Este artigo é o segundo de uma série sobre limites de otimização relacionados ao agrupamento e agregação de dados. Na Parte 1, forneci a fórmula de engenharia reversa para o custo do operador do Stream Aggregate. Expliquei que esse operador precisa consumir as linhas ordenadas pelo conjunto de agrupamento (qualquer ordem de seus membros), e que quando os dados são obtidos pré-ordenados de um índice, você obtém escala linear em relação ao número de linhas e ao número de grupos. Além disso, não há nenhuma concessão de memória necessária nesse caso.
Neste artigo, concentro-me no custo e no dimensionamento de uma operação baseada em agregação de fluxo quando os dados não são obtidos pré-ordenados de um índice, em vez disso, precisam ser classificados primeiro.
Em meus exemplos, usarei o banco de dados de exemplo PerformanceV3, como na Parte 1. Você pode baixar o script que cria e preenche esse banco de dados aqui. Antes de executar os exemplos deste artigo, certifique-se de executar o código a seguir primeiro para eliminar alguns índices desnecessários:
DROP INDEX idx_nc_sid_od_cid ON dbo.Orders; DROP INDEX idx_unc_od_oid_i_cid_eid ON dbo.Orders;
Os únicos dois índices que devem ser deixados nesta tabela são
idx_cl_od (agrupado com orderdate como a chave) e PK_Orders (não agrupado com orderid como chave). Classificar + Agregar stream
O foco deste artigo é tentar descobrir como uma operação de agregação de fluxo é dimensionada quando os dados não são pré-ordenados pelo conjunto de agrupamento. Como o operador Stream Aggregate precisa processar as linhas ordenadas, se elas não forem pré-ordenadas em um índice, o plano deverá incluir um operador Sort explícito. Portanto, o custo da operação agregada que você deve levar em consideração é a soma dos custos dos operadores Sort + Stream Aggregate.
Usarei a seguinte consulta (chamaremos de Consulta 1) para demonstrar um plano envolvendo essa otimização:
SELECT shipperid, MAX(orderdate) AS maxod FROM (SELECT TOP (100) * FROM dbo.Orders) AS D GROUP BY shipperid;
O plano para esta consulta é mostrado na Figura 1.

Figura 1:plano para a consulta 1
O motivo pelo qual uso uma expressão de tabela com um filtro TOP é controlar o número exato de linhas (estimadas) envolvidas no agrupamento e agregação. A aplicação de alterações controladas facilita a tentativa de engenharia reversa das fórmulas de custeio.
Se você está se perguntando por que filtrar um número tão pequeno de linhas neste exemplo, isso tem a ver com os limites de otimização que tornam essa estratégia preferida ao algoritmo Hash Aggregate. Na Parte 3, descreverei o custo e o dimensionamento da alternativa de hash. Nos casos em que o otimizador não escolhe uma operação de agregação de fluxo por si só, por exemplo, quando um grande número de linhas está envolvido, você sempre pode forçá-lo com a dica OPTION(ORDER GROUP) durante o processo de pesquisa. Ao focar no custo de planos seriais, você obviamente pode adicionar uma dica MAXDOP 1 para eliminar o paralelismo.
Conforme mencionado, para avaliar o custo e o dimensionamento de um algoritmo agregado de fluxo não pré-ordenado, você precisa levar em consideração a soma dos operadores Sort + Stream Aggregate. Você já conhece a fórmula de custo para o operador Stream Aggregate da Parte 1:
@numrows * 0,0000006 + @numgroups * 0,0000005
Em nossa consulta, temos 100 linhas de entrada estimadas e 5 grupos de saída estimados (5 IDs de remetente distintos estimados com base nas informações de densidade). Portanto, o custo do operador Stream Aggregate em nosso plano é:
100 * 0,0000006 + 5 * 0,0000005 =0,0000625
Vamos tentar descobrir a fórmula de custeio para o operador Sort. Lembre-se, nosso foco é o custo estimado e o dimensionamento porque nosso objetivo final é descobrir os limites de otimização em que o otimizador altera suas escolhas de uma estratégia para outra.
A estimativa de custo de E/S parece ser fixa:0,0112613. Obtenho o mesmo custo de E/S independentemente de fatores como número de linhas, número de colunas de classificação, tipo de dados e assim por diante. Isso provavelmente é devido a algum trabalho de E/S antecipado.
Quanto ao custo da CPU, infelizmente, a Microsoft não expõe publicamente os algoritmos exatos que eles usam para classificação. No entanto, entre os algoritmos comuns usados para classificação por mecanismos de banco de dados em geral estão diferentes implementações de classificação por mesclagem e classificação rápida. Graças aos esforços feitos por Paul White, que gosta de olhar para os rastreamentos de pilha do depurador do Windows (nem todos temos estômago para isso), temos um pouco mais de visão sobre o tópico, publicado em sua série “Internals of the Seven SQL Server Sorteios.” De acordo com as descobertas de Paul, a classe de classificação geral (usada no plano acima) usa a classificação de mesclagem (primeiro interna, depois fazendo a transição para externa). Em média, esse algoritmo requer n log n comparações para classificar n itens. Com isso em mente, provavelmente é uma aposta segura como ponto de partida supor que a parte da CPU do custo da operadora é baseada em uma fórmula como:
Custo de CPU do operador =
É claro que isso pode ser uma simplificação excessiva da fórmula de custo real que a Microsoft usa, mas, na ausência de qualquer documentação sobre o assunto, esse é um palpite inicial.
Em seguida, você pode obter os custos de CPU de classificação de dois planos de consulta produzidos para classificar diferentes números de linhas, digamos 1.000 e 2.000, e com base neles e na fórmula acima, fazer engenharia reversa do custo de comparação e do custo de inicialização. Para isso, você não precisa usar uma consulta agrupada; basta fazer um ORDER BY básico. Usarei as duas consultas a seguir (vamos chamá-las de Consulta 2 e Consulta 3):
SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (1000) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (2000) * FROM dbo.Orders) AS D ORDER BY myorderid;
O objetivo da ordenação pelo resultado de uma computação é forçar um operador Sort a ser usado no plano.
A Figura 2 mostra as partes relevantes dos dois planos:
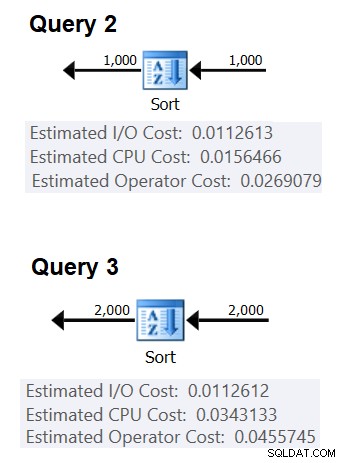
Figura 2:planos para consulta 2 e consulta 3
Para tentar inferir o custo de uma comparação, você usaria a seguinte fórmula:
custo de comparação =
((
/ (
(0,0343133 – 0,0156466) / (2000*LOG(2000) – 1000*LOG(1000)) =2,25061348918698E-06
Quanto ao custo de inicialização, você pode inferir com base em qualquer plano, por exemplo, com base no plano que classifica 2.000 linhas:
custo de inicialização =
0,0343133 – 2000*LOG(2000) * 2,25061348918698E-06 =9,99127891201865E-05
E assim nossa fórmula de custo de CPU de classificação se torna:
Custo da CPU do operador de classificação =9,99127891201865E-05 + @numrows * LOG(@numrows) * 2,25061348918698E-06
Usando técnicas semelhantes, você descobrirá que fatores como o tamanho médio da linha, o número de colunas de ordenação e seus tipos de dados não afetam o custo estimado da CPU de classificação. O único fator que parece ser relevante é o número estimado de linhas. Observe que a classificação precisará de uma concessão de memória e a concessão é proporcional ao número de linhas (não grupos) e ao tamanho médio das linhas. Mas nosso foco atualmente é o custo estimado do operador, e parece que essa estimativa é afetada apenas pelo número estimado de linhas.
Essa fórmula parece prever o custo da CPU até um limite de cerca de 5.000 linhas. Experimente com os seguintes números:100, 200, 300, 400, 500, 1000, 2000, 3000, 4000, 5000:
SELECT
numrows,
9.99127891201865E-05 + numrows * LOG(numrows) * 2.25061348918698E-06 AS predicatedcost
FROM (VALUES(100), (200), (300), (400), (500), (1000), (2000), (3000), (4000), (5000))
AS D(numrows); Compare o que a fórmula prevê e os custos estimados de CPU que os planos mostram para as seguintes consultas:
SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (100) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (200) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (300) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (400) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (500) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (1000) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (2000) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (3000) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (4000) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (5000) * FROM dbo.Orders) AS D ORDER BY myorderid;
Obtive os seguintes resultados:
numrows predicatedcost estimatedcost ratio ----------- --------------- -------------- ------- 100 0.0011363 0.0011365 1.00018 200 0.0024848 0.0024849 1.00004 300 0.0039510 0.0039511 1.00003 400 0.0054937 0.0054938 1.00002 500 0.0070933 0.0070933 1.00000 1000 0.0156466 0.0156466 1.00000 2000 0.0343133 0.0343133 1.00000 3000 0.0541576 0.0541576 1.00000 4000 0.0747667 0.0747665 1.00000 5000 0.0959445 0.0959442 1.00000
A coluna custo previsto mostra a predicação com base em nossa fórmula de engenharia reversa, a coluna custo estimado mostra o custo estimado que aparece no plano e a proporção da coluna mostra a proporção entre o último e o primeiro.
A predicação parece bastante precisa até 5.000 linhas. No entanto, com números superiores a 5.000, nossa fórmula de engenharia reversa para de funcionar bem. A consulta a seguir fornece as predicações para linhas de 6K, 7K, 10K, 20K, 100K e 200K:
SELECT
numrows,
9.99127891201865E-05 + numrows * LOG(numrows) * 2.25061348918698E-06 AS predicatedcost
FROM (VALUES(6000), (7000), (10000), (20000), (100000), (200000)) AS D(numrows); Use as seguintes consultas para obter os custos estimados de CPU dos planos (observe a dica para forçar um plano serial, pois com um número maior de linhas é mais provável que você obtenha um plano paralelo em que as fórmulas de custo sejam ajustadas para paralelismo):
SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (6000) * FROM dbo.Orders) AS D ORDER BY myorderid OPTION(MAXDOP 1); SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (7000) * FROM dbo.Orders) AS D ORDER BY myorderid OPTION(MAXDOP 1); SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (10000) * FROM dbo.Orders) AS D ORDER BY myorderid OPTION(MAXDOP 1); SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D ORDER BY myorderid OPTION(MAXDOP 1); SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (100000) * FROM dbo.Orders) AS D ORDER BY myorderid OPTION(MAXDOP 1); SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (200000) * FROM dbo.Orders) AS D ORDER BY myorderid OPTION(MAXDOP 1);
Obtive os seguintes resultados:
numrows predicatedcost estimatedcost ratio
----------- --------------- -------------- ------
6000 0.117575 0.160970 1.3691
7000 0.139583 0.244848 1.7541
10000 0.207389 0.603420 2.9096
20000 0.445878 1.311710 2.9419
100000 2.591210 7.623920 2.9422
200000 5.494330 16.165700 2.9423 Como você pode ver, além de 5.000 linhas nossa fórmula se torna cada vez menos precisa, mas curiosamente, a taxa de precisão se estabiliza em cerca de 2,94 em torno de 20.000 linhas. Isso implica que, com números grandes, nossa fórmula ainda se aplica, apenas com um custo de comparação mais alto, e que aproximadamente entre 5.000 e 20.000 linhas, ela transita gradualmente do custo de comparação mais baixo para o mais alto. Mas o que poderia explicar a diferença entre a pequena e a grande escala? A boa notícia é que a resposta não é tão complexa quanto conciliar a mecânica quântica e a relatividade geral com a teoria das cordas. É só que, em menor escala, a Microsoft queria levar em conta o fato de que o cache da CPU provavelmente será usado e, para fins de custo, eles assumem um tamanho de cache fixo.
Portanto, para descobrir o custo de comparação em grande escala, você deseja usar os custos de CPU de classificação de dois planos para números acima de 20.000. Usarei 100.000 e 200.000 linhas (duas últimas linhas na tabela acima). Aqui está a fórmula para inferir o custo de comparação:
custo de comparação =
(16,1657 – 7,62392) / (200000*LOG(200000) – 100000*LOG(100000)) =6,62193536908588E-06
Em seguida, aqui está a fórmula para inferir o custo inicial com base no plano para 200.000 linhas:
custo inicial =
16,1657 – 200000*LOG(200000) * 6,62193536908588E-06 =1,35166186417734E-04
Pode muito bem ser que o custo inicial para as pequenas e grandes escalas seja o mesmo, e que a diferença que obtivemos seja devido a erros de arredondamento. De qualquer forma, com um grande número de linhas, o custo inicial torna-se insignificante em comparação com o custo das comparações.
Em resumo, aqui está a fórmula para o custo de CPU do operador Sort para números grandes (>=20.000):
Custo da CPU do operador =1,35166186417734E-04 + @numrows * LOG(@numrows) * 6,62193536908588E-06
Vamos testar a precisão da fórmula com 500K, 1M e 10M de linhas. O código a seguir fornece as predicações da nossa fórmula:
SELECT
numrows,
1.35166186417734E-04 + numrows * LOG(numrows) * 6.62193536908588E-06 AS predicatedcost
FROM (VALUES(500000), (1000000), (10000000)) AS D(numrows); Use as seguintes consultas para obter os custos estimados de CPU:
SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (500000) * FROM dbo.Orders) AS D ORDER BY myorderid OPTION(MAXDOP 1); SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (1000000) * FROM dbo.Orders) AS D ORDER BY myorderid OPTION(MAXDOP 1); SELECT CHECKSUM(NEWID()) as myorderid FROM (SELECT TOP (10000000) O1.orderid FROM dbo.Orders AS O1 CROSS JOIN dbo.Orders AS O2) AS D ORDER BY myorderid OPTION(MAXDOP 1);
Obtive os seguintes resultados:
numrows predicatedcost estimatedcost ratio
----------- --------------- -------------- ------
500000 43.4479 43.448 1.0000
1000000 91.4856 91.486 1.0000
10000000 1067.3300 1067.340 1.0000
Parece que nossa fórmula para números grandes funciona muito bem.
Juntando tudo
O custo total da aplicação de um agregado de fluxo com classificação explícita para um pequeno número de linhas (<=5.000 linhas) é:
0,0112613
+ 9,99127891201865E-05 + @numrows * LOG(@ numrows) * 2,25061348918698E-06
+ @numrows * 0,0000006 + @numgroups * 0,0000005
A Figura 3 tem um gráfico de área mostrando como esse custo é dimensionado.
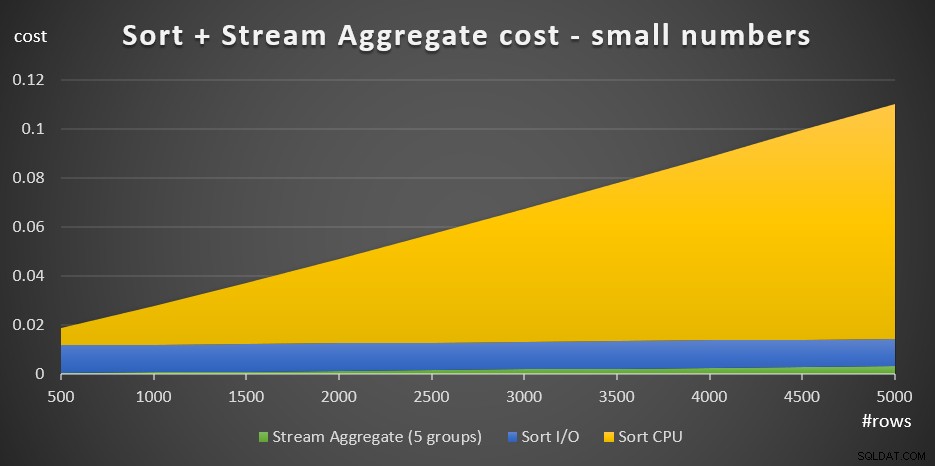
Figura 3:Custo de classificação + Agregação de fluxo para um pequeno número de linhas
O custo de CPU de classificação é a parte mais substancial do custo agregado de classificação + fluxo total. Ainda assim, com um pequeno número de linhas, o custo do Stream Aggregate e a parte de Sort I/O do custo não são totalmente desprezíveis. Em termos visuais, você pode ver claramente todas as três partes do gráfico.
Quanto a um grande número de linhas (>=20.000), a fórmula de custeio é:
0,0112613
+ 1,35166186417734E-04 + @numrows * LOG(@numrows) * 6,62193536908588E-06
+ @numrows * 0,0000006 + @numgroups * 0,0000005
Não vi muito valor em buscar a maneira exata como o custo de comparação transita da pequena para a grande escala.
A Figura 4 tem um gráfico de área mostrando como o custo é dimensionado para números grandes.
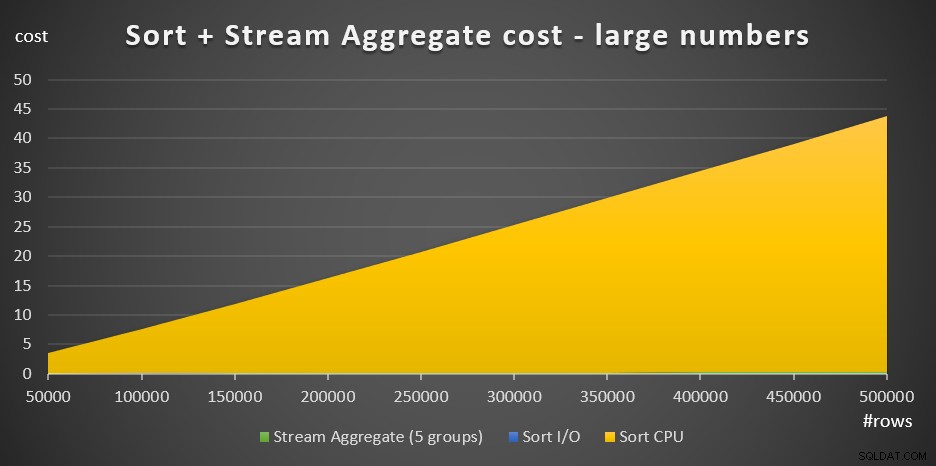
Figura 4:Custo de classificação + Agregação de fluxo para um grande número de linhas
Com um grande número de linhas, o custo Agregado de fluxo e o custo de E/S de classificação são tão insignificantes em comparação com o custo de CPU de classificação que nem são visíveis a olho nu no gráfico. Além disso, a parte do custo da CPU de classificação atribuída ao trabalho de inicialização também é insignificante. Portanto, a única parte do cálculo de custo que é realmente significativa é o custo total de comparação:
@numrows * LOG(@numrows) *
Isso significa que, quando você precisar avaliar o dimensionamento da estratégia Sort + Stream Aggregate, poderá simplificá-la apenas para essa parte dominante. Por exemplo, se você precisar avaliar como o custo seria dimensionado de 100.000 linhas para 100.000.000 linhas, você pode usar a fórmula (observe que o custo de comparação é irrelevante):
(100000000 * LOG(100000000)
Isso informa que quando o número de linhas aumenta de 100.000 por um fator de 1.000 para 100.000.000, o custo estimado aumenta por um fator de 1.600.
A escala de 1.000.000 a 1.000.000.000 de linhas é calculada como:
(1000000000 * LOG(1000000000)) / (1000000 * LOG(1000000)) =1500
Ou seja, quando o número de linhas aumenta de 1.000.000 por um fator de 1.000, o custo estimado aumenta por um fator de 1.500.
Essas são observações interessantes sobre a forma como a estratégia Sort + Stream Aggregate é dimensionada. Devido ao seu custo inicial muito baixo e ao dimensionamento linear extra, você esperaria que essa estratégia funcionasse bem com números muito pequenos de linhas, mas não tão bem com números grandes. Além disso, o fato de que o operador Stream Aggregate sozinho representa uma fração tão pequena do custo em comparação com quando uma classificação também é necessária, informa que você pode obter um desempenho significativamente melhor se a situação for tal que você possa criar um índice de suporte .
Na próxima parte da série, abordarei o dimensionamento do algoritmo Hash Aggregate. Se você gosta deste exercício de tentar descobrir fórmulas de custeio, veja se consegue descobrir para este algoritmo. O importante é descobrir os fatores que o afetam, a maneira como ele é dimensionado e as condições em que ele se sai melhor do que os outros algoritmos.