Alguém excluiu acidentalmente parte do banco de dados. Alguém esqueceu de incluir uma cláusula WHERE em uma consulta DELETE ou eliminou a tabela errada. Coisas assim podem e vão acontecer, é inevitável e humano. Mas o impacto pode ser desastroso. O que você pode fazer para se proteger dessas situações e como recuperar seus dados? Nesta postagem do blog, abordaremos alguns dos casos mais comuns de perda de dados e como você pode se preparar para se recuperar deles.
Preparações
Há coisas que você deve fazer para garantir uma recuperação suave. Vamos passar por eles. Lembre-se de que não é uma situação de "escolha uma" - idealmente, você implementará todas as medidas que discutiremos abaixo.
Backup
Você tem que ter um backup, não há como fugir disso. Você deve testar seus arquivos de backup - a menos que você teste seus backups, você não pode ter certeza se eles são bons e se você poderá restaurá-los. Para recuperação de desastres, você deve manter uma cópia de seu backup em algum lugar fora do seu datacenter - para o caso de todo o datacenter ficar indisponível. Para acelerar a recuperação, é muito útil manter uma cópia do backup também nos nós do banco de dados. Se seu conjunto de dados for grande, copiá-lo pela rede de um servidor de backup para o nó do banco de dados que você deseja restaurar pode levar um tempo significativo. Manter o backup mais recente localmente pode melhorar significativamente os tempos de recuperação.
Backup lógico
Seu primeiro backup, provavelmente, será um backup físico. Para MySQL ou MariaDB, será algo como xtrabackup ou algum tipo de instantâneo do sistema de arquivos. Esses backups são ótimos para restaurar um conjunto de dados inteiro ou para provisionar novos nós. No entanto, em caso de exclusão de um subconjunto de dados, eles sofrem uma sobrecarga significativa. Em primeiro lugar, você não poderá restaurar todos os dados, caso contrário, você substituirá todas as alterações que ocorreram após a criação do backup. O que você está procurando é a capacidade de restaurar apenas um subconjunto de dados, apenas as linhas que foram removidas acidentalmente. Para fazer isso com um backup físico, você teria que restaurá-lo em um host separado, localizar as linhas removidas, despejá-las e restaurá-las no cluster de produção. Copiar e restaurar centenas de gigabytes de dados apenas para recuperar um punhado de linhas é algo que definitivamente chamaríamos de sobrecarga significativa. Para evitar isso, você pode usar backups lógicos - em vez de armazenar dados físicos, esses backups armazenam dados em formato de texto. Isso facilita a localização dos dados exatos que foram removidos, que podem ser restaurados diretamente no cluster de produção. Para facilitar ainda mais, você também pode dividir esse backup lógico em partes e fazer backup de cada tabela em um arquivo separado. Se o seu conjunto de dados for grande, fará sentido dividir o máximo possível um arquivo de texto enorme. Isso tornará o backup inconsistente, mas na maioria dos casos, isso não é problema - se você precisar restaurar todo o conjunto de dados para um estado consistente, usará o backup físico, que é muito mais rápido nesse sentido. Se você precisar restaurar apenas um subconjunto de dados, os requisitos de consistência serão menos rigorosos.
Recuperação pontual
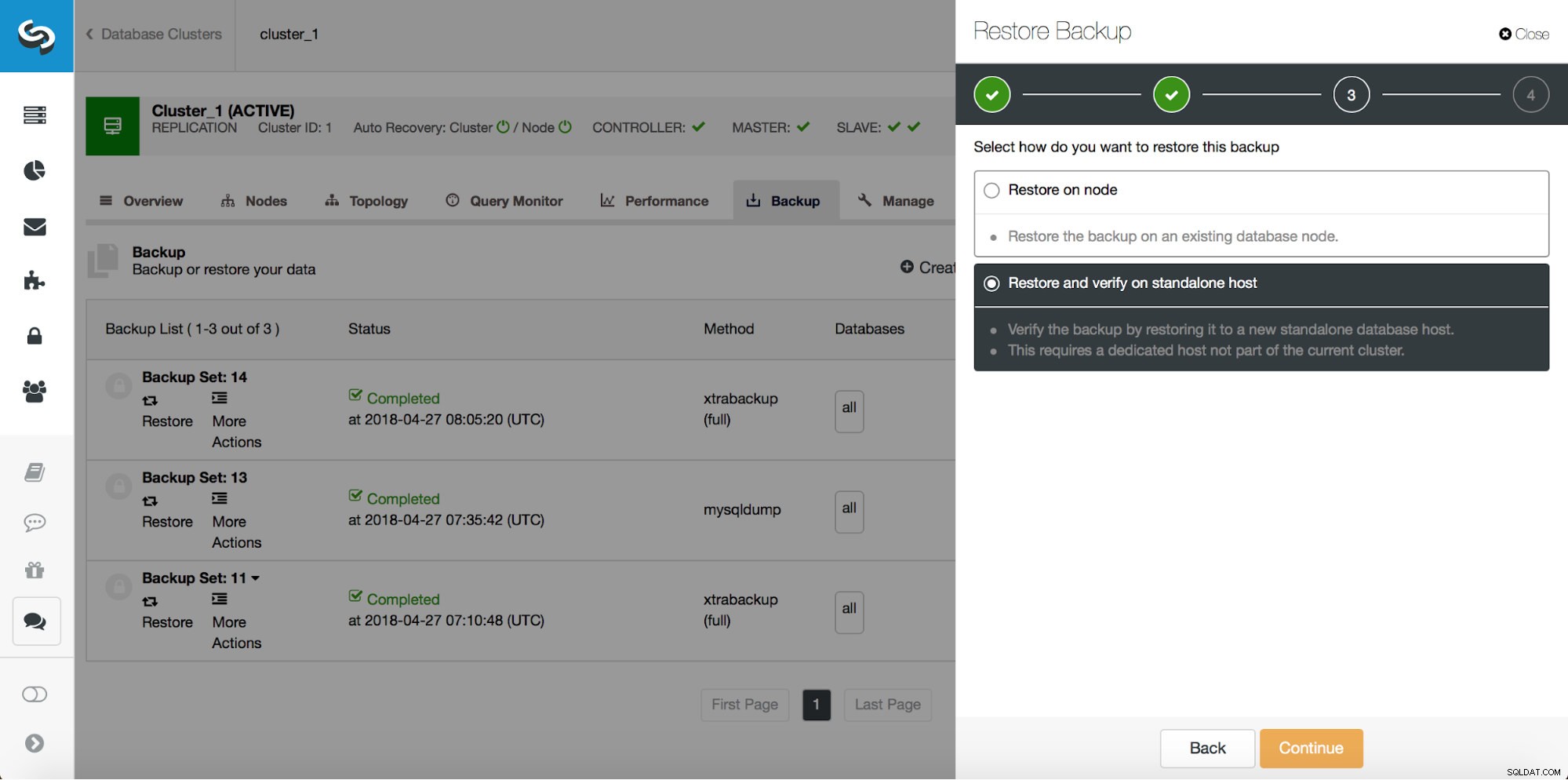
O backup é apenas o começo - você poderá restaurar seus dados para o ponto em que o backup foi feito, mas, provavelmente, os dados foram removidos após esse período. Apenas restaurando os dados ausentes do backup mais recente, você pode perder todos os dados que foram alterados após o backup. Para evitar isso, você deve implementar a Recuperação Point-In-Time. Para o MySQL, basicamente significa que você terá que usar logs binários para reproduzir todas as alterações que aconteceram entre o momento do backup e o evento de perda de dados. A captura de tela abaixo mostra como o ClusterControl pode ajudar com isso.
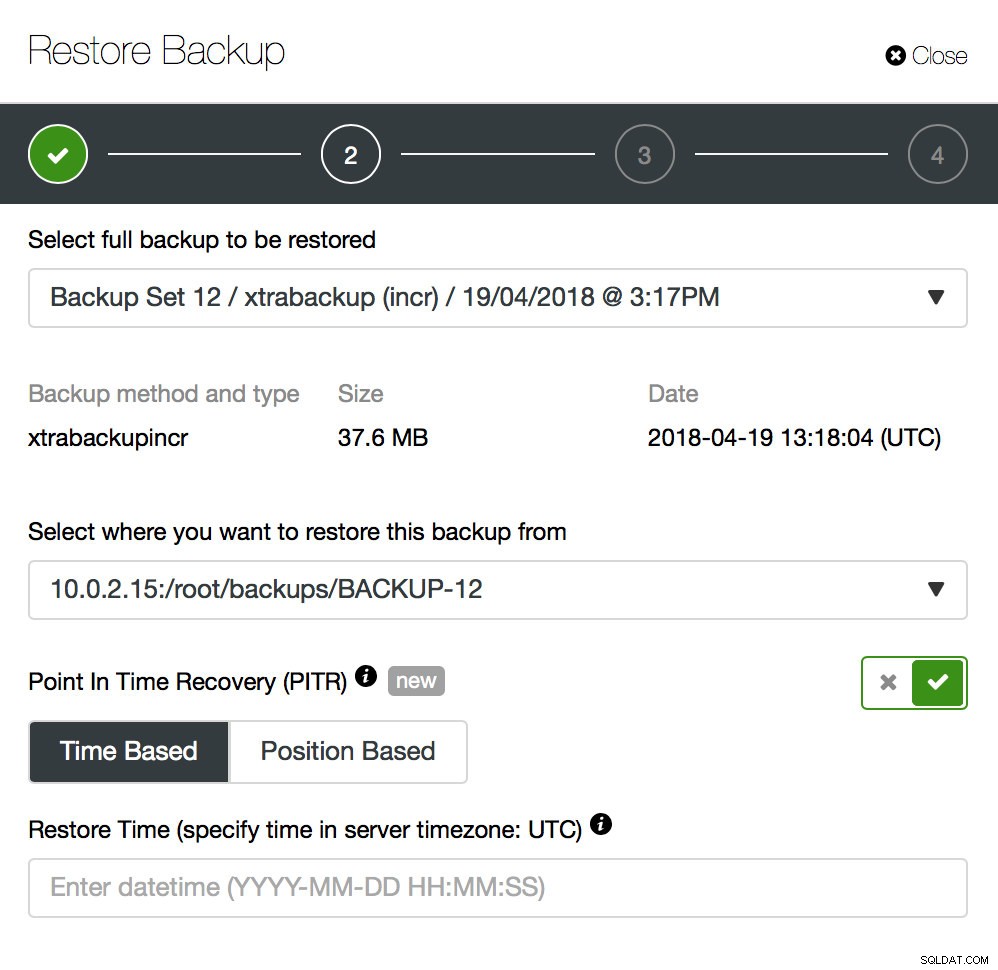
O que você terá que fazer é restaurar esse backup até o momento anterior à perda de dados. Você terá que restaurá-lo em um host separado para não fazer alterações no cluster de produção. Depois de restaurar o backup, você pode fazer login nesse host, encontrar os dados ausentes, despejá-los e restaurá-los no cluster de produção.
Escravo Atrasado
Todos os métodos que discutimos acima têm um ponto problemático comum - leva tempo para restaurar os dados. Pode levar mais tempo, quando você restaura todos os dados e tenta despejar apenas a parte interessante. Pode levar menos tempo se você tiver backup lógico e puder detalhar rapidamente os dados que deseja restaurar, mas não é uma tarefa rápida. Você ainda precisa encontrar algumas linhas em um arquivo de texto grande. Quanto maior, mais complicada fica a tarefa - às vezes, o tamanho do arquivo torna todas as ações mais lentas. Um método para evitar esses problemas é ter um escravo atrasado. Os escravos normalmente tentam manter-se atualizados com o mestre, mas também é possível configurá-los para que mantenham distância do mestre. Na captura de tela abaixo, você pode ver como usar o ClusterControl para implantar esse escravo:
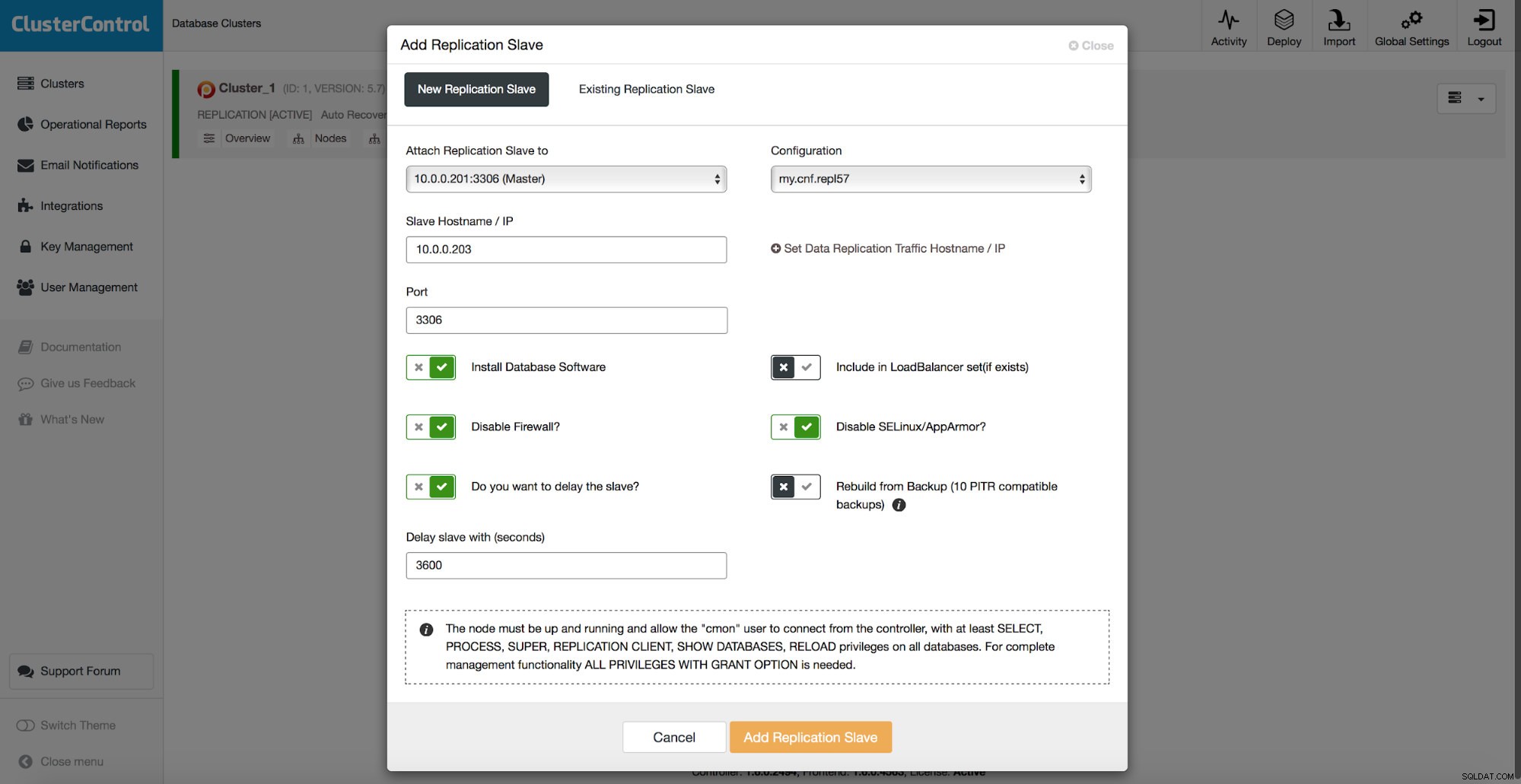
Resumindo, temos aqui a opção de adicionar um escravo de replicação à configuração do banco de dados e configurá-lo para ser atrasado. Na captura de tela acima, o escravo será atrasado em 3600 segundos, que é uma hora. Isso permite que você use esse escravo para recuperar os dados removidos até uma hora da exclusão dos dados. Você não terá que restaurar um backup, será suficiente executar mysqldump ou SELECT ... INTO OUTFILE para os dados ausentes e você obterá os dados para restaurar em seu cluster de produção.
Restaurando dados
Nesta seção, veremos alguns exemplos de exclusão acidental de dados e como você pode se recuperar deles. Abordaremos a recuperação de uma perda total de dados, também mostraremos como recuperar de uma perda parcial de dados ao usar backups físicos e lógicos. Finalmente, mostraremos como restaurar linhas excluídas acidentalmente se você tiver um escravo atrasado em sua configuração.
Perda total de dados
Acidental “rm -rf” ou “DROP SCHEMA myonlyschema;” foi executado e você acabou sem dados. Se você também removeu arquivos que não sejam do diretório de dados do MySQL, pode ser necessário reprovisionar o host. Para manter as coisas mais simples, vamos supor que apenas o MySQL foi impactado. Vamos considerar dois casos, com um escravo atrasado e sem um.
Sem escravo atrasado
Nesse caso, a única coisa que podemos fazer é restaurar o último backup físico. Como todos os nossos dados foram removidos, não precisamos nos preocupar com a atividade que aconteceu após a perda de dados, porque sem dados, não há atividade. Devemos estar preocupados com a atividade que aconteceu após o backup. Isso significa que temos que fazer uma restauração Point-in-Time. Obviamente, levará mais tempo do que apenas restaurar os dados do backup. Se trazer seu banco de dados rapidamente é mais crucial do que restaurar todos os dados, você também pode restaurar um backup e ficar bem com ele.
Em primeiro lugar, se você ainda tiver acesso a logs binários no servidor que deseja restaurar, poderá usá-los para PITR. Primeiro, queremos converter a parte relevante dos logs binários em um arquivo de texto para investigação adicional. Sabemos que a perda de dados ocorreu depois das 13:00:00. Primeiro, vamos verificar qual arquivo binlog devemos investigar:
example@sqldat.com:~# ls -alh /var/lib/mysql/binlog.*
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:32 /var/lib/mysql/binlog.000001
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:33 /var/lib/mysql/binlog.000002
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:35 /var/lib/mysql/binlog.000003
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:38 /var/lib/mysql/binlog.000004
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:39 /var/lib/mysql/binlog.000005
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:41 /var/lib/mysql/binlog.000006
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:43 /var/lib/mysql/binlog.000007
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:45 /var/lib/mysql/binlog.000008
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:47 /var/lib/mysql/binlog.000009
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:49 /var/lib/mysql/binlog.000010
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:51 /var/lib/mysql/binlog.000011
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:53 /var/lib/mysql/binlog.000012
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:55 /var/lib/mysql/binlog.000013
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:57 /var/lib/mysql/binlog.000014
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:59 /var/lib/mysql/binlog.000015
-rw-r----- 1 mysql mysql 306M Apr 23 13:18 /var/lib/mysql/binlog.000016Como pode ser visto, estamos interessados no último arquivo binlog.
example@sqldat.com:~# mysqlbinlog --start-datetime='2018-04-23 13:00:00' --verbose /var/lib/mysql/binlog.000016 > sql.outUma vez feito, vamos dar uma olhada no conteúdo deste arquivo. Vamos procurar por 'drop schema' no vim. Aqui está uma parte relevante do arquivo:
# at 320358785
#180423 13:18:58 server id 1 end_log_pos 320358850 CRC32 0x0893ac86 GTID last_committed=307804 sequence_number=307805 rbr_only=no
SET @@SESSION.GTID_NEXT= '52d08e9d-46d2-11e8-aa17-080027e8bf1b:443415'/*!*/;
# at 320358850
#180423 13:18:58 server id 1 end_log_pos 320358946 CRC32 0x487ab38e Query thread_id=55 exec_time=1 error_code=0
SET TIMESTAMP=1524489538/*!*/;
/*!\C utf8 *//*!*/;
SET @@session.character_set_client=33,@@session.collation_connection=33,@@session.collation_server=8/*!*/;
drop schema sbtest
/*!*/;Como podemos ver, queremos restaurar até a posição 320358785. Podemos passar esses dados para a UI do ClusterControl:
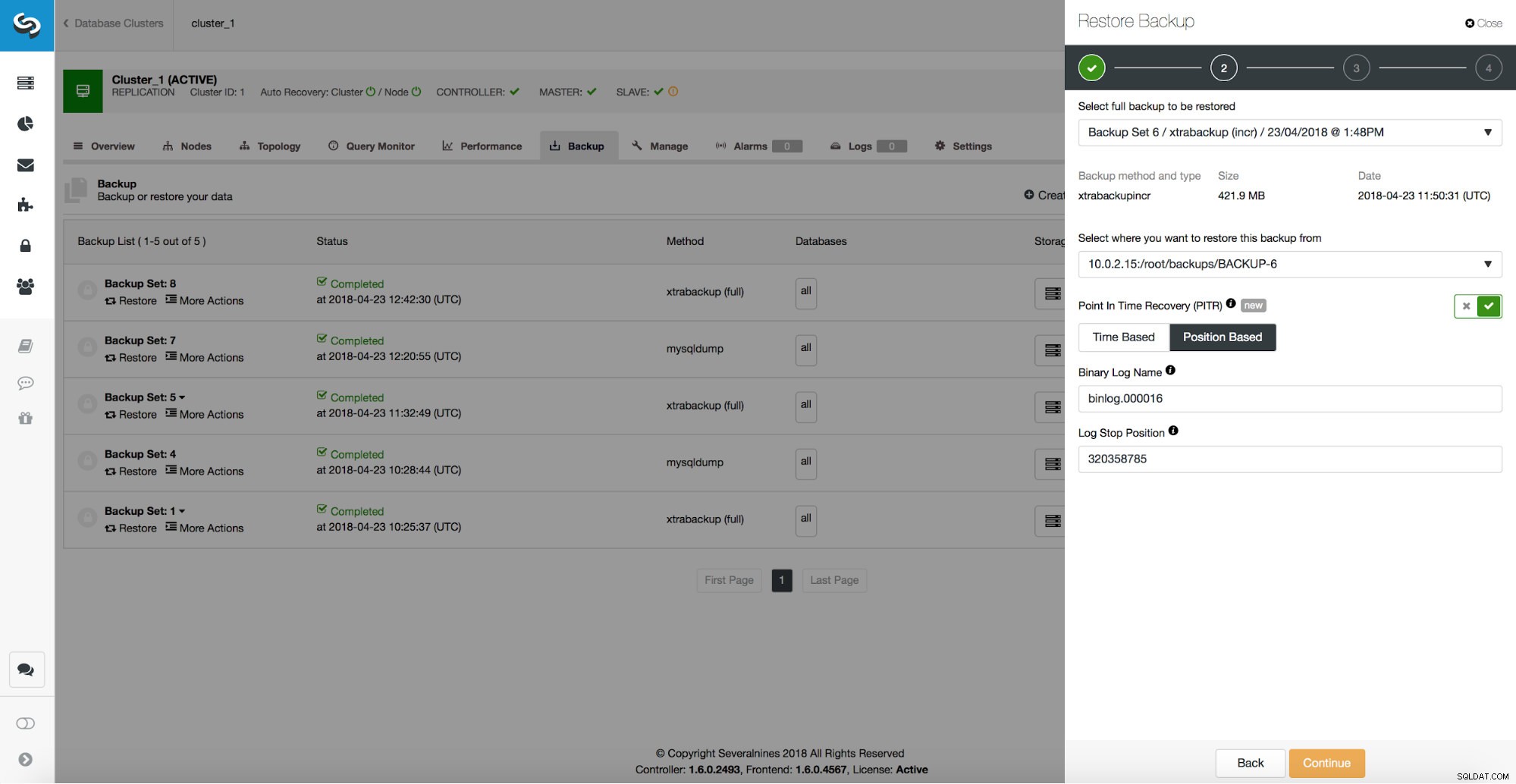
Escravo Atrasado
Se tivermos um escravo atrasado e esse host for suficiente para lidar com todo o tráfego, podemos usá-lo e promovê-lo a mestre. Primeiro, porém, temos que nos certificar de que ele alcançou o antigo mestre até o ponto da perda de dados. Usaremos alguns CLI aqui para fazer isso acontecer. Primeiro, precisamos descobrir em qual posição ocorreu a perda de dados. Então vamos parar o escravo e deixá-lo rodar até o evento de perda de dados. Mostramos como obter a posição correta na seção anterior - examinando logs binários. Podemos usar essa posição (binlog.000016, posição 320358785) ou, se usarmos um escravo multithread, devemos usar o GTID do evento de perda de dados (52d08e9d-46d2-11e8-aa17-080027e8bf1b:443415) e repetir as consultas até aquele GTID.
Primeiro, vamos parar o escravo e desabilitar o atraso:
mysql> STOP SLAVE;
Query OK, 0 rows affected (0.01 sec)
mysql> CHANGE MASTER TO MASTER_DELAY = 0;
Query OK, 0 rows affected (0.02 sec)Então podemos iniciá-lo para uma determinada posição de log binário.
mysql> START SLAVE UNTIL MASTER_LOG_FILE='binlog.000016', MASTER_LOG_POS=320358785;
Query OK, 0 rows affected (0.01 sec)Se quisermos usar o GTID, o comando será diferente:
mysql> START SLAVE UNTIL SQL_BEFORE_GTIDS = ‘52d08e9d-46d2-11e8-aa17-080027e8bf1b:443415’;
Query OK, 0 rows affected (0.01 sec)Uma vez que a replicação parou (ou seja, todos os eventos que solicitamos foram executados), devemos verificar se o host contém os dados ausentes. Nesse caso, você pode promovê-lo a mestre e, em seguida, reconstruir outros hosts usando o novo mestre como fonte de dados.
Essa nem sempre é a melhor opção. Tudo depende de quão atrasado seu escravo está - se estiver atrasado em algumas horas, pode não fazer sentido esperar que ele o alcance, especialmente se o tráfego de gravação for pesado em seu ambiente. Nesse caso, é mais provável que seja mais rápido reconstruir hosts usando backup físico. Por outro lado, se você tiver um volume de tráfego bastante pequeno, essa pode ser uma boa maneira de corrigir o problema rapidamente, promover um novo mestre e continuar atendendo ao tráfego, enquanto o restante dos nós está sendo reconstruído em segundo plano .
Perda de dados parcial - Backup físico
Em caso de perda parcial de dados, os backups físicos podem ser ineficientes, mas, como esses são os tipos mais comuns de backup, é muito importante saber usá-los para restauração parcial. O primeiro passo será sempre restaurar um backup até um momento antes do evento de perda de dados. Também é muito importante restaurá-lo em um host separado. O ClusterControl usa o xtrabackup para backups físicos, então mostraremos como usá-lo. Vamos supor que executamos a seguinte consulta incorreta:
DELETE FROM sbtest1 WHERE id < 23146;Queríamos excluir apenas uma única linha (‘=’ na cláusula WHERE), em vez disso, excluímos várias delas (
mysqlbinlog --verbose /var/lib/mysql/binlog.000003 > bin.outAgora, vamos olhar para o arquivo de saída e ver o que podemos encontrar lá. Estamos usando replicação baseada em linha, portanto, não veremos o SQL exato que foi executado. Em vez disso (desde que usemos o sinalizador --verbose para mysqlbinlog), veremos eventos como abaixo:
### DELETE FROM `sbtest`.`sbtest1`
### WHERE
### @1=999296
### @2=1009782
### @3='96260841950-70557543083-97211136584-70982238821-52320653831-03705501677-77169427072-31113899105-45148058587-70555151875'
### @4='84527471555-75554439500-82168020167-12926542460-82869925404'Como pode ser visto, o MySQL identifica linhas para excluir usando a condição WHERE muito precisa. Sinais misteriosos no comentário legível por humanos, “@1”, “@2”, significam “primeira coluna”, “segunda coluna”. Sabemos que a primeira coluna é 'id', que é algo que nos interessa. Precisamos encontrar um grande evento DELETE em uma tabela 'sbtest1'. Os comentários a seguir devem mencionar id de 1, depois id de '2', depois '3' e assim por diante - tudo até id de '23145'. Todos devem ser executados em uma única transação (único evento em um log binário). Depois de analisar a saída usando ‘less’, encontramos:
### DELETE FROM `sbtest`.`sbtest1`
### WHERE
### @1=1
### @2=1006036
### @3='123'
### @4='43683718329-48150560094-43449649167-51455516141-06448225399'
### DELETE FROM `sbtest`.`sbtest1`
### WHERE
### @1=2
### @2=1008980
### @3='123'
### @4='05603373460-16140454933-50476449060-04937808333-32421752305'O evento, ao qual esses comentários estão anexados, começou em:
#180427 8:09:21 server id 1 end_log_pos 29600687 CRC32 0x8cfdd6ae Xid = 307686
COMMIT/*!*/;
# at 29600687
#180427 8:09:21 server id 1 end_log_pos 29600752 CRC32 0xb5aa18ba GTID last_committed=42844 sequence_number=42845 rbr_only=yes
/*!50718 SET TRANSACTION ISOLATION LEVEL READ COMMITTED*//*!*/;
SET @@SESSION.GTID_NEXT= '0c695e13-4931-11e8-9f2f-080027e8bf1b:55893'/*!*/;
# at 29600752
#180427 8:09:21 server id 1 end_log_pos 29600826 CRC32 0xc7b71da5 Query thread_id=44 exec_time=0 error_code=0
SET TIMESTAMP=1524816561/*!*/;
/*!\C utf8 *//*!*/;
SET @@session.character_set_client=33,@@session.collation_connection=33,@@session.collation_server=8/*!*/;
BEGIN
/*!*/;
# at 29600826Então, queremos restaurar o backup até o commit anterior na posição 29600687. Vamos fazer isso agora. Usaremos um servidor externo para isso. Restauraremos o backup até essa posição e manteremos o servidor de restauração funcionando para que possamos extrair posteriormente os dados ausentes.
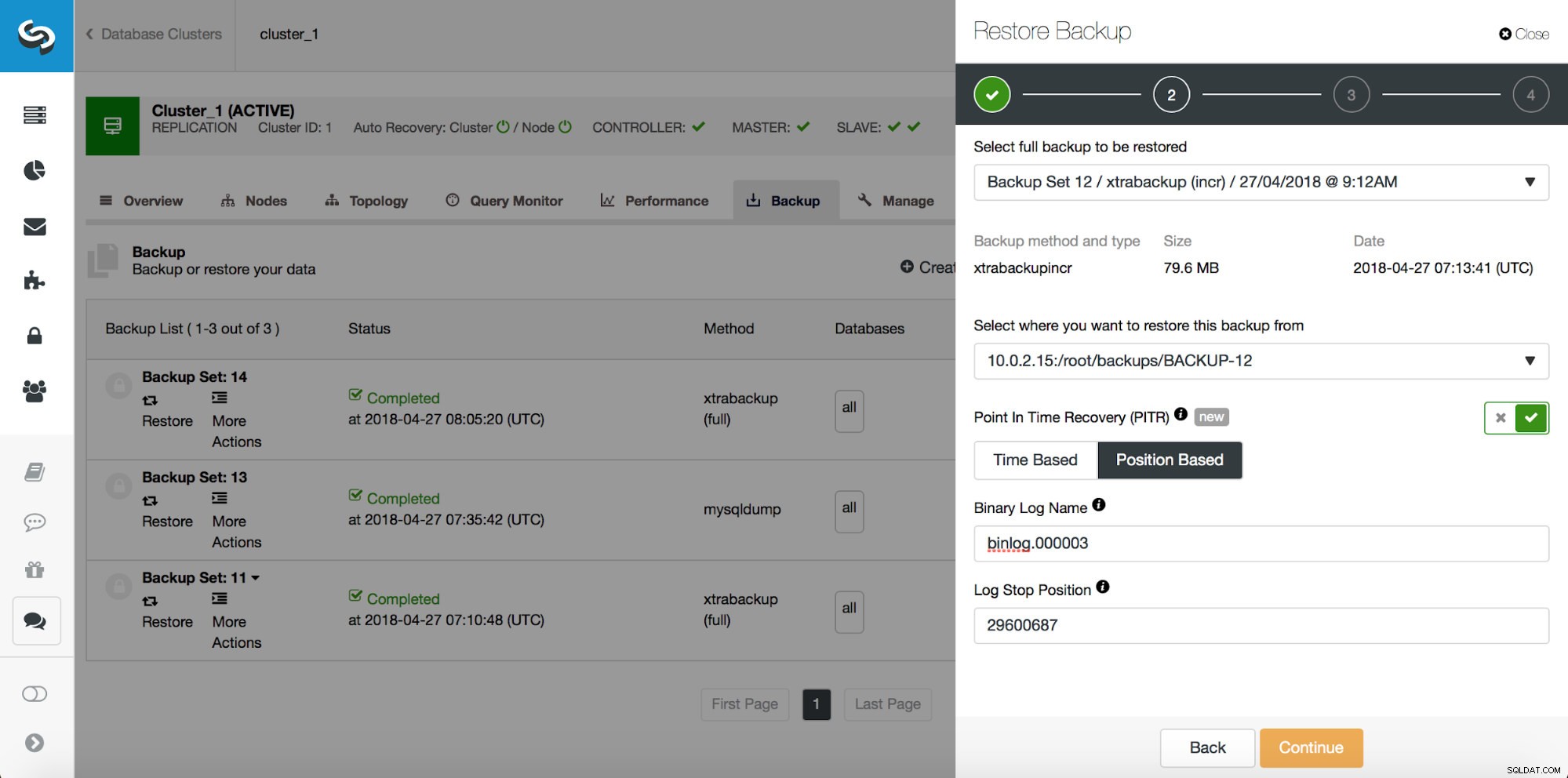
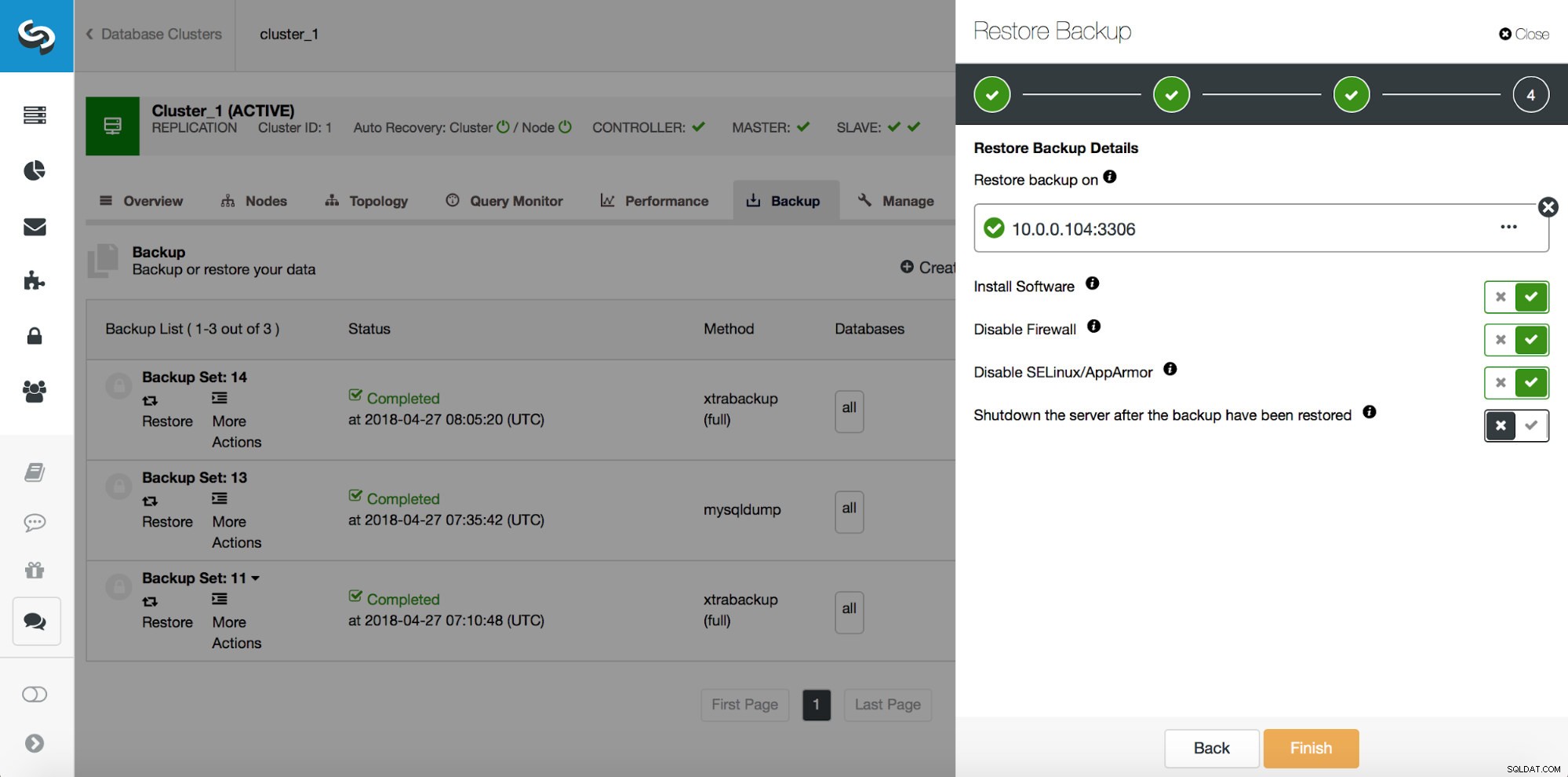
Depois que a restauração for concluída, vamos garantir que nossos dados tenham sido recuperados:
mysql> SELECT COUNT(*) FROM sbtest.sbtest1 WHERE id < 23146;
+----------+
| COUNT(*) |
+----------+
| 23145 |
+----------+
1 row in set (0.03 sec)Parece bom. Agora podemos extrair esses dados em um arquivo que carregaremos de volta no mestre.
mysql> SELECT * FROM sbtest.sbtest1 WHERE id < 23146 INTO OUTFILE 'missing.sql';
ERROR 1290 (HY000): The MySQL server is running with the --secure-file-priv option so it cannot execute this statementAlgo não está certo - isso ocorre porque o servidor está configurado para poder gravar arquivos apenas em um local específico - é tudo uma questão de segurança, não queremos permitir que os usuários salvem conteúdo em qualquer lugar que desejarem. Vamos verificar onde podemos salvar nosso arquivo:
mysql> SHOW VARIABLES LIKE "secure_file_priv";
+------------------+-----------------------+
| Variable_name | Value |
+------------------+-----------------------+
| secure_file_priv | /var/lib/mysql-files/ |
+------------------+-----------------------+
1 row in set (0.13 sec)Ok, vamos tentar mais uma vez:
mysql> SELECT * FROM sbtest.sbtest1 WHERE id < 23146 INTO OUTFILE '/var/lib/mysql-files/missing.sql';
Query OK, 23145 rows affected (0.05 sec)Agora parece muito melhor. Vamos copiar os dados para o mestre:
example@sqldat.com:~# scp /var/lib/mysql-files/missing.sql 10.0.0.101:/var/lib/mysql-files/
missing.sql 100% 1744KB 1.7MB/s 00:00Agora é hora de carregar as linhas ausentes no mestre e testar se deu certo:
mysql> LOAD DATA INFILE '/var/lib/mysql-files/missing.sql' INTO TABLE sbtest.sbtest1;
Query OK, 23145 rows affected (2.22 sec)
Records: 23145 Deleted: 0 Skipped: 0 Warnings: 0
mysql> SELECT COUNT(*) FROM sbtest.sbtest1 WHERE id < 23146;
+----------+
| COUNT(*) |
+----------+
| 23145 |
+----------+
1 row in set (0.00 sec)Isso é tudo, restauramos nossos dados ausentes.
Perda de dados parcial - Backup lógico
Na seção anterior, restauramos os dados perdidos usando backup físico e um servidor externo. E se tivéssemos um backup lógico criado? Vamos dar uma olhada. Primeiro, vamos verificar se temos um backup lógico:
example@sqldat.com:~# ls -alh /root/backups/BACKUP-13/
total 5.8G
drwx------ 2 root root 4.0K Apr 27 07:35 .
drwxr-x--- 5 root root 4.0K Apr 27 07:14 ..
-rw-r--r-- 1 root root 2.4K Apr 27 07:35 cmon_backup.metadata
-rw------- 1 root root 5.8G Apr 27 07:35 mysqldump_2018-04-27_071434_complete.sql.gzSim, está lá. Agora, é hora de descompactá-lo.
example@sqldat.com:~# mkdir /root/restore
example@sqldat.com:~# zcat /root/backups/BACKUP-13/mysqldump_2018-04-27_071434_complete.sql.gz > /root/restore/backup.sqlAo examiná-lo, você verá que os dados são armazenados no formato INSERT de vários valores. Por exemplo:
INSERT INTO `sbtest1` VALUES (1,1006036,'18034632456-32298647298-82351096178-60420120042-90070228681-93395382793-96740777141-18710455882-88896678134-41810932745','43683718329-48150560094-43449649167-51455516141-06448225399'),(2,1008980,'69708345057-48265944193-91002879830-11554672482-35576538285-03657113365-90301319612-18462263634-56608104414-27254248188','05603373460-16140454933-50476449060-04937808333-32421752305')Tudo o que precisamos fazer agora é identificar onde nossa tabela está localizada e onde as linhas que nos interessam estão armazenadas. Primeiro, conhecendo os padrões mysqldump (soltar tabela, criar uma nova, desabilitar índices, inserir dados) vamos descobrir qual linha contém a instrução CREATE TABLE para a tabela ‘sbtest1’:
example@sqldat.com:~/restore# grep -n "CREATE TABLE \`sbtest1\`" backup.sql > out
example@sqldat.com:~/restore# cat out
971:CREATE TABLE `sbtest1` (Agora, usando um método de tentativa e erro, precisamos descobrir onde procurar nossas linhas. Mostraremos o comando final que criamos. O truque é tentar imprimir um intervalo diferente de linhas usando sed e, em seguida, verificar se a última linha contém linhas próximas, mas posteriores ao que estamos procurando. No comando abaixo, procuramos as linhas entre 971 (CREATE TABLE) e 993. Também pedimos ao sed para sair quando chegar à linha 994, pois o restante do arquivo não nos interessa:
example@sqldat.com:~/restore# sed -n '971,993p; 994q' backup.sql > 1.sql
example@sqldat.com:~/restore# tail -n 1 1.sql | lessA saída se parece com abaixo:
INSERT INTO `sbtest1` VALUES (31351,1007187,'23938390896-69688180281-37975364313-05234865797-89299459691-74476188805-03642252162-40036598389-45190639324-97494758464','60596247401-06173974673-08009930825-94560626453-54686757363'),Isso significa que nosso intervalo de linhas (até a linha com id de 23145) está próximo. Em seguida, trata-se da limpeza manual do arquivo. Queremos que comece com a primeira linha que precisamos restaurar:
INSERT INTO `sbtest1` VALUES (1,1006036,'18034632456-32298647298-82351096178-60420120042-90070228681-93395382793-96740777141-18710455882-88896678134-41810932745','43683718329-48150560094-43449649167-51455516141-06448225399')E termine com a última linha para restaurar:
(23145,1001595,'37250617862-83193638873-99290491872-89366212365-12327992016-32030298805-08821519929-92162259650-88126148247-75122945670','60801103752-29862888956-47063830789-71811451101-27773551230');Tivemos que cortar alguns dos dados desnecessários (é uma inserção de várias linhas), mas depois de tudo isso temos um arquivo que podemos carregar de volta no mestre.
example@sqldat.com:~/restore# cat 1.sql | mysql -usbtest -psbtest -h10.0.0.101 sbtest
mysql: [Warning] Using a password on the command line interface can be insecure.Por fim, última verificação:
mysql> SELECT COUNT(*) FROM sbtest.sbtest1 WHERE id < 23146;
+----------+
| COUNT(*) |
+----------+
| 23145 |
+----------+
1 row in set (0.00 sec)Tudo está bem, os dados foram restaurados.
Perda de dados parcial, escravo atrasado
Neste caso, não passaremos por todo o processo. Já descrevemos como identificar a posição de um evento de perda de dados nos logs binários. Também descrevemos como parar um escravo atrasado e iniciar a replicação novamente, até um ponto antes do evento de perda de dados. Também explicamos como usar SELECT INTO OUTFILE e LOAD DATA INFILE para exportar dados de um servidor externo e carregá-los no mestre. Isso é tudo que você precisa. Enquanto os dados ainda estiverem no escravo atrasado, você deve pará-lo. Então você precisa localizar a posição antes do evento de perda de dados, iniciar o escravo até esse ponto e, uma vez feito isso, usar o escravo atrasado para extrair os dados que foram excluídos, copiar o arquivo para o mestre e carregá-lo para restaurar os dados .
Conclusão
Restaurar dados perdidos não é divertido, mas se você seguir as etapas que passamos neste blog, você terá uma boa chance de recuperar o que perdeu.



