O T-SQL Tuesday deste mês está sendo apresentado por Mike Donnelly (@SQLMD), e ele resume o tópico da seguinte forma:
O tópico deste mês é direto, mas muito aberto. Você deve aprender algo novo e, em seguida, escrever uma postagem no blog explicando isso.
Bem, a partir do momento em que Mike anunciou o assunto, eu realmente não quis aprender nada de novo, e como o fim de semana se aproximava e eu sabia que segunda-feira ia me agredir como jurado, pensei que teria que sentar mês fora.
Então, Martin Smith me ensinou algo que eu nunca soube, ou sabia há muito tempo, mas esqueci (às vezes você não sabe o que não sabe, e às vezes você não consegue lembrar o que nunca soube e o que não pode lembrar). Minha lembrança foi que alterar uma coluna de
NOT NULL para NULL deveria ser uma operação somente de metadados, com gravações em qualquer página sendo adiadas até que a página seja atualizada por outros motivos, pois o NULL bitmap não precisaria existir até que pelo menos uma linha pudesse se tornar NULL . Nesse mesmo post, @ypercube também me lembrou desta citação pertinente do Books Online (erro e tudo):
A alteração de uma coluna de NOT NULL para NULL não é suportada como uma operação online quando a coluna alterada é referenciada por índices não clusterizados.
"Não é uma operação online" pode ser interpretada como "não é uma operação somente de metadados" - o que significa que na verdade será uma operação de tamanho de dados (quanto maior o índice, mais tempo levará).
Eu me propus a provar isso com um experimento bastante simples (mas demorado) contra uma coluna de destino específica para converter de
NOT NULL para NULL . Eu criaria 3 tabelas, todas com uma chave primária clusterizada, mas cada uma com um índice não clusterizado diferente. Um teria a coluna de destino como uma coluna de chave, o segundo como um INCLUDE coluna e o terceiro não faria referência à coluna de destino. Aqui estão minhas tabelas e como eu as preenchi:
CREATE TABLE dbo.test1
(
a INT NOT NULL, b INT NOT NULL, c BIGINT NOT NULL,
CONSTRAINT pk_t1 PRIMARY KEY (a,b)
);
GO
CREATE NONCLUSTERED INDEX ix1 ON dbo.test1(b,c);
GO
CREATE TABLE dbo.test2
(
a INT NOT NULL, b INT NOT NULL, c BIGINT NOT NULL,
CONSTRAINT pk_t2 PRIMARY KEY (a,b)
);
GO
CREATE NONCLUSTERED INDEX ix2 ON dbo.test2(b) INCLUDE(c);
GO
CREATE TABLE dbo.test3
(
a INT NOT NULL, b INT NOT NULL, c BIGINT NOT NULL,
CONSTRAINT pk_t3 PRIMARY KEY (a,b)
);
GO
CREATE NONCLUSTERED INDEX ix3 ON dbo.test3(b);
GO
INSERT dbo.test1(a,b,c) -- repeat for test2 / test3
SELECT n1, n2, ABS(n2)-ABS(n1)
FROM
(
SELECT TOP (100000) s1.[object_id], s2.[object_id]
FROM master.sys.all_objects AS s1
CROSS JOIN master.sys.all_objects AS s2
GROUP BY s1.[object_id], s2.[object_id]
) AS n(n1, n2); Cada tabela tinha 100.000 linhas, os índices clusterizados tinham 310 páginas e os índices não clusterizados tinham 272 páginas (
test1 e test2 ) ou 174 páginas (test3 ). (Esses valores são fáceis de obter em sys.dm_db_index_physical_stats .) Em seguida, eu precisava de uma maneira simples de capturar as operações registradas no nível da página – escolhi
sys.fn_dblog() , embora eu pudesse ter cavado mais fundo e examinado as páginas diretamente. Eu não me incomodei em mexer com valores de LSN para passar para a função, já que eu não estava executando isso em produção e não me importava muito com desempenho, então após os testes eu apenas despejei os resultados da função, excluindo quaisquer dados que foi registrado antes do ALTER TABLE operações. -- establish an exclusion set SELECT * INTO #x FROM sys.fn_dblog(NULL, NULL);
Agora eu podia fazer meus testes, que eram bem mais simples que a configuração.
ALTER TABLE dbo.test1 ALTER COLUMN c BIGINT NULL; ALTER TABLE dbo.test2 ALTER COLUMN c BIGINT NULL; ALTER TABLE dbo.test3 ALTER COLUMN c BIGINT NULL;
Agora eu poderia examinar as operações que foram registradas em cada caso:
SELECT AllocUnitName, [Operation], Context, c = COUNT(*)
FROM
(
SELECT * FROM sys.fn_dblog(NULL, NULL)
WHERE [Operation] = N'LOP_FORMAT_PAGE'
AND AllocUnitName LIKE N'dbo.test%'
EXCEPT
SELECT * FROM #x
) AS x
GROUP BY AllocUnitName, [Operation], Context
ORDER BY AllocUnitName, [Operation], Context; Os resultados parecem sugerir que cada página folha do índice não clusterizado é tocada para os casos em que a coluna de destino foi mencionada no índice de alguma forma, mas nenhuma operação ocorre para o caso em que a coluna de destino não é mencionada em nenhum índice não agrupado:
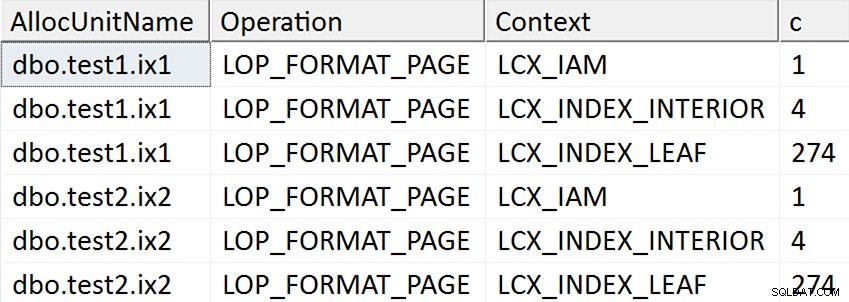
De fato, nos dois primeiros casos, novas páginas são alocadas (você pode validar isso com
DBCC IND , como Spörri fez em sua resposta), então a operação pode ocorrer online, mas isso não significa que seja rápido (já que ainda precisa escrever uma cópia de todos esses dados e fazer o NULL mudança de bitmap como parte da escrita de cada nova página e registrar toda essa atividade). Acho que a maioria das pessoas suspeitaria que alterar uma coluna de
NOT NULL para NULL seria apenas metadados em todos os cenários, mas mostrei aqui que isso não é verdade se a coluna for referenciada por um índice não clusterizado (e coisas semelhantes acontecem se for uma chave ou INCLUDE coluna). Talvez esta operação também possa ser forçada a ser ONLINE no Banco de Dados SQL do Azure hoje ou será possível na próxima versão principal? Isso não necessariamente tornará as operações físicas reais mais rápidas, mas impedirá o bloqueio como resultado. Eu não testei esse cenário (e a análise se ele está realmente online é mais difícil no Azure de qualquer maneira), nem testei em um heap. Algo que eu possa revisitar em um post futuro. Enquanto isso, tenha cuidado com quaisquer suposições que você possa fazer sobre operações somente de metadados.