Em março, iniciei uma série sobre mitos de desempenho generalizados no SQL Server. Uma crença que encontro de tempos em tempos é que você pode superdimensionar colunas varchar ou nvarchar sem nenhuma penalidade.
Vamos supor que você esteja armazenando endereços de e-mail. Em uma vida anterior, lidei bastante com isso – na época, a RFC 3696 dizia que um endereço de e-mail poderia ter 320 caracteres (64chars@255chars). Um RFC mais recente, #5321, agora reconhece que 254 caracteres é o máximo que um endereço de e-mail pode ter. E se algum de vocês tiver um endereço tão longo, talvez devêssemos conversar. :-)
Agora, quer você siga o padrão antigo ou o novo, você tem que apoiar a possibilidade de que alguém use todos os caracteres permitidos. O que significa que você precisa usar 254 ou 320 caracteres. Mas o que eu tenho visto as pessoas não se incomodam em pesquisar o padrão, e apenas assumem que eles precisam suportar 1.000 caracteres, 4.000 caracteres ou até mais.
Então, vamos dar uma olhada no que acontece quando temos tabelas com uma coluna de endereço de e-mail de tamanho variável, mas armazenando exatamente os mesmos dados:
CREATE TABLE dbo.Email_V320 ( id int IDENTITY PRIMARY KEY, email varchar(320) ); CREATE TABLE dbo.Email_V1000 ( id int IDENTITY PRIMARY KEY, email varchar(1000) ); CREATE TABLE dbo.Email_V4000 ( id int IDENTITY PRIMARY KEY, email varchar(4000) ); CREATE TABLE dbo.Email_Vmax ( id int IDENTITY PRIMARY KEY, email varchar(max) );
Agora, vamos gerar 10.000 endereços de e-mail fictícios a partir dos metadados do sistema e preencher todas as quatro tabelas com os mesmos dados:
INSERT dbo.Email_V320(email) SELECT TOP (10000) REPLACE(LEFT(LEFT(c.name, 64) + '@' + LEFT(o.name, 128) + '.com', 254), ' ', '') FROM sys.all_columns AS c INNER JOIN sys.all_objects AS o ON c.[object_id] = o.[object_id] INNER JOIN sys.all_columns AS c2 ON c.[object_id] = c2.[object_id] ORDER BY NEWID(); INSERT dbo.Email_V1000(email) SELECT email FROM dbo.Email_V320; INSERT dbo.Email_V4000(email) SELECT email FROM dbo.Email_V320; INSERT dbo.Email_Vmax (email) SELECT email FROM dbo.Email_V320; -- let's rebuild ALTER INDEX ALL ON dbo.Email_V320 REBUILD; ALTER INDEX ALL ON dbo.Email_V1000 REBUILD; ALTER INDEX ALL ON dbo.Email_V4000 REBUILD; ALTER INDEX ALL ON dbo.Email_Vmax REBUILD;
Para validar que cada tabela contém exatamente os mesmos dados:
SELECT AVG(LEN(email)), MAX(LEN(email)) FROM dbo.Email_<size>;
Todos os quatro rendem 35 e 77 para mim; sua milhagem pode variar. Vamos também garantir que todas as quatro tabelas ocupem o mesmo número de páginas no disco:
SELECT o.name, COUNT(p.[object_id])
FROM sys.objects AS o
CROSS APPLY sys.dm_db_database_page_allocations
(DB_ID(), o.object_id, 1, NULL, 'LIMITED') AS p
WHERE o.name LIKE N'Email[_]V[^2]%'
GROUP BY o.name; Todas essas quatro consultas rendem 89 páginas (mais uma vez, sua milhagem pode variar).
Agora, vamos fazer uma consulta típica que resulta em uma verificação de índice clusterizado:
SELECT id, email FROM dbo.Email_<size>;
Se olharmos para coisas como duração, leituras e custos estimados, todos parecem iguais:
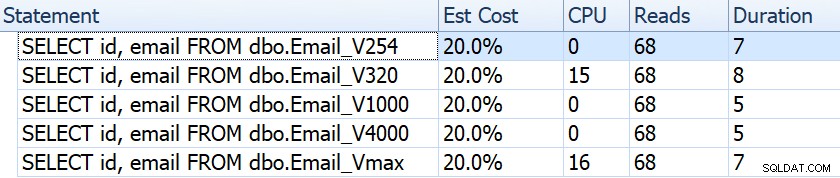
Isso pode levar as pessoas a uma falsa suposição de que não há nenhum impacto no desempenho. Mas se olharmos um pouco mais de perto, na dica de ferramenta para a varredura de índice clusterizado em cada plano, vemos uma diferença que pode entrar em jogo em outras consultas mais elaboradas:

A partir daqui, vemos que, quanto maior a definição da coluna, maior a linha estimada e o tamanho dos dados. Nesta consulta simples, o custo de E/S (0,0512731) é o mesmo em todas as consultas, independentemente da definição, porque a varredura de índice clusterizado precisa ler todos os dados de qualquer maneira.
Mas há outros cenários em que essa linha estimada e o tamanho total dos dados terão impacto:operações que exigem recursos adicionais, como classificações. Vamos pegar essa consulta ridícula que não serve a nenhum propósito real, além de exigir várias operações de classificação:
SELECT /* V<size> */ ROW_NUMBER() OVER (PARTITION BY email ORDER BY email DESC),
email, REVERSE(email), SUBSTRING(email, 1, CHARINDEX('@', email))
FROM dbo.Email_V<size>
GROUP BY REVERSE(email), email, SUBSTRING(email, 1, CHARINDEX('@', email))
ORDER BY REVERSE(email), email; Executamos essas quatro consultas e vemos todos os planos assim:

No entanto, esse ícone de aviso no operador SELECT só aparece nas tabelas 4000/max. Qual é o aviso? É um aviso de concessão de memória excessiva, introduzido no SQL Server 2016. Aqui está o aviso para varchar(4000):

E para varchar(max):

Vamos olhar um pouco mais de perto e ver o que está acontecendo, pelo menos de acordo com sys.dm_exec_query_stats:
SELECT [table] = SUBSTRING(t.[text], 1, CHARINDEX(N'*/', t.[text])), s.last_elapsed_time, s.last_grant_kb, s.max_ideal_grant_kb FROM sys.dm_exec_query_stats AS s CROSS APPLY sys.dm_exec_sql_text(s.sql_handle) AS t WHERE t.[text] LIKE N'%/*%dbo.'+N'Email_V%' ORDER BY s.last_grant_kb;
Resultados:

No meu cenário, a duração não foi afetada pelas diferenças de concessão de memória (exceto para o caso máximo), mas você pode ver claramente a progressão linear que coincide com o tamanho declarado da coluna. Que você pode usar para extrapolar o que aconteceria em um sistema com memória insuficiente. Ou uma consulta mais elaborada em um conjunto de dados muito maior. Ou simultaneidade significativa. Qualquer um desses cenários pode exigir spills para processar as operações de classificação, e a duração quase certamente seria afetada como resultado.
Mas de onde vêm essas concessões de memória maiores? Lembre-se, é a mesma consulta, em relação aos mesmos dados exatos. O problema é que, para certas operações, o SQL Server precisa levar em conta a quantidade de dados *pode* estar em uma coluna. Ele não faz isso com base na criação de perfil dos dados e não pode fazer suposições com base nos valores de etapa do histograma <=201. Em vez disso, ele deve estimar que cada linha contém um valor metade do tamanho da coluna declarada . Portanto, para um varchar(4000), ele assume que cada endereço de e-mail tem 2.000 caracteres.
Quando não é possível ter um endereço de e-mail com mais de 254 ou 320 caracteres, não há nada a ganhar com o tamanho excessivo, e há muito a perder. Aumentar o tamanho de uma coluna de largura variável posteriormente é muito mais fácil do que lidar com todas as desvantagens agora.
Claro, superdimensionando
char ou nchar colunas podem ter penalidades muito mais óbvias.