As sete classes de implementação de classificação do SQL Server são:
- CQScanSortNovo
- CQScanTopSortNovo
- CQScanIndexSortNovo
- CQScanPartitionSortNew (somente SQL Server 2014)
- CQScanInMemSortNovo
- Procedimento compilado nativamente de OLTP na memória (Hekaton) Top N Sort (somente SQL Server 2014)
- Procedimento compilado nativamente de OLTP na memória (Hekaton) Classificação geral (somente SQL Server 2014)
Os primeiros quatro tipos foram abordados na primeira parte deste artigo.
5. CQScanInMemSortNovo
Essa classe de classificação possui vários recursos interessantes, alguns deles exclusivos:
- Como o nome sugere, ele sempre ordena inteiramente na memória; ele nunca será derramado para tempdb
- A classificação é sempre realizada usando quicksort qsort_s na biblioteca de tempo de execução C padrão MSVCR100
- Ele pode executar todos os três tipos de classificação lógica:Classificação geral, N principais e classificação distinta
- Pode ser usado para classificações flexíveis por partição de armazenamento de colunas em cluster (consulte a seção 4 na parte 1)
- A memória que ele usa pode ser armazenada em cache com o plano em vez de ser reservada logo antes da execução
- Pode ser identificado como uma classificação na memória nos planos de execução
- No máximo 500 valores podem ser classificados
- Ele nunca é usado para classificações de construção de índice (consulte a seção 3 na parte 1)
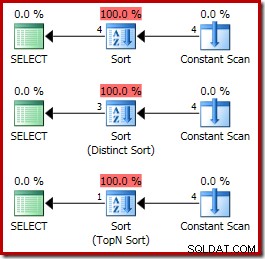
CQScanInMemSortNovo é uma classe de classificação que você não encontrará com frequência. Como ele sempre classifica na memória usando um algoritmo de classificação rápida de biblioteca padrão, não seria uma boa opção para tarefas gerais de classificação de banco de dados. Na verdade, essa classe de classificação é usada apenas quando todas as suas entradas são constantes de tempo de execução (incluindo referências @variable). Do ponto de vista do plano de execução, isso significa que a entrada para o operador Sort deve ser uma Varredura constante operador, como os exemplos abaixo demonstram:
-- Regular Sort on system scalar functions
SELECT X.i
FROM
(
SELECT @@TIMETICKS UNION ALL
SELECT @@TOTAL_ERRORS UNION ALL
SELECT @@TOTAL_READ UNION ALL
SELECT @@TOTAL_WRITE
) AS X (i)
ORDER BY X.i;
-- Distinct Sort on constant literals
WITH X (i) AS
(
SELECT 3 UNION ALL
SELECT 1 UNION ALL
SELECT 1 UNION ALL
SELECT 2
)
SELECT DISTINCT X.i
FROM X
ORDER BY X.i;
-- Top N Sort on variables, constants, and functions
DECLARE
@x integer = 1,
@y integer = 2;
SELECT TOP (1)
X.i
FROM
(
VALUES
(@x), (@y), (123),
(@@CONNECTIONS)
) AS X (i)
ORDER BY X.i; Os planos de execução são:
Uma pilha de chamadas típica durante a classificação é mostrada abaixo. Observe a chamada para qsort_s na biblioteca MSVCR100:
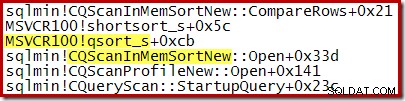
Todos os três planos de execução mostrados acima são classificações na memória usando CQScanInMemSortNew com entradas pequenas o suficiente para que a memória de classificação seja armazenada em cache. Essas informações não são expostas por padrão nos planos de execução, mas podem ser reveladas usando o sinalizador de rastreamento não documentado 8666. Quando esse sinalizador está ativo, propriedades adicionais aparecem para o operador Sort:
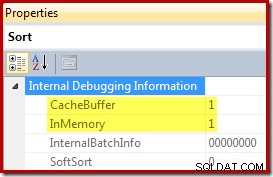
O buffer de cache é limitado a 62 linhas neste exemplo, conforme demonstrado abaixo:
-- Cache buffer limited to 62 rows
SELECT X.i
FROM
(
VALUES
(001),(002),(003),(004),(005),(006),(007),(008),(009),(010),
(011),(012),(013),(014),(015),(016),(017),(018),(019),(020),
(021),(022),(023),(024),(025),(026),(027),(028),(029),(030),
(031),(032),(033),(034),(035),(036),(037),(038),(039),(040),
(041),(042),(043),(044),(045),(046),(047),(048),(049),(050),
(051),(052),(053),(054),(055),(056),(057),(058),(059),(060),
(061),(062)--, (063)
) AS X (i)
ORDER BY X.i; Remova o comentário do item final nesse script para ver a propriedade Sort cache buffer mudar de 1 para 0:
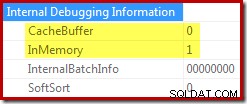
Quando o buffer não é armazenado em cache, a classificação na memória deve alocar memória à medida que inicializa e conforme necessário à medida que lê as linhas de sua entrada. Quando um buffer em cache pode ser usado, esse trabalho de alocação de memória é evitado.
O script a seguir pode ser usado para demonstrar que o número máximo de itens para um CQScanInMemSortNew quicksort na memória é 500:
SELECT X.i
FROM
(
VALUES
(001),(002),(003),(004),(005),(006),(007),(008),(009),(010),
(011),(012),(013),(014),(015),(016),(017),(018),(019),(020),
(021),(022),(023),(024),(025),(026),(027),(028),(029),(030),
(031),(032),(033),(034),(035),(036),(037),(038),(039),(040),
(041),(042),(043),(044),(045),(046),(047),(048),(049),(050),
(051),(052),(053),(054),(055),(056),(057),(058),(059),(060),
(061),(062),(063),(064),(065),(066),(067),(068),(069),(070),
(071),(072),(073),(074),(075),(076),(077),(078),(079),(080),
(081),(082),(083),(084),(085),(086),(087),(088),(089),(090),
(091),(092),(093),(094),(095),(096),(097),(098),(099),(100),
(101),(102),(103),(104),(105),(106),(107),(108),(109),(110),
(111),(112),(113),(114),(115),(116),(117),(118),(119),(120),
(121),(122),(123),(124),(125),(126),(127),(128),(129),(130),
(131),(132),(133),(134),(135),(136),(137),(138),(139),(140),
(141),(142),(143),(144),(145),(146),(147),(148),(149),(150),
(151),(152),(153),(154),(155),(156),(157),(158),(159),(160),
(161),(162),(163),(164),(165),(166),(167),(168),(169),(170),
(171),(172),(173),(174),(175),(176),(177),(178),(179),(180),
(181),(182),(183),(184),(185),(186),(187),(188),(189),(190),
(191),(192),(193),(194),(195),(196),(197),(198),(199),(200),
(201),(202),(203),(204),(205),(206),(207),(208),(209),(210),
(211),(212),(213),(214),(215),(216),(217),(218),(219),(220),
(221),(222),(223),(224),(225),(226),(227),(228),(229),(230),
(231),(232),(233),(234),(235),(236),(237),(238),(239),(240),
(241),(242),(243),(244),(245),(246),(247),(248),(249),(250),
(251),(252),(253),(254),(255),(256),(257),(258),(259),(260),
(261),(262),(263),(264),(265),(266),(267),(268),(269),(270),
(271),(272),(273),(274),(275),(276),(277),(278),(279),(280),
(281),(282),(283),(284),(285),(286),(287),(288),(289),(290),
(291),(292),(293),(294),(295),(296),(297),(298),(299),(300),
(301),(302),(303),(304),(305),(306),(307),(308),(309),(310),
(311),(312),(313),(314),(315),(316),(317),(318),(319),(320),
(321),(322),(323),(324),(325),(326),(327),(328),(329),(330),
(331),(332),(333),(334),(335),(336),(337),(338),(339),(340),
(341),(342),(343),(344),(345),(346),(347),(348),(349),(350),
(351),(352),(353),(354),(355),(356),(357),(358),(359),(360),
(361),(362),(363),(364),(365),(366),(367),(368),(369),(370),
(371),(372),(373),(374),(375),(376),(377),(378),(379),(380),
(381),(382),(383),(384),(385),(386),(387),(388),(389),(390),
(391),(392),(393),(394),(395),(396),(397),(398),(399),(400),
(401),(402),(403),(404),(405),(406),(407),(408),(409),(410),
(411),(412),(413),(414),(415),(416),(417),(418),(419),(420),
(421),(422),(423),(424),(425),(426),(427),(428),(429),(430),
(431),(432),(433),(434),(435),(436),(437),(438),(439),(440),
(441),(442),(443),(444),(445),(446),(447),(448),(449),(450),
(451),(452),(453),(454),(455),(456),(457),(458),(459),(460),
(461),(462),(463),(464),(465),(466),(467),(468),(469),(470),
(471),(472),(473),(474),(475),(476),(477),(478),(479),(480),
(481),(482),(483),(484),(485),(486),(487),(488),(489),(490),
(491),(492),(493),(494),(495),(496),(497),(498),(499),(500)
--, (501)
) AS X (i)
ORDER BY X.i; Novamente, descomente o último item para ver o InMemory Classifique a alteração da propriedade de 1 para 0. Quando isso acontecer, CQScanInMemSortNew é substituído por CQScanSortNew (consulte a seção 1) ou CQScanTopSortNew (seção 2). Um não-CQScanInMemSortNew a classificação ainda pode ser executada na memória, é claro, ela apenas usa um algoritmo diferente e pode derramar para tempdb se necessário.
6. Procedimento armazenado OLTP na memória compilado nativamente Top N Sort
A implementação atual de procedimentos armazenados compilados nativamente OLTP na memória (anteriormente denominado Hekaton) usa uma fila de prioridade seguida por qsort_s para N principais classificações, quando as seguintes condições são atendidas:
- A consulta contém TOP (N) com uma cláusula ORDER BY
- O valor de N é um literal constante (não uma variável)
- N tem um valor máximo de 8192; Apesar
- A presença de junções ou agregações pode reduzir o valor 8192 conforme documentado aqui
O código a seguir cria uma tabela Hekaton contendo 4.000 linhas:
CREATE DATABASE InMemoryOLTP;
GO
-- Add memory optimized filegroup
ALTER DATABASE InMemoryOLTP
ADD FILEGROUP InMemoryOLTPFileGroup
CONTAINS MEMORY_OPTIMIZED_DATA;
GO
-- Add file (adjust path if necessary)
ALTER DATABASE InMemoryOLTP
ADD FILE
(
NAME = N'IMOLTP',
FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL12.SQL2014\MSSQL\DATA\IMOLTP.hkf'
)
TO FILEGROUP InMemoryOLTPFileGroup;
GO
USE InMemoryOLTP;
GO
CREATE TABLE dbo.Test
(
col1 integer NOT NULL,
col2 integer NOT NULL,
col3 integer NOT NULL,
CONSTRAINT PK_dbo_Test
PRIMARY KEY NONCLUSTERED HASH (col1)
WITH (BUCKET_COUNT = 8192)
)
WITH
(
MEMORY_OPTIMIZED = ON,
DURABILITY = SCHEMA_ONLY
);
GO
-- Add numbers from 1-4000 using
-- Itzik Ben-Gan's number generator
WITH
L0 AS (SELECT 1 AS c UNION ALL SELECT 1),
L1 AS (SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS (SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B),
L3 AS (SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B),
L4 AS (SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B),
L5 AS (SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B),
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS n FROM L5)
INSERT dbo.Test
(col1, col2, col3)
SELECT
N.n,
ABS(CHECKSUM(NEWID())),
ABS(CHECKSUM(NEWID()))
FROM Nums AS N
WHERE N.n BETWEEN 1 AND 4000; O próximo script cria um Top N Sort adequado em um procedimento armazenado compilado nativamente:
-- Natively-compiled Top N Sort stored procedure
CREATE PROCEDURE dbo.TestP
WITH EXECUTE AS OWNER, SCHEMABINDING, NATIVE_COMPILATION
AS
BEGIN ATOMIC
WITH
(
TRANSACTION ISOLATION LEVEL = SNAPSHOT,
LANGUAGE = N'us_english'
)
SELECT TOP (2) T.col2
FROM dbo.Test AS T
ORDER BY T.col2
END;
GO
EXECUTE dbo.TestP; O plano de execução estimado é:

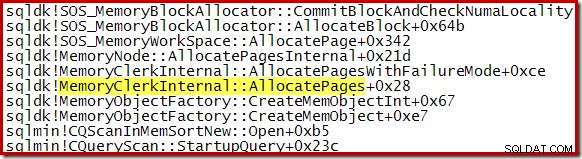
Uma pilha de chamadas capturada durante a execução mostra a inserção na fila de prioridade em andamento:

Após a conclusão da construção da fila de prioridade, a próxima pilha de chamadas mostra uma passagem final pelo quicksort da biblioteca padrão:
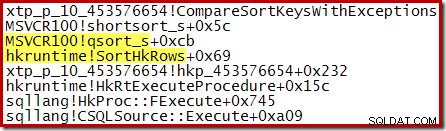
O xtp_p_* A biblioteca mostrada nessas pilhas de chamadas é a dll compilada nativamente para o procedimento armazenado, com o código-fonte salvo na instância local do SQL Server. O código-fonte é gerado automaticamente a partir da definição de procedimento armazenado. Por exemplo, o arquivo C para este procedimento armazenado nativo contém o seguinte fragmento:
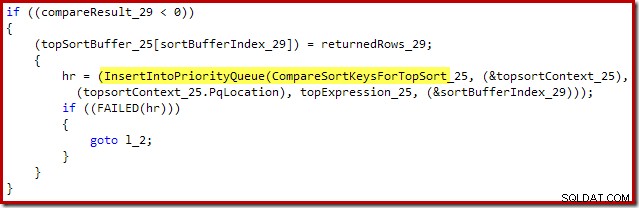
Isso é o mais próximo que podemos chegar de ter acesso ao código-fonte do SQL Server.
7. Ordenação de procedimento armazenado compilado nativamente OLTP na memória
Atualmente, os procedimentos compilados nativamente não suportam Distinct Sort, mas a classificação geral não distinta é suportada, sem quaisquer restrições no tamanho do conjunto. Para demonstrar, primeiro adicionaremos 6.000 linhas à tabela de teste, totalizando 10.000 linhas:
WITH
L0 AS (SELECT 1 AS c UNION ALL SELECT 1),
L1 AS (SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS (SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B),
L3 AS (SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B),
L4 AS (SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B),
L5 AS (SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B),
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS n FROM L5)
INSERT dbo.Test
(col1, col2, col3)
SELECT
N.n,
ABS(CHECKSUM(NEWID())),
ABS(CHECKSUM(NEWID()))
FROM Nums AS N
WHERE N.n BETWEEN 4001 AND 10000; Agora podemos descartar o procedimento de teste anterior (os procedimentos compilados nativamente não podem ser alterados no momento) e criar um novo que execute uma classificação comum (não top-n) das 10.000 linhas:
DROP PROCEDURE dbo.TestP;
GO
CREATE PROCEDURE dbo.TestP
WITH EXECUTE AS OWNER, SCHEMABINDING, NATIVE_COMPILATION
AS
BEGIN ATOMIC
WITH
(
TRANSACTION ISOLATION LEVEL = SNAPSHOT,
LANGUAGE = N'us_english'
)
SELECT T.col2
FROM dbo.Test AS T
ORDER BY T.col2
END;
GO
EXECUTE dbo.TestP; O plano de execução estimado é:

O rastreamento da execução dessa classificação mostra que ela começa gerando várias pequenas execuções classificadas usando o quicksort da biblioteca padrão novamente:
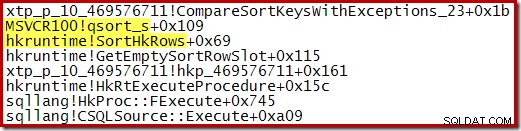
Quando esse processo estiver concluído, as execuções classificadas são mescladas, usando um esquema de fila de prioridade:
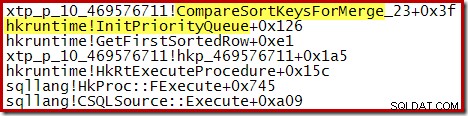
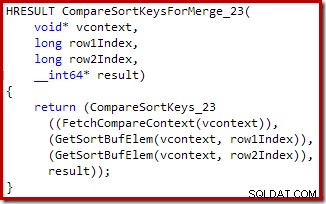
Novamente, o código-fonte C para o procedimento mostra alguns dos detalhes:
Resumo da Parte 2
- CQScanInMemSortNovo é sempre um quicksort na memória. Ele é limitado a 500 linhas de um Constant Scan e pode armazenar em cache sua memória de classificação para pequenas entradas. Uma classificação pode ser identificada como um CQScanInMemSortNew classificar usando as propriedades do plano de execução expostas pelo sinalizador de rastreamento 8666.
- A classificação N principal compilada nativa do Hekaton requer um valor literal constante para N <=8192 e classifica usando uma fila de prioridade seguida por uma classificação rápida padrão
- Hekaton compilado nativo General Sort pode classificar qualquer número de linhas, usando a biblioteca padrão quicksort para gerar execuções de classificação e uma classificação de mesclagem de fila prioritária para combinar execuções. Ele não é compatível com a classificação distinta.