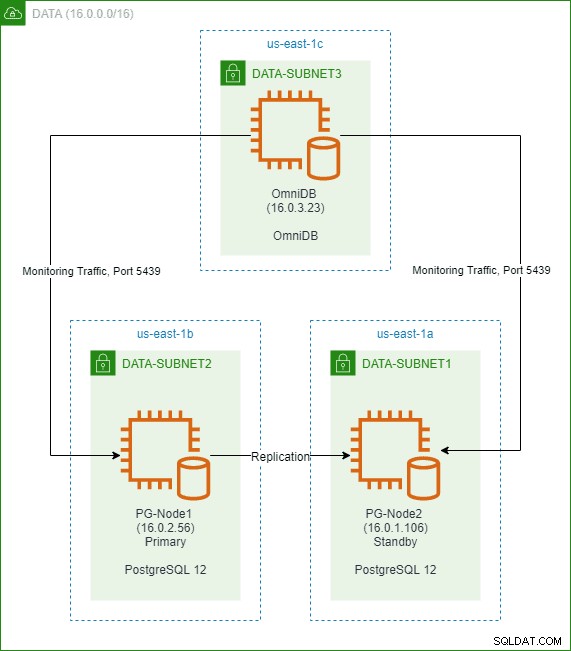
Em um artigo anterior desta série, criamos um cluster PostgreSQL 12 de dois nós na nuvem AWS. Também instalamos e configuramos o 2ndQuadrant OmniDB em um terceiro nó. A imagem abaixo mostra a arquitetura:
Poderíamos nos conectar ao nó principal e ao nó de espera da interface de usuário baseada na web do OmniDB. Em seguida, restauramos um banco de dados de amostra chamado “dvdrental” no nó primário que começou a replicar para o standby.
Nesta parte da série, aprenderemos como criar e usar um painel de monitoramento no OmniDB. DBAs e equipes de operação geralmente preferem ferramentas gráficas em vez de consultas complexas para inspecionar visualmente a integridade do banco de dados. O OmniDB vem com vários widgets importantes que podem ser facilmente usados em um painel de monitoramento. Como veremos mais adiante, ele também permite que os usuários escrevam seus próprios widgets de monitoramento.
Criando um painel de monitoramento de desempenho
Vamos começar com o painel padrão que o OmniDB vem.
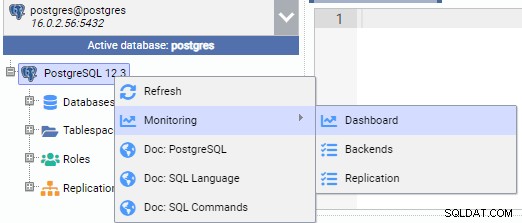
Na imagem abaixo, estamos conectados ao nó primário (PG-Node1). Clicamos com o botão direito do mouse no nome da instância e, no menu pop-up, escolhemos “Monitor” e, em seguida, selecionamos “Dashboard”.
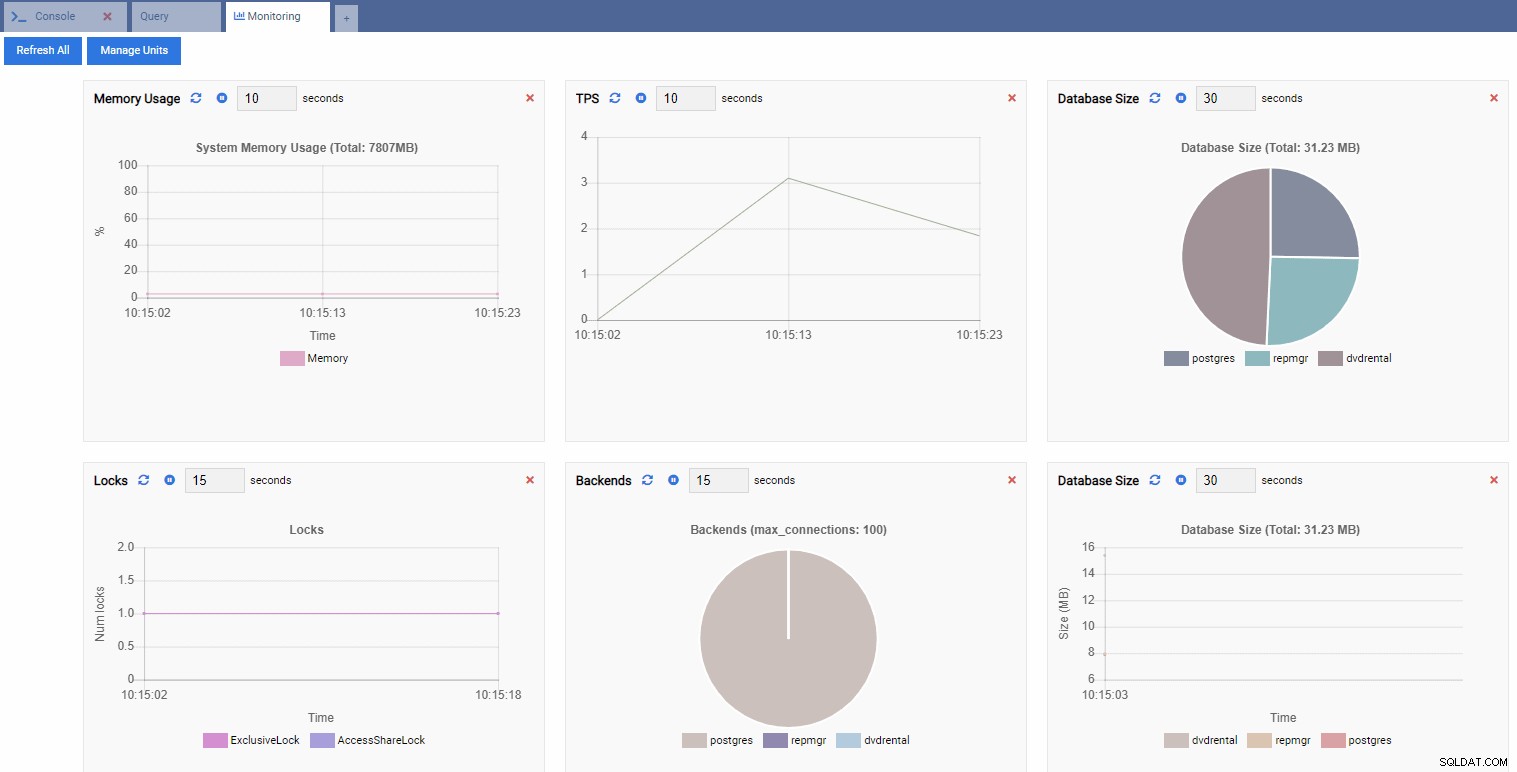
Isso abre um painel com alguns widgets.
Em termos do OmniDB, os widgets retangulares no painel são chamados de Monitoring Units . Cada uma dessas unidades mostra uma métrica específica da instância do PostgreSQL à qual está conectada e atualiza seus dados dinamicamente.
Compreendendo as Unidades de Monitoramento
OmniDB vem com quatro tipos de Unidades de Monitoramento:
- Uma grade é uma estrutura tabular que mostra o resultado de uma consulta. Por exemplo, esta pode ser a saída de SELECT * FROM pg_stat_replication. Uma grade se parece com isso:
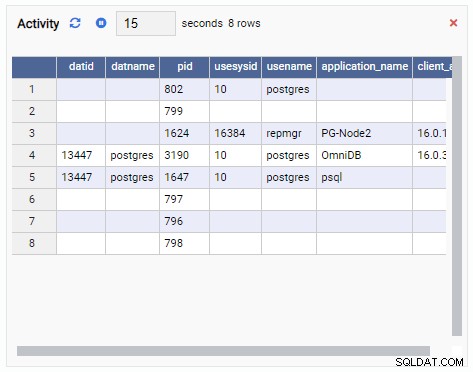
- Um Gráfico mostra os dados em formato gráfico, como linhas ou gráficos de pizza. Quando ele é atualizado, todo o gráfico é redesenhado na tela com um novo valor e o valor antigo desaparece. Com essas Unidades de Monitoramento, podemos ver apenas o valor atual da métrica. Aqui está um exemplo de um gráfico:
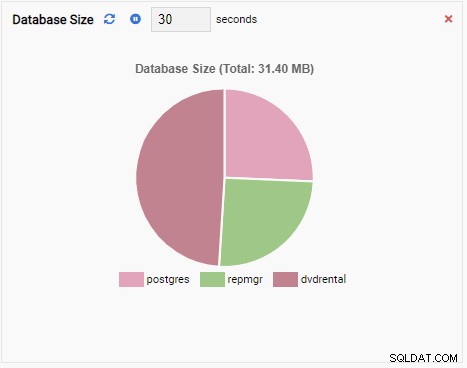
- Um Anexo de gráfico também é uma Unidade de Monitoramento do tipo Gráfico, exceto quando é atualizada, acrescenta o novo valor à série existente. Com Chart-Append, podemos ver facilmente as tendências ao longo do tempo. Aqui está um exemplo:
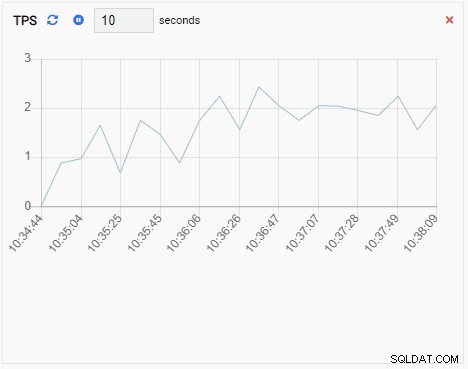
- Um Gráfico mostra os relacionamentos entre instâncias de cluster do PostgreSQL e uma métrica associada. Como a Unidade de Monitoramento de Gráfico, uma Unidade de Monitoramento de Gráfico também atualiza seu valor antigo com um novo. A imagem abaixo mostra que o nó atual (PG-Node1) está replicando para o PG-Node2:
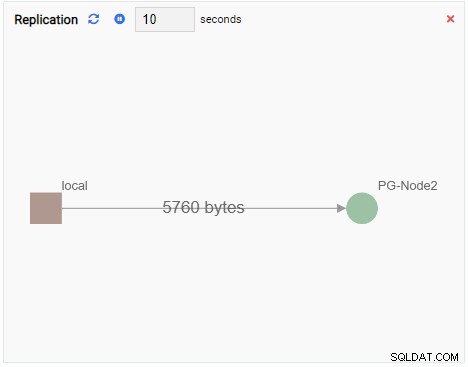
Cada Unidade de Monitoramento tem vários elementos comuns:
- O nome da unidade de monitoramento
- Um botão "atualizar" para atualizar manualmente a unidade
- Um botão de "pausa" para interromper temporariamente a atualização da unidade de monitoramento
- Uma caixa de texto mostrando o intervalo de atualização atual. Isso pode ser alterado
- Um botão "fechar" (marca de cruz vermelha) para remover a unidade de monitoramento do painel
- A área de desenho real do Monitoramento
Unidades de monitoramento pré-construídas
O OmniDB vem com várias Unidades de Monitoramento para PostgreSQL que podemos adicionar ao nosso painel. Para acessar essas unidades, clicamos no botão “Gerenciar Unidades” na parte superior do painel:
Isso abre a lista "Gerenciar unidades":
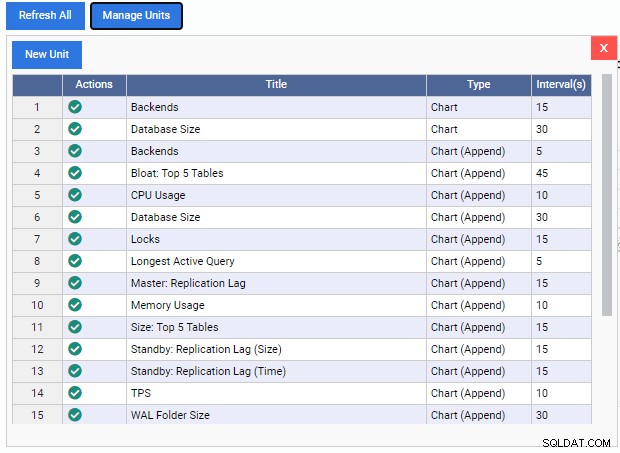
Como podemos ver, existem poucas Unidades de Monitoramento pré-construídas aqui. Os códigos para essas unidades de monitoramento podem ser baixados gratuitamente no repositório GitHub do 2ndQuadrant. Cada unidade listada aqui mostra seu nome, tipo (Gráfico, Anexo de Gráfico, Gráfico ou Grade) e a taxa de atualização padrão.
Para adicionar uma Unidade de Monitoramento ao painel, basta clicar na marca verde na coluna “Ações” dessa unidade. Podemos misturar e combinar diferentes Unidades de Monitoramento para construir o painel que queremos.
Na imagem abaixo, adicionamos as seguintes unidades ao nosso painel de monitoramento de desempenho e removemos todo o resto:
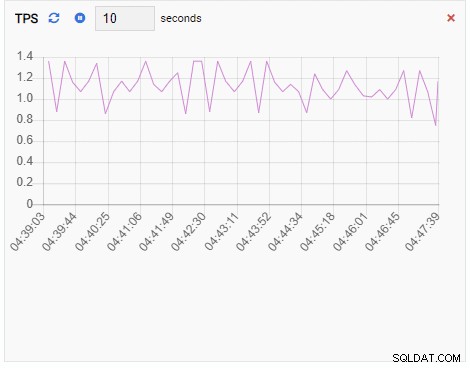
TPS (transação por segundo):
Número de bloqueios:
Número de back-ends:
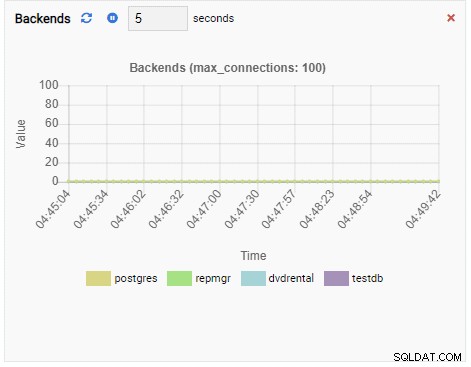
Como nossa instância está ociosa, podemos ver que os valores de TPS, Locks e Backends são mínimos.
Teste do painel de monitoramento
Agora executaremos o pgbench em nosso nó primário (PG-Node1). O pgbench é uma ferramenta de benchmarking simples que acompanha o PostgreSQL. Como a maioria das outras ferramentas desse tipo, o pgbench cria um esquema e tabelas de exemplo de sistemas OLTP em um banco de dados quando inicializado. Depois disso, ele pode emular várias conexões de clientes, cada uma executando várias transações no banco de dados. Nesse caso, não faremos benchmarking do nó primário do PostgreSQL; vamos apenas criar o banco de dados para o pgbench e ver se nossas Unidades de Monitoramento do painel captam a mudança na integridade do sistema.
Primeiro, estamos criando um banco de dados para pgbench no nó primário:
[example@sqldat.com ~]$ psql -h PG-Node1 -U postgres -c "CREATE DATABASE testdb";CREATE DATABASE
Em seguida, estamos inicializando o banco de dados “testdb” para o pgbench:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/pgbench -h PG-Node1 -p 5432 -I dtgvp -i -s 20 testdbsoltando tabelas antigas...criando tabelas...gerando dados... 100.000 de 2.000.000 tuplas (5%) feito (decorrido 0,02 s, restante 0,43 s) 200.000 de 2.000.000 tuplas (10%) feito (decorrido 0,05 s, restante 0,41 s)……2000000 de 2000.000 tuplas (100%) concluído (decorrido 1,84 s, restante 0,00 s) aspirando... criando chaves primárias... concluído.
Com o banco de dados inicializado, agora iniciamos o processo de carregamento real. No trecho de código abaixo, pedimos ao pgbench para iniciar com 50 conexões de cliente simultâneas no banco de dados testdb, cada conexão executando 100.000 transações em suas tabelas. O teste de carga será executado em dois threads.
[example@sqldat.com ~]$ /usr/pgsql-12/bin/pgbench -h PG-Node1 -p 5432 -c 50 -j 2 -t 100000 testdbiniciando vácuo...fim.……
Se agora voltarmos ao nosso painel OmniDB, veremos que as Unidades de Monitoramento estão mostrando alguns resultados muito diferentes.
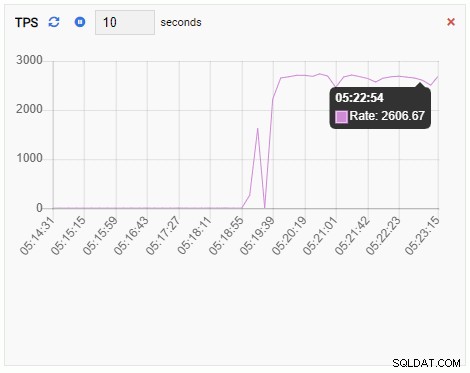
A métrica TPS está mostrando um valor bastante alto. Há um salto repentino de menos de 2 para mais de 2000:
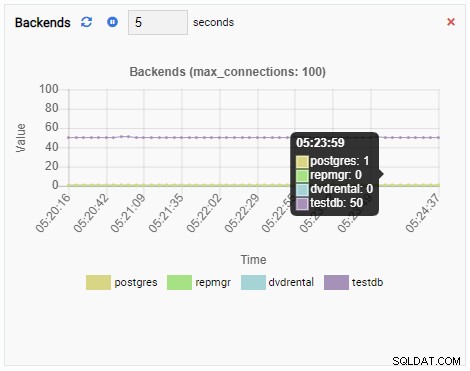
O número de back-ends aumentou. Como esperado, testdb tem 50 conexões enquanto outros bancos de dados estão inativos:
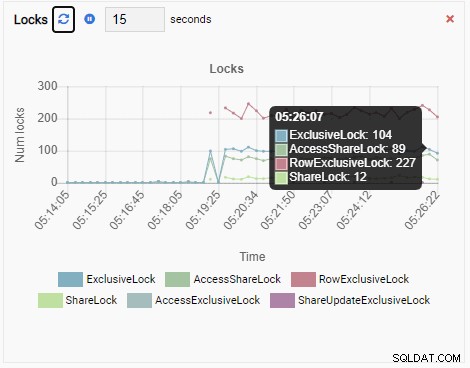
E, finalmente, o número de bloqueios exclusivos de linha no banco de dados testdb também é alto:
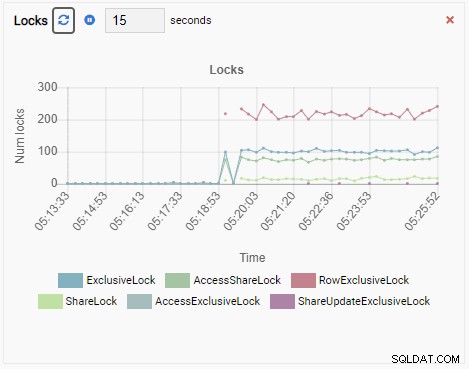
Agora imagine isso. Você é um DBA e usa o OmniDB para gerenciar uma frota de instâncias do PostgreSQL. Você recebe uma chamada para investigar o desempenho lento em uma das instâncias.
Usando um painel como o que acabamos de ver (embora seja muito simples), você pode encontrar facilmente a causa raiz. Você pode verificar o número de back-ends, bloqueios, memória disponível etc. para ver o que está causando o problema.
E é aí que o OmniDB pode ser uma ferramenta realmente útil.
Criando unidades de monitoramento personalizadas
Às vezes precisaremos criar nossas próprias Unidades de Monitoramento. Para escrever uma nova Unidade de Monitoramento, clicamos no botão “Nova Unidade” na lista “Gerenciar Unidades”. Isso abre uma nova guia com uma tela vazia para escrever código:
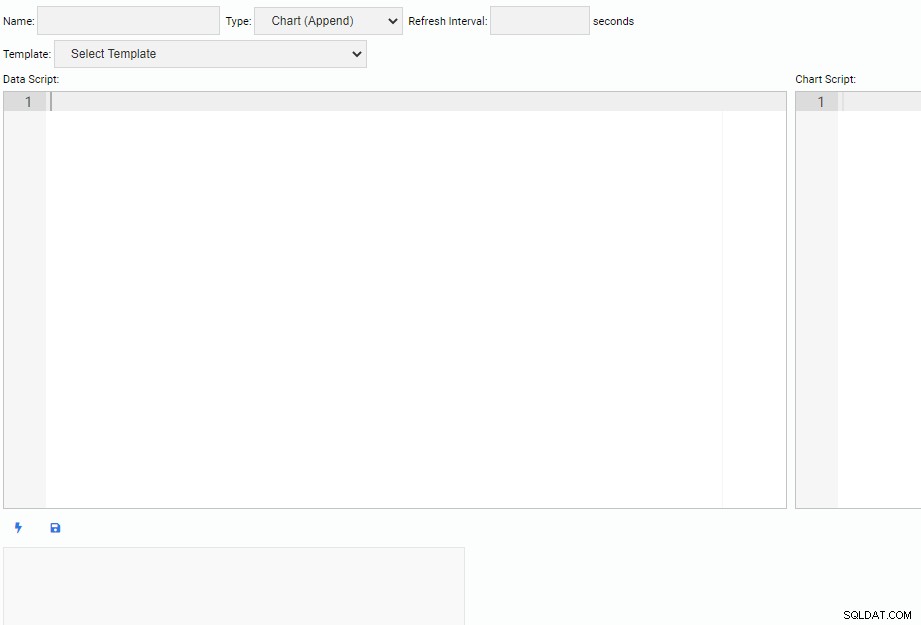
Na parte superior da tela, temos que especificar um nome para nossa Unidade de Monitoramento, selecionar seu tipo e especificar seu intervalo de atualização padrão. Também podemos selecionar uma unidade existente como modelo.
Na seção de cabeçalho, há duas caixas de texto. O editor “Data Script” é onde escrevemos o código para obter dados para nossa Unidade de Monitoramento. Toda vez que uma unidade é atualizada, o código do script de dados será executado. O editor “Chart Script” é onde escrevemos o código para desenhar a unidade real. Isso é executado quando a unidade é desenhada pela primeira vez.
Todo o código de script de dados é escrito em Python. Para a Unidade de Monitoramento do tipo Gráfico, o OmniDB precisa que o script do gráfico seja escrito em Chart.js.
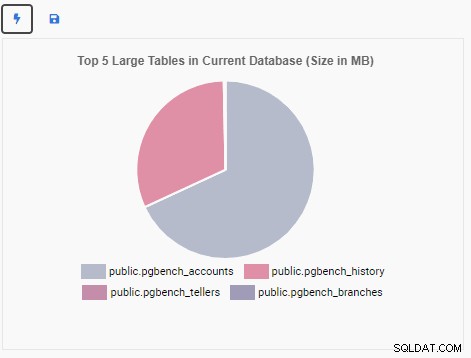
Vamos agora criar uma Unidade de Monitoramento para mostrar as 5 principais tabelas grandes no banco de dados atual. Com base no banco de dados selecionado no OmniDB, a Unidade de Monitoramento alterará sua exibição para refletir os nomes das cinco maiores tabelas desse banco de dados.
Para escrever uma nova Unidade, é melhor começar com um modelo existente e modificar seu código. Isso economizará tempo e esforço. Na imagem a seguir, nomeamos nossa Unidade de Monitoramento como “Top 5 Large Tables”. Escolhemos ser do tipo Gráfico (Sem acréscimo) e fornecemos uma taxa de atualização de 30 segundos. Também baseamos nossa Unidade de Monitoramento no modelo Tamanho do Banco de Dados:
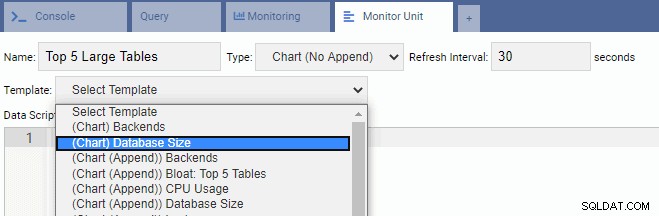
A caixa de texto Data Script é preenchida automaticamente com o código da Database Size Monitoring Unit:
from datetime import datetimefrom random import randintdatabases =connection.Query(''' SELECT d.datname AS datname, round(pg_catalog.pg_database_size(d.datname)/1048576.0,2) AS size FROM pg_catalog.pg_database d WHERE d. datname não está em ('template0','template1')''')data =[]color =[]label =[]for db in databases.Rows: data.append(db["size"]) color.append( "rgb(" + str(randint(125, 225)) + "," + str(randint(125, 225)) + "," + str(randint(125, 225)) + ")") label.append (db["datname"])total_size =connection.ExecuteScalar(''' SELECT round(sum(pg_catalog.pg_database_size(datname)/1048576.0),2) FROM pg_catalog.pg_database WHERE NOT datistemplate''')result ={ "labels ":label, "datasets":[ { "data":data, "backgroundColor":color, "label":"Dataset 1" } ], "title":"Database Size (Total:" + str(total_size)) " MB)"}
E a caixa de texto Chart Script também é preenchida com código:
total_size =connection.ExecuteScalar(''' SELECT round(sum(pg_catalog.pg_database_size(datname)/1048576.0),2) FROM pg_catalog.pg_database WHERE NOT datistemplate''')result ={ "type":"pie" , "data":Nenhum, "options":{ "responsive":True, "title":{ "display":True, "text":"Tamanho do banco de dados (Total:" + str(total_size) + " MB)" } }}
Podemos modificar o Data Script para obter as 5 principais tabelas grandes do banco de dados. No script abaixo, mantivemos a maior parte do código original, exceto a instrução SQL:
from datetime import datetimefrom random import randinttables =connection.Query('''SELECT nspname || '.' || relname AS "tablename", round(pg_catalog.pg_total_relation_size(c.oid)/1048576.0,2) AS " table_size" FROM pg_class C LEFT JOIN pg_namespace N ON (N.oid =C.relnamespace) WHERE nspname NOT IN ('pg_catalog', 'information_schema') AND C.relkind <> 'i' AND nspname !~ '^pg_toast' ORDER BY 2 DESC LIMIT 5;''')data =[]color =[]label =[]for table in tables.Rows: data.append(table["table_size"]) color.append("rgb(" + str (randint(125, 225)) + "," + str(randint(125, 225)) + "," + str(randint(125, 225)) + ")") label.append(table["tablename" ])result ={ "labels":label, "datasets":[ { "data":data, "backgroundColor":color, "label":"Top 5 Large Tables" } ]}
Aqui, estamos obtendo o tamanho combinado de cada tabela e seus índices no banco de dados atual. Estamos classificando os resultados em ordem decrescente e selecionando as cinco primeiras linhas.
Em seguida, estamos preenchendo três arrays Python iterando sobre o conjunto de resultados.
Por fim, estamos construindo uma string JSON com base nos valores dos arrays.
Na caixa de texto Chart Script, modificamos o código para remover o comando SQL original. Aqui, estamos especificando apenas o aspecto cosmético do gráfico. Estamos definindo o gráfico como tipo de pizza e fornecendo um título para ele:
resultado ={ "type":"pie", "data":None, "options":{ "responsive":True, "title":{ "display":True, "text":"Top 5 Large Tabelas no banco de dados atual (tamanho em MB)" } }}
Agora podemos testar a unidade clicando no ícone de relâmpago. Isso mostrará a nova Unidade de Monitoramento na área de desenho de visualização:
Em seguida, salvamos a unidade clicando no ícone do disco. Uma caixa de mensagem confirma que a unidade foi salva:

Agora voltamos ao nosso painel de monitoramento e adicionamos a nova Unidade de Monitoramento:
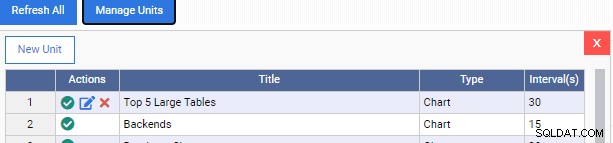
Observe como temos mais dois ícones na coluna "Ações" para nossa unidade de monitoramento personalizada. Um é para editá-lo, o outro é para removê-lo do OmniDB.
A unidade de monitoramento “Top 5 Large Tables” agora exibe as cinco maiores tabelas no banco de dados atual:
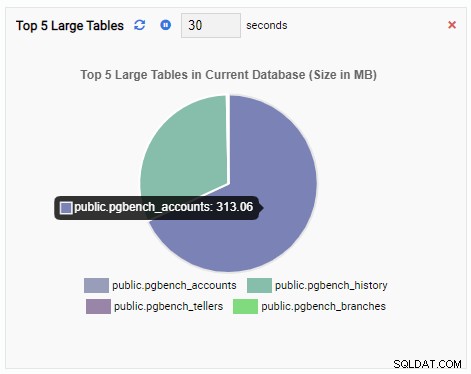
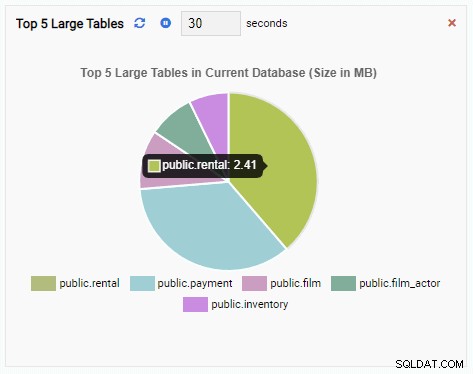
Se fecharmos o painel, mudarmos para outro banco de dados no painel de navegação e abrirmos o painel novamente, veremos que a Unidade de Monitoramento foi alterada para refletir as tabelas desse banco de dados:
Palavras Finais
Isso conclui nossa série de duas partes sobre OmniDB. Como vimos, o OmniDB tem algumas unidades de monitoramento bacanas que os DBAs do PostgreSQL acharão úteis para o rastreamento de desempenho. Vimos como podemos usar essas unidades para identificar possíveis gargalos no servidor. Também vimos como criar nossas próprias unidades personalizadas. Os leitores são incentivados a criar e testar unidades de monitoramento de desempenho para suas cargas de trabalho específicas. O 2ndQuadrant agradece qualquer contribuição para o repositório GitHub da OmniDB Monitoring Unit.