Há poucos dias foi lançado uma nova versão do ClusterControl, a 1.7.2, onde podemos ver várias novidades, uma das principais é o suporte para TimescaleDB.
TimescaleDB é um banco de dados de séries temporais de código aberto otimizado para ingestão rápida e consultas complexas que suportam SQL completo. É baseado no PostgreSQL e oferece o melhor dos mundos NoSQL e Relacional para dados de séries temporais. O TimescaleDB oferece suporte à replicação de streaming como o principal método de replicação, que pode ser usado em uma configuração de alta disponibilidade. No entanto, o PostgreSQL não vem com failover automático e isso é um problema em um ambiente de produção de alta disponibilidade. O failover manual geralmente implica que um humano é chamado e precisa encontrar um computador, fazer login nos sistemas, entender o que está acontecendo, antes de iniciar os procedimentos de failover. Isso se traduz em um longo período de inatividade. Felizmente, existe uma maneira de automatizar failovers com ClusterControl, que agora oferece suporte a TimescaleDB.
Neste blog, veremos como implantar uma configuração replicada do TimescaleDB com failover automático em apenas alguns cliques usando o ClusterControl. Também veremos como adicionar um único endpoint de banco de dados para aplicativos via HAProxy. Como pré-requisito, você deve instalar a versão 1.7.2 do ClusterControl em um host ou VM dedicado.
Implantar TimescaleDB
Para realizar uma nova instalação do TimescaleDB a partir do ClusterControl, basta selecionar a opção “Deploy” e seguir as instruções que aparecem. Observe que, se você já tiver uma instância do TimescaleDB em execução, precisará selecionar 'Import Existing Server/Database'.
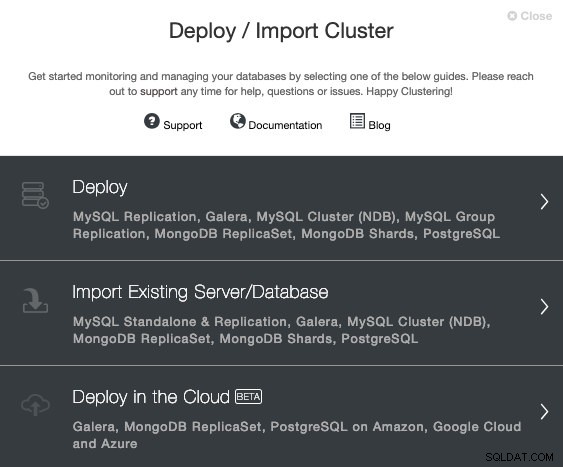
Ao selecionar TimescaleDB, devemos especificar Usuário, Chave ou Senha e porta para conectar por SSH aos nossos hosts TimescaleDB. Também precisamos de um nome para nosso novo cluster e se queremos que o ClusterControl instale o software e as configurações correspondentes para nós.
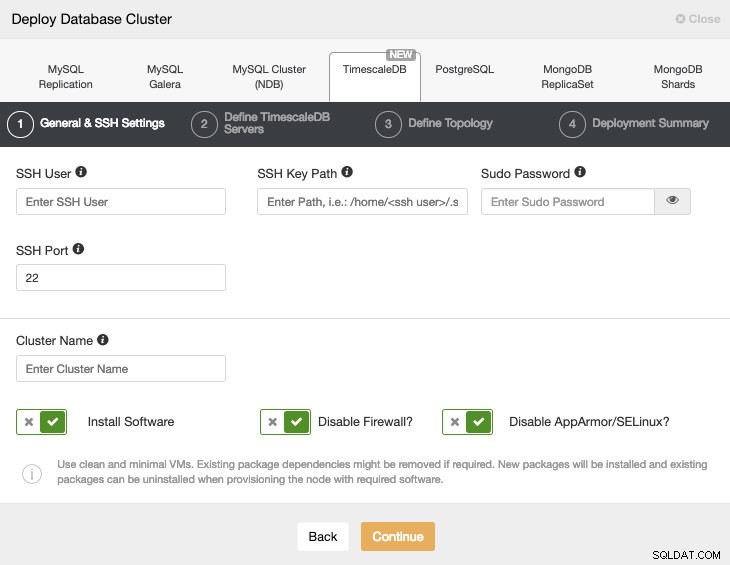
Verifique aqui o requisito de usuário do ClusterControl para esta tarefa.
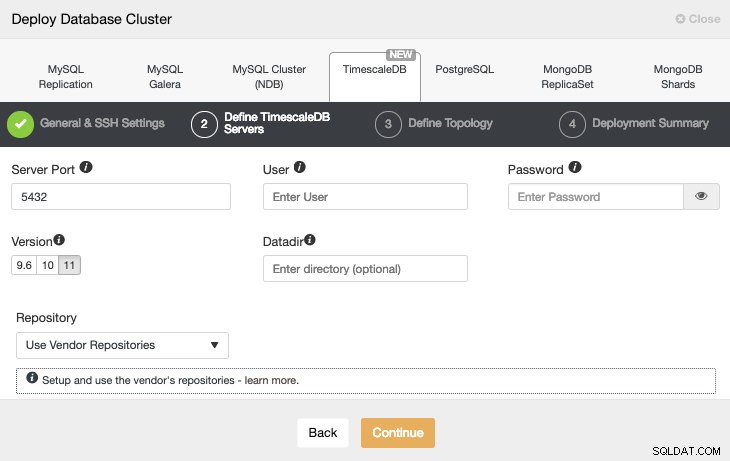
Após configurar as informações de acesso SSH, devemos definir o usuário do banco de dados, versão e datadir (opcional). Também podemos especificar qual repositório usar.
Na próxima etapa, precisamos adicionar nossos servidores ao cluster que vamos criar.
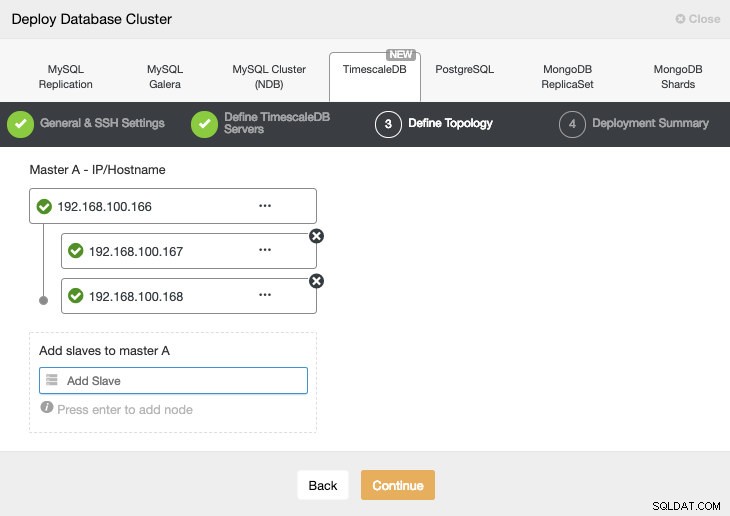
Ao adicionar nossos servidores, podemos inserir o IP ou o nome do host.
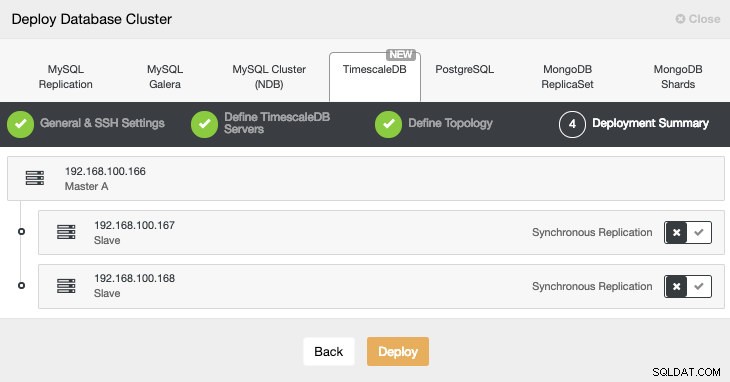
Na última etapa, podemos escolher se nossa replicação será síncrona ou assíncrona.
Podemos monitorar o status da criação do nosso novo cluster a partir do monitor de atividades do ClusterControl.
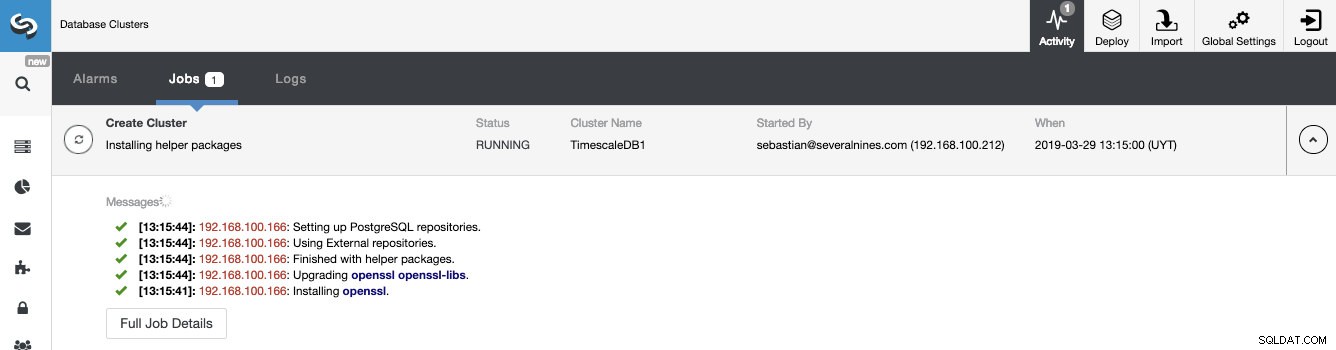
Quando a tarefa estiver concluída, podemos ver nosso novo cluster TimescaleDB na tela principal do ClusterControl.

Depois de criar nosso cluster, podemos realizar várias tarefas nele, como adicionar um balanceador de carga (HAProxy) ou uma nova réplica.
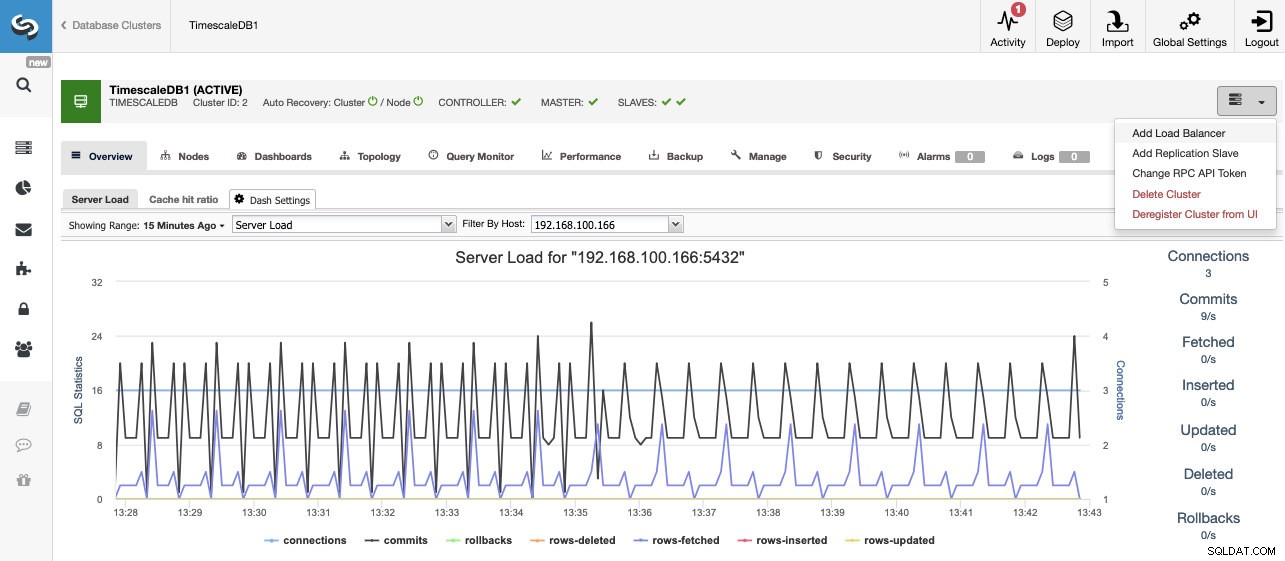
Escalonamento do TimescaleDB
Se formos para ações de cluster e selecionarmos “Add Replication Slave”, podemos criar uma nova réplica do zero ou adicionar um banco de dados TimescaleDB existente como uma réplica.
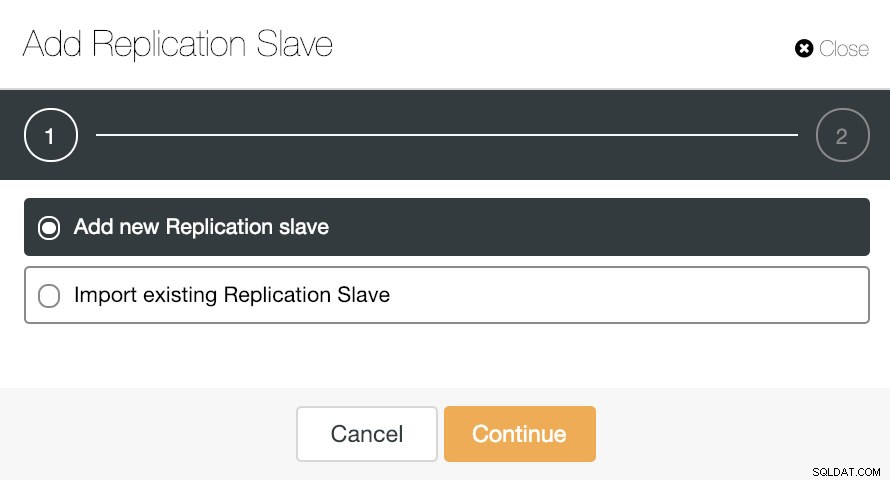
Vamos ver como adicionar um novo slave de replicação pode ser uma tarefa muito fácil.
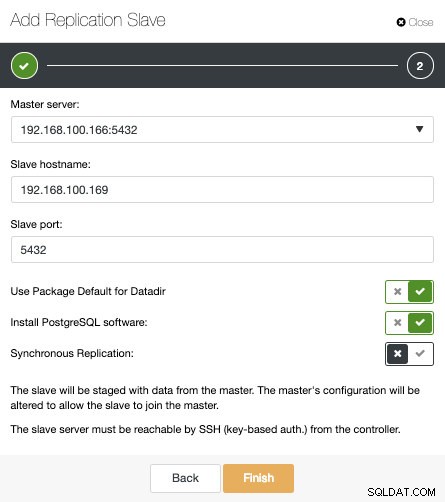
Como você pode ver na imagem, só precisamos escolher nosso servidor Master, inserir o endereço IP do nosso novo servidor slave e a porta do banco de dados. Então, podemos escolher se queremos que o ClusterControl instale o software para nós e se o escravo de replicação deve ser Síncrono ou Assíncrono.
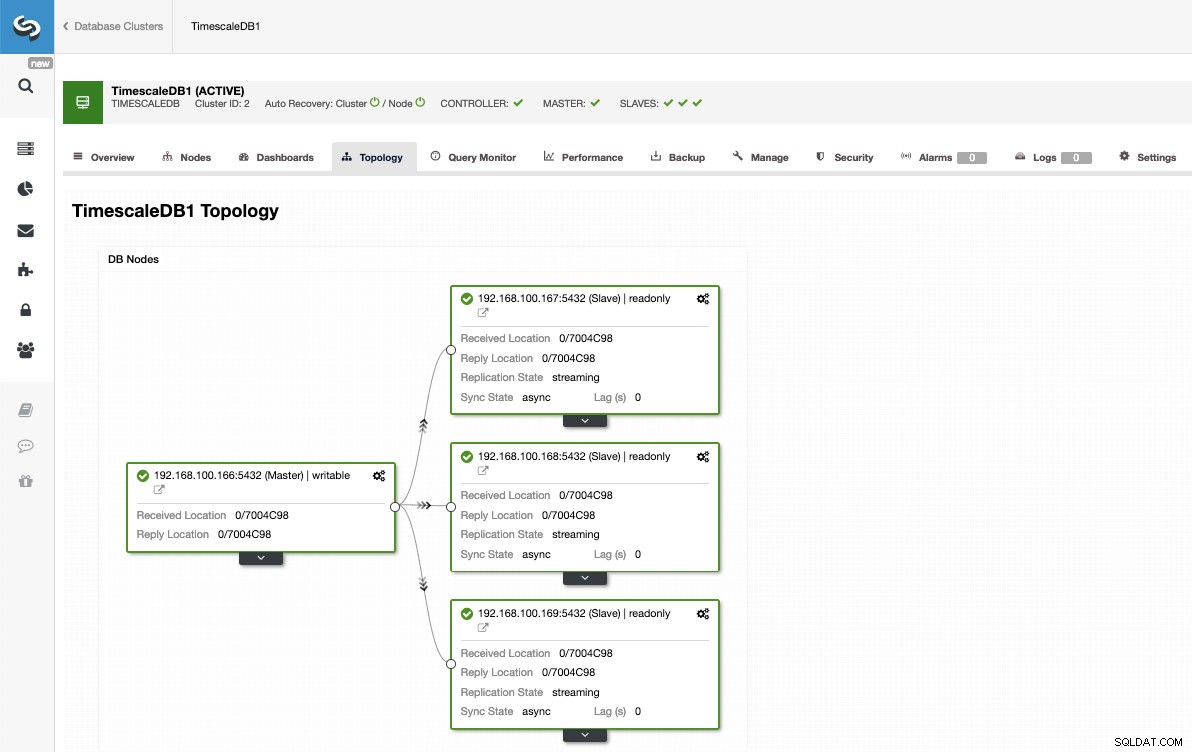
Dessa forma, podemos adicionar quantas réplicas quisermos e distribuir o tráfego de leitura entre elas usando um balanceador de carga, que também podemos implementar com o ClusterControl.
A partir do ClusterControl, você também pode executar diferentes tarefas de gerenciamento como Reboot Host, Rebuild Replication Slave ou Promover Slave, com um clique.
Conclusão
Como vimos acima, agora você pode implantar o TimescaleDB usando o ClusterControl. Uma vez implantado, o ClusterControl fornece uma ampla gama de recursos, desde monitoramento, alerta, failover automático, backup, recuperação pontual, verificação de backup até dimensionamento de réplicas de leitura. Isso pode ajudá-lo a gerenciar o TimescaleDB de maneira amigável e intuitiva.