Como vimos anteriormente, pode ser um desafio para as empresas migrar seus dados do RDS para MySQL. Na primeira parte deste blog, mostramos como configurar seu ambiente de destino no EC2 e inserir uma camada de proxy (ProxySQL) entre seus aplicativos e o RDS. Nesta segunda parte, mostraremos como fazer a migração real dos dados para o seu próprio servidor e, em seguida, redirecionar seus aplicativos para a nova instância do banco de dados sem tempo de inatividade.
Copiando dados do RDS
Assim que nosso tráfego de banco de dados estiver sendo executado por meio do ProxySQL, podemos iniciar os preparativos para copiar nossos dados do RDS. Precisamos fazer isso para configurar a replicação entre o RDS e nossa instância MySQL em execução no EC2. Feito isso, configuraremos o ProxySQL para redirecionar o tráfego do RDS para nosso MySQL/EC2.
Conforme discutimos na primeira postagem do blog desta série, a única maneira de obter dados do RDS é por meio de despejo lógico. Sem acesso à instância, não podemos usar nenhuma ferramenta de backup físico quente, como o xtrabackup. Também não podemos usar instantâneos, pois não há como criar nada além de uma nova instância do RDS a partir do instantâneo.
Estamos limitados a ferramentas de dump lógicas, portanto, a opção lógica seria usar mydumper/myloader para processar os dados. Felizmente, mydumper pode criar backups consistentes para que possamos confiar nele para fornecer as coordenadas do log binário para o nosso novo escravo se conectar. O principal problema ao criar réplicas RDS é a política de rotação de log binário - despejo e carregamento lógicos podem levar até dias em conjuntos de dados maiores (centenas de gigabytes) e você precisa manter os logs binários na instância do RDS durante todo esse processo. Claro, você pode aumentar a retenção de rotação do log binário no RDS (chamar mysql.rds_set_configuration('binlog retenção horas', 24); - você pode mantê-los até 7 dias), mas é muito mais seguro fazer isso de forma diferente.
Antes de prosseguirmos com o dump, adicionaremos uma réplica à nossa instância do RDS.
 Painel do Amazon RDS
Painel do Amazon RDS 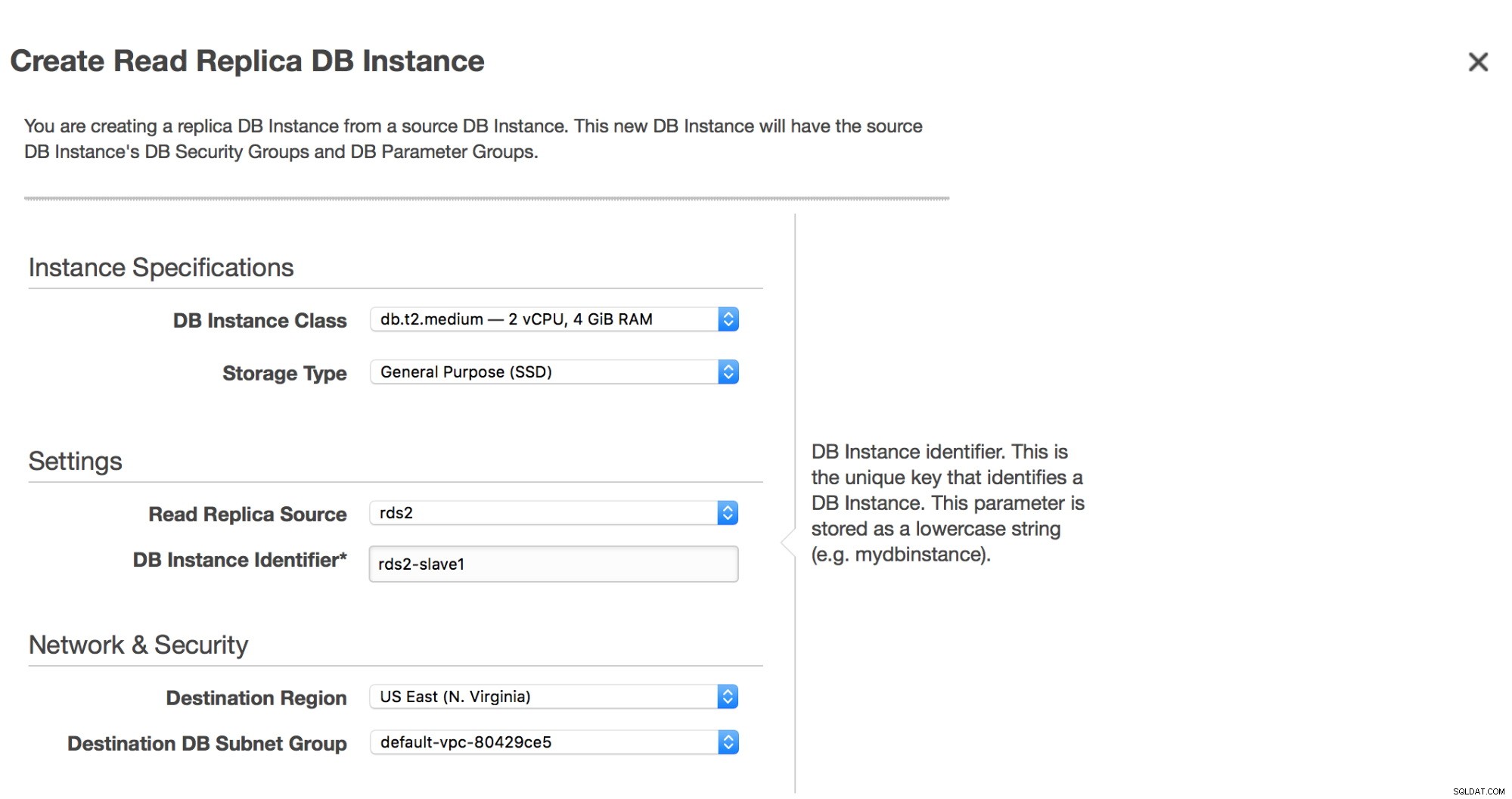 Criar banco de dados de réplica no RDS
Criar banco de dados de réplica no RDS 
Assim que clicarmos no botão “Create Read Replica”, um snapshot será iniciado na réplica “master” do RDS. Ele será usado para provisionar o novo escravo. O processo pode levar horas, tudo depende do tamanho do volume, quando foi a última vez que um snapshot foi tirado e do desempenho do volume (io1/gp2? Magnético? Quantos pIOPS tem um volume?).
 Réplica mestre do RDS
Réplica mestre do RDS Quando o escravo estiver pronto (seu status mudou para “disponível”), podemos fazer login nele usando seu endpoint RDS.
 Escravo RDS
Escravo RDS Uma vez logado, pararemos a replicação em nosso escravo - isso garantirá que o mestre RDS não limpe os logs binários e eles ainda estarão disponíveis para nosso escravo EC2 assim que concluirmos nosso processo de despejo/recarregamento.
mysql> CALL mysql.rds_stop_replication;
+---------------------------+
| Message |
+---------------------------+
| Slave is down or disabled |
+---------------------------+
1 row in set (1.02 sec)
Query OK, 0 rows affected (1.02 sec)Agora, finalmente é hora de copiar os dados para o EC2. Primeiro, precisamos instalar o mydumper. Você pode obtê-lo no github:https://github.com/maxbube/mydumper. O processo de instalação é bastante simples e bem descrito no arquivo leia-me, portanto, não o abordaremos aqui. Provavelmente você terá que instalar alguns pacotes (listados no readme) e a parte mais difícil é identificar qual pacote contém mysql_config - depende do sabor do MySQL (e às vezes também da versão do MySQL).
Depois de ter o mydumper compilado e pronto, você pode executá-lo:
example@sqldat.com:~/mydumper# mkdir /tmp/rdsdump
example@sqldat.com:~/mydumper# ./mydumper -h rds2.cvsw8xpajw2b.us-east-1.rds.amazonaws.com -p tpccpass -u tpcc -o /tmp/rdsdump --lock-all-tables --chunk-filesize 100 --events --routines --triggers
. Observe --lock-all-tables que garante que o instantâneo dos dados será consistente e será possível usá-lo para criar um escravo. Agora, temos que esperar até que mydumper complete sua tarefa.
Mais uma etapa é necessária - não queremos restaurar o esquema mysql, mas precisamos copiar os usuários e suas concessões. Podemos usar pt-show-grants para isso:
example@sqldat.com:~# wget https://percona.com/get/pt-show-grants
example@sqldat.com:~# chmod u+x ./pt-show-grants
example@sqldat.com:~# ./pt-show-grants -h rds2.cvsw8xpajw2b.us-east-1.rds.amazonaws.com -u tpcc -p tpccpass > grants.sqlAmostra de pt-show-grants pode ser assim:
-- Grants for 'sbtest'@'%'
CREATE USER IF NOT EXISTS 'sbtest'@'%';
ALTER USER 'sbtest'@'%' IDENTIFIED WITH 'mysql_native_password' AS '*2AFD99E79E4AA23DE141540F4179F64FFB3AC521' REQUIRE NONE PASSWORD EXPIRE DEFAULT ACCOUNT UNLOCK;
GRANT ALTER, ALTER ROUTINE, CREATE, CREATE ROUTINE, CREATE TEMPORARY TABLES, CREATE USER, CREATE VIEW, DELETE, DROP, EVENT, EXECUTE, INDEX, INSERT, LOCK TABLES, PROCESS, REFERENCES, RELOAD, REPLICATION CLIENT, REPLICATION SLAVE, SELECT, SHOW DATABASES, SHOW VIEW, TRIGGER, UPDATE ON *.* TO 'sbtest'@'%';Cabe a você escolher quais usuários devem ser copiados para sua instância MySQL/EC2. Não faz sentido fazer isso para todos eles. Por exemplo, os usuários root não têm privilégio 'SUPER' no RDS, então é melhor recriá-los do zero. O que você precisa copiar são concessões para o usuário do seu aplicativo. Também precisamos copiar os usuários usados pelo ProxySQL (proxysql-monitor no nosso caso).
Inserindo dados em sua instância MySQL/EC2
Como dito acima, não queremos restaurar esquemas do sistema. Portanto, moveremos os arquivos relacionados a esses esquemas para fora do nosso diretório mydumper:
example@sqldat.com:~# mkdir /tmp/rdsdump_sys/
example@sqldat.com:~# mv /tmp/rdsdump/mysql* /tmp/rdsdump_sys/
example@sqldat.com:~# mv /tmp/rdsdump/sys* /tmp/rdsdump_sys/Quando terminarmos, é hora de começar a carregar os dados na instância MySQL/EC2:
example@sqldat.com:~/mydumper# ./myloader -d /tmp/rdsdump/ -u tpcc -p tpccpass -t 4 --overwrite-tables -h 172.30.4.238Observe que usamos quatro threads (-t 4) - certifique-se de definir isso para o que fizer sentido em seu ambiente. Trata-se de saturar a instância MySQL de destino - CPU ou E/S, dependendo do gargalo. Queremos extrair o máximo possível para garantir que usamos todos os recursos disponíveis para carregar os dados.
Depois que os dados principais são carregados, há mais duas etapas a serem seguidas, ambas relacionadas aos internos do RDS e ambas podem interromper nossa replicação. Primeiro, o RDS contém algumas tabelas rds_* no esquema mysql. Queremos carregá-los caso alguns deles sejam usados pelo RDS - a replicação será interrompida se nosso escravo não os tiver. Podemos fazer da seguinte forma:
example@sqldat.com:~/mydumper# for i in $(ls -alh /tmp/rdsdump_sys/ | grep rds | awk '{print $9}') ; do echo $i ; mysql -ppass -uroot mysql < /tmp/rdsdump_sys/$i ; done
mysql.rds_configuration-schema.sql
mysql.rds_configuration.sql
mysql.rds_global_status_history_old-schema.sql
mysql.rds_global_status_history-schema.sql
mysql.rds_heartbeat2-schema.sql
mysql.rds_heartbeat2.sql
mysql.rds_history-schema.sql
mysql.rds_history.sql
mysql.rds_replication_status-schema.sql
mysql.rds_replication_status.sql
mysql.rds_sysinfo-schema.sqlUm problema semelhante é com as tabelas de fuso horário, precisamos carregá-las usando dados da instância do RDS:
example@sqldat.com:~/mydumper# for i in $(ls -alh /tmp/rdsdump_sys/ | grep time_zone | grep -v schema | awk '{print $9}') ; do echo $i ; mysql -ppass -uroot mysql < /tmp/rdsdump_sys/$i ; done
mysql.time_zone_name.sql
mysql.time_zone.sql
mysql.time_zone_transition.sql
mysql.time_zone_transition_type.sqlQuando tudo isso estiver pronto, podemos configurar a replicação entre o RDS (mestre) e nossa instância MySQL/EC2 (escravo).
Configurando a replicação
Mydumper, ao realizar um dump consistente, anota uma posição de log binário. Podemos encontrar esses dados em um arquivo chamado metadados no diretório de despejo. Vamos dar uma olhada nisso, então usaremos a posição para configurar a replicação.
example@sqldat.com:~/mydumper# cat /tmp/rdsdump/metadata
Started dump at: 2017-02-03 16:17:29
SHOW SLAVE STATUS:
Host: 10.1.4.180
Log: mysql-bin-changelog.007079
Pos: 10537102
GTID:
Finished dump at: 2017-02-03 16:44:46Uma última coisa que nos falta é um usuário que possamos usar para configurar nosso escravo. Vamos criar um na instância do RDS:
example@sqldat.com:~# mysql -ppassword -h rds2.cvsw8xpajw2b.us-east-1.rds.amazonaws.commysql> CREATE USER IF NOT EXISTS 'rds_rpl'@'%' IDENTIFIED BY 'rds_rpl_pass';
Query OK, 0 rows affected (0.04 sec)mysql> GRANT REPLICATION SLAVE ON *.* TO 'rds_rpl'@'%';
Query OK, 0 rows affected (0.01 sec)Agora é hora de escravizar nosso servidor MySQL/EC2 da instância RDS:
mysql> CHANGE MASTER TO MASTER_HOST='rds2.cvsw8xpajw2b.us-east-1.rds.amazonaws.com', MASTER_USER='rds_rpl', MASTER_PASSWORD='rds_rpl_pass', MASTER_LOG_FILE='mysql-bin-changelog.007079', MASTER_LOG_POS=10537102;
Query OK, 0 rows affected, 2 warnings (0.03 sec)mysql> START SLAVE;
Query OK, 0 rows affected (0.02 sec)mysql> SHOW SLAVE STATUS\G
*************************** 1. row ***************************
Slave_IO_State: Queueing master event to the relay log
Master_Host: rds2.cvsw8xpajw2b.us-east-1.rds.amazonaws.com
Master_User: rds_rpl
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin-changelog.007080
Read_Master_Log_Pos: 13842678
Relay_Log_File: relay-bin.000002
Relay_Log_Pos: 20448
Relay_Master_Log_File: mysql-bin-changelog.007079
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 10557220
Relay_Log_Space: 29071382
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 258726
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1237547456
Master_UUID: b5337d20-d815-11e6-abf1-120217bb3ac2
Master_Info_File: mysql.slave_master_info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: System lock
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp:
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set:
Executed_Gtid_Set:
Auto_Position: 0
Replicate_Rewrite_DB:
Channel_Name:
Master_TLS_Version:
1 row in set (0.01 sec)A última etapa será mudar nosso tráfego da instância RDS para MySQL/EC2, mas precisamos deixá-lo acompanhar primeiro.
Quando o escravo alcançou, precisamos realizar um cutover. Para automatizá-lo, decidimos preparar um script bash curto que se conectará ao ProxySQL e fará o que precisa ser feito.
# At first, we define old and new masters
OldMaster=rds2.cvsw8xpajw2b.us-east-1.rds.amazonaws.com
NewMaster=172.30.4.238
(
# We remove entries from mysql_replication_hostgroup so ProxySQL logic won’t interfere
# with our script
echo "DELETE FROM mysql_replication_hostgroups;"
# Then we set current master to OFFLINE_SOFT - this will allow current transactions to
# complete while not accepting any more transactions - they will wait (by default for
# 10 seconds) for a master to become available again.
echo "UPDATE mysql_servers SET STATUS='OFFLINE_SOFT' WHERE hostname=\"$OldMaster\";"
echo "LOAD MYSQL SERVERS TO RUNTIME;"
) | mysql -u admin -padmin -h 127.0.0.1 -P6032
# Here we are going to check for connections in the pool which are still used by
# transactions which haven’t closed so far. If we see that neither hostgroup 10 nor
# hostgroup 20 has open transactions, we can perform a switchover.
CONNUSED=`mysql -h 127.0.0.1 -P6032 -uadmin -padmin -e 'SELECT IFNULL(SUM(ConnUsed),0) FROM stats_mysql_connection_pool WHERE status="OFFLINE_SOFT" AND (hostgroup=10 OR hostgroup=20)' -B -N 2> /dev/null`
TRIES=0
while [ $CONNUSED -ne 0 -a $TRIES -ne 20 ]
do
CONNUSED=`mysql -h 127.0.0.1 -P6032 -uadmin -padmin -e 'SELECT IFNULL(SUM(ConnUsed),0) FROM stats_mysql_connection_pool WHERE status="OFFLINE_SOFT" AND (hostgroup=10 OR hostgroup=20)' -B -N 2> /dev/null`
TRIES=$(($TRIES+1))
if [ $CONNUSED -ne "0" ]; then
sleep 0.05
fi
done
# Here is our switchover logic - we basically exchange hostgroups for RDS and EC2
# instance. We also configure back mysql_replication_hostgroups table.
(
echo "UPDATE mysql_servers SET STATUS='ONLINE', hostgroup_id=110 WHERE hostname=\"$OldMaster\" AND hostgroup_id=10;"
echo "UPDATE mysql_servers SET STATUS='ONLINE', hostgroup_id=120 WHERE hostname=\"$OldMaster\" AND hostgroup_id=20;"
echo "UPDATE mysql_servers SET hostgroup_id=10 WHERE hostname=\"$NewMaster\" AND hostgroup_id=110;"
echo "UPDATE mysql_servers SET hostgroup_id=20 WHERE hostname=\"$NewMaster\" AND hostgroup_id=120;"
echo "INSERT INTO mysql_replication_hostgroups VALUES (10, 20, 'hostgroups');"
echo "LOAD MYSQL SERVERS TO RUNTIME;"
) | mysql -u admin -padmin -h 127.0.0.1 -P6032Quando tudo estiver pronto, você deverá ver o seguinte conteúdo na tabela mysql_servers:
mysql> select * from mysql_servers;
+--------------+-----------------------------------------------+------+--------+--------+-------------+-----------------+---------------------+---------+----------------+-------------+
| hostgroup_id | hostname | port | status | weight | compression | max_connections | max_replication_lag | use_ssl | max_latency_ms | comment |
+--------------+-----------------------------------------------+------+--------+--------+-------------+-----------------+---------------------+---------+----------------+-------------+
| 20 | 172.30.4.238 | 3306 | ONLINE | 1 | 0 | 100 | 10 | 0 | 0 | read server |
| 10 | 172.30.4.238 | 3306 | ONLINE | 1 | 0 | 100 | 10 | 0 | 0 | read server |
| 120 | rds2.cvsw8xpajw2b.us-east-1.rds.amazonaws.com | 3306 | ONLINE | 1 | 0 | 100 | 10 | 0 | 0 | |
| 110 | rds2.cvsw8xpajw2b.us-east-1.rds.amazonaws.com | 3306 | ONLINE | 1 | 0 | 100 | 10 | 0 | 0 | |
+--------------+-----------------------------------------------+------+--------+--------+-------------+-----------------+---------------------+---------+----------------+-------------+No lado do aplicativo, você não deve ver muito impacto, graças à capacidade do ProxySQL de enfileirar consultas por algum tempo.
Com isso finalizamos o processo de migração do seu banco de dados do RDS para o EC2. O último passo a fazer é remover nosso escravo RDS - ele fez seu trabalho e pode ser excluído.
Em nosso próximo post do blog, vamos construir sobre isso. Analisaremos um cenário em que moveremos nosso banco de dados da AWS/EC2 para um provedor de hospedagem separado.