Observação:Este artigo mostra a migração de um modelo de banco de dados relacional (RDB) para esquema em estrela usando o Eclipse IDE para Voracity (e seus produtos incluídos), IRI Workbench, seguindo uma introdução a ambas as arquiteturas. Se você estiver interessado em migrar seu RDB ou dados para um modelo do Data Vault 2.0, um novo assistente do Workbench será lançado no World Wide Data Vault Consortium em maio de 2019; assine o blog do IRI para obter as instruções passo a passo assim que elas forem publicadas!
Um data warehouse (DW) é uma coleção de dados extraídos do sistema operacional ou transacional em uma empresa, transformados para eliminar inconsistências e organizados para oferecer suporte a análises e/ou relatórios rápidos. O DW requer um esquema ou uma descrição lógica e representação gráfica de seu banco de dados operacional. Este artigo aborda esses tópicos e fornece um guia de como mudar de um esquema de banco de dados relacional convencional para um esquema DW popular chamado esquema em estrela.
Esquema em estrela vs. Relacional
A maioria das estruturas de dados relacionais é ilustrada em diagramas entidade-relacionamento (ER). Um diagrama ER é usado no desenvolvimento de modelos conceituais para um sistema de gerenciamento de banco de dados de processamento de transações online (OLTP). É a fonte da qual a estrutura da tabela é traduzida.
O esquema em estrela, no entanto, é o padrão amplamente aceito para a estrutura de tabela subjacente de um data warehouse. Sua forma de estrela simples (quando diagramado em ER) mostra a tabela de fatos (contendo valores de transação ou medidas) no centro e as tabelas de dimensão (contendo valores descritivos ou atributivos) irradiando dela. Normalmente, a tabela de fatos está na terceira forma normal (3NF), enquanto as tabelas dimensionais são desnormalizadas.
As diferenças básicas entre um modelo entidade-relacional (ER) e um modelo em estrela são:
- Modelos ER usam estruturas lógicas e físicas para design de banco de dados normalizado
- Os modelos de dimensão usam uma estrutura física para design de banco de dados desnormalizado
Para ver como o software IRI pode des/normalizar dados por meio da articulação de linha-coluna, clique aqui.
Antecedentes do processo de conversão
Neste artigo, demonstro como converter dados de um modelo relacional em estrela usando tarefas que você deve definir mais ou menos manualmente, mas pode criar e executar automaticamente e modificar facilmente.
O que você verá aqui são os dados 4GL e as especificações de trabalho da IRI - expressos em scripts "SortCL"[1] - que mapeiam dados em tabelas de dimensão e unem dados na tabela de fatos central. SortCL é o programa principal de manipulação e mapeamento de dados na plataforma de gerenciamento de dados e ETL do IRI Voracity. No entanto, entender a metodologia e os mapeamentos em meus trabalhos SortCL é a chave aqui, não a sintaxe de script.
A GU do Eclipse gratuita, IRI Workbench, fornece um editor SortCL com reconhecimento de sintaxe, bem como contornos gráficos e diálogos, diagramas de fluxo de trabalho e mapeamento e assistentes de trabalho intuitivos, para criar ou modificar automaticamente esses scripts se você não quiser fazer isso à mão. Para sua informação, o IRI usa os mesmos metadados e GUI para criar perfis e diagramar bancos de dados, gerar dados de teste, executar ETL, formatar relatórios, mascarar PII, capturar dados alterados, migrar e replicar dados, limpar e validar dados etc.
O Workbench usa uma versão aprimorada do plug-in Data Tools Platform (DTP) para Eclipse para conectar-se a bancos de dados sobre JDBC e ativar operações SQL e troca de metadados IRI na visualização Data Source Explorer (DSE). Nesse caso, o Workbench é compatível com:
- a criação e o preenchimento de tabelas de teste Oracle restritas (origem) por meio de SortCL (ou jobs IRI RowGen de acordo com este artigo)
- o mapeamento de dados da tabela de entidade em tabelas de dimensão via SortCL
- o mapeamento de elementos fato como uma relação n-ária para associar a tabela de dimensão principal; ou seja, realizando uma junção de várias tabelas em SortCL para criar a tabela de fatos
- população de todas as tabelas de destino (esquema em estrela)
- Diagramas ER dos esquemas de origem e destino
Os tipos de entidade no meu modelo relacional original são:Dept, Emp, Project, Category, Item, Item_Use e Sale:
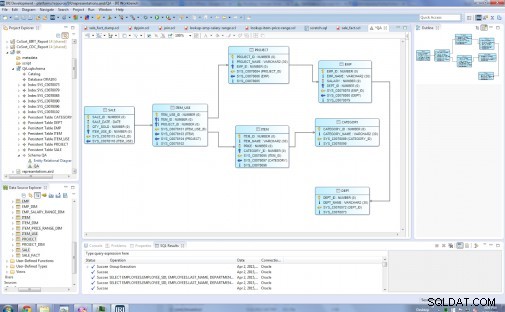
Antes…
O próximo diagrama mostra o modelo Star final com oito tabelas de dimensões e uma tabela de fatos. As tabelas de dimensão são: Dept_Dim, Emp_Dim, Emp_Salary_Range_Dim, Project_Dim, Category_Dim, Item_Price_Range_Dim, Item_Dim. A tabela de fatos no centro é Sale_Fact, que contém chaves para todas as tabelas de dimensão.

… Depois
Etapas de conversão
- Definir e criar a tabela de fatos
A estrutura da tabela Sale_Fact é mostrada neste documento. A chave primária é sale_id e o restante dos atributos são chaves estrangeiras herdadas das tabelas Dimension. Estou usando um banco de dados Oracle (embora qualquer RDB funcione) conectado ao Workbench DSE (via JDBC) e SortCL para transformação e mapeamento de dados ( via ODBC). Criei minhas tabelas em scripts SQL editados no scrapbook SQL do DSE e executados no Workbench.
- Definir e criar as tabelas de dimensão
Use a mesma técnica e metadados vinculados acima para criar essas tabelas de dimensão que receberão os dados relacionais mapeados dos jobs SortCL na próxima etapa:tabela Category_Dim, Dept para Dept_Dim, Project para Project_Dim, Item para Item_Dim e Emp para Emp_Dim. Você pode executar esse programa .SQL com toda a lógica CREATE de uma vez para construir as tabelas.
- Mova os dados originais da tabela Entity para as tabelas Dimension
Defina e execute os jobs SortCL mostrados aqui para mapear os dados (teste criado por RowGen) do esquema relacional em tabelas de dimensão para o esquema Star. Especificamente, esses scripts carregam dados da tabela Category para a tabela Category_Dim, Dept para Dept_Dim, Project para Project_Dim, Item para Item_Dim e Emp para Emp_Dim.
- Preencher a tabela de fatos
Use SortCL para unir dados das tabelas de entidades originais Sale, Emp, Project, Item_Use, Item, Category para preparar dados para a nova tabela Sale_Fact . Use o segundo script (join job) aqui.
Para aprimorar nosso exemplo, também usaremos SortCL para introduzir novos dados dimensionais no esquema Star, no qual minha tabela Fact também dependerá. Você pode ver essas tabelas adicionais no diagrama em estrela acima que não estavam no meu esquema relacional:Emp_Salary_Range_Dim e Item_Price_Range_Dim. Essas tabelas são criadas no mesmo arquivo .SQL para as tabelas Fact e outras dimensões.
A tabela de fatos precisa dos dados emp_salary_range_id e item_price_range_id dessas tabelas para representar o intervalo de valores nessas tabelas de dimensão. Quando carrego os valores de preço dimensional no data warehouse, por exemplo, quero atribuí-los a uma faixa de preço:
| Item_Price | Range_Id | Range_Name | Intervalo_Fim |
|---|---|---|---|
| 1 | Baixo | 1 | 100 |
| 2 | Meio | 101 | 500 |
| 3 | Alto | 501 | 999 |
A maneira mais simples de atribuir IDs de intervalo no script de trabalho (que está preparando dados para minha tabela Sale_Fact) é usar uma instrução IF-THEN-ELSE na seção de saída. Consulte este artigo sobre valores de bucket para obter informações básicas.
De qualquer forma, criei este job inteiro com o CoSort New Join Job assistente no Workbench. E uma vez que eu executei, minha tabela de fatos foi preenchida:
 Exibição da tabela Sale_Fact no IRI Workbench DSE
Exibição da tabela Sale_Fact no IRI Workbench DSE Conclusão
A principal vantagem da representação dimensional de dados é reduzir a complexidade de uma estrutura de banco de dados. Isso torna o banco de dados mais fácil para as pessoas entenderem e escreverem consultas, minimizando o número de tabelas e, portanto, o número de junções necessárias. Conforme mencionado anteriormente, os modelos dimensionais também otimizam o desempenho da consulta. No entanto, tem fraqueza, bem como força. A estrutura fixa do Star Schema limita as consultas. Assim, como facilita a escrita das consultas mais comuns, também restringe a forma como os dados podem ser analisados.
A GUI do IRI Workbench para Voracity tem um conjunto poderoso e abrangente de ferramentas que simplificam a integração de dados, incluindo a criação, manutenção e expansão de data warehouses. Com essa interface intuitiva e fácil de usar, o Voracity facilita a criação de processos ETL (extrair, transformar, carregar) rápido, flexível e completo, envolvendo estruturas de dados em diferentes plataformas.
Nas operações de ETL, os dados são extraídos de diferentes fontes, transformados separadamente e carregados em um data warehouse e possivelmente em outros destinos. Construir o processo ETL é, potencialmente, uma das maiores tarefas da construção de um armazém; é complexo e demorado. A abordagem de ETL da IRI oferece suporte a esse processo de maneira altamente eficiente e independente do banco de dados, realizando toda a integração e preparação de dados no sistema de arquivos.
[1] Se você gosta de sintaxe, observe que os scripts SortCL usados no produto IRI CoSort ou na plataforma IRI Voracity são compatíveis com a mesma sintaxe e definições de dados que o IRI RowGen para geração de dados de teste, IRI NextForm para migração de dados e IRI FieldShield para mascaramento de dados. Todas essas ferramentas são compatíveis com a GUI do IRI Workbench, e seus metadados também podem ser compartilhados e gerenciados por equipe para controle de versão, linhagem de trabalho/dados e segurança na nuvem.
[2] Para exibir diagramas E-R no IRI Workbench:
- Selecione Novo projeto IRI e crie uma nova pasta
- Selecione essa pasta e destaque todas as tabelas de banco de dados aplicáveis no Data Source Explorer; em seguida, clique com o botão direito em IRI, New ER-Diagram
- Um arquivo (Schema.QA) será criado
- Clique com o botão direito do mouse nesse arquivo e selecione Nova representação, novo diagrama de relação de entidade.
[3] Os elementos do diagrama ER que ilustram esses modelos incluem:
- tipos de entidade definidos
- atributos definidos
- o relacionamento entre os tipos de entidade
- imagem geral ou diagrama conceitual
[4] IRI FACT e SQL*Loader são opções de extração e carregamento em massa, respectivamente.