Recentemente, lançamos um novo site de suporte, onde você pode fazer perguntas, enviar comentários sobre produtos ou solicitações de recursos ou abrir tíquetes de suporte. Parte do objetivo era centralizar todos os locais onde estávamos atendendo a comunidade. Isso incluiu o site de perguntas e respostas SQLPerformance.com, onde Paul White, Hugo Kornelis e muitos outros têm ajudado a resolver suas questões mais complicadas de ajuste de consulta e plano de execução, desde fevereiro de 2013. Digo a você com sentimentos contraditórios que o O site de perguntas e respostas foi encerrado.
Há uma vantagem, no entanto. Agora você pode fazer essas perguntas difíceis no novo fórum de suporte. Se você está procurando o conteúdo antigo, bem, ele ainda está lá, mas parece um pouco diferente. Por uma variedade de razões que não vou abordar hoje, uma vez que decidimos encerrar o site de perguntas e respostas original, decidimos simplesmente hospedar todo o conteúdo existente em um site WordPress somente leitura, em vez de migrá-lo para o back-end do novo sítio.
Esta postagem não é sobre os motivos por trás dessa decisão.
Eu me senti muito mal com a rapidez com que o site de respostas teve que ficar offline, o DNS mudou e o conteúdo migrou. Como um banner de aviso foi implementado no site, mas o AnswerHub não o tornou visível, isso foi um choque para muitos usuários. Então, eu queria ter certeza de manter adequadamente o máximo de conteúdo possível, e queria que estivesse certo. Este post está aqui porque achei que seria interessante falar sobre o processo real, quantas peças diferentes de tecnologia estavam envolvidas para realizá-lo e mostrar o resultado. Não espero que nenhum de vocês se beneficie desse ponta a ponta, pois esse é um caminho de migração relativamente obscuro, mas mais como um exemplo de unir várias tecnologias para realizar uma tarefa. Também serve como um bom lembrete para mim mesmo de que muitas coisas não acabam sendo tão fáceis quanto parecem antes de você começar.
O TL;DR é o seguinte:gastei muito tempo e esforço para fazer o conteúdo arquivado parecer bom, embora ainda esteja tentando recuperar as últimas postagens que chegaram no final. Usei essas tecnologias:
- Perl
- SQL Server
- PowerShell
- Transmitir (FTP)
- HTML
- CSS
- C#
- MarkdownSharp
- phpMyAdmin
- MySQL
Daí o título. Se você quer um grande pedaço dos detalhes sangrentos, aqui estão eles. Se você tiver alguma dúvida ou feedback, entre em contato ou comente abaixo.
O AnswerHub forneceu um arquivo de despejo de 665 MB do banco de dados MySQL que hospedava o conteúdo de perguntas e respostas. Cada editor que tentei engasgou com isso, então primeiro tive que dividi-lo em um arquivo por tabela usando este prático script Perl de Jared Cheney. As tabelas que eu precisava eram chamadas de
network11_nodes (perguntas, respostas e comentários), network11_authoritables (usuários) e network11_managed_files (todos os anexos, incluindo uploads de planos):perl extract_sql.pl -t network11_nodes -r dump.sql>> nodes.sqlperl extract_sql.pl -t network11_authoritables -r dump.sql>> users.sql
perl extract_sql.pl -t network11_managed_files -r dump.sql>> files.sql
Agora, eles não eram extremamente rápidos para carregar no SSMS, mas pelo menos eu poderia usar Ctrl +H para alterar (por exemplo) isso:
CREATE TABLE `network11_managed_files` ( `c_id` bigint(20) NOT NULL, ... ); INSERT INTO `network11_managed_files` (`c_id`, ...) VALUES (1, ...);
Para isso:
CREATE TABLE dbo.files ( c_id bigint NOT NULL, ... ); INSERT dbo.files (c_id, ...) VALUES (1, ...);
Então eu poderia carregar os dados no SQL Server para que eu pudesse manipulá-los. E acredite, eu manipulei.
Em seguida, tive que recuperar todos os anexos. Veja, o arquivo de despejo do MySQL que recebi do fornecedor continha um zilhão de
INSERT instruções, mas nenhum dos arquivos de plano reais que os usuários enviaram — o banco de dados tinha apenas os caminhos relativos para os arquivos. Usei o T-SQL para criar uma série de comandos do PowerShell que chamariam Invoke-WebRequest para recuperar todos os arquivos e armazená-los localmente (muitas maneiras de esfolar este gato, mas isso foi muito fácil). A partir disso:SELECT 'Invoke-WebRequest -Uri ' + '"$($url)' + RTRIM(c_id) + '-' + c_name + '"' + ' -OutFile "E:\s\temp\' + RTRIM(c_id) + '-' + c_name + '";' FROM dbo.files WHERE LOWER(c_mime_type) LIKE 'application/%';
Isso gerou esse conjunto de comandos (junto com um pré-comando para resolver esse problema de TLS); a coisa toda correu bem rápido, mas eu não recomendo essa abordagem para qualquer combinação de {massive set of files} e/ou {low bandwidth}:
$AllProtocols = [System.Net.SecurityProtocolType]'Ssl3,Tls,Tls11,Tls12'; [System.Net.ServicePointManager]::SecurityProtocol = $AllProtocols; $u = "https://answers.sqlperformance.com/s/temp/"; Invoke-WebRequest -Uri "$($u)/1-proc.pesession" -OutFile "E:\s\temp\1-proc.pesession"; Invoke-WebRequest -Uri "$($u)/14-test.pesession" -OutFile "E:\s\temp\14-test.pesession"; Invoke-WebRequest -Uri "$($u)/15-a.QueryAnalysis" -OutFile "E:\s\temp\15-a.QueryAnalysis"; ...
Isso baixou quase todos os anexos, mas, reconhecidamente, alguns foram perdidos devido a erros no site antigo quando foram carregados inicialmente. Portanto, no novo site, você pode ver ocasionalmente uma referência a um anexo que não existe.
Então eu usei o Panic Transmit 5 para fazer o upload do
temp pasta para o novo site e agora, quando o conteúdo for carregado, links para /s/temp/1-proc.pesession continuará trabalhando. Em seguida, mudei para SSL. Para solicitar um certificado no novo site WordPress, tivemos que atualizar o DNS para answers.sqlperformance.com para apontar para o CNAME em nosso host WordPress, WPEngine. Foi uma espécie de galinha e ovo aqui - tivemos que sofrer algum tempo de inatividade para URLs https, que falhariam por nenhum certificado no novo site. Tudo bem porque o certificado do site antigo havia expirado, então, na verdade, não estávamos em pior situação. Eu também tive que esperar para fazer isso até que eu tivesse baixado todos os arquivos do site antigo, porque uma vez que o DNS virasse, não haveria como chegar até eles, exceto por alguma porta dos fundos.
Enquanto esperava a propagação do DNS, comecei a trabalhar na lógica para colocar todas as perguntas, respostas e comentários em algo consumível no WordPress. Não apenas os esquemas de tabela eram diferentes do WordPress, os tipos de entidades também são bem diferentes. Minha visão era combinar cada pergunta – e quaisquer respostas e/ou comentários – em um único post.
A parte complicada é que a tabela de nós contém apenas todos os três tipos de conteúdo na mesma tabela, com referências pai e pai original ("mestre"). Seu código de front-end provavelmente usa algum tipo de cursor para percorrer e exibir o conteúdo em ordem hierárquica e cronológica. Eu não teria esse luxo no WordPress, então tive que encadear o HTML de uma só vez. Apenas como exemplo, aqui está a aparência dos dados:
SELECT c_type, c_id, c_parent, oParent = c_originalParent, c_creation_date, c_title FROM dbo.nodes WHERE c_originalParent = 285; /* c_type c_id c_parent oParent c_creation_date accepted c_title ---------- ------ -------- ------- ---------------- -------- ------------------------- question 285 NULL 285 2013-02-13 16:30 why is the MERGE JOIN ... answer 287 285 285 2013-02-14 01:15 1 NULL comment 289 285 285 2013-02-14 13:35 NULL answer 293 285 285 2013-02-14 18:22 NULL comment 294 287 285 2013-02-14 18:29 NULL comment 298 285 285 2013-02-14 20:40 NULL comment 299 298 285 2013-02-14 18:29 NULL */
Eu não podia ordenar por id, ou tipo, ou por pai, pois às vezes um comentário vinha mais tarde em uma resposta anterior, a primeira resposta nem sempre seria a resposta aceita e assim por diante. Eu queria essa saída (onde
++ representa um nível de recuo):/* c_type c_id c_parent oParent c_creation_date reason ---------- ------ -------- ------- ---------------- ------------------------- question 285 NULL 285 2013-02-13 16:30 question is ALWAYS first ++comment 289 285 285 2013-02-14 13:35 comments on the question before answers answer 287 285 285 2013-02-14 01:15 first answer (accepted = 1) ++comment 294 287 285 2013-02-14 18:29 first comment on first answer ++comment 298 287 285 2013-02-14 20:40 second comment on first answer ++++comment 299 298 285 2013-02-14 18:29 reply to second comment on first answer answer 293 285 285 2013-02-14 18:22 second answer */
Comecei a escrever um CTE recursivo e,
DECLARE @foo TABLE
(
c_type varchar(255),
c_id int,
c_parent int,
oParent int,
accepted bit
);
INSERT @foo(c_type, c_id, c_parent, oParent, accepted) VALUES
('question', 285, NULL, 285, 0),
('answer', 287, 285 , 285, 1),
('comment', 289, 285 , 285, 0),
('comment', 294, 287 , 285, 0),
('comment', 298, 287 , 285, 0),
('comment', 299, 298 , 285, 0),
('answer', 293, 285 , 285, 0);
;WITH cte AS
(
SELECT
lvl = 0,
f.c_type,
f.c_id, f.c_parent, f.oParent,
Sort = CONVERT(varchar(255),RIGHT('00000' + CONVERT(varchar(5),f.c_id),5))
FROM @foo AS f WHERE f.c_parent IS NULL
UNION ALL
SELECT
lvl = c.lvl + 1,
c_type = CONVERT(varchar(255), CASE
WHEN f.accepted = 1 THEN 'accepted answer'
WHEN f.c_type = 'comment' THEN c.c_type + ' ' + f.c_type
ELSE f.c_type
END),
f.c_id, f.c_parent, f.oParent,
Sort = CONVERT(varchar(255),c.Sort + RIGHT('00000' + CONVERT(varchar(5),f.c_id),5))
FROM @foo AS f INNER JOIN cte AS c ON c.c_id = f.c_parent
)
SELECT lvl = CASE lvl WHEN 0 THEN 1 ELSE lvl END, c_type, c_id, c_parent, oParent, Sort
FROM cte
ORDER BY
oParent,
CASE
WHEN c_type LIKE 'question%' THEN 1 -- it's a question *or* a comment on the question
WHEN c_type LIKE 'accepted answer%' THEN 2 -- accepted answer *or* comment on accepted answer
ELSE 3 END,
Sort; Resultados:
/* lvl c_type c_id c_parent oParent Sort ---- --------------------------------- ----------- ----------- ----------- -------------------- 1 question 285 NULL 285 00285 1 question comment 289 285 285 0028500289 1 accepted answer 287 285 285 0028500287 2 accepted answer comment 294 287 285 002850028700294 2 accepted answer comment 298 287 285 002850028700298 3 accepted answer comment comment 299 298 285 00285002870029800299 1 answer 293 285 285 0028500293 */
Gênio. Eu localizei uma dúzia ou mais de outros, e fiquei feliz por estar passando para a próxima etapa. Agradeci profusamente a Andy várias vezes, mas deixe-me fazer de novo:Obrigado Andy!
Agora que eu poderia retornar todo o conjunto na ordem que eu gostaria, eu tive que realizar alguma manipulação da saída para aplicar elementos HTML e nomes de classe que me permitiriam marcar perguntas, respostas, comentários e recuo de forma significativa. O objetivo final era uma saída que se parecia com isso (e lembre-se, este é um dos casos mais simples):
<div class="question">
<span class="authorq" title=" Author : author name ">
<i class="fas fa-user"></i>Author name</span>
<span class="createdq" title=" February 13th, 2013 ">
<i class="fas fa-calendar-alt"></i>2013-02-13 16:30:36</span>
<div class=mainbodyq>I don't understand why the merge operator is passing over 4million
rows to the hash match operator when there is only 41K and 19K from other operators.
<div class=attach><i class="fas fa-file"></i>
<a target="_blank" href="/s/temp/254-tmp4DA0.queryanalysis" rel="noopener noreferrer">
/s/temp/254-tmp4DA0.queryanalysis</a>
</div>
</div>
<div class="comment indent1 ">
<div class=linecomment>
<span class="authorc" title=" Author : author name ">
<i class="fas fa-user"></i>author name</span>
<span class="createdc" title=" February 14th, 2013 ">
<i class="fas fa-calendar-alt"></i>2013-02-14 13:35:39</span>
</div>
<div class=mainbodyc>
I am still trying to understand the significant amount of rows from the MERGE operator.
Unless it's a result of a Cartesian product from the two inputs then finally the WHERE
predicate is applied to filter out the unmatched rows leaving the 4 million row count.
</div>
</div>
<div class="answer indent1 [accepted]">
<div class=lineanswer>
<span class="authora" title=" Author : author name ">
<i class="fas fa-user"></i>author name</span>
<span class="createda" title=" February 14th, 2013 ">
<i class="fas fa-calendar-alt"></i>2013-02-14 01:15:42</span>
</div>
<div class=mainbodya>
The reason for the large number of rows can be seen in the Plan Explorer tool tip for
the Merge Join operator:
<img src="/s/temp/259-sp.png" alt="Merge Join tool tip" />
...
</div>
</div>
</div> Não vou percorrer o número ridículo de iterações pelas quais tive que passar para chegar a uma forma confiável dessa saída para todos os mais de 5.000 itens (o que se traduziu em quase 1.000 postagens depois que tudo foi colado). Além disso, eu precisava gerá-los na forma de
INSERT declarações que eu poderia colar no phpMyAdmin no site WordPress, o que significava aderir ao seu diagrama de sintaxe bizarro. Essas declarações precisavam incluir outras informações adicionais exigidas pelo WordPress, mas não presentes ou precisas nos dados de origem (como post_type ). E esse console de administração expiraria devido a muitos dados, então eu tive que dividi-lo em ~ 750 inserções por vez. Aqui está o procedimento com o qual acabei (isso não é realmente para aprender nada específico, apenas uma demonstração de quanta manipulação dos dados importados foi necessária):CREATE /* OR ALTER */ PROCEDURE dbo.BuildMySQLInserts
@LowerBound int = 1,
@UpperBound int = 750
AS
BEGIN
SET NOCOUNT ON;
;WITH CTE AS
(
SELECT lvl = 0,
[type] = CONVERT(varchar(100),f.[type]),
f.id,
f.parent,
f.master_parent,
created = CONVERT(char(10), f.created, 120) + ' '
+ CONVERT(char(8), f.created, 108),
f.state,
Sort = CONVERT(varchar(100),RIGHT('0000000000'
+ CONVERT(varchar(10),f.id),10))
FROM dbo.foo AS f
WHERE f.type = 'question'
AND master_parent BETWEEN @LowerBound AND @UpperBound
UNION ALL
SELECT lvl = c.lvl + 1,
CONVERT(varchar(100),CASE
WHEN f.[state] = '[accepted]' THEN 'accepted answer'
WHEN f.type = 'comment' THEN c.type + ' ' + f.type
ELSE f.type
END),
f.id,
f.parent,
f.master_parent,
created = CONVERT(char(10), f.created, 120) + ' '
+ CONVERT(char(8), f.created, 108),
f.state,
Sort = CONVERT(varchar(100),c.sort + RIGHT('0000000000'
+ CONVERT(varchar(10),f.id),10))
FROM dbo.foo AS f
JOIN CTE AS c ON c.id = f.parent
)
SELECT
master_parent,
prefix = CASE WHEN lvl = 0 THEN
CONVERT(varchar(11), master_parent) + ', 3, ''' + created + ''', '''
+ created + ''',''' END,
bodypre = '<div class="' + COALESCE(c_type, RTRIM(LEFT([type],8)))
+ CASE WHEN c_type <> 'question' THEN ' indent' + RTRIM(lvl)
+ COALESCE(' ' + [state], '') ELSE '' END + '">'
+ CASE WHEN c_type <> 'question' THEN
'<div class=line' + c_type + '>' ELSE '' END
+ '<span class="author' + LEFT(c_type, 1) + '" title=" Author : '
+ REPLACE(REPLACE(Fullname,'''','\'''),'"','')
+ ' "><i class="fas fa-user"></i>' + REPLACE(Fullname,'''','\''') --"
+ '</span> <span class="created' + LEFT(c_type,1) + '" title=" '
+ DATENAME(MONTH, c_creation_date) + ' ' + RTRIM(DAY(c_creation_date))
+ CASE
WHEN DAY(c_creation_date) IN (1,21,31) THEN 'st'
WHEN DAY(c_creation_date) IN (2,22) THEN 'nd'
WHEN DAY(c_creation_date) IN (3,23) THEN 'rd' ELSE 'th' END
+ ', ' + RTRIM(YEAR(c_creation_date))
+ ' "><i class="fas fa-calendar-alt"></i>' + created + '</span>'
+ CASE WHEN c_type <> 'question' THEN '</div>' ELSE '' END,
body = '<div class=mainbody' + left(c_type,1) + '>'
+ REPLACE(REPLACE(c_body, char(39), '\' + char(39)), '’', '\' + char(39)),
bodypost = COALESCE(urls, '') + '</div></div>',--'
+ CASE WHEN c_type = 'question' THEN '</div>' ELSE '' END,
suffix = ''',''' + REPLACE(n.c_title, '''', '\''') + ''','''',''publish'',
''closed'',''closed'','''',''' + REPLACE(n.c_plug, '''', '\''')
+ ''','''','''',''' + created + ''',''' + created + ''','''',0,
''https://answers.sqlperformance.com/?p=' + CONVERT(varchar(11), master_parent)
+ ''', 0, ''post'','''',0);',
rn = RTRIM(ROW_NUMBER() OVER (PARTITION BY master_parent
ORDER BY master_parent,
CASE
WHEN [type] LIKE 'question%' THEN 1
WHEN [type] LIKE 'accepted answer%' THEN 2
ELSE 3
END,
Sort)),
c = RTRIM(COUNT(*) OVER (PARTITION BY master_parent))
FROM CTE
LEFT OUTER JOIN dbo.network11_nodes AS n
ON cte.id = n.c_id
LEFT OUTER JOIN dbo.Users AS u
ON n.c_author = u.UserID
LEFT OUTER JOIN
(
SELECT NodeID, urls = STRING_AGG('<div class=attach>
<i class="fas fa-file'
+ CASE WHEN c_mime_type IN ('image/jpeg','image/png')
THEN '-image' ELSE '' END
+ '"></i><a target="_blank" href=' + url + ' rel="noopener noreferrer">' + url + '</a></div>', '\n')
FROM dbo.Attachments
GROUP BY NodeID
) AS a
ON n.c_id = a.NodeID
ORDER BY master_parent,
CASE
WHEN [type] LIKE 'question%' THEN 1
WHEN [type] LIKE 'accepted answer%' THEN 2
ELSE 3
END,
Sort;
END
GO A saída disso não está completa e ainda não está pronta para ser inserida no WordPress:
 Saída de amostra (clique para ampliar)
Saída de amostra (clique para ampliar) Eu precisaria de alguma ajuda adicional do C# para transformar o conteúdo real (incluindo markdown) em HTML e CSS que eu pudesse controlar melhor e escrever a saída (um monte de
INSERT instruções que incluíam um monte de código HTML) para arquivos no disco que eu poderia abrir e colar no phpMyAdmin. Para o HTML, texto simples + markdown que começou assim:Há um [post aqui no blog][1] que fala sobre isso, e também [este post](https://somewhere).
SELECT algo de dbo.sometable;
[1]:https://em outro lugar
Precisaria se tornar isso:
Há uma postagem de blog aqui que fala sobre isso, e também esta postagem .
SELECIONE algo de dbo.sometable; Para conseguir isso, recrutei a ajuda do MarkdownSharp, uma biblioteca de código aberto originada no Stack Overflow que lida com grande parte da conversão de markdown para HTML. Foi um bom ajuste para minhas necessidades, mas não perfeito; Eu ainda teria que realizar mais manipulações:
- MarkdownSharp não permite coisas como
target=_blank, então eu mesmo teria que injetá-los após o processamento; - código (qualquer coisa prefixada com quatro espaços) herda os wrappers
using System.Text; using System.Data; using System.Data.SqlClient; using MarkdownSharp; using System.IO; namespace AnswerHubMigrator { class Program { static void Main(string[] args) { StringBuilder output; string suffix = ""; string thisfile = ""; // pass two arguments on the command line, e.g. 1, 750 int LowerBound = int.Parse(args[0]); int UpperBound = int.Parse(args[1]); // auto-expand URLs, and only accept bold/italic markdown // when it completely surrounds an entire word var options = new MarkdownOptions { AutoHyperlink = true, StrictBoldItalic = true }; MarkdownSharp.Markdown mark = new MarkdownSharp.Markdown(options); using (var conn = new SqlConnection("Server=.\\SQL2017;Integrated Security=true")) using (var cmd = new SqlCommand("MigrateDB.dbo.BuildMySQLInserts", conn)) { cmd.CommandType = CommandType.StoredProcedure; cmd.Parameters.Add("@LowerBound", SqlDbType.Int).Value = LowerBound; cmd.Parameters.Add("@UpperBound", SqlDbType.Int).Value = UpperBound; conn.Open(); using (var reader = cmd.ExecuteReader()) { // use a StringBuilder to dump output to a file output = new StringBuilder(); while (reader.Read()) { // on first pass, make a new delete/insert // delete is to make the commands idempotent if (reader["rn"].Equals("1")) { // for each master parent, I would create a // new WordPress post, inheriting the parent ID output.Append("DELETE FROM `wp_posts` WHERE ID = "); output.Append(reader["master_parent"].ToString()); output.Append("; INSERT INTO `wp_posts` (`ID`, `post_author`, "); output.Append("`post_date`, `post_date_gmt`, `post_content`, "); output.Append("`post_title`, `post_excerpt`, `post_status`, "); output.Append("`comment_status`, `ping_status`, `post_password`,"); output.Append(" `post_name`, `to_ping`, `pinged`, `post_modified`,"); output.Append(" `post_modified_gmt`, `post_content_filtered`, "); output.Append("`post_parent`, `guid`, `menu_order`, `post_type`, "); output.Append("`post_mime_type`, `comment_count`) VALUES ("); // I'm sure some of the above columns are optional, but identifying // those would not be a valuable use of time IMHO output.Append(reader["prefix"]); // hold on to the additional values until last row suffix = reader["suffix"].ToString(); } // manipulate the body content to be WordPress and INSERT statement-friendly string body = reader["body"].ToString().Replace(@"\n", "\n"); body = mark.Transform(body).Replace("href=", "target=_blank href="); body = body.Replace("<p>", "").Replace("</p>", ""); body = body.Replace("<pre><code>", "<pre lang=\"tsql\">"); body = body.Replace("</code></"+"pre>", "</"+"pre>"); body = body.Replace(@"'", "\'").Replace(@"’", "\'"); body = reader["bodypre"].ToString() + body.Replace("\n", @"\n"); body += reader["bodypost"].ToString(); body = body.Replace("<", "<").Replace(">", ">"); output.Append(body); // if we are on the last row, add additional values from the first row if (reader["c"].Equals(reader["rn"])) { output.Append(suffix); } } thisfile = UpperBound.ToString(); using (StreamWriter w = new StreamWriter(@"C:\wp\" + thisfile + ".sql")) { w.WriteLine(output); w.Flush(); } } } } } }
Sim, isso é um monte de código feio, mas finalmente me levou ao conjunto de saída que não faria o phpMyAdmin vomitar, e que o WordPress apresentaria bem (o suficiente). Eu simplesmente chamei o programa C# várias vezes com os diferentes intervalos de parâmetros:
AnswerHubMigrator 1 750 AnswerHubMigrator 751 1500 AnswerHubMigrator 1501 2250 ...
Então eu abri cada um dos arquivos, colei-os no phpMyAdmin e apertei GO:
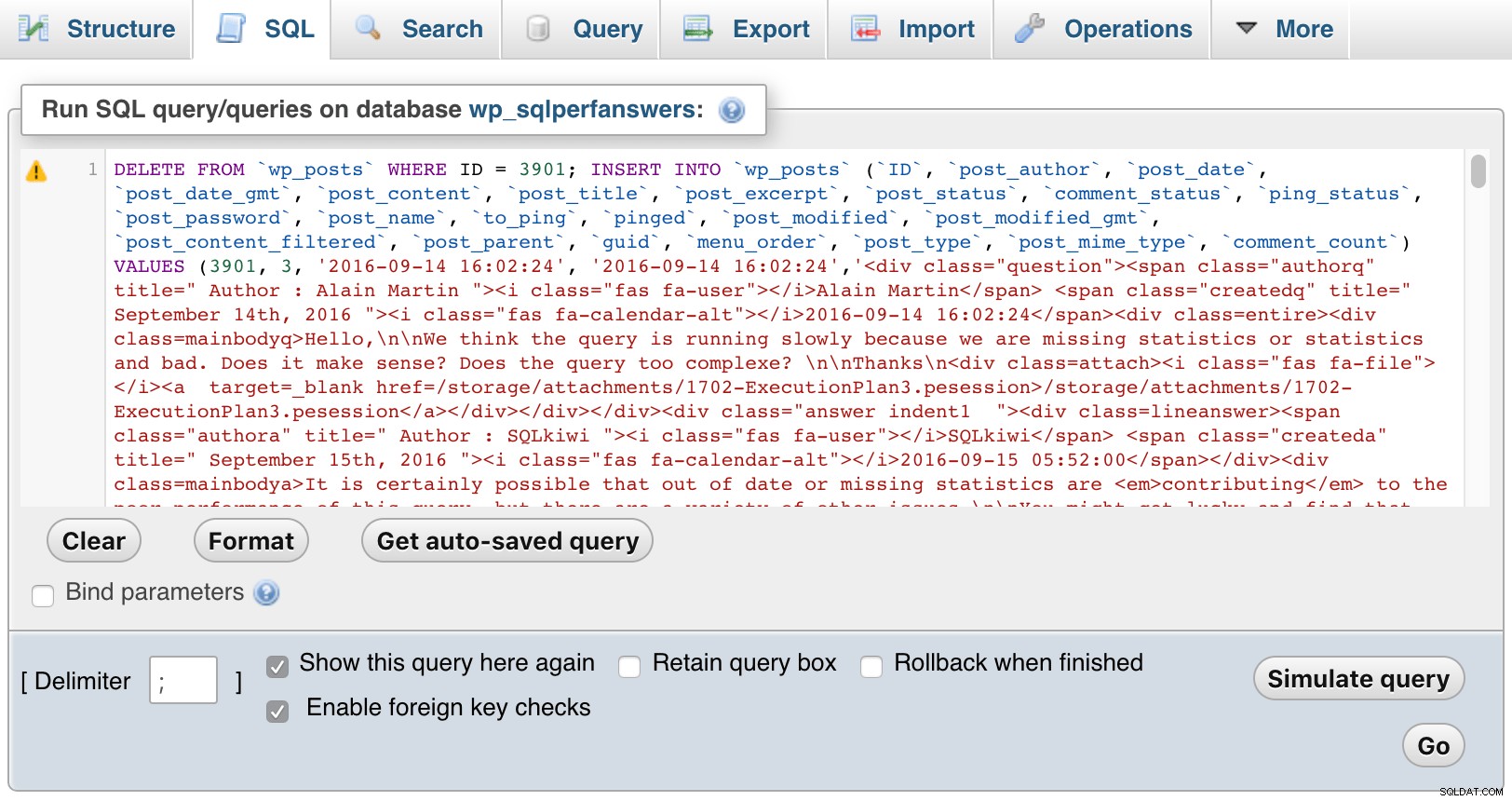 phpMyAdmin (clique para ampliar)
phpMyAdmin (clique para ampliar)
Claro que eu tive que adicionar um pouco de CSS no WordPress para ajudar a diferenciar entre perguntas, comentários e respostas, e também recuar comentários para mostrar respostas a perguntas e respostas, aninhar comentários respondendo a comentários e assim por diante. Aqui está a aparência de um trecho quando você analisa as perguntas de um mês:
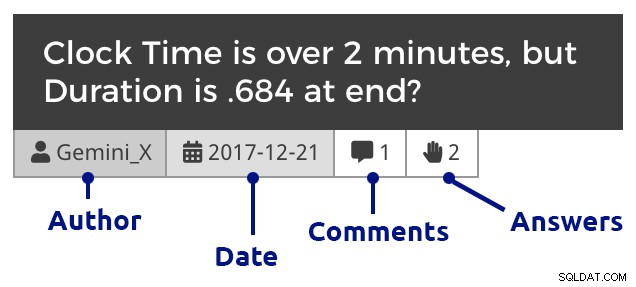 Tijolo de pergunta (clique para ampliar)
Tijolo de pergunta (clique para ampliar)
E, em seguida, uma postagem de exemplo, mostrando imagens incorporadas, vários anexos, comentários aninhados e uma resposta:
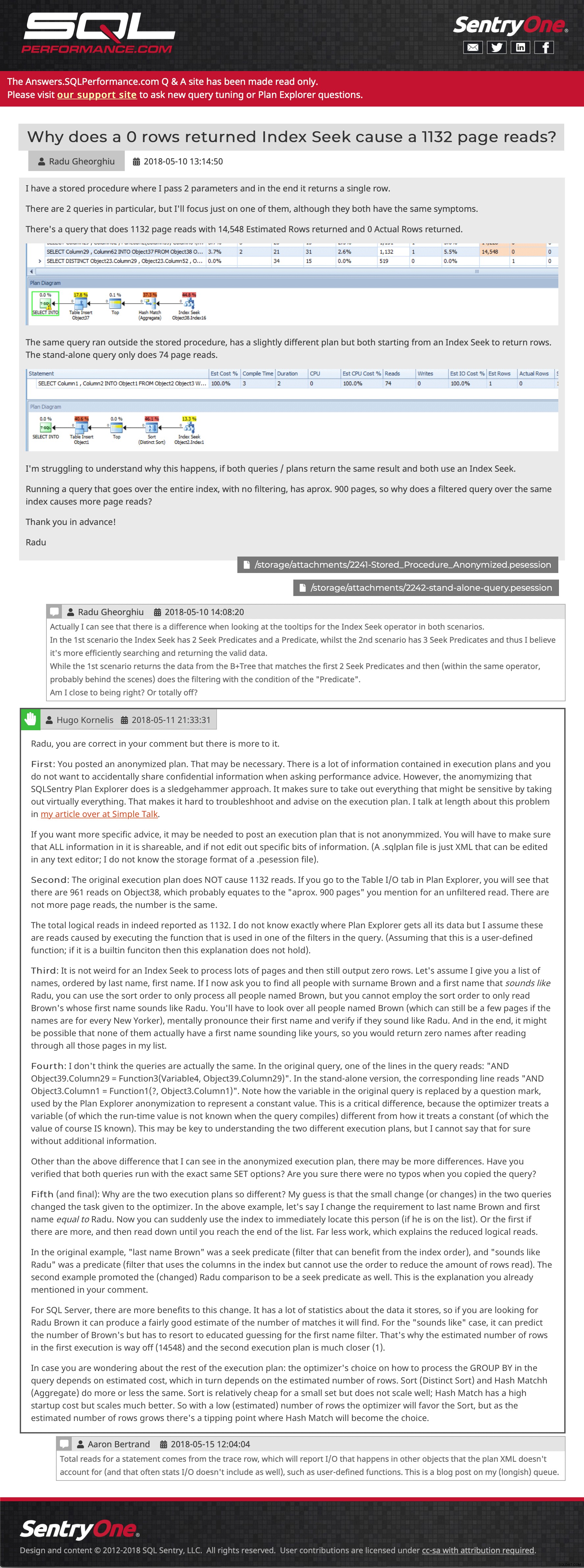 Exemplo de pergunta e resposta (clique para ir até lá)
Exemplo de pergunta e resposta (clique para ir até lá)
Ainda estou tentando recuperar algumas postagens que foram enviadas ao site depois que o último backup foi feito, mas convido você a navegar. Por favor, avise-nos se você encontrar algo faltando ou fora do lugar, ou apenas para nos dizer que o conteúdo ainda é útil para você. Esperamos reintroduzir a funcionalidade de upload do plano a partir do Plan Explorer, mas isso exigirá algum trabalho de API no novo site de suporte, portanto, não tenho um ETA para você hoje.
- Answers.SQLPerformance.com