Recentemente, fui repreendido por sugerir que, em alguns casos, um índice não clusterizado terá um desempenho melhor para uma consulta específica do que o índice clusterizado. Essa pessoa afirmou que o índice clusterizado é sempre melhor porque está sempre cobrindo por definição, e que qualquer índice não clusterizado com algumas ou todas as mesmas colunas de chave sempre foi redundante.
Concordo com prazer que o índice clusterizado está sempre cobrindo (e para evitar qualquer ambiguidade aqui, vamos nos ater a tabelas baseadas em disco com índices tradicionais de árvore B).
 Eu discordo, porém, que um índice clusterizado seja sempre mais rápido do que um índice não agrupado. Também discordo que é sempre redundante criar um índice não clusterizado ou uma restrição exclusiva que consiste nas mesmas (ou algumas das mesmas) colunas na chave de clustering.
Eu discordo, porém, que um índice clusterizado seja sempre mais rápido do que um índice não agrupado. Também discordo que é sempre redundante criar um índice não clusterizado ou uma restrição exclusiva que consiste nas mesmas (ou algumas das mesmas) colunas na chave de clustering. Vamos pegar este exemplo,
Warehouse.StockItemTransactions , da WideWorldImporters. O índice clusterizado é implementado por meio de uma chave primária apenas no StockItemTransactionID coluna (bastante típico quando você tem algum tipo de ID substituto gerado por uma IDENTIDADE ou SEQUÊNCIA). É uma coisa bastante comum exigir uma contagem de toda a tabela (embora em muitos casos existam maneiras melhores). Isso pode ser para inspeção casual ou como parte de um procedimento de paginação. A maioria das pessoas vai fazer assim:
SELECT COUNT(*) FROM Warehouse.StockItemTransactions;
Com o esquema atual, isso usará um índice não clusterizado:
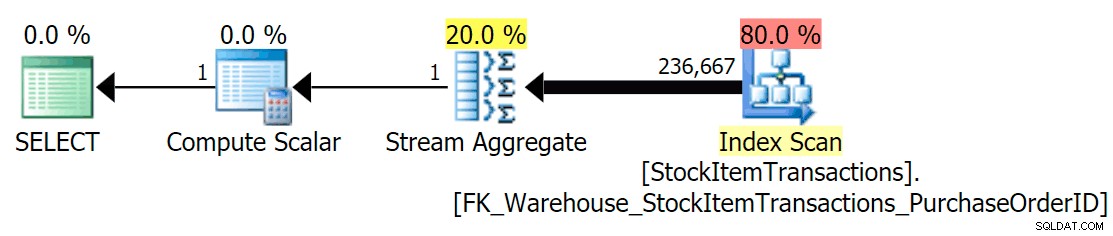
Sabemos que o índice não clusterizado não contém todas as colunas do índice clusterizado. A operação de contagem só precisa ter certeza de que todas as linhas estão incluídas, sem se importar com quais colunas estão presentes, então o SQL Server normalmente escolherá o índice com o menor número de páginas (neste caso, o índice escolhido tem ~414 páginas).
Agora vamos executar a consulta novamente, desta vez comparando-a com uma consulta com sugestão que força o uso do índice clusterizado.
SELECT COUNT(*) FROM Warehouse.StockItemTransactions; SELECT COUNT(*) /* with hint */ FROM Warehouse.StockItemTransactions WITH (INDEX(1));
Obtemos uma forma de plano quase idêntica, mas podemos ver uma enorme diferença nas leituras (414 para o índice escolhido versus 1.982 para o índice clusterizado):
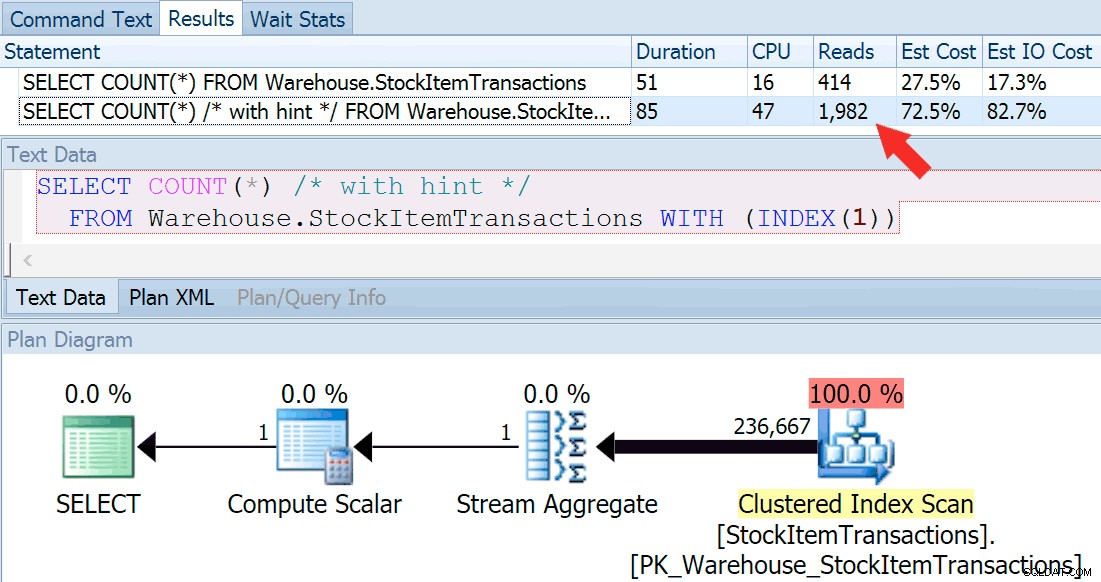
A duração é um pouco maior para o índice clusterizado, mas a diferença é insignificante quando estamos lidando com uma pequena quantidade de dados em cache em um disco rápido. Essa discrepância seria muito mais pronunciada com mais dados, em um disco lento ou em um sistema com pressão de memória.
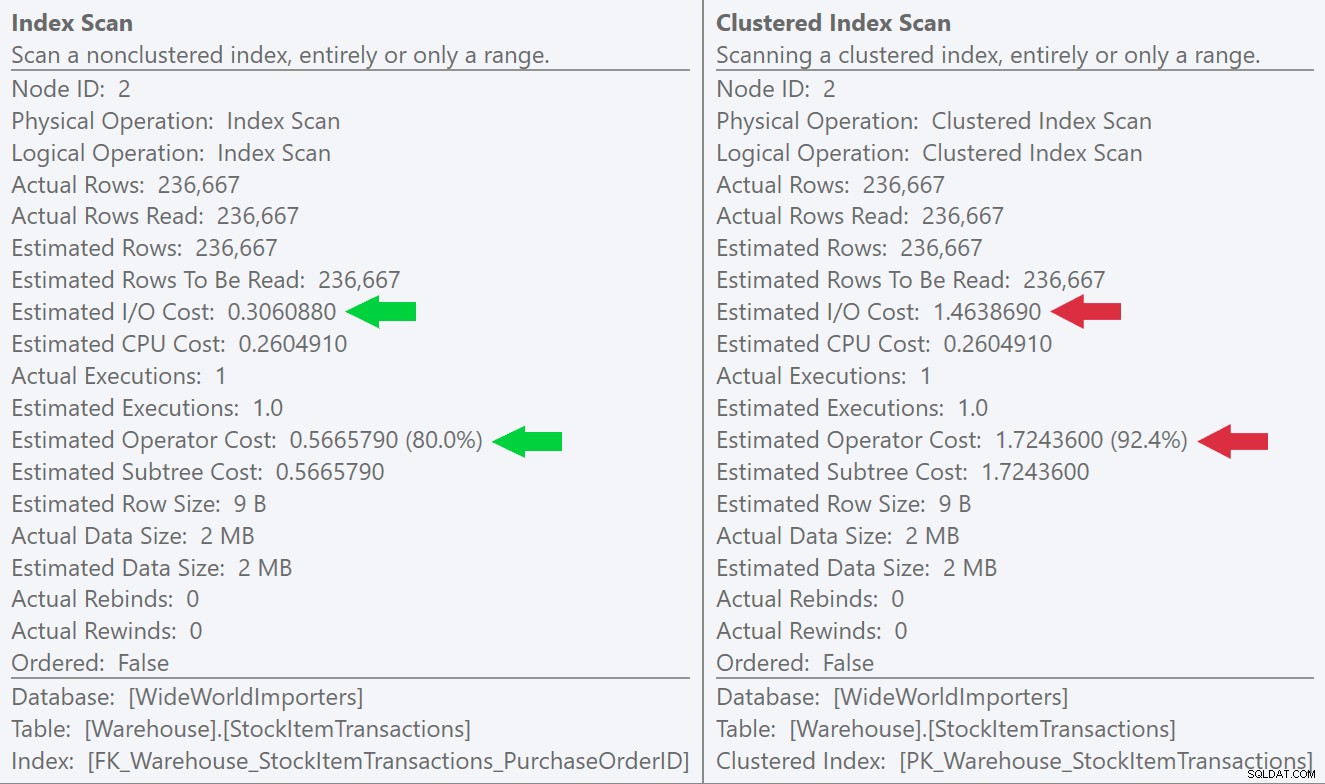
Se observarmos as dicas de ferramentas para as operações de varredura, podemos ver que, embora o número de linhas e os custos estimados de CPU sejam idênticos, a grande diferença vem do custo estimado de E/S (porque o SQL Server sabe que há mais páginas no índice clusterizado do que o índice não clusterizado):
Podemos ver essa diferença ainda mais claramente se criarmos um índice novo e exclusivo apenas na coluna ID (tornando-o "redundante" com o índice clusterizado, certo?):
CREATE UNIQUE INDEX NewUniqueNCIIndex ON Warehouse.StockItemTransactions(StockItemTransactionID);
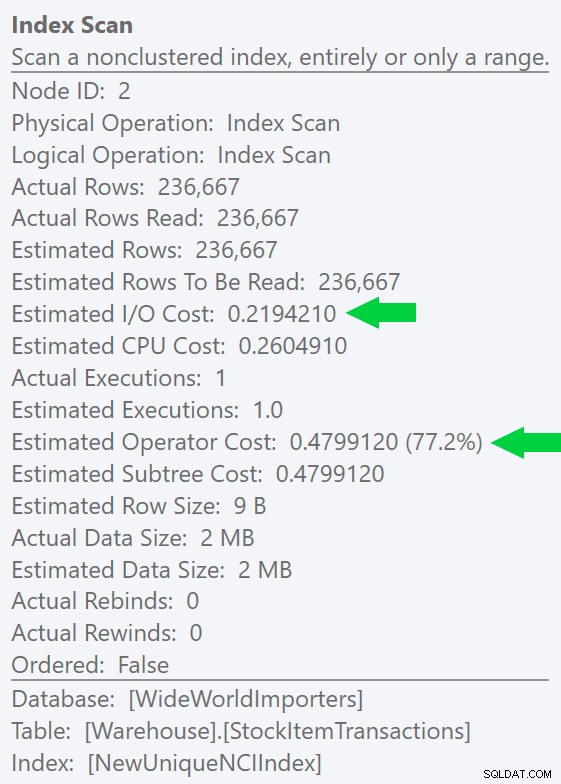 Executar uma consulta semelhante com uma dica de índice explícita produz a mesma forma de plano, mas uma E/S estimada ainda menor custo (e durações ainda menores) – veja a imagem à direita. E se você executar a consulta original sem a dica, verá que o SQL Server agora também escolhe esse índice.
Executar uma consulta semelhante com uma dica de índice explícita produz a mesma forma de plano, mas uma E/S estimada ainda menor custo (e durações ainda menores) – veja a imagem à direita. E se você executar a consulta original sem a dica, verá que o SQL Server agora também escolhe esse índice. Pode parecer óbvio, mas muita gente acreditaria que o índice clusterizado é a melhor escolha aqui. O SQL Server quase sempre favorecerá fortemente qualquer método que forneça a maneira mais barata de executar toda a E/S e, no caso de uma verificação completa, esse será o índice "mais fino". Isso também pode acontecer com os dois tipos de buscas (singleton e range scans), pelo menos quando o índice estiver cobrindo.
Agora, como sempre, isso não de qualquer forma significa que você deve criar índices adicionais em todas as suas tabelas para satisfazer as consultas de contagem. Essa não é apenas uma maneira ineficiente de verificar o tamanho da tabela (novamente, consulte este artigo), mas um índice para dar suporte a isso significaria que você está executando essa consulta com mais frequência do que atualizando os dados. Lembre-se de que todo índice requer espaço em disco, espaço na memória e todas as gravações na tabela também devem tocar em todos os índices (índices filtrados à parte).
Resumo
Eu poderia apresentar muitos outros exemplos que mostram quando um não clusterizado pode ser útil e vale o custo de manutenção, mesmo ao duplicar a(s) coluna(s) chave do índice clusterizado. Índices não clusterizados podem ser criados com as mesmas colunas de chave, mas em uma ordem de chave diferente, ou com ASC/DESC diferente nas próprias colunas para oferecer melhor suporte a uma ordem de apresentação alternativa. Você também pode ter índices não clusterizados que carregam apenas um pequeno subconjunto das linhas por meio do uso de um filtro. Por fim, se você puder satisfazer suas consultas mais comuns com índices mais finos e não agrupados, isso também será melhor para o consumo de memória.
Mas, na verdade, meu ponto desta série é apenas mostrar um contra-exemplo que ilustra a tolice de fazer declarações gerais como esta. Vou deixar você com uma explicação de Paul White que, em uma resposta do DBA.SE, explica por que um índice não clusterizado pode, de fato, ter um desempenho muito melhor do que um índice clusterizado. Isso é verdade mesmo quando ambos usam qualquer tipo de busca:
- Diferença entre busca de índice clusterizado e busca de índice não clusterizado