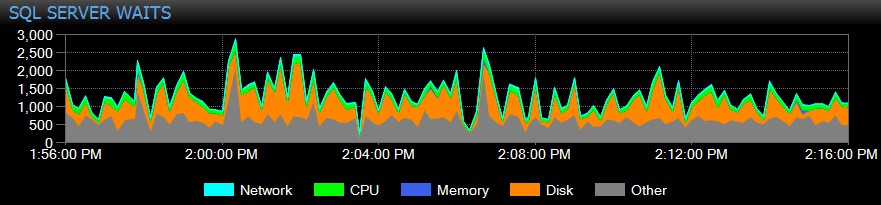
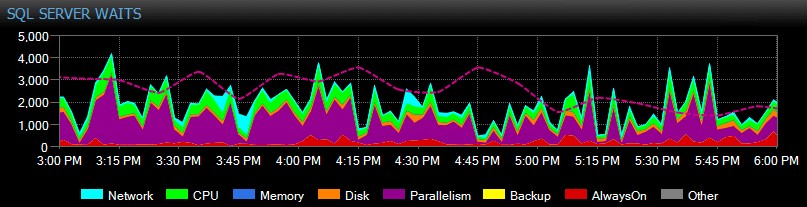
Você pode até personalizar esperas que são ou não coletadas, alterar as categorias que são apresentadas visualmente e criar alertas e/ou respostas inteligentes para cenários de espera específicos. Muitos de nossos clientes usam o SQL Sentry para se concentrar em problemas reais de desempenho relacionados a esperas, pois permite que eles ignorem muito do ruído que é apenas a atividade normal de thread do SQL Server.
Resumo
Como você pode ver nas informações acima, as esperas sempre acontecem no SQL Server, porque é assim que o agendamento de threads e os sistemas multithread funcionam. Eles são uma das ferramentas mais poderosas em sua caixa de ferramentas de solução de problemas, portanto, se você ainda não os estiver usando, agora é a hora de começar. A curva de aprendizado é curta e íngreme - depois de executar as várias consultas e ferramentas algumas vezes, você rapidamente pega o jeito, e então é um caso de ler os guias para as esperas que você está vendo e determinar se eles são um problema de não.
Boa solução de problemas!