As tarefas Gaps e Islands são desafios de consulta clássicos em que você precisa identificar intervalos de valores ausentes e intervalos de valores existentes em uma sequência. A sequência geralmente é baseada em alguma data, ou valores de data e hora, que normalmente deveriam aparecer em intervalos regulares, mas algumas entradas estão faltando. A tarefa de intervalos procura os períodos ausentes e a tarefa de ilhas procura os períodos existentes. Eu cobri muitas soluções para tarefas de lacunas e ilhas em meus livros e artigos no passado. Recentemente fui presenteado com um novo desafio especial de ilhas pelo meu amigo Adam Machanic, e resolvê-lo exigiu um pouco de criatividade. Neste artigo apresento o desafio e a solução que encontrei.
O desafio
Em seu banco de dados, você acompanha os serviços que sua empresa suporta em uma tabela chamada CompanyServices, e cada serviço normalmente informa uma vez por minuto que está online em uma tabela chamada EventLog. O código a seguir cria essas tabelas e as preenche com pequenos conjuntos de dados de exemplo:
SET NOCOUNT ON; USE tempdb; IF OBJECT_ID(N'dbo.EventLog') IS NOT NULL DROP TABLE dbo.EventLog; IF OBJECT_ID(N'dbo.CompanyServices') IS NOT NULL DROP TABLE dbo.CompanyServices; CREATE TABLE dbo.CompanyServices ( serviceid INT NOT NULL, CONSTRAINT PK_CompanyServices PRIMARY KEY(serviceid) ); GO INSERT INTO dbo.CompanyServices(serviceid) VALUES(1), (2), (3); CREATE TABLE dbo.EventLog ( logid INT NOT NULL IDENTITY, serviceid INT NOT NULL, logtime DATETIME2(0) NOT NULL, CONSTRAINT PK_EventLog PRIMARY KEY(logid) ); GO INSERT INTO dbo.EventLog(serviceid, logtime) VALUES (1, '20180912 08:00:00'), (1, '20180912 08:01:01'), (1, '20180912 08:01:59'), (1, '20180912 08:03:00'), (1, '20180912 08:05:00'), (1, '20180912 08:06:02'), (2, '20180912 08:00:02'), (2, '20180912 08:01:03'), (2, '20180912 08:02:01'), (2, '20180912 08:03:00'), (2, '20180912 08:03:59'), (2, '20180912 08:05:01'), (2, '20180912 08:06:01'), (3, '20180912 08:00:01'), (3, '20180912 08:03:01'), (3, '20180912 08:04:02'), (3, '20180912 08:06:00'); SELECT * FROM dbo.EventLog;
A tabela EventLog está atualmente preenchida com os seguintes dados:
logid serviceid logtime ----------- ----------- --------------------------- 1 1 2018-09-12 08:00:00 2 1 2018-09-12 08:01:01 3 1 2018-09-12 08:01:59 4 1 2018-09-12 08:03:00 5 1 2018-09-12 08:05:00 6 1 2018-09-12 08:06:02 7 2 2018-09-12 08:00:02 8 2 2018-09-12 08:01:03 9 2 2018-09-12 08:02:01 10 2 2018-09-12 08:03:00 11 2 2018-09-12 08:03:59 12 2 2018-09-12 08:05:01 13 2 2018-09-12 08:06:01 14 3 2018-09-12 08:00:01 15 3 2018-09-12 08:03:01 16 3 2018-09-12 08:04:02 17 3 2018-09-12 08:06:00
A tarefa das ilhas especiais é identificar os períodos de disponibilidade (atendimento, hora de início, hora de término). Um problema é que não há garantia de que um serviço informará que está online exatamente a cada minuto; você deve tolerar um intervalo de até, digamos, 66 segundos da entrada de log anterior e ainda considerá-la parte do mesmo período de disponibilidade (ilha). Além de 66 segundos, a nova entrada de log inicia um novo período de disponibilidade. Portanto, para os dados de amostra de entrada acima, sua solução deve retornar o seguinte conjunto de resultados (não necessariamente nesta ordem):
serviceid starttime endtime ----------- --------------------------- --------------------------- 1 2018-09-12 08:00:00 2018-09-12 08:03:00 1 2018-09-12 08:05:00 2018-09-12 08:06:02 2 2018-09-12 08:00:02 2018-09-12 08:06:01 3 2018-09-12 08:00:01 2018-09-12 08:00:01 3 2018-09-12 08:03:01 2018-09-12 08:04:02 3 2018-09-12 08:06:00 2018-09-12 08:06:00
Observe, por exemplo, como a entrada de log 5 inicia uma nova ilha, pois o intervalo da entrada de log anterior é de 120 segundos (> 66), enquanto a entrada de log 6 não inicia uma nova ilha, pois o intervalo da entrada anterior é de 62 segundos ( <=66). Outro problema é que Adam queria que a solução fosse compatível com ambientes pré-SQL Server 2012, o que torna o desafio muito mais difícil, já que você não pode usar funções de agregação de janela com um quadro para calcular totais em execução e funções de janela de deslocamento como LAG e LEAD. Como de costume, sugiro tentar resolver o desafio sozinho antes de olhar para minhas soluções. Use os pequenos conjuntos de dados de amostra para verificar a validade de suas soluções. Use o código a seguir para preencher suas tabelas com grandes conjuntos de dados de amostra (500 serviços, ~10 milhões de entradas de log para testar o desempenho de suas soluções):
-- Helper function dbo.GetNums
IF OBJECT_ID(N'dbo.GetNums') IS NOT NULL DROP FUNCTION dbo.GetNums;
GO
CREATE FUNCTION dbo.GetNums(@low AS BIGINT, @high AS BIGINT) RETURNS TABLE
AS
RETURN
WITH
L0 AS (SELECT c FROM (SELECT 1 UNION ALL SELECT 1) AS D(c)),
L1 AS (SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS (SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B),
L3 AS (SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B),
L4 AS (SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B),
L5 AS (SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B),
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L5)
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum;
GO
-- ~10,000,000 intervals
DECLARE
@numservices AS INT = 500,
@logsperservice AS INT = 20000,
@enddate AS DATETIME2(0) = '20180912',
@validinterval AS INT = 60, -- seconds
@normdifferential AS INT = 3, -- seconds
@percentmissing AS FLOAT = 0.01;
TRUNCATE TABLE dbo.EventLog;
TRUNCATE TABLE dbo.CompanyServices;
INSERT INTO dbo.CompanyServices(serviceid)
SELECT A.n AS serviceid
FROM dbo.GetNums(1, @numservices) AS A;
WITH C AS
(
SELECT S.n AS serviceid,
DATEADD(second, -L.n * @validinterval + CHECKSUM(NEWID()) % (@normdifferential + 1), @enddate) AS logtime,
RAND(CHECKSUM(NEWID())) AS rnd
FROM dbo.GetNums(1, @numservices) AS S
CROSS JOIN dbo.GetNums(1, @logsperservice) AS L
)
INSERT INTO dbo.EventLog WITH (TABLOCK) (serviceid, logtime)
SELECT serviceid, logtime
FROM C
WHERE rnd > @percentmissing; As saídas que fornecerei para as etapas de minhas soluções assumirão os pequenos conjuntos de dados de amostra e os números de desempenho que fornecerei assumirão os grandes conjuntos.
Todas as soluções que apresentarei se beneficiam do seguinte índice:
CREATE INDEX idx_sid_ltm_lid ON dbo.EventLog(serviceid, logtime, logid);
Boa sorte!
Solução 1 para SQL Server 2012+
Antes de abordar uma solução compatível com ambientes pré-SQL Server 2012, abordarei uma que requer um mínimo de SQL Server 2012. Vou chamá-la de Solução 1.
O primeiro passo na solução é calcular um sinalizador chamado isstart que é 0 se o evento não iniciar uma nova ilha e 1 caso contrário. Isso pode ser feito usando a função LAG para obter o tempo de log do evento anterior e verificando se a diferença de tempo em segundos entre os eventos anteriores e atuais é menor ou igual ao intervalo permitido. Aqui está o código que implementa esta etapa:
DECLARE @allowedgap AS INT = 66; -- in seconds
SELECT *,
CASE
WHEN DATEDIFF(second,
LAG(logtime) OVER(PARTITION BY serviceid ORDER BY logtime, logid),
logtime) <= @allowedgap THEN 0
ELSE 1
END AS isstart
FROM dbo.EventLog; Este código gera a seguinte saída:
logid serviceid logtime isstart ----------- ----------- --------------------------- ----------- 1 1 2018-09-12 08:00:00 1 2 1 2018-09-12 08:01:01 0 3 1 2018-09-12 08:01:59 0 4 1 2018-09-12 08:03:00 0 5 1 2018-09-12 08:05:00 1 6 1 2018-09-12 08:06:02 0 7 2 2018-09-12 08:00:02 1 8 2 2018-09-12 08:01:03 0 9 2 2018-09-12 08:02:01 0 10 2 2018-09-12 08:03:00 0 11 2 2018-09-12 08:03:59 0 12 2 2018-09-12 08:05:01 0 13 2 2018-09-12 08:06:01 0 14 3 2018-09-12 08:00:01 1 15 3 2018-09-12 08:03:01 1 16 3 2018-09-12 08:04:02 0 17 3 2018-09-12 08:06:00 1
Em seguida, um simples total de execução do sinalizador isstart produz um identificador de ilha (vou chamá-lo de grp). Aqui está o código que implementa esta etapa:
DECLARE @allowedgap AS INT = 66;
WITH C1 AS
(
SELECT *,
CASE
WHEN DATEDIFF(second,
LAG(logtime) OVER(PARTITION BY serviceid ORDER BY logtime, logid),
logtime) <= @allowedgap THEN 0
ELSE 1
END AS isstart
FROM dbo.EventLog
)
SELECT *,
SUM(isstart) OVER(PARTITION BY serviceid ORDER BY logtime, logid
ROWS UNBOUNDED PRECEDING) AS grp
FROM C1; Este código gera a seguinte saída:
logid serviceid logtime isstart grp ----------- ----------- --------------------------- ----------- ----------- 1 1 2018-09-12 08:00:00 1 1 2 1 2018-09-12 08:01:01 0 1 3 1 2018-09-12 08:01:59 0 1 4 1 2018-09-12 08:03:00 0 1 5 1 2018-09-12 08:05:00 1 2 6 1 2018-09-12 08:06:02 0 2 7 2 2018-09-12 08:00:02 1 1 8 2 2018-09-12 08:01:03 0 1 9 2 2018-09-12 08:02:01 0 1 10 2 2018-09-12 08:03:00 0 1 11 2 2018-09-12 08:03:59 0 1 12 2 2018-09-12 08:05:01 0 1 13 2 2018-09-12 08:06:01 0 1 14 3 2018-09-12 08:00:01 1 1 15 3 2018-09-12 08:03:01 1 2 16 3 2018-09-12 08:04:02 0 2 17 3 2018-09-12 08:06:00 1 3
Por fim, você agrupa as linhas por ID de serviço e o identificador da ilha e retorna os tempos de registro mínimo e máximo como a hora de início e a hora de término de cada ilha. Aqui está a solução completa:
DECLARE @allowedgap AS INT = 66;
WITH C1 AS
(
SELECT *,
CASE
WHEN DATEDIFF(second,
LAG(logtime) OVER(PARTITION BY serviceid ORDER BY logtime, logid),
logtime) <= @allowedgap THEN 0
ELSE 1
END AS isstart
FROM dbo.EventLog
),
C2 AS
(
SELECT *,
SUM(isstart) OVER(PARTITION BY serviceid ORDER BY logtime, logid
ROWS UNBOUNDED PRECEDING) AS grp
FROM C1
)
SELECT serviceid, MIN(logtime) AS starttime, MAX(logtime) AS endtime
FROM C2
GROUP BY serviceid, grp; Essa solução levou 41 segundos para ser concluída no meu sistema e produziu o plano mostrado na Figura 1.
 Figura 1:plano para a solução 1
Figura 1:plano para a solução 1 Como você pode ver, ambas as funções de janela são calculadas com base na ordem do índice, sem a necessidade de classificação explícita.
Se você estiver usando o SQL Server 2016 ou posterior, poderá usar o truque que abordo aqui para habilitar o operador Window Aggregate do modo em lote criando um índice columnstore filtrado vazio, assim:
CREATE NONCLUSTERED COLUMNSTORE INDEX idx_cs ON dbo.EventLog(logid) WHERE logid = -1 AND logid = -2;
A mesma solução agora leva apenas 5 segundos para ser concluída no meu sistema, produzindo o plano mostrado na Figura 2.
 Figura 2:planejar a solução 1 usando o operador Window Aggregate do modo de lote
Figura 2:planejar a solução 1 usando o operador Window Aggregate do modo de lote Tudo isso é ótimo, mas, como mencionado, Adam estava procurando uma solução que pudesse ser executada em ambientes anteriores a 2012.
Antes de continuar, certifique-se de descartar o índice columnstore para limpeza:
DROP INDEX idx_cs ON dbo.EventLog;
Solução 2 para ambientes pré-SQL Server 2012
Infelizmente, antes do SQL Server 2012, não tínhamos suporte para funções de janela de deslocamento como LAG, nem suporte para calcular totais em execução com funções de agregação de janela com um quadro. Isso significa que você precisará trabalhar muito mais para encontrar uma solução razoável.
O truque que usei é transformar cada entrada de log em um intervalo artificial cuja hora de início é a hora de log da entrada e cuja hora de término é a hora de log da entrada mais o intervalo permitido. Você pode então tratar a tarefa como uma tarefa clássica de empacotamento de intervalo.
A primeira etapa da solução calcula os delimitadores de intervalo artificiais e os números de linha que marcam as posições de cada um dos tipos de eventos (counteach). Aqui está o código que implementa esta etapa:
DECLARE @allowedgap AS INT = 66; SELECT logid, serviceid, logtime AS s, -- important, 's' > 'e', for later ordering DATEADD(second, @allowedgap, logtime) AS e, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, logid) AS counteach FROM dbo.EventLog;
Este código gera a seguinte saída:
logid serviceid s e counteach ------ ---------- -------------------- -------------------- ---------- 1 1 2018-09-12 08:00:00 2018-09-12 08:01:06 1 2 1 2018-09-12 08:01:01 2018-09-12 08:02:07 2 3 1 2018-09-12 08:01:59 2018-09-12 08:03:05 3 4 1 2018-09-12 08:03:00 2018-09-12 08:04:06 4 5 1 2018-09-12 08:05:00 2018-09-12 08:06:06 5 6 1 2018-09-12 08:06:02 2018-09-12 08:07:08 6 7 2 2018-09-12 08:00:02 2018-09-12 08:01:08 1 8 2 2018-09-12 08:01:03 2018-09-12 08:02:09 2 9 2 2018-09-12 08:02:01 2018-09-12 08:03:07 3 10 2 2018-09-12 08:03:00 2018-09-12 08:04:06 4 11 2 2018-09-12 08:03:59 2018-09-12 08:05:05 5 12 2 2018-09-12 08:05:01 2018-09-12 08:06:07 6 13 2 2018-09-12 08:06:01 2018-09-12 08:07:07 7 14 3 2018-09-12 08:00:01 2018-09-12 08:01:07 1 15 3 2018-09-12 08:03:01 2018-09-12 08:04:07 2 16 3 2018-09-12 08:04:02 2018-09-12 08:05:08 3 17 3 2018-09-12 08:06:00 2018-09-12 08:07:06 4
A próxima etapa é desarticular os intervalos em uma sequência cronológica de eventos de início e fim, identificados como tipos de eventos 's' e 'e', respectivamente. Note que a escolha das letras s e e é importante (
's' > 'e' ). Esta etapa calcula os números de linha que marcam a ordem cronológica correta de ambos os tipos de eventos, que agora são intercalados (countboth). Caso um intervalo termine exatamente onde outro começa, posicionando o evento inicial antes do evento final, você os agrupará. Aqui está o código que implementa esta etapa: DECLARE @allowedgap AS INT = 66;
WITH C1 AS
(
SELECT logid, serviceid,
logtime AS s, -- important, 's' > 'e', for later ordering
DATEADD(second, @allowedgap, logtime) AS e,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, logid) AS counteach
FROM dbo.EventLog
)
SELECT logid, serviceid, logtime, eventtype, counteach,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) AS countboth
FROM C1
UNPIVOT(logtime FOR eventtype IN (s, e)) AS U; Este código gera a seguinte saída:
logid serviceid logtime eventtype counteach countboth ------ ---------- -------------------- ---------- ---------- ---------- 1 1 2018-09-12 08:00:00 s 1 1 2 1 2018-09-12 08:01:01 s 2 2 1 1 2018-09-12 08:01:06 e 1 3 3 1 2018-09-12 08:01:59 s 3 4 2 1 2018-09-12 08:02:07 e 2 5 4 1 2018-09-12 08:03:00 s 4 6 3 1 2018-09-12 08:03:05 e 3 7 4 1 2018-09-12 08:04:06 e 4 8 5 1 2018-09-12 08:05:00 s 5 9 6 1 2018-09-12 08:06:02 s 6 10 5 1 2018-09-12 08:06:06 e 5 11 6 1 2018-09-12 08:07:08 e 6 12 7 2 2018-09-12 08:00:02 s 1 1 8 2 2018-09-12 08:01:03 s 2 2 7 2 2018-09-12 08:01:08 e 1 3 9 2 2018-09-12 08:02:01 s 3 4 8 2 2018-09-12 08:02:09 e 2 5 10 2 2018-09-12 08:03:00 s 4 6 9 2 2018-09-12 08:03:07 e 3 7 11 2 2018-09-12 08:03:59 s 5 8 10 2 2018-09-12 08:04:06 e 4 9 12 2 2018-09-12 08:05:01 s 6 10 11 2 2018-09-12 08:05:05 e 5 11 13 2 2018-09-12 08:06:01 s 7 12 12 2 2018-09-12 08:06:07 e 6 13 13 2 2018-09-12 08:07:07 e 7 14 14 3 2018-09-12 08:00:01 s 1 1 14 3 2018-09-12 08:01:07 e 1 2 15 3 2018-09-12 08:03:01 s 2 3 16 3 2018-09-12 08:04:02 s 3 4 15 3 2018-09-12 08:04:07 e 2 5 16 3 2018-09-12 08:05:08 e 3 6 17 3 2018-09-12 08:06:00 s 4 7 17 3 2018-09-12 08:07:06 e 4 8
Como mencionado, counteach marca a posição do evento apenas entre os eventos do mesmo tipo, e countboth marca a posição do evento entre os eventos combinados e intercalados de ambos os tipos.
A mágica é então tratada pela próxima etapa – computando a contagem de intervalos ativos após cada evento com base em counteach e countboth. O número de intervalos ativos é o número de eventos de início que aconteceram até agora menos o número de eventos de término que aconteceram até agora. Para eventos de início, counteach informa quantos eventos de início aconteceram até agora e você pode descobrir quantos terminaram até agora subtraindo counteach de countboth. Então, a expressão completa informando quantos intervalos estão ativos é então:
counteach - (countboth - counteach)
Para eventos finais, counteach informa quantos eventos finais aconteceram até agora e você pode descobrir quantos começaram até agora subtraindo counteach de countboth. Então, a expressão completa informando quantos intervalos estão ativos é então:
(countboth - counteach) - counteach
Usando a seguinte expressão CASE, você calcula a coluna de contagem ativa com base no tipo de evento:
CASE
WHEN eventtype = 's' THEN
counteach - (countboth - counteach)
WHEN eventtype = 'e' THEN
(countboth - counteach) - counteach
END Na mesma etapa, você filtra apenas os eventos que representam início e fim de intervalos compactados. Os inícios de intervalos compactados têm um tipo 's' e um countactive 1. Os finais de intervalos compactados têm um tipo 'e' e um countactive 0.
Após a filtragem, você fica com pares de eventos start-end de intervalos compactados, mas cada par é dividido em duas linhas – uma para o evento inicial e outra para o evento final. Portanto, a mesma etapa calcula o identificador do par usando números de linha, com a fórmula (rownum – 1) / 2 + 1.
Aqui está o código que implementa esta etapa:
DECLARE @allowedgap AS INT = 66;
WITH C1 AS
(
SELECT logid, serviceid,
logtime AS s, -- important, 's' > 'e', for later ordering
DATEADD(second, @allowedgap, logtime) AS e,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, logid) AS counteach
FROM dbo.EventLog
),
C2 AS
(
SELECT logid, serviceid, logtime, eventtype, counteach,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) AS countboth
FROM C1
UNPIVOT(logtime FOR eventtype IN (s, e)) AS U
)
SELECT serviceid, eventtype, logtime,
(ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) - 1) / 2 + 1 AS grp
FROM C2
CROSS APPLY ( VALUES( CASE
WHEN eventtype = 's' THEN
counteach - (countboth - counteach)
WHEN eventtype = 'e' THEN
(countboth - counteach) - counteach
END ) ) AS A(countactive)
WHERE (eventtype = 's' AND countactive = 1)
OR (eventtype = 'e' AND countactive = 0); Este código gera a seguinte saída:
serviceid eventtype logtime grp ----------- ---------- -------------------- ---- 1 s 2018-09-12 08:00:00 1 1 e 2018-09-12 08:04:06 1 1 s 2018-09-12 08:05:00 2 1 e 2018-09-12 08:07:08 2 2 s 2018-09-12 08:00:02 1 2 e 2018-09-12 08:07:07 1 3 s 2018-09-12 08:00:01 1 3 e 2018-09-12 08:01:07 1 3 s 2018-09-12 08:03:01 2 3 e 2018-09-12 08:05:08 2 3 s 2018-09-12 08:06:00 3 3 e 2018-09-12 08:07:06 3
A última etapa dinamiza os pares de eventos em uma linha por intervalo e subtrai o intervalo permitido do horário de término para gerar novamente o horário correto do evento. Aqui está o código da solução completa:
DECLARE @allowedgap AS INT = 66;
WITH C1 AS
(
SELECT logid, serviceid,
logtime AS s, -- important, 's' > 'e', for later ordering
DATEADD(second, @allowedgap, logtime) AS e,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, logid) AS counteach
FROM dbo.EventLog
),
C2 AS
(
SELECT logid, serviceid, logtime, eventtype, counteach,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) AS countboth
FROM C1
UNPIVOT(logtime FOR eventtype IN (s, e)) AS U
),
C3 AS
(
SELECT serviceid, eventtype, logtime,
(ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) - 1) / 2 + 1 AS grp
FROM C2
CROSS APPLY ( VALUES( CASE
WHEN eventtype = 's' THEN
counteach - (countboth - counteach)
WHEN eventtype = 'e' THEN
(countboth - counteach) - counteach
END ) ) AS A(countactive)
WHERE (eventtype = 's' AND countactive = 1)
OR (eventtype = 'e' AND countactive = 0)
)
SELECT serviceid, s AS starttime, DATEADD(second, -@allowedgap, e) AS endtime
FROM C3
PIVOT( MAX(logtime) FOR eventtype IN (s, e) ) AS P; Essa solução levou 43 segundos para ser concluída no meu sistema e gerou o plano mostrado na Figura 3.
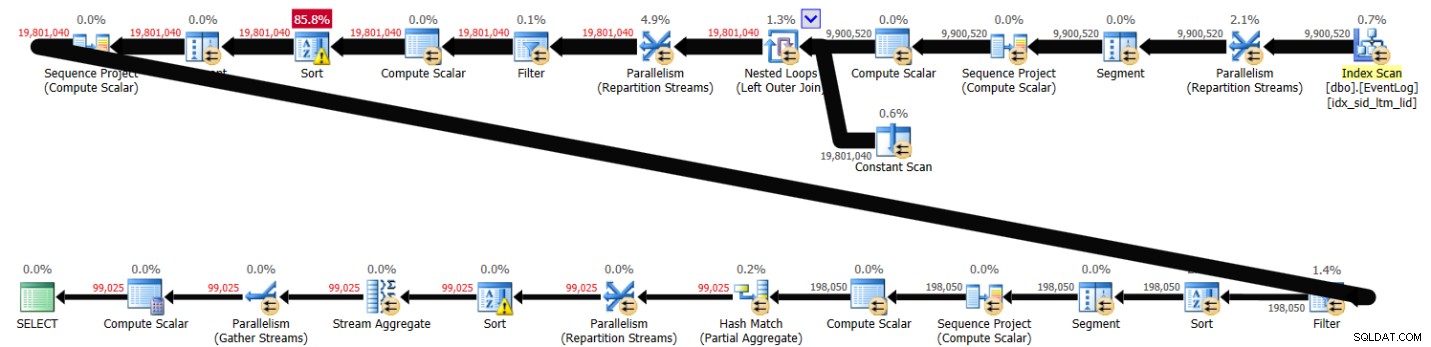 Figura 3:plano para a solução 2
Figura 3:plano para a solução 2 Como você pode ver, o cálculo do número da primeira linha é calculado com base na ordem do índice, mas os próximos dois envolvem classificação explícita. Ainda assim, o desempenho não é tão ruim, considerando que existem cerca de 10.000.000 de linhas envolvidas.
Embora o ponto sobre esta solução seja usar um ambiente pré-SQL Server 2012, apenas por diversão, testei seu desempenho depois de criar um índice columnstore filtrado para ver como ele se comporta com o processamento em lote habilitado:
CREATE NONCLUSTERED COLUMNSTORE INDEX idx_cs ON dbo.EventLog(logid) WHERE logid = -1 AND logid = -2;
Com o processamento em lote ativado, essa solução levou 29 segundos para ser concluída no meu sistema, produzindo o plano mostrado na Figura 4.
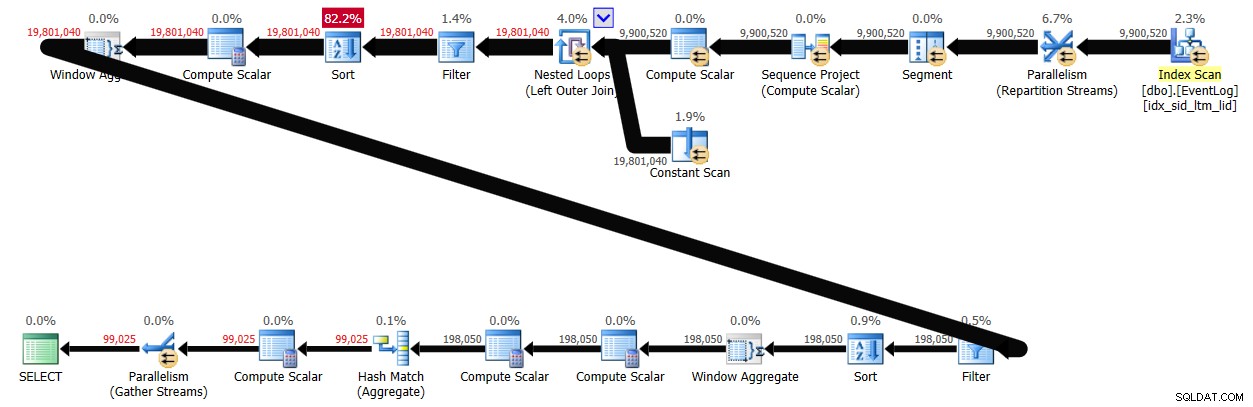
Conclusão
É natural que quanto mais limitado for o seu ambiente, mais desafiador será resolver as tarefas de consulta. O desafio especial das ilhas de Adam é muito mais fácil de resolver em versões mais recentes do SQL Server do que em versões mais antigas. Mas então você se força a usar técnicas mais criativas. Então, como exercício, para melhorar suas habilidades de consulta, você pode enfrentar desafios com os quais já está familiarizado, mas impor intencionalmente certas restrições. Você nunca sabe em quais tipos de ideias interessantes você pode tropeçar!