Você ainda mantém o design pai/filho ou gostaria de tentar algo novo, como o ID de hierarquia do SQL Server? Bem, é realmente novo porque o hierarchyID faz parte do SQL Server desde 2008. É claro que a novidade em si não é um argumento persuasivo. Mas observe que a Microsoft adicionou esse recurso para representar relacionamentos um-para-muitos com vários níveis de uma maneira melhor.
Você pode se perguntar que diferença isso faz e quais benefícios você obtém ao usar o hierarchyID em vez dos relacionamentos pais/filhos usuais. Se você nunca explorou essa opção, pode ser surpreendente para você.
A verdade é que não explorei essa opção desde que foi lançada. No entanto, quando finalmente o fiz, achei uma grande inovação. É um código mais bonito, mas tem muito mais nele. Neste artigo, vamos descobrir todas essas excelentes oportunidades.
No entanto, antes de nos aprofundarmos nas peculiaridades do uso do hierarchyID do SQL Server, vamos esclarecer seu significado e escopo.
O que é o ID de hierarquia do SQL Server?
O hierarchyID do SQL Server é um tipo de dados interno projetado para representar árvores, que são o tipo mais comum de dados hierárquicos. Cada item em uma árvore é chamado de nó. Em um formato de tabela, é uma linha com uma coluna do tipo de dados hierarquiaID.
Normalmente, demonstramos hierarquias usando um design de tabela. Uma coluna de ID representa um nó e outra coluna representa o pai. Com o HierarchyID do SQL Server, precisamos apenas de uma coluna com um tipo de dados de hierarchyID.
Ao consultar uma tabela com uma coluna hierarchyID, você vê valores hexadecimais. É uma das imagens visuais de um nó. Outra maneira é uma string:
‘/’ representa o nó raiz;
‘/1/’, ‘/2/’, ‘/3/’ ou ‘/n/’ representam os filhos – descendentes diretos de 1 a n;
‘/1/1/’ ou ‘/1/2/’ são os “filhos de filhos – “netos”. A string como ‘/1/2/’ significa que o primeiro filho da raiz tem dois filhos, que são, por sua vez, dois netos da raiz.
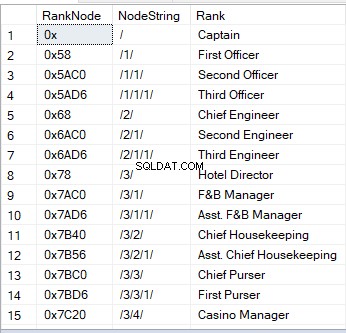
Aqui está uma amostra do que parece:
Ao contrário de outros tipos de dados, as colunas hierarquiaID podem aproveitar os métodos integrados. Por exemplo, se você tiver uma coluna hierarchyID chamada RankNode , você pode ter a seguinte sintaxe:
RankNode.
Métodos de ID de hierarquia do SQL Server
Um dos métodos disponíveis é IsDescendantOf . Ele retorna 1 se o nó atual for descendente de um valor de hierarchyID.
Você pode escrever código com este método semelhante ao abaixo:
SELECT
r.RankNode
,r.Rank
FROM dbo.Ranks r
WHERE r.RankNode.IsDescendantOf(0x58) = 1Outros métodos usados com hierarchyID são os seguintes:
- GetRoot – o método estático que retorna a raiz da árvore.
- GetDescendant – retorna um nó filho de um pai.
- GetAncestor – retorna um hierarchyID que representa o enésimo ancestral de um determinado nó.
- GetLevel – retorna um inteiro que representa a profundidade do nó.
- ToString – retorna a string com a representação lógica de um nó. ToString é chamado implicitamente quando ocorre a conversão de hierarchyID para o tipo de string.
- GetReparentedValue – move um nó do pai antigo para o novo pai.
- Parse – atua como o oposto de ToString . Ele converte a exibição de string de um hierarchyID valor para hexadecimal.
Estratégias de indexação de ID de hierarquia do SQL Server
Para garantir que as consultas de tabelas usando o hierarchyID sejam executadas o mais rápido possível, você precisa indexar a coluna. Existem duas estratégias de indexação:
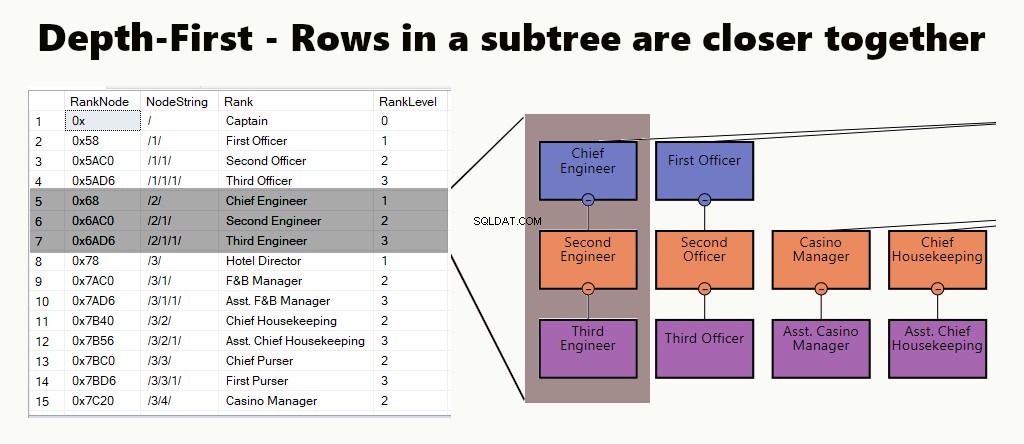
PROFUNDIDADE PRIMEIRO
Em um índice de profundidade, as linhas da subárvore estão mais próximas umas das outras. Ele atende a consultas como encontrar um departamento, suas subunidades e funcionários. Outro exemplo é um gerente e seus funcionários armazenados mais próximos.
Em uma tabela, você pode implementar um índice de profundidade criando um índice clusterizado para os nós. Além disso, executamos um de nossos exemplos, assim.
LARGURA-PRIMEIRO
Em um índice de largura, as linhas do mesmo nível estão mais próximas. Ele atende a consultas como encontrar todos os funcionários subordinados diretamente ao gerente. Se a maioria das consultas for semelhante a esta, crie um índice clusterizado com base em (1) nível e (2) nó.
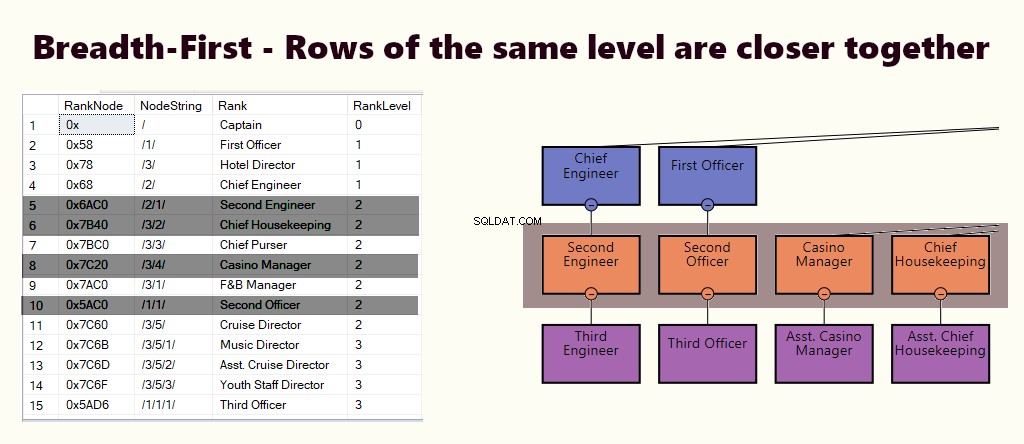
Depende de seus requisitos se você precisa de um índice de profundidade, de largura ou de ambos. Você precisa equilibrar a importância do tipo de consulta e as instruções DML executadas na tabela.
Limitações de ID de hierarquia do SQL Server
Infelizmente, o uso de hierarchyID não resolve todos os problemas:
- O SQL Server não consegue adivinhar qual é o filho de um pai. Você precisa definir a árvore na tabela.
- Se você não usar uma restrição exclusiva, o valor de hierarchyID gerado não será exclusivo. Lidar com esse problema é responsabilidade do desenvolvedor.
- Os relacionamentos de nós pai e filho não são aplicados como um relacionamento de chave estrangeira. Portanto, antes de excluir um nó, consulte quaisquer descendentes existentes.
Visualizando hierarquias
Antes de prosseguirmos, considere mais uma questão. Olhando para o conjunto de resultados com strings de nós, você acha que a visualização da hierarquia é difícil para seus olhos?
Para mim, é um grande sim porque não estou ficando mais jovem.
Por esse motivo, usaremos o Power BI e o Hierarchy Chart da Akvelon junto com nossas tabelas de banco de dados. Eles ajudarão a exibir a hierarquia em um organograma. Espero que facilite o trabalho.
Agora, vamos ao que interessa.
Usos do SQL Server HierarchyID
Você pode usar HierarchyID com os seguintes cenários de negócios:
- Estrutura organizacional
- Pastas, subpastas e arquivos
- Tarefas e subtarefas em um projeto
- Páginas e subpáginas de um site
- Dados geográficos com países, regiões e cidades
Mesmo que seu cenário de negócios seja semelhante ao acima e você raramente consulte as seções de hierarquia, você não precisa de hierarchyID.
Por exemplo, sua organização processa as folhas de pagamento dos funcionários. Você precisa acessar a subárvore para processar a folha de pagamento de alguém? De jeito nenhum. No entanto, se você processar comissões de pessoas em um sistema de marketing multinível, pode ser diferente.
Neste post, usamos a parte da estrutura organizacional e a cadeia de comando em um navio de cruzeiro. A estrutura foi adaptada do organograma daqui. Dê uma olhada na Figura 4 abaixo:

Agora você pode visualizar a hierarquia em questão. Usamos as tabelas abaixo ao longo deste post:
- Navios – é a tabela em pé para a lista dos navios de cruzeiro.
- Classificações – é a tabela de patentes da tripulação. Lá, estabelecemos hierarquias usando o hierarchyID.
- Equipe – é a lista da tripulação de cada navio e suas classificações.
A estrutura da tabela de cada caso é a seguinte:
CREATE TABLE [dbo].[Vessel](
[VesselId] [int] IDENTITY(1,1) NOT NULL,
[VesselName] [varchar](20) NOT NULL,
CONSTRAINT [PK_Vessel] PRIMARY KEY CLUSTERED
(
[VesselId] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
CREATE TABLE [dbo].[Ranks](
[RankId] [int] IDENTITY(1,1) NOT NULL,
[Rank] [varchar](50) NOT NULL,
[RankNode] [hierarchyid] NOT NULL,
[RankLevel] [smallint] NOT NULL,
[ParentRankId] [int] -- this is redundant but we will use this to compare
-- with parent/child
) ON [PRIMARY]
GO
CREATE UNIQUE NONCLUSTERED INDEX [IX_RankId] ON [dbo].[Ranks]
(
[RankId] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO
CREATE UNIQUE CLUSTERED INDEX [IX_RankNode] ON [dbo].[Ranks]
(
[RankNode] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO
CREATE TABLE [dbo].[Crew](
[CrewId] [int] IDENTITY(1,1) NOT NULL,
[CrewName] [varchar](50) NOT NULL,
[DateHired] [date] NOT NULL,
[RankId] [int] NOT NULL,
[VesselId] [int] NOT NULL,
CONSTRAINT [PK_Crew] PRIMARY KEY CLUSTERED
(
[CrewId] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
ALTER TABLE [dbo].[Crew] WITH CHECK ADD CONSTRAINT [FK_Crew_Ranks] FOREIGN KEY([RankId])
REFERENCES [dbo].[Ranks] ([RankId])
GO
ALTER TABLE [dbo].[Crew] CHECK CONSTRAINT [FK_Crew_Ranks]
GO
ALTER TABLE [dbo].[Crew] WITH CHECK ADD CONSTRAINT [FK_Crew_Vessel] FOREIGN KEY([VesselId])
REFERENCES [dbo].[Vessel] ([VesselId])
GO
ALTER TABLE [dbo].[Crew] CHECK CONSTRAINT [FK_Crew_Vessel]
GOInserindo dados de tabela com o SQL Server HierarchyID
A primeira tarefa no uso completo do hierarchyID é adicionar registros à tabela com umhierarquiaID coluna. Existem duas maneiras de fazê-lo.
Usando strings
A maneira mais rápida de inserir dados com hierarchyID é usar strings. Para ver isso em ação, vamos adicionar alguns registros às Classificações tabela.
INSERT INTO dbo.Ranks
([Rank], RankNode, RankLevel)
VALUES
('Captain', '/',0)
,('First Officer','/1/',1)
,('Chief Engineer','/2/',1)
,('Hotel Director','/3/',1)
,('Second Officer','/1/1/',2)
,('Second Engineer','/2/1/',2)
,('F&B Manager','/3/1/',2)
,('Chief Housekeeping','/3/2/',2)
,('Chief Purser','/3/3/',2)
,('Casino Manager','/3/4/',2)
,('Cruise Director','/3/5/',2)
,('Third Officer','/1/1/1/',3)
,('Third Engineer','/2/1/1/',3)
,('Asst. F&B Manager','/3/1/1/',3)
,('Asst. Chief Housekeeping','/3/2/1/',3)
,('First Purser','/3/3/1/',3)
,('Asst. Casino Manager','/3/4/1/',3)
,('Music Director','/3/5/1/',3)
,('Asst. Cruise Director','/3/5/2/',3)
,('Youth Staff Director','/3/5/3/',3)O código acima adiciona 20 registros à tabela Ranks.
Como você pode ver, a estrutura em árvore foi definida no INSERIR declaração acima. É discernível facilmente quando usamos strings. Além disso, o SQL Server converte para os valores hexadecimais correspondentes.
Usando Max(), GetAncestor() e GetDescendant()
O uso de strings se adequa à tarefa de preencher os dados iniciais. A longo prazo, você precisa do código para lidar com a inserção sem fornecer strings.
Para fazer esta tarefa, obtenha o último nó usado por um pai ou ancestral. Realizamos isso usando as funções MAX() e GetAncestor() . Veja o código de exemplo abaixo:
-- add a bartender rank reporting to the Asst. F&B Manager
DECLARE @MaxNode HIERARCHYID
DECLARE @ImmediateSuperior HIERARCHYID = 0x7AD6
SELECT @MaxNode = MAX(RankNode) FROM dbo.Ranks r
WHERE r.RankNode.GetAncestor(1) = @ImmediateSuperior
INSERT INTO dbo.Ranks
([Rank], RankNode, RankLevel)
VALUES
('Bartender', @ImmediateSuperior.GetDescendant(@MaxNode,NULL),
@ImmediateSuperior.GetDescendant(@MaxNode, NULL).GetLevel())Abaixo estão os pontos retirados do código acima:
- Primeiro, você precisa de uma variável para o último nó e o superior imediato.
- O último nó pode ser adquirido usando MAX() contra RankNode para o pai ou superior imediato especificado. No nosso caso, é o Assistant F&B Manager com um valor de nó de 0x7AD6.
- Em seguida, para garantir que nenhum filho duplicado apareça, use @ImmediateSuperior.GetDescendant(@MaxNode, NULL) . O valor em @MaxNode é o último filho. Se não for NULL , GetDescendente() retorna o próximo valor de nó possível.
- Por último, GetLevel() retorna o nível do novo nó criado.
Consultando dados
Depois de adicionar registros à nossa tabela, é hora de consultá-la. 2 maneiras de consultar dados estão disponíveis:
A consulta de descendentes diretos
Quando procuramos os funcionários subordinados diretamente ao gerente, precisamos saber duas coisas:
- O valor do nó do gerente ou pai
- O nível do funcionário abaixo do gerente
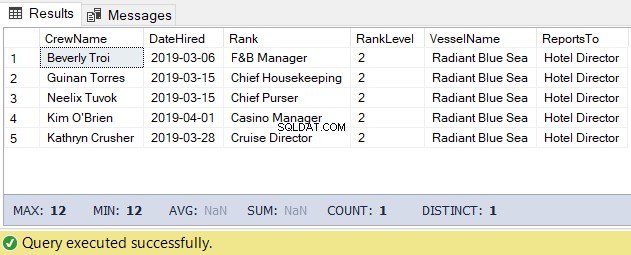
Para esta tarefa, podemos usar o código abaixo. A saída é a lista da tripulação sob o Diretor do Hotel.
-- Get the list of crew directly reporting to the Hotel Director
DECLARE @Node HIERARCHYID = 0x78 -- the Hotel Director's node/hierarchyid
DECLARE @Level SMALLINT = @Node.GetLevel()
SELECT
a.CrewName
,a.DateHired
,b.Rank
,b.RankLevel
,c.VesselName
,(SELECT Rank FROM dbo.Ranks WHERE RankNode = b.RankNode.GetAncestor(1)) AS ReportsTo
FROM dbo.Crew a
INNER JOIN dbo.Ranks b ON a.RankId = b.RankId
INNER JOIN dbo.Vessel c ON a.VesselId = c.VesselId
WHERE b.RankNode.IsDescendantOf(@Node)=1
AND b.RankLevel = @Level + 1 -- add 1 for the level of the crew under the
-- Hotel DirectorO resultado do código acima é o seguinte na Figura 5:
Consulta de subárvores
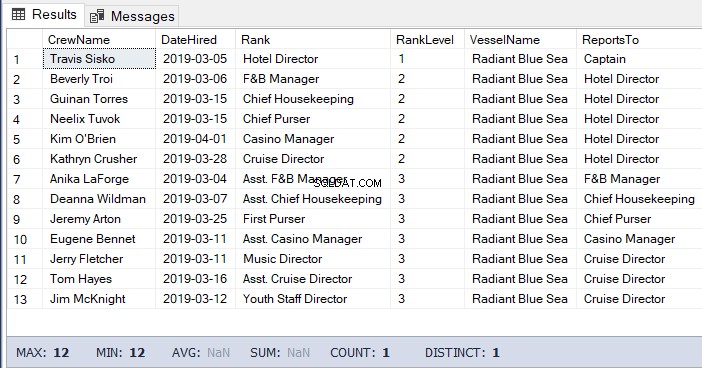
Às vezes, você também precisa listar as crianças e os filhos das crianças até o final. Para fazer isso, você precisa ter o hierarchyID do pai.
A consulta será semelhante ao código anterior, mas sem a necessidade de obter o nível. Veja o exemplo de código:
-- Get the list of the crew under the Hotel Director down to the lowest level
DECLARE @Node HIERARCHYID = 0x78 -- the Hotel Director's node/hierarchyid
SELECT
a.CrewName
,a.DateHired
,b.Rank
,b.RankLevel
,c.VesselName
,(SELECT Rank FROM dbo.Ranks WHERE RankNode = b.RankNode.GetAncestor(1)) AS ReportsTo
FROM dbo.Crew a
INNER JOIN dbo.Ranks b ON a.RankId = b.RankId
INNER JOIN dbo.Vessel c ON a.VesselId = c.VesselId
WHERE b.RankNode.IsDescendantOf(@Node)=1O resultado do código acima:
Movendo nós com o ID de hierarquia do SQL Server
Outra operação padrão com dados hierárquicos é mover um filho ou uma subárvore inteira para outro pai. No entanto, antes de prosseguirmos, observe um problema em potencial:
Potencial problema
- Primeiro, a movimentação de nós envolve E/S. A frequência com que você move os nós pode ser o fator decisivo se você usar o hierarchyID ou o pai/filho normal.
- Segundo, mover um nó em um design pai/filho atualiza uma linha. Ao mesmo tempo, quando você move um nó com hierarchyID, ele atualiza uma ou mais linhas. O número de linhas afetadas depende da profundidade do nível de hierarquia. Isso pode se transformar em um problema significativo de desempenho.
Solução
Você pode lidar com esse problema com o design do banco de dados.
Vamos considerar o design que usamos aqui.
Em vez de definir a hierarquia na Tripulação tabela, nós a definimos nas Classificações tabela. Essa abordagem difere do Funcionário tabela no AdventureWorks banco de dados de exemplo e oferece as seguintes vantagens:
- Os membros da tripulação se movem com mais frequência do que as fileiras em uma embarcação. Esse design reduzirá os movimentos dos nós na hierarquia. Como resultado, minimiza o problema definido acima.
- Definir mais de uma hierarquia na Equipe tabela é mais complicada, pois dois navios precisam de dois capitães. O resultado são dois nós raiz.
- Se você precisar exibir todas as classificações com o membro da tripulação correspondente, poderá usar um LEFT JOIN. Se ninguém estiver a bordo para essa classificação, ele mostra um espaço vazio para a posição.
Agora, vamos para o objetivo desta seção. Adicione nós filhos sob os pais errados.
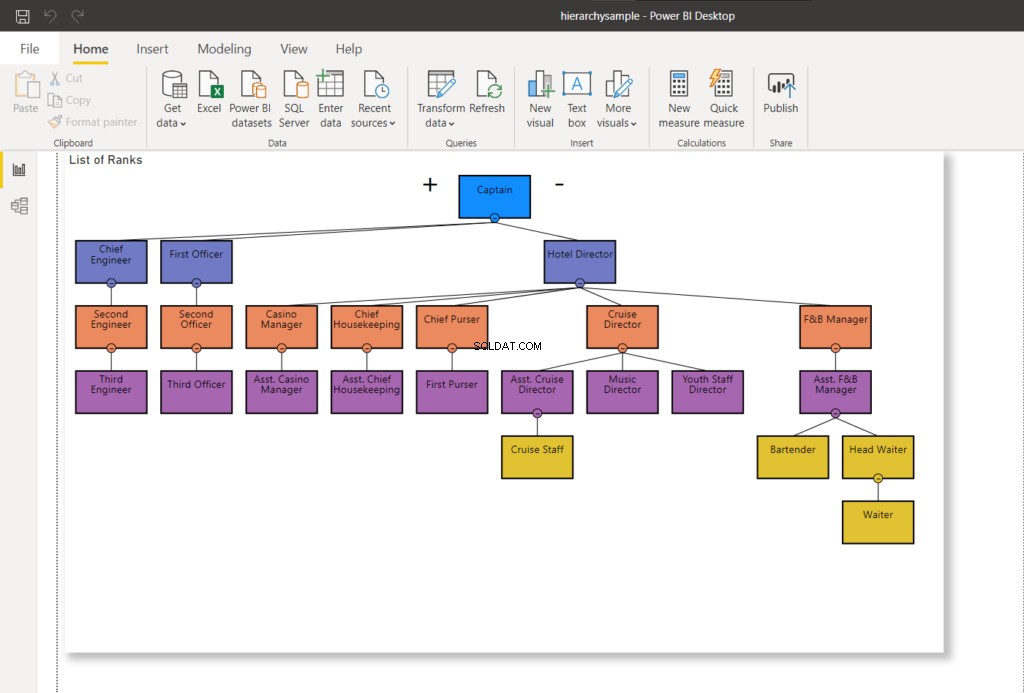
Para visualizar o que estamos prestes a fazer, imagine uma hierarquia como a abaixo. Observe os nós amarelos.

Mover um nó sem filhos
Mover um nó filho requer o seguinte:
- Defina o hierarchyID do nó filho a ser movido.
- Defina a hierarquiaID do pai antigo.
- Defina a hierarquiaID do novo pai.
- Usar ATUALIZAR com GetReparentedValue() para mover o nó fisicamente.
Comece movendo um nó sem filhos. No exemplo abaixo, movemos a Equipe do Cruzeiro do Diretor do Cruzeiro para o Assistente. Diretor do Cruzeiro.
-- Moving a node with no child node
DECLARE @NodeToMove HIERARCHYID
DECLARE @OldParent HIERARCHYID
DECLARE @NewParent HIERARCHYID
SELECT @NodeToMove = r.RankNode
FROM dbo.Ranks r
WHERE r.RankId = 24 -- the cruise staff
SELECT @OldParent = @NodeToMove.GetAncestor(1)
SELECT @NewParent = r.RankNode
FROM dbo.Ranks r
WHERE r.RankId = 19 -- the assistant cruise director
UPDATE dbo.Ranks
SET RankNode = @NodeToMove.GetReparentedValue(@OldParent,@NewParent)
WHERE RankNode = @NodeToMoveDepois que o nó for atualizado, um novo valor hexadecimal será usado para o nó. Atualizando minha conexão do Power BI com o SQL Server – isso mudará o gráfico de hierarquia conforme mostrado abaixo:
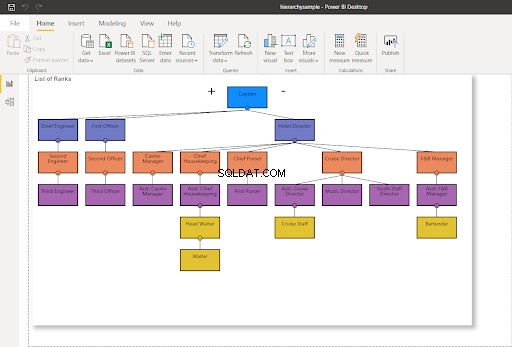
Na Figura 8, a equipe do Cruzeiro não se reporta mais ao Diretor do Cruzeiro – é alterada para reportar ao Diretor Assistente do Cruzeiro. Compare-o com a Figura 7 acima.
Agora, vamos prosseguir para a próxima etapa e mover o Head Waiter para o Assistant F&B Manager.
Mover um nó com filhos
Há um desafio nesta parte.
O problema é que o código anterior não funcionará com um nó com nem mesmo um filho. Lembramos que mover um nó requer a atualização de um ou mais nós filhos.
Além disso, não termina aí. Se o novo pai tiver um filho existente, podemos encontrar valores de nó duplicados.
Neste exemplo, temos que enfrentar esse problema:o Asst. O F&B Manager tem um nó filho Bartender.
Preparar? Aqui está o código:
-- Move a node with at least one child
DECLARE @NodeToMove HIERARCHYID
DECLARE @OldParent HIERARCHYID
DECLARE @NewParent HIERARCHYID
SELECT @NodeToMove = r.RankNode
FROM dbo.Ranks r
WHERE r.RankId = 22 -- the head waiter
SELECT @OldParent = @NodeToMove.GetAncestor(1) -- head waiter's old parent
--> asst chief housekeeping
SELECT @NewParent = r.RankNode
FROM dbo.Ranks r
WHERE r.RankId = 14 -- the assistant f&b manager
DECLARE children_cursor CURSOR FOR
SELECT RankNode FROM dbo.Ranks r
WHERE RankNode.GetAncestor(1) = @OldParent;
DECLARE @ChildId hierarchyid;
OPEN children_cursor
FETCH NEXT FROM children_cursor INTO @ChildId;
WHILE @@FETCH_STATUS = 0
BEGIN
START:
DECLARE @NewId hierarchyid;
SELECT @NewId = @NewParent.GetDescendant(MAX(RankNode), NULL)
FROM dbo.Ranks r WHERE RankNode.GetAncestor(1) = @NewParent; -- ensure
--to get a new id in case there's a
--sibling
UPDATE dbo.Ranks
SET RankNode = RankNode.GetReparentedValue(@ChildId, @NewId)
WHERE RankNode.IsDescendantOf(@ChildId) = 1;
IF @@error <> 0 GOTO START -- On error, retry
FETCH NEXT FROM children_cursor INTO @ChildId;
END
CLOSE children_cursor;
DEALLOCATE children_cursor;No exemplo de código acima, a iteração começa com a necessidade de transferir o nó para o filho no último nível.
Depois de executá-lo, as Classificações tabela será atualizada. E, novamente, se você quiser ver as alterações visualmente, atualize o relatório do Power BI. Você verá as alterações semelhantes à abaixo:
Benefícios de usar o ID de hierarquia do SQL Server vs. Pai/Filho
Para convencer alguém a usar um recurso, precisamos conhecer os benefícios.
Assim, nesta seção, compararemos declarações usando as mesmas tabelas como as do início. Um usará hierarquiaID e o outro usará a abordagem pai/filho. O conjunto de resultados será o mesmo para ambas as abordagens. Esperamos que para este exercício seja igual ao da Figura 6 acima de.
Agora que os requisitos são precisos, vamos examinar os benefícios minuciosamente.
Mais simples de codificar
Veja o código abaixo:
-- List down all the crew under the Hotel Director using hierarchyID
SELECT
a.CrewName
,a.DateHired
,b.Rank
,b.RankLevel
,c.VesselName
,d.RANK AS ReportsTo
FROM dbo.Crew a
INNER JOIN dbo.Vessel c ON a.VesselId = c.VesselId
INNER JOIN dbo.Ranks b ON a.RankId = b.RankId
INNER JOIN dbo.Ranks d ON d.RankNode = b.RankNode.GetAncestor(1)
WHERE a.VesselId = 1
AND b.RankNode.IsDescendantOf(0x78)=1Esta amostra precisa apenas de um valor de hierarchyID. Você pode alterar o valor à vontade sem alterar a consulta.
Agora, compare a instrução para a abordagem pai/filho produzindo o mesmo conjunto de resultados:
-- List down all the crew under the Hotel Director using parent/child
SELECT
a.CrewName
,a.DateHired
,b.Rank
,b.RankLevel
,c.VesselName
,d.Rank AS ReportsTo
FROM dbo.Crew a
INNER JOIN dbo.Vessel c ON a.VesselId = c.VesselId
INNER JOIN dbo.Ranks b ON a.RankId = b.RankId
INNER JOIN dbo.Ranks d ON b.RankParentId = d.RankId
WHERE a.VesselId = 1
AND (b.RankID = 4) OR (b.RankParentID = 4 OR b.RankParentId >= 7)O que você acha? Os exemplos de código são quase os mesmos, exceto um ponto.
O ONDE cláusula na segunda consulta não será flexível para se adaptar se uma subárvore diferente for necessária.
Torne a segunda consulta suficientemente genérica e o código será mais longo. Caramba!
Execução mais rápida
De acordo com a Microsoft, “consultas de subárvore são significativamente mais rápidas com o hierarchyID” em comparação com pai/filho. Vamos ver se é verdade.
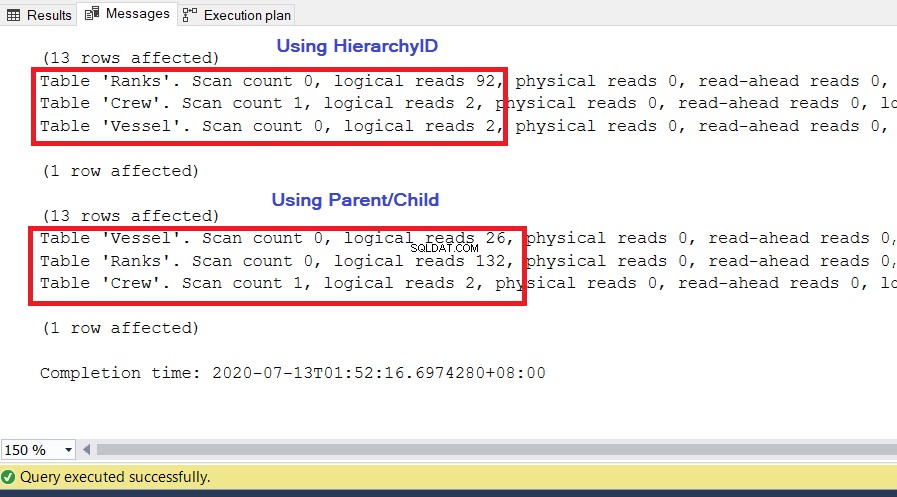
Usamos as mesmas consultas anteriores. Uma métrica significativa a ser usada para desempenho são as leituras lógicas do SET STATISTICS IO . Ele informa quantas páginas de 8 KB o SQL Server precisará para obter o conjunto de resultados que desejamos. Quanto maior o valor, maior o número de páginas que o SQL Server acessa e lê, e mais lenta a execução da consulta. Execute SET STATISTICS IO ON e execute novamente as duas consultas acima. O valor mais baixo das leituras lógicas será o vencedor.
ANÁLISE
Como você pode ver na Figura 10, as estatísticas de E/S para a consulta com hierarchyID têm leituras lógicas mais baixas do que suas contrapartes pai/filho. Observe os seguintes pontos neste resultado:
- A Embarcação table é a mais notável das três tabelas. O uso de hierarchyID requer apenas 2 * 8 KB =16 KB de páginas a serem lidas pelo SQL Server a partir do cache (memória). Enquanto isso, usar pai/filho requer 26 * 8 KB =208 KB de páginas – significativamente mais alto do que usar o hierarchyID.
- As Classificações tabela, que inclui nossa definição de hierarquias, requer 92 * 8 KB =736 KB. Por outro lado, usar pai/filho requer 132 * 8 KB =1056 KB.
- A Equipe tabela precisa de 2 * 8 KB =16 KB, que é o mesmo para ambas as abordagens.
Kilobytes de páginas podem ser um valor pequeno por enquanto, mas temos apenas alguns registros. No entanto, isso nos dá uma ideia de como nossa consulta será exigente em qualquer servidor. Para melhorar o desempenho, você pode executar uma ou mais das seguintes ações:
- Adicione índices apropriados
- Reestruturar a consulta
- Atualizar estatísticas
Se você fez o acima e as leituras lógicas diminuíram sem adicionar mais registros, o desempenho aumentaria. Contanto que você faça as leituras lógicas mais baixas do que para a que usa o hierarchyID, isso será uma boa notícia.
Mas por que se referir a leituras lógicas em vez de tempo decorrido?
Verificando o tempo decorrido para ambas as consultas usando SET STATISTICS TIME ON revela um pequeno número de diferenças de milissegundos para nosso pequeno conjunto de dados. Além disso, seu servidor de desenvolvimento pode ter uma configuração de hardware, configurações do SQL Server e carga de trabalho diferentes. Um tempo decorrido de menos de um milissegundo pode enganá-lo se sua consulta estiver executando tão rápido quanto o esperado ou não.
CAVANDO MAIS
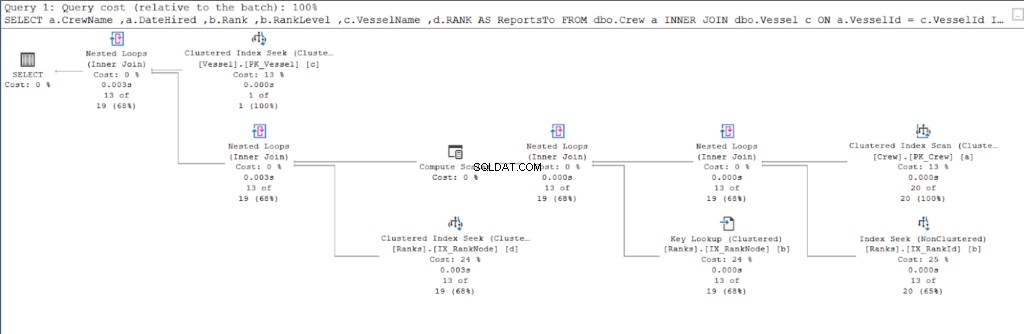
ATIVAR E/S DE ESTATÍSTICAS não revela as coisas que acontecem “nos bastidores”. Nesta seção, descobrimos por que o SQL Server chega com esses números observando o plano de execução.
Vamos começar com o plano de execução da primeira consulta.
Agora, observe o plano de execução da segunda consulta.
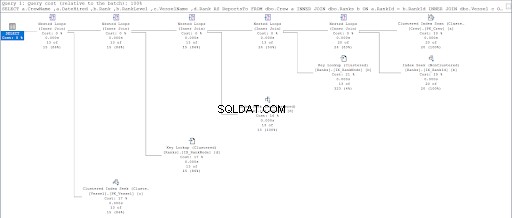
Comparando as Figuras 11 e 12, vemos que o SQL Server precisa de esforço adicional para produzir o conjunto de resultados se você usar a abordagem pai/filho. O ONDE cláusula é responsável por esta complicação.
No entanto, a falha também pode ser do design da mesa. Usamos a mesma tabela para ambas as abordagens:as Classificações tabela. Então, tentei duplicar as Classificações tabela, mas utilizam diferentes índices clusterizados apropriados para cada procedimento.
No resultado, o uso de hierarchyID ainda teve menos leituras lógicas em comparação com a contraparte pai/filho. Finalmente, provamos que a Microsoft estava certa em reivindicar isso.
Conclusão
Aqui, o momento aha central para hierarchyID é:
- HierarchyID é um tipo de dados integrado projetado para uma representação mais otimizada de árvores, que são o tipo mais comum de dados hierárquicos.
- Cada item na árvore é um nó, e os valores de hierarchyID podem estar em formato hexadecimal ou de string.
- HierarchyID é aplicável a dados de estruturas organizacionais, tarefas de projeto, dados geográficos e similares.
- Existem métodos para percorrer e manipular dados hierárquicos, como GetAncestor (), GetDescendant (). GetLevel (), GetReparentedValue () e muito mais.
- A maneira convencional de consultar dados hierárquicos é obter os descendentes diretos de um nó ou obter as subárvores sob um nó.
- O uso de hierarchyID para consultar subárvores não é apenas mais simples de codificar. Ele também tem um desempenho melhor do que pai/filho.
O design pai/filho não é nada ruim, e este post não é para diminuir isso. No entanto, expandir as opções e introduzir novas ideias é sempre um grande benefício para um desenvolvedor.
Você mesmo pode tentar os exemplos que oferecemos aqui. Receba os efeitos e veja como você pode aplicá-los em seu próximo projeto envolvendo hierarquias.
Se você gostar do post e de suas ideias, você pode divulgar clicando nos botões de compartilhamento da mídia social preferida.