No ano passado, apresentei uma solução para simular secundários legíveis do Grupo de Disponibilidade sem investir no Enterprise Edition. Para não impedir as pessoas de comprar a Enterprise Edition, pois há muitos benefícios fora dos AGs, mas mais ainda para aqueles que não têm chance de ter a Enterprise Edition em primeiro lugar:
- Secundários legíveis com orçamento limitado
Eu tento ser um defensor incansável do cliente Standard Edition; é quase uma piada corrente que certamente – dado o número de recursos que obtém em cada nova versão – essa edição como um todo está no caminho de descontinuação. Em reuniões privadas com a Microsoft, pedi que os recursos também fossem incluídos na Standard Edition, especialmente com recursos que são muito mais benéficos para pequenas empresas do que aqueles com orçamento de hardware ilimitado.
Os clientes da Enterprise Edition aproveitam os benefícios de gerenciamento e desempenho oferecidos pelo particionamento de tabela, mas esse recurso não está disponível na Standard Edition. Uma ideia me ocorreu recentemente de que existe uma maneira de obter pelo menos algumas das vantagens do particionamento em qualquer edição, e isso não envolve visualizações particionadas. Isso não quer dizer que as visualizações particionadas não sejam uma opção viável que valha a pena considerar; estes são bem descritos por outros, incluindo Daniel Hutmacher (Visualizações particionadas sobre particionamento de tabelas) e Kimberly Tripp (Tabelas Particionadas vs. Visualizações Particionadas – Por que elas ainda existem?). Minha ideia é um pouco mais simples de implementar.
Seu novo herói:índices filtrados
Agora, eu sei, esse recurso é uma palavra de quatro letras para alguns; antes de prosseguir, você deve estar feliz com os índices filtrados, ou pelo menos ciente de suas limitações. Algumas leituras para lhe dar um equilíbrio justo antes de tentar vendê-lo:
- Falo sobre várias deficiências em Como os índices filtrados podem ser um recurso mais poderoso e aponto muitos itens do Connect para você votar;
- Paul White (@SQL_Kiwi) fala sobre problemas de ajuste em Limitações do Otimizador com Índices Filtrados e também em Um Efeito Colateral Inesperado de Adicionar um Índice Filtrado; e,
- Jes Borland (@grrl_geek) nos diz o que você pode (e não pode) fazer com índices filtrados.
Leia todos aqueles? E você ainda está aqui? Excelente.
O TL;DR disso é que você pode usar índices filtrados para manter todos os seus "dados quentes" em uma estrutura física separada e até mesmo em hardware subjacente separado (você pode ter uma unidade SSD ou PCIe rápida disponível, mas não pode t segure a mesa inteira).
Um exemplo rápido
Há muitos casos de uso em que uma parte dos dados é consultada com muito mais frequência do que o restante – pense em uma loja de varejo gerenciando pedidos, uma padaria agendando entregas de bolos de casamento ou um estádio de futebol medindo dados de participação e concessão. Nesses casos, a maior parte ou toda a atividade de consulta diária está relacionada aos dados "atuais".
Vamos mantê-lo simples; vamos criar um banco de dados com uma tabela Orders muito estreita:
CREATE DATABASE PoorManPartition;GO USE PoorManPartition;GO CREATE TABLE dbo.Orders( OrderID INT IDENTITY(1,1) PRIMARY KEY, OrderDate DATE NOT NULL DEFAULT SYSUTCDATETIME(), OrderTotal DECIMAL(8,2) --, .. .outras colunas...);
Agora, digamos que você tenha espaço suficiente em seu armazenamento rápido para manter um mês de dados (com bastante espaço para considerar a sazonalidade e o crescimento futuro). Podemos adicionar um novo grupo de arquivos e colocar um arquivo de dados na unidade rápida.
ALTER DATABASE PoorManPartition ADD FILEGROUP HotData;GO ALTER DATABASE PoorManPartition ADD FILE ( Nome =N'HotData', FileName =N'Z:\folder\HotData.mdf', Tamanho =100MB, FileGrowth =25MB) TO FILEGROUP HotData;
Agora, vamos criar um índice filtrado em nosso grupo de arquivos HotData, onde o filtro inclui tudo desde o início de novembro de 2015 e as colunas comuns envolvidas em consultas baseadas em tempo estão na lista de chaves ou de inclusão:
CREATE INDEX FilteredIndex ON dbo.Orders(OrderDate) INCLUDE(OrderTotal) WHERE OrderDate>='20151101' AND OrderDate <'20151201' ON HotData;
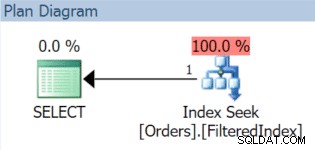
Podemos inserir algumas linhas e verificar o plano de execução para ter certeza de que as consultas cobertas podem, de fato, usar o índice:
INSERT dbo.Orders(OrderDate) VALUES('20151001'),('20151103'),('20151127');GO SELECT index_id, rows FROM sys.partitions WHERE object_id =OBJECT_ID(N'dbo.Orders'); /* Resultados:index_id rows -------- ---- 1 3 2 2*/ SELECT OrderID, OrderDate, OrderTotal FROM dbo.Orders WHERE OrderDate>='20151102' AND OrderDate <'20151106';
O plano de execução resultante, com certeza, usa o índice filtrado (mesmo que o predicado do filtro na consulta não corresponda exatamente à definição do índice):
Agora, 1º de dezembro chega e é hora de trocar nossos dados de novembro e substituí-los por dezembro. Podemos apenas recriar o índice filtrado com um novo predicado de filtro e usar o DROP_EXISTING opção:
CREATE INDEX FilteredIndex ON dbo.Orders(OrderDate) INCLUDE(OrderTotal) WHERE OrderDate>='20151201' AND OrderDate <'20160101' WITH (DROP_EXISTING =ON) ON HotData;
Agora, podemos adicionar mais algumas linhas, verificar as estatísticas da partição e executar nossa consulta anterior e uma nova para verificar os índices usados:
INSERT dbo.Orders(OrderDate) VALUES('20151202'),('20151205');GO SELECT index_id, linhas FROM sys.partitions WHERE object_id =OBJECT_ID(N'dbo.Orders'); /* Resultados:index_id rows -------- ---- 1 5 2 2*/ SELECT OrderID, OrderDate, OrderTotal FROM dbo.Orders WHERE OrderDate>='20151102' AND OrderDate <'20151106'; SELECT OrderID, OrderDate, OrderTotal FROM dbo.Orders WHERE OrderDate>='20151202' AND OrderDate <'20151204';
Nesse caso, obtemos uma verificação de índice clusterizado com a consulta de novembro:
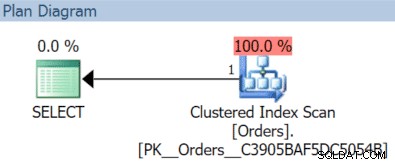
(Mas isso seria diferente se tivéssemos um índice separado e não filtrado com OrderDate como a chave.)
E não mostrarei novamente, mas com a consulta de dezembro, obtemos a mesma busca de índice filtrada de antes.
Você também pode manter vários índices, um para o mês atual, um para o mês anterior e assim por diante, e pode gerenciá-los separadamente (em 1º de dezembro, basta descartar o índice de outubro e deixar o de novembro sozinho, por exemplo) . Você também pode manter vários índices de intervalos de tempo mais curtos ou mais longos (semana atual e anterior, trimestre atual e anterior), etc. A solução é bastante flexível.
Devido às limitações dos índices filtrados, não tentarei empurrar isso como uma solução perfeita, nem um substituto completo para particionamento de tabela ou exibições particionadas. Alternar uma partição, por exemplo, é uma operação de metadados, enquanto recria um índice com DROP_EXISTING pode ter muitos logs (e como você não está no Enterprise Edition, não pode ser executado online). Você também pode achar que as visualizações particionadas são mais rápidas – há mais trabalho em torno da manutenção de tabelas físicas separadas e as restrições que tornam a visualização particionada possível, mas a recompensa em termos de desempenho de consulta pode ser melhor em alguns casos.
Automação
O ato de recriar o índice pode ser automatizado com bastante facilidade, usando um trabalho simples que faz algo assim uma vez por mês (ou qualquer que seja o tamanho da janela "quente"):
DECLARE @sql NVARCHAR(MAX), @dt DATE =DATEADD(DAY, 1-DAY(GETDATE()), GETDATE()); SET @sql =N'CREATE INDEX FilteredIndex ON dbo.Orders(OrderDate) INCLUDE(OrderTotal) WHERE OrderDate>=''' + CONVERT(CHAR(8), @dt, 112) + N''' WITH (DROP_EXISTING =ON ) ON HotData;'; EXEC PoorManPartition.sys.sp_executesql @sql;
Você também pode criar vários índices com meses de antecedência, assim como criar partições futuras com antecedência – afinal, os índices futuros não ocuparão nenhum espaço até que haja dados relevantes para seus predicados. E você pode simplesmente descartar os índices que estavam segmentando os dados mais antigos que agora deseja tornar frios.
Perspectiva
Depois que terminei este artigo, é claro, me deparei com outro post da Kimberly Tripp, que você deve ler antes de prosseguir com qualquer coisa que estou defendendo aqui (e que eu tinha lido antes de começar):
- Que tal índices filtrados em vez de particionamento?
Por várias razões, Kimberly é muito mais a favor de exibições particionadas para implementar algo semelhante ao particionamento na Standard Edition; no entanto, para certos cenários, o uso de índices filtrados ainda me intriga o suficiente para continuar com minha experimentação. Uma das áreas em que os índices filtrados podem ser benéficos é quando seus dados "quentes" têm vários critérios - não apenas divididos por data, mas também por outros atributos (talvez você queira consultas rápidas em todos os pedidos deste mês que são para um nível específico do cliente ou acima de um determinado valor em dólares).
Próximo…
Em um post futuro, vou brincar com esse conceito em um sistema de ponta, com algum volume e carga de trabalho do mundo real. Quero descobrir as diferenças de desempenho entre esta solução, um índice de cobertura não filtrado, uma exibição particionada e uma tabela particionada. Dentro de uma VM em um laptop com apenas SSDs disponíveis, provavelmente não renderia testes realistas ou justos em escala.