Como consultor que trabalha com SQL Server, muitas vezes me pedem para examinar um servidor que parece estar com problemas de desempenho. Durante a triagem no servidor, faço algumas perguntas, como:qual é a sua utilização normal da CPU, quais são as suas latências médias de disco, qual é a sua utilização normal da memória e assim por diante. A resposta geralmente é “não sabemos” ou “não estamos capturando essa informação regularmente”. Não ter uma linha de base recente torna muito difícil saber como é o comportamento anormal. Se você não sabe o que é um comportamento normal, como saber com certeza se as coisas estão melhores ou piores? Costumo usar as expressões “se você não está monitorando, não pode medir” e “se você não está medindo, não pode gerenciá-lo”.
De uma perspectiva de monitoramento, no mínimo, as organizações devem monitorar tarefas com falha, como backups, manutenção de índice, DBCC CHECKDB e quaisquer outras tarefas importantes. É fácil configurar notificações de falha para eles; no entanto, você também precisa de um processo para garantir que os trabalhos estejam sendo executados conforme o esperado. Já vi trabalhos que ficam pendurados e nunca são concluídos. Uma notificação de falha não acionaria um alarme, pois o trabalho nunca é bem-sucedido ou falha.
A partir de uma linha de base de desempenho, existem várias métricas-chave que devem ser capturadas. Criei um processo que uso com clientes que captura as principais métricas regularmente e armazena esses valores em um banco de dados do usuário. Meu processo é simples:um banco de dados dedicado com procedimentos armazenados que usam scripts comuns que inserem os conjuntos de resultados em tabelas. Tenho trabalhos do SQL Agent para executar os procedimentos armazenados em intervalos regulares e um script de limpeza para limpar dados com mais de X dias. As métricas que sempre capturo incluem:
Expectativa de vida da página :PLE é provavelmente uma das melhores maneiras de avaliar se o seu sistema está sob pressão de memória interna. A maioria dos sistemas tem valores de PLE que flutuam durante cargas de trabalho normais. Eu gosto de tendência desses valores para saber quais são os valores mínimo, médio e máximo. Eu gosto de tentar entender o que causou a queda do PLE em determinados horários do dia para ver se esses processos podem ser ajustados. Muitas vezes, alguém está fazendo uma varredura de tabela e liberando o buffer pool. Ser capaz de indexar adequadamente essas consultas pode ajudar. Apenas certifique-se de estar monitorando o contador PLE correto – veja aqui .
Utilização da CPU :Ter uma linha de base para a utilização da CPU permite que você saiba se o seu sistema está subitamente sob pressão da CPU. Muitas vezes, quando um usuário reclama de problemas de desempenho, eles observam que a CPU parece alta. Por exemplo, se a CPU estiver pairando em torno de 80%, eles podem achar isso preocupante, no entanto, se a CPU também estiver em 80% durante o mesmo período das semanas anteriores, quando nenhum problema foi relatado, a probabilidade de que a CPU seja o problema é muito baixa. A CPU de tendência não serve apenas para capturar quando a CPU atinge um pico e permanece em um valor consistentemente alto. Tenho várias histórias de quando fui levado a uma ponte de conferência de gravidade porque havia um problema com um aplicativo. Sendo o DBA, eu usava o chapéu de “Default Blame Acceptor”. Quando a equipe do aplicativo disse que havia um problema com o banco de dados, cabia a mim provar que não era, o servidor de banco de dados era culpado até que se prove inocente. Lembro-me vividamente de um incidente em que a equipe do aplicativo estava confiante de que o servidor de banco de dados estava com problemas porque os usuários não conseguiam se conectar. Eles leram na internet que o SQL Server poderia estar sofrendo de inanição do pool de threads se estivesse recusando conexões. Eu pulei no servidor e comecei a olhar para os recursos e quais processos estavam sendo executados no momento. Em poucos minutos, relatei que o servidor em questão estava muito entediado. Com base em nossas métricas de linha de base, a CPU era normalmente de 60% e estava ociosa em torno de 20%, a expectativa de vida da página era visivelmente maior que o normal e não havia bloqueio ou bloqueio acontecendo, a E/S parecia ótima, sem erros em nenhum log e as contagens de sessões foram cerca de 1/3 de sua contagem normal. Em seguida, fiz o comentário:“Parece que os usuários nem estão acessando o servidor de banco de dados”. Isso chamou a atenção do pessoal da rede e eles perceberam que uma alteração feita no balanceador de carga não estava funcionando corretamente e determinaram que mais de 50% das conexões estavam sendo roteadas incorretamente e não chegavam ao servidor de banco de dados. Se eu não soubesse qual era a linha de base, levaríamos muito mais tempo para chegar à resolução.
E/S de disco :A captura de métricas de disco é muito importante. O DMV sys.dm_io_virtual_file_stats é cumulativo desde a última reinicialização do servidor. Capturar suas latências de E/S em um intervalo de tempo fornecerá uma linha de base do que é normal durante esse período. Confiar no valor cumulativo pode fornecer dados distorcidos de atividades após o horário comercial ou longos períodos em que o sistema estava ocioso. Paul discutiu isso aqui .
Tamanhos de arquivo de banco de dados :ter um inventário de seus bancos de dados que inclua tamanho de arquivo, tamanho usado, espaço livre e muito mais pode ajudar a prever o crescimento do banco de dados. Muitas vezes me pedem para prever quanto armazenamento seria necessário para um servidor de banco de dados no próximo ano. Sem conhecer a tendência de crescimento semanal ou mensal, não tenho como chegar a um número inteligentemente. Uma vez que eu comece a rastrear esses valores, posso fazer uma tendência adequada disso. Além das tendências, também pude descobrir quando houve um crescimento inesperado do banco de dados. Quando vejo um crescimento inesperado e investigo, geralmente descubro que alguém duplicou uma tabela para fazer alguns testes (sim, em produção!) ou fez algum outro processo único. O rastreamento desse tipo de dados e a capacidade de responder quando ocorrem anomalias ajuda a mostrar que você é proativo e está vigiando seus sistemas.
Estatísticas de espera :o monitoramento das estatísticas de espera pode ajudá-lo a descobrir a causa de determinados problemas de desempenho. Muitos DBAs novos ficam preocupados quando começam a pesquisar estatísticas de espera e não percebem que as esperas sempre ocorrem, e é assim que o sistema de agendamento do SQL Server funciona. Há também muitas esperas que podem ser consideradas benignas, ou principalmente inofensivas. Paul Randal exclui essas esperas inofensivas em seu popular script de estatísticas de espera. Paul também construiu uma vasta biblioteca de vários tipos de espera e classes de trava com descrições e outras informações sobre como solucionar problemas de esperas e travas.
Documentei meu processo de coleta de dados e você pode encontrar o código em meu blog . Dependendo da situação e dos tipos de problemas que um cliente possa ter, também posso querer capturar métricas adicionais. Glenn Berry blogou sobre um processo que ele montou que captura contagem média de tarefas, contagem média de tarefas executáveis, contagem média de E/S pendente, utilização da CPU do processo do SQL Server e expectativa de vida média da página em todos os nós NUMA. Uma rápida pesquisa na Internet revelará vários outros processos de coleta de dados que as pessoas compartilharam, até mesmo a Equipe Tiger do SQL Server tem um processo que utiliza T-SQL e PowerShell.
Usar um banco de dados personalizado e criar seu próprio pacote de coleta de dados é uma solução válida para capturar uma linha de base, mas a maioria de nós não está no negócio de criar soluções completas de monitoramento do SQL Server. Há muito mais que seria útil para capturar, coisas como consultas de longa duração, consultas principais e procedimentos armazenados baseados em memória, E/S e CPU, deadlocks, fragmentação de índice, transações por segundo e muito mais. Para isso, sempre recomendo que os clientes adquiram uma ferramenta de monitoramento de terceiros. Esses fornecedores são especializados em manter-se atualizados sobre as últimas tendências e recursos do SQL Server para que você possa concentrar seu tempo em garantir que o SQL Server seja o mais estável e rápido possível.
Soluções como SQL Sentry (para SQL Server) e DB Sentry (para o Banco de Dados SQL do Azure) captura todas essas métricas para você e permite que você crie facilmente diferentes linhas de base. Você pode ter uma linha de base normal, final de mês, final de trimestre e muito mais. Você pode então aplicar a linha de base e ver visualmente como as coisas são diferentes. Mais importante, você pode configurar qualquer número de alertas para várias condições e ser notificado quando as métricas excederem seus limites.
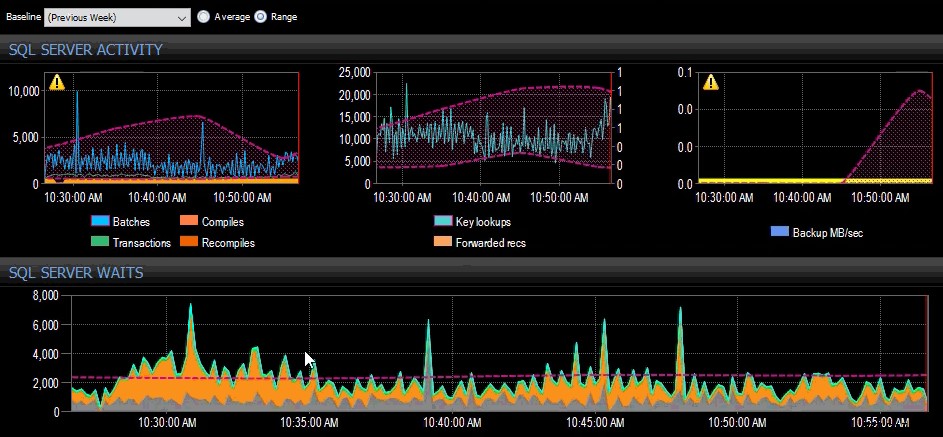 A linha de base da semana passada aplicada a várias métricas do SQL Server no painel do SQL Sentry.
A linha de base da semana passada aplicada a várias métricas do SQL Server no painel do SQL Sentry. 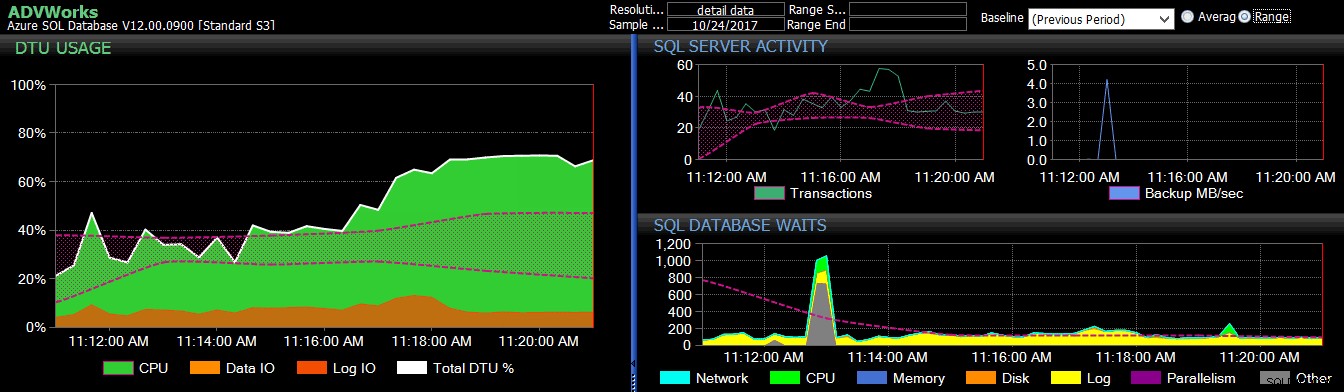 A linha de base do período anterior aplicada a várias métricas do Banco de Dados SQL do Azure no painel do DB Sentry.
A linha de base do período anterior aplicada a várias métricas do Banco de Dados SQL do Azure no painel do DB Sentry. Para obter mais informações sobre linhas de base no SentryOne, consulte estas postagens no blog da equipe ou este vídeo de terça-feira de 2 minutos . Interessado em baixar um teste? Eles também têm cobertura para você .