Para o T-SQL Tuesday deste mês, Steve Jones (@way0utwest) nos pediu para falar sobre nossas melhores ou piores experiências de gatilho. Embora seja verdade que os gatilhos são frequentemente desaprovados e até temidos, eles têm vários casos de uso válidos, incluindo:
- Auditoria (antes de 2016 SP1, quando esse recurso se tornou gratuito em todas as edições)
- Aplicação de regras de negócios e integridade de dados, quando não podem ser implementadas facilmente em restrições e você não deseja que elas dependam do código do aplicativo ou das próprias consultas DML
- Manter versões históricas de dados (antes do Change Data Capture, Change Tracking e Temporal Tables)
- Alertas de fila ou processamento assíncrono em resposta a uma alteração específica
- Permitir modificações nas visualizações (via gatilhos INSTEAD OF)
Essa não é uma lista exaustiva, apenas uma rápida recapitulação de alguns cenários que experimentei em que os gatilhos eram a resposta certa na época.
Quando gatilhos são necessários, eu sempre gosto de explorar o uso de gatilhos INSTEAD OF em vez de gatilhos AFTER. Sim, eles são um pouco mais trabalhosos*, mas têm alguns benefícios muito importantes. Em teoria, pelo menos, a perspectiva de impedir que uma ação (e suas consequências de log) aconteça parece muito mais eficiente do que deixar tudo acontecer e depois desfazê-lo.
*
Digo isso porque você precisa codificar a instrução DML novamente dentro do gatilho; é por isso que eles não são chamados de gatilhos BEFORE. A distinção é importante aqui, pois alguns sistemas implementam gatilhos BEFORE verdadeiros, que simplesmente são executados primeiro. No SQL Server, um gatilho INSTEAD OF cancela efetivamente a instrução que causou o disparo.
Vamos fingir que temos uma tabela simples para armazenar nomes de contas. Neste exemplo, criaremos duas tabelas, para que possamos comparar dois gatilhos diferentes e seu impacto na duração da consulta e no uso do log. O conceito é que temos uma regra de negócio:o nome da conta não está presente em outra tabela, o que representa nomes "ruins", e o gatilho é usado para impor essa regra. Aqui está o banco de dados:
USE [master];
GO
CREATE DATABASE [tr] ON (name = N'tr_dat', filename = N'C:\temp\tr.mdf', size = 4096MB)
LOG ON (name = N'tr_log', filename = N'C:\temp\tr.ldf', size = 2048MB);
GO
ALTER DATABASE [tr] SET RECOVERY FULL;
GO E as tabelas:
USE [tr]; GO CREATE TABLE dbo.Accounts_After ( AccountID int PRIMARY KEY, name sysname UNIQUE, filler char(255) NOT NULL DEFAULT '' ); CREATE TABLE dbo.Accounts_Instead ( AccountID int PRIMARY KEY, name sysname UNIQUE, filler char(255) NOT NULL DEFAULT '' ); CREATE TABLE dbo.InvalidNames ( name sysname PRIMARY KEY ); INSERT dbo.InvalidNames(name) VALUES (N'poop'),(N'hitler'),(N'boobies'),(N'cocaine');
E, finalmente, os gatilhos. Para simplificar, estamos lidando apenas com inserções e, tanto no after quanto no em vez de case, vamos abortar todo o lote se algum nome único violar nossa regra:
CREATE TRIGGER dbo.tr_Accounts_After
ON dbo.Accounts_After
AFTER INSERT
AS
BEGIN
IF EXISTS
(
SELECT 1 FROM inserted AS i
INNER JOIN dbo.InvalidNames AS n
ON i.name = n.name
)
BEGIN
RAISERROR(N'Tsk tsk.', 11, 1);
ROLLBACK TRANSACTION;
RETURN;
END
END
GO
CREATE TRIGGER dbo.tr_Accounts_Instead
ON dbo.Accounts_After
INSTEAD OF INSERT
AS
BEGIN
IF EXISTS
(
SELECT 1 FROM inserted AS i
INNER JOIN dbo.InvalidNames AS n
ON i.name = n.name
)
BEGIN
RAISERROR(N'Tsk tsk.', 11, 1);
RETURN;
END
ELSE
BEGIN
INSERT dbo.Accounts_Instead(AccountID, name, filler)
SELECT AccountID, name, filler FROM inserted;
END
END
GO Agora, para testar o desempenho, tentaremos inserir 100.000 nomes em cada tabela, com uma taxa de falha previsível de 10%. Em outras palavras, 90.000 são nomes corretos, os outros 10.000 falham no teste e fazem com que o gatilho seja revertido ou não inserido, dependendo do lote.
Primeiro, precisamos fazer alguma limpeza antes de cada lote:
TRUNCATE TABLE dbo.Accounts_Instead; TRUNCATE TABLE dbo.Accounts_After; GO CHECKPOINT; CHECKPOINT; BACKUP LOG triggers TO DISK = N'C:\temp\tr.trn' WITH INIT, COMPRESSION; GO
Antes de iniciarmos a carne de cada lote, contaremos as linhas no log de transações e mediremos o tamanho e o espaço livre. Em seguida, passaremos por um cursor para processar as 100.000 linhas em ordem aleatória, tentando inserir cada nome na tabela apropriada. Quando terminarmos, mediremos a contagem de linhas e o tamanho do log novamente e verificaremos a duração.
SET NOCOUNT ON;
DECLARE @batch varchar(10) = 'After', -- or After
@d datetime2(7) = SYSUTCDATETIME(),
@n nvarchar(129),
@i int,
@err nvarchar(512);
-- measure before and again when we're done:
SELECT COUNT(*) FROM sys.fn_dblog(NULL, NULL);
SELECT CurrentSizeMB = size/128.0,
FreeSpaceMB = (size-CONVERT(int, FILEPROPERTY(name,N'SpaceUsed')))/128.0
FROM sys.database_files
WHERE name = N'tr_log';
DECLARE c CURSOR LOCAL FAST_FORWARD
FOR
SELECT name, i = ROW_NUMBER() OVER (ORDER BY NEWID())
FROM
(
SELECT DISTINCT TOP (90000) LEFT(o.name,64) + '/' + LEFT(c.name,63)
FROM sys.all_objects AS o
CROSS JOIN sys.all_columns AS c
UNION ALL
SELECT TOP (10000) N'boobies' FROM sys.all_columns
) AS x (name)
ORDER BY i;
OPEN c;
FETCH NEXT FROM c INTO @n, @i;
WHILE @@FETCH_STATUS = 0
BEGIN
BEGIN TRY
IF @batch = 'After'
INSERT dbo.Accounts_After(AccountID,name) VALUES(@i,@n);
IF @batch = 'Instead'
INSERT dbo.Accounts_Instead(AccountID,name) VALUES(@i,@n);
END TRY
BEGIN CATCH
SET @err = ERROR_MESSAGE();
END CATCH
FETCH NEXT FROM c INTO @n, @i;
END
-- measure again when we're done:
SELECT COUNT(*) FROM sys.fn_dblog(NULL, NULL);
SELECT duration = DATEDIFF(MILLISECOND, @d, SYSUTCDATETIME()),
CurrentSizeMB = size/128.0,
FreeSpaceMB = (size-CAST(FILEPROPERTY(name,N'SpaceUsed') AS int))/128.0
FROM sys.database_files
WHERE name = N'tr_log';
CLOSE c; DEALLOCATE c; Resultados (média de 5 execuções de cada lote):
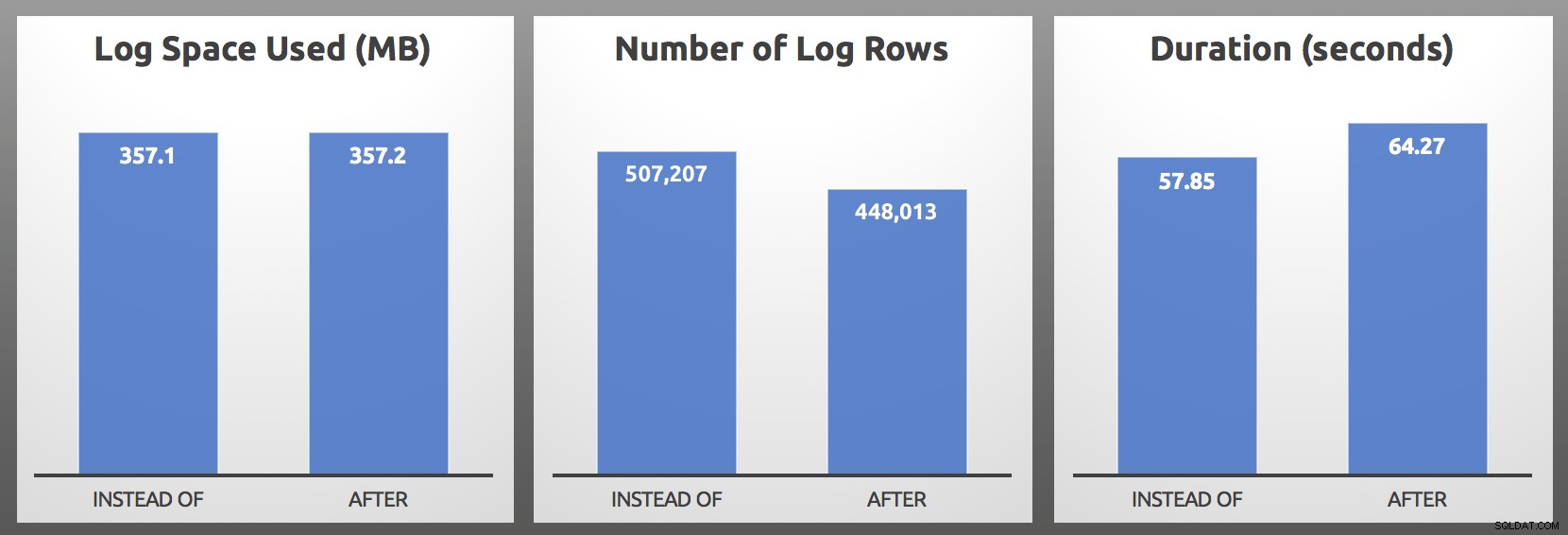 APÓS vs. EM VEZ DE:Resultados
APÓS vs. EM VEZ DE:Resultados Em meus testes, o uso de log foi quase idêntico em tamanho, com mais de 10% a mais de linhas de log geradas pelo gatilho INSTEAD OF. Eu fiz algumas escavações no final de cada lote:
SELECT [Operation], COUNT(*) FROM sys.fn_dblog(NULL, NULL) GROUP BY [Operation] ORDER BY [Operation];
E aqui estava um resultado típico (destaquei os principais deltas):
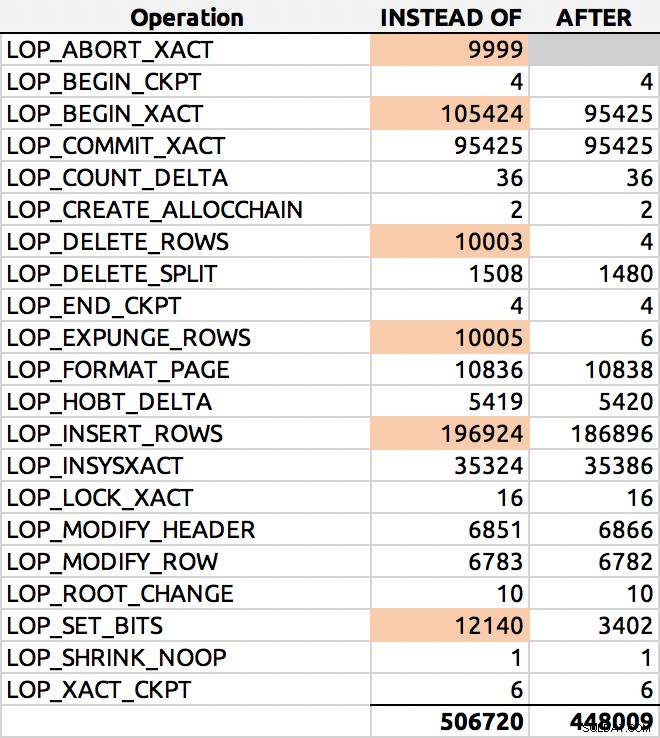 Distribuição de linhas de log
Distribuição de linhas de log Vou cavar isso mais profundamente em outra ocasião.
Mas quando você vai direto ao assunto…
…a métrica mais importante quase sempre será a duração , e no meu caso o gatilho INSTEAD OF executou pelo menos 5 segundos mais rápido em todos os testes diretos. Caso tudo isso soe familiar, sim, já falei sobre isso antes, mas naquela época não observei esses mesmos sintomas com as linhas de log.
Observe que esse pode não ser seu esquema ou carga de trabalho exato, você pode ter um hardware muito diferente, sua simultaneidade pode ser maior e sua taxa de falha pode ser muito maior (ou menor). Meus testes foram realizados em uma máquina isolada com bastante memória e SSDs PCIe muito rápidos. Se o seu log estiver em uma unidade mais lenta, as diferenças no uso do log poderão superar as outras métricas e alterar significativamente as durações. Todos esses fatores (e mais!) podem afetar seus resultados, portanto, você deve testar em seu ambiente.
O ponto, porém, é que os gatilhos INSTEAD OF podem ser mais adequados. Agora, se pudéssemos obter gatilhos INSTEAD OF DDL…